基于多核架构和多收发队列的高速捕包模型研究
2013-08-20齐战胜林立友
齐战胜 林立友
厦门市美亚柏科信息股份有限公司北京分公司 北京 100025
0 引言
一个好的包捕获系统应该尽可能少的丢包,实时捕获流经系统的所有数据包,而且应该较少地占用CPU资源,使得系统拥有更多的时间来对数据包内容的进行处理。
在包捕获硬件方面,当前市场上有很多千兆以太网报文处理网卡,如Endace 公司生产的DAG网卡、Liberouter及SCAMPI项目开发的COMBO网卡等。由于基于硬件的捕包方式价格比较昂贵,而且系统缺乏一定的灵活性,难以适应当今瞬息万变的网络发展现状与具体的流量分析需求。
在包捕获软件方面,设计了很多优秀的包捕获函数库如Libpcap、nCap、DMA-Ring和PF_RING等。Libpcap是一个优秀的数据包捕获函数库,由网卡驱动、操作系统内核协议栈以及套接字接口三个部分组成,由于消耗了较高的CPU资源、引入了较高的包传输延时等问题,效率较低。为了提高包捕获的效率,很多研究人员已经做了大量的工作,包括从操作系统和应用软件两个方面进行优化。在操作系统方面:由于很多网络应用都有实时性的要求,增加了一些实时的内核来提高网络的实时性;为了避免频繁的中断造成的中断活锁现象,Linux内核中引入了一些新的 API函数,简称NAPI(NewAPI),通过在重负载的情况下采用轮询的方式来提高包捕获系统的性能。在应用软件方面:一种方式是减少内存拷贝次数,Libpcap-mmap、nCap、DMA-RING和PF_RING都采用了这种方式;第二种方式是减少系统调用的次数。
综合分析以上包捕获技术,发现以上没有任何一种包捕获接口的速度能达到千兆线速的处理目标,即使它们的设计目标是这样;第二,都是基于单核的系统来进行设计,没有考虑到发挥多核平台和多收发队列网卡的优势来增加系统的吞吐量。
本文在基于PCI-E总线的 Intel X86 多核平台下,通过充分利用RPS和RFS的包分发技术、PF_RING的零拷贝技术和多核CPU的计算资源,解决了 Gbit 及其以上链路带宽下的包捕获问题。
1 包捕获模型
多核处理器是指在一枚处理器中集成两个或多个完整的计算引擎(内核)。操作系统通过在多个执行内核之间划分任务,多核处理器可在特定的时钟周期内执行更多的任务。
多队列网卡是一种技术,最初是用来解决网络 IO QoS问题的,后来随着网络IO的带宽的不断提升,单核CPU不能完全处满足网卡的需求,通过多队列网卡驱动的支持,将各个队列通过中断绑定到不同的核上,以满足网卡的需求。常见的有Intel的 82575、82576、82599、82580,Boardcom的57711等。
为了充分利用多核处理器的计算资源和多队列网卡的吞吐能力,本文提出了以下包捕获模型,如图1所示。
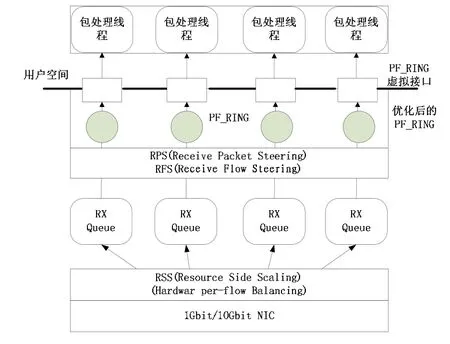
图1 包捕获模型
此模型中采用的是Intel 82576多队列网卡,模型工作流程如下:
(1) 数据包到达网卡后,产生硬中断,网卡RSS根据数据包的IP和端口计算出hash值,hash值跟中断个数取模后,分成若干个接收队列。
(2) 为了保证分发到每个包处理线程的数据链的完整性(一个链接上的上行和下行数据都分发到一个包处理线程),所以这里需要利用RPS和RFS技术对数据包进行重新计算Hash值,然后取模分发到相应的CPU核心上。
(3) 改进后的PF_RING为每一个接收队列创建一个虚拟的网络接口,通过在内核注册的函数接收RFS分发下来的数据包,然后送到相应的虚拟网络接口。
(4) 用户空间的包处理线程通过PF_RING的虚拟网络接口读取数据包并处理。
2 核心技术简介
2.1 RSS技术
多队列数据包分发技术接收方扩展 (RSS,Receive Side Scaling)。目前的NICs支持多个接收和传输队列,即多队列。接收的时候,一个网卡能够发送不同的包到不同的队列,为了在不同的CPU之间分散处理。NIC针对每一个包,通过一个过滤器来指定这个包属于少数几个流中的一个流。每个流中的数据包被控制在一个单独的接收队列中,而队列轮回的被CPU进行处理。这种机制就叫做RSS。RSS的目标和其他控制技术目的都是为了提高数据吞吐性能。
RSS中的过滤器是一个基于L3和L4层头部的hash函数。例如,基于IP地址和TCP端口的4元组的hash函数。最常见的RSS硬件实现中,使用了128个间接表,其中每个表存储一个队列号(注,网卡的队列数比较少,比如igb是8个,bnx2是5个)。针对某个包而言,使用这个包计算出的hash值(hash是Toeplitz算法)的低7位先确定间接表,再从间接表中的值访问队列。
多队列网卡的驱动提供了一个内核模块参数,用来指定硬件队列个数。一个典型的RSS配置中,最好的是一个CPU对应一个接收队列。每个接收队列有一个单独的IRQ,即中断号。NIC通过IRQ来通知CPU什么时候新的数据包到达了指定的队列。有效的队列到IRQ的映射是由/proc/interrupts来指定的。一些系统会运行 irqbalance服务,这个服务会动态的优化IRQ的亲和性。
2.2 RPS技术
RPS(Receive Packet Steering) 逻辑上是一种以软件的方式来实现RSS。在数据包被从网卡驱动传向网络协议栈时,RPS在底半环境(通过软中断来实现的,在硬中断处理函数之后)中被调用。通过把数据包放在目标CPU的backlog队列,并唤醒CPU来处理,之后队列中数据包被发送到网络协议栈进行处理。
RPS相比RSS有几个好处:
(1) RPS能够被任何NIC使用。
(2) 软件过滤器能够轻易的被添加,用来hash新的协议。
(3) 它不会增加硬件设备的中断。
决定目标CPU的第一步是基于包的地址和端口(有的协议是2元组,有的协议是4元组)来计算hash值。这个值与这个包的流保持一致。这个hash值要么是由硬件来提供的,要么是由协议栈来计算的。每一个接收硬件队列有一个相关的CPU列表,RPS可以将包放到这个队列中进行处理。对于每一个接收到的包,指向这个列表的索引是通过流hash值对列表大小取模来计算的。被指向的 CPU是处理包的目标CPU,并且这个包被加到CPU的backlog队列的尾部。经过底半处理后,IPI被发送到这个包所插到的那个CPU。IPI唤醒远程CPU来处理backlog队列,之后队列中数据包被发送到网络协议栈进行处理。
RPS要求内核编译了CONFIG_RPS选项(SMP上默认是打开的)。尽管编译到内核,直到被配置了才能启用。对于某个接收队列,RPS可以转发流量到哪个 CPU,是由/sys/class/net/queues/rx-/rps_cpus来控制的。这个文件实现了CPU的位图。默认,当值是0,RPS是无效的,数据包是由中断的CPU来处理的。
2.3 RFS技术
RFS(Receive Flow Steering),RPS只依靠hash来控制数据包,提供了好的负载平衡,但是它没有考虑应用程序的位置(注:这个位置是指程序在哪个 cpu上执行)。RFS则考虑到了应用程序的位置。RFS的目标是通过指派应用线程正在运行的CPU来进行数据包处理,以此来增加数据缓存的命中率。RFS依靠RPS的机制插入数据包到指定CPU的backlog队列,并唤醒那个CPU来执行。
RFS中,数据包并不会直接的通过数据包的hash值被转发,但是hash值将会作为流查询表的索引。这个表映射数据流与处理这个流的CPU。这个数据流的hash值(就是这个流中的数据包的 hash值)将被用来计算这个表的索引。流查询表的每条记录中所记录的CPU是上次处理数据流的CPU。如果记录中没有CPU,那么数据包将会使用RPS来处理。多个记录会指向相同的CPU。确实,当流很多而CPU很少时,很有可能一个应用线程处理多个不同hash值的数据流。
RFS需要内核编译 CONFIG_RPS选项,直到明显的配置,RFS才起作用。全局数据流表(rps_sock_flow_table)的总数可以通过下面的参数来设置:/proc/sys/net/core/rps_sock_flow_entries每个队列的数据流表总数可以通过下面的参数来设置:/sys/class/net//queues/rx-/rps_flow_cnt。
2.4 线程绑定技术
通过调用 SetThreadAffinityMask,就能为各个线程设置亲缘性屏蔽:

该函数中的 hThread参数用于指明要限制哪个线程,dwThreadAffinityMask用于指明该线程能够在哪个CPU上运行。dwThreadAffinityMask必须是进程的亲缘性屏蔽的相应子集。返回值是线程的前一个亲缘性屏蔽。
例如,可能有一个包含4个线程的进程,它们在拥有4个CPU的计算机上运行。如果这些线程中的一个线程正在执行非常重要的操作,而你想增加某个CPU始终可供它使用的可能性,为此你对其他3个线程进行了限制,使它们不能在CPU 0上运行,而只能在CPU 1、2和3上运行。因此,若要将3个线程限制到CPU 1、2和3上去运行,可以这样操作:


2.5 PF_RING技术及优化
2.5.1 PF_RING技术简介
PF_RING是Luca研究出来的基于Linux内核级的高效数据包捕获技术。PF_RING基本原理是将网卡接收的数据包存储在一个环状缓存,这也是为什么叫RING的原因,这个环状缓存有两个接口,一个供网卡向其中写数据包,另一个为应用层程序提供读取数据包的接口,读取数据包的接口通过 mmap函数(将一个文件或其它对象映射进内存)实现的。图2显示了PF_RING的工作原理。

图2 PF_RING
2.5.2 PF_RING技术优化
由于 PF_RING需要定制的网卡驱动的支持,并且PF_RING的虚拟网络接口目前仅支持 DNA(Direct NIC Access)模式,所以为了适应本模型的需要,本文做了以下优化:
(1) 修改PF_RING定制的网卡驱动,开启网卡多接收队列的功能;
(2) 把PF_RING的DNA模块的虚拟网络接口功能移植到NAPI模式下。
3 性能分析
3.1 实验环境搭建
图3显示了测试环境的部署情况。

图3 测试环境
测试服务器,i3 CPU 2.93GHZ,4G内存,2块Intel 82576千兆网卡,Red Hat Enterprise 6.0系统(内核已升级为2.6.39),
网络流量发生仪,基于 Intel IXP2400 的网络处理器,用于产生测试的流量。
控制端是普通的PC机,用来控制流量的组织、发送和控制。
3.2 性能测试与分析
3.2.1 捕包性能测试与分析
控制端控制流量发生仪发送 1000Mbit,长度分别为128、512 和 1024 字节的数据包,在被测试主机上分别采用 Libpcap,PF_RING和本文捕包模型接收测试流量。图4显示了当丢包数为零时各个包捕获方式可以接收的最大流速率。
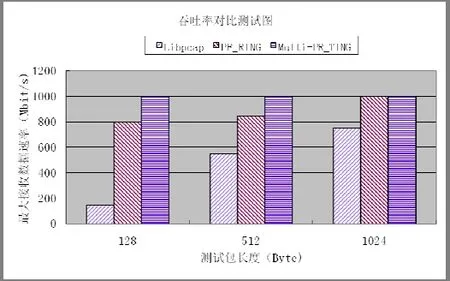
图4 吞吐率对比测试图
分析图4的结果可以得出:在 1024 字节、512字节和128字节,1000Mbit 的链路环境下,Multi-PF_RING和PF_RING 接收速率没有什么区别。
3.2.2 CPU使用率测试与分析
CPU 空闲率是衡量包捕获接口的重要指标,空闲率高的CPU 可以有更多的时间用来做与应用更加相关的工作,控制端控制流量发生仪发送 100Mbit 至 1000Mbit,字节长度为512字节的链路流量。
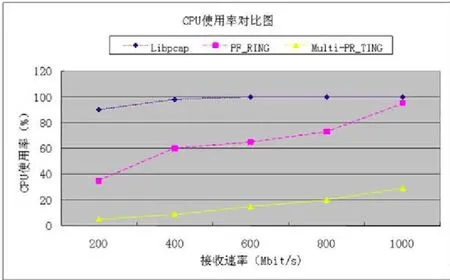
图5 CPU使用率对比图
分析图 5结果可以得出:同等接收速率下,Multi-PF_RING的CPU使用率最低。即使在1000Mbit/s时,CPU仍然有 70%左右的空闲率,可以让 CPU有足够的计算资源对数据包进行处理。
3.3 功能测试与分析
控制端控制流量发生仪发送 IP 包头地址轮转变化的IP 包,在测试服务器端观察 Multi-PF_RING接收数据包的情况,发现测试服务器接收的 IP 包与流量发生仪发送的 IP包内容一致,验证了程序的正确性;每个核心收到的链路数据是完整的,验证了程序对数据包的分发是符合应用逻辑的。
4 结束语
本文首先提出了一种基于多核架构和多收发队列的包捕获模型,然后对包捕获模型中涉及的核心技术进行了详细介绍和分析,并结合本模型捕包的需要对 PF_RING的接口进行了优化。实验结果表明,本文设计的 Multi-PF_RING 模型在保持高吞吐量的同时,具有更低的CPU使用率,给CPU留出了足够的资源进行数据包的处理,并且保证了同一链接的数据始终被分发到一个CPU核心上。本文的不足之处是没有考虑负载均衡的情况,当链接数目较少或者同一链接数据超多的情况下,会造成个别CPU核心超负荷运转而其它核心闲置的情况,后期会进一步研究负载均衡的问题。
[1]张显,黎文伟.基于多核平台的数据包捕获方法性能评估[J].计算机应用研究.2011.
[2]孙江.基于多核处理器的普适性报文捕获技术研究[D].解放军信息工程大学.2011.
[3]笱程成.基于多核架构的高速 IP包捕获技术研究[D].解放军信息工程大学.2010.
[4]http://www.ntop.org/products/pf_ring.
http://code.google.com/p/kernel/wiki/NetScalingGuide.
