基于数据挖掘的渤海湾水生态环境特性研究
2013-08-14向先全王海波路文海杨翼陶建华
向先全,王海波,路文海,杨翼,陶建华
(1.国家海洋信息中心,天津 300171;2.天津大学 环境科学与工程学院,天津 300072)
随着包括遥感在内的现代化监测技术的发展和监测手段的多样化,水生态环境数据的数量、覆盖范围和复杂性都在飞快地增长。如何科学、有效地利用这些数据,从中获取潜在有用的信息,成为水生态环境研究的重要问题。因此,需要一种从大量数据中去粗存精、去伪存真的技术,数据挖掘技术就是人们长期对数据库技术进行研究和开发的结果,是信息技术自然演化的结果(魏红宇等,2008)。国内外关于数据挖掘技术在海洋领域的应用研究已经取得了许多实质性的进展。Bridges等(1999)利用海洋数据源开展了分类规则挖掘的研究;Kitamoto(2002)对海洋遥感图像进行了聚类分析研究;马超飞等(2003)针对遥感图像的关联规则挖掘进行了深入研究;夏登文等(2005)利用海洋数据仓库开展了数据挖掘技术方法的研究;宁勇(2008)将数据挖掘技术应用于海洋环境在线监测及赤潮灾害智能预警系统中,取得了较好的效果。
渤海湾是位于渤海西侧的一个半封闭淤泥质浅水海湾,海水交换能力和自净能力很弱,近岸海域水体的富营养化和赤潮频繁发生(向先全 等,2011)。近年来,随着卫星遥感技术的快速发展,其在近岸海域生态环境研究中应用广泛(Takahiro et al,2007)。因此,本文以渤海湾为研究背景,利用海洋环境遥感数据,综合采用多种数据挖掘技术对渤海湾的水生态环境特性进行研究。
1 研究方法
数据挖掘覆盖的算法很广,在特定的问题中,数据挖掘的分析方法有一定的区别,这主要取决于数据的类型和规模,以及问题求解的目标。常用的数据挖掘分析方法包括:聚类分析、关联分析和决策树分析等(廖芹等,2010)。
聚类分析是对一群不知道类别的观察对象按照彼此相似程度进行分类,达到“物以类聚”的目的。主要是用数学的方法研究给定对象的分类,把一个没有类别标记的样本集按某种准则分成若干个子集(类),使相似的样本尽可能归为一类,而不相似的样本尽量划分到不同的类中。聚类分析的算法可分为:分裂法、层次法、基于密度方法、基于网格方法、基于模型方法等。
关联分析就是要发现关联规则,找出给定数据集中数据项之间的联系,发现项目集或属性之间的相关性、关联关系。一个典型的关联规则是“在购买面包和黄油的顾客中,有90%的人同时也买了牛奶”(面包+黄油=>牛奶)。一般用信任度和支持度来描述关联规则的属性。设D是一个事务数据库,其中每一个事务由一些项目构成,项目的集合简称项目集,项目集X的支持度是指在事务数据库D中包含项目集X的事务占整个事务的比例,即项目集X在总事务中出现的频率,记为sup(X),一般定义为

可信度是指项目集X出现,使项目集Y也出现的事件在总事务中出现的频率,记为conf(Y|X),一般定义为

支持度可发现频率出现较大的项目集,而可信度可发现频率较大的关联规则,体现项目集在另一项目集影响下相对总事务所占的比重。关联分析的目的是从已知的事务集中产生数据项集之间的关联规则,同时保证规则的支持度和信任度大于用户预先指定的最小支持度和最小信任度。
决策树学习算法是以一组样本数据集为基础的一种归纳学习算法,着眼于从一组无次序、无规则的样本数据中推理出决策树表示形式的分类规则。决策树是类似于流程图的一个树状结构,由一个根节点、一系列内部节点(分支节点)以及终极节点(叶节点)组成。每个非叶节点表示对一个属性的测试,每个分支对应于一个输出;每个叶节点表示一个判定的类别。决策树学习算法最大的优点就在于它在学习过程中不需要了解很多的背景知识,只从样本数据集提供的信息就能够产生一棵决策树。
2 研究区域及数据来源
本文采用的卫星遥感数据来源于国家卫星海洋应用中心,使用的是国家海洋一号卫星HY-1B的遥感数据。图1为该卫星遥感水体叶绿素浓度的一个专题图示例。通过遥感影像反演,提取出海洋生态环境的一些指标因子,其数据格式为HDF(Hierarchical Data Format)格式。
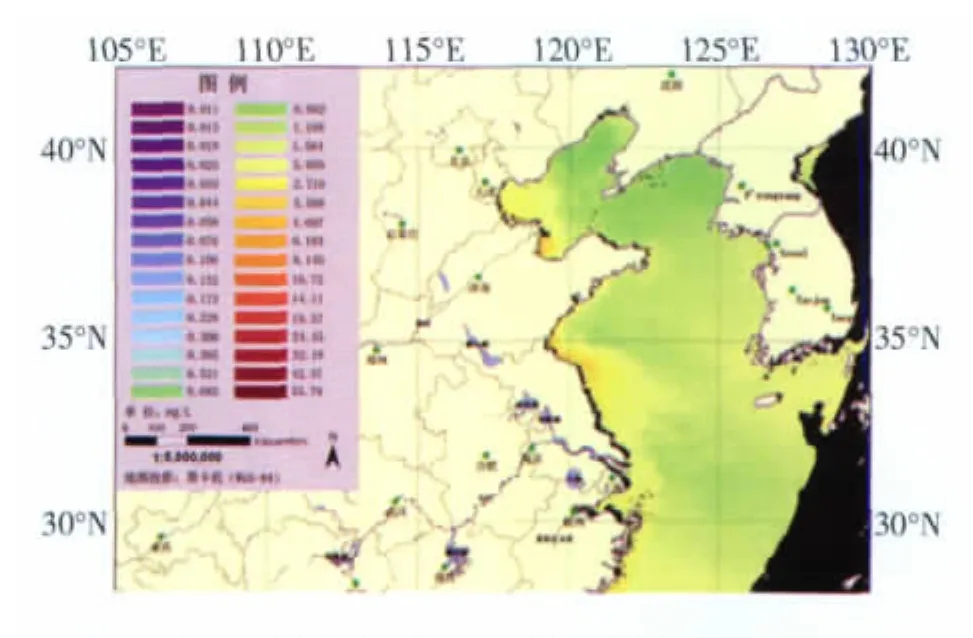
图1 卫星遥感水体叶绿素浓度的专题图示例
卫星遥感探测的生态环境指标主要有4个:叶绿素浓度(CHL)、悬浮泥沙浓度(Suspended Sediment Concentration,SSC)、海水透明度(Secchi Disk Depth,SDD)及海表温度(Sea Surface Temperature,SST),单位分别为μg/L、mg/L、m和℃。利用美国资源系统研究所(ESRI)开发的ArcGIS软件中的功能模块,读取HDF文件,然后转化为栅格数据形式。HY-1B卫星图像的分辨率为0.01°×0.01°,约为1 100 m×1 100 m。本文的研究中,渤海湾覆盖的网格数为11 106个,如图2所示。

图2 渤海湾覆盖的网格
通过HY-1B卫星,每日可获取2幅生态环境因子的遥感影像。本文采用的水生态环境遥感数据,其时间范围为2008-2009年。2008、2009年渤海湾各网格中水生态环境各指标的遥感数据采用该网格中该指标的年均值计算而来。由于阴雨等天气原因,卫星遥感并不能实时地检测到地面(海面)的信息,故在原始的遥感数据中,欠缺了某些空间位置或某些天的遥感值。本文对于图像中未检测的像素,采用剔除方式进行处理。
3 研究结果与讨论
3.1 基于k-means算法的渤海湾水生态环境聚类分析
通过聚类分析可以把指标值大小相似的网格聚在一起,将渤海湾分成不同的区块,通过研究各区块的指标值可更清楚地了解渤海湾水生态环境的一些特性。本节利用聚类分析的k-means算法对2008和2009年渤海湾水生态环境特性进行研究,k-means算法是一种基于划分的聚类方法,是最常用和最知名的聚类算法。利用k-means算法分别对2008和2009年的渤海湾遥感数据进行聚类分析。由于各指标的单位不同,而且各指标值的数量级也有差异,故聚类之前对各指标进行标准化处理。
原始的遥感数据为 Xi=(xi,1,…,xi,j,…,xi,m),通过公式(3)标准化为:Zi=(zi,1,…,zi,j,…,zi,m),其中i表示渤海湾网格数,i=1,2,…,n,n为11 106;j表示遥感指标数,j=1,2,…,m,m为4。
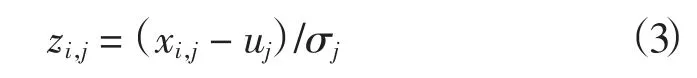

其中:dij表示xi到cj的欧氏距离,cj表示聚类中心。
通过计算发现当取k=3时,聚类的效果最好,此时将遥感数据在渤海湾空间上共聚成3类。2008和2009年的聚类结果如图3所示,蓝色为第Ⅰ类;绿色为第Ⅱ类;黄色为第Ⅲ类。表1给出了各聚类中心的指标值。第Ⅰ类主要分布在渤海湾东北部,表现出叶绿素浓度低、悬浮泥沙浓度低、透明度高和海表温度较低的特征。第Ⅲ类主要分布在渤海湾西南部,表现出与第Ⅰ类相反的特征。第Ⅱ类的聚类中心各指标值在第Ⅰ和第Ⅲ类聚类中心值的中间,同时在空间上也处于中间过渡区域。

图3 渤海湾遥感数据的聚类图

表1 渤海湾遥感数据的聚类中心
第Ⅰ类区域的分布位置靠近渤海中部,离近岸较远,受陆源影响较小,因此表现出悬浮泥沙浓度低、叶绿素浓度低等特征。对于第Ⅲ类区域,王勇智(2006)和于炜(2011)指出受风浪、潮流以及环流等影响,渤海湾南部始终维持悬浮物浓度高,同时由于悬浮物对氮、磷等营养盐的吸附作用,促进浮游植物的生长(毕玲玲,2006),加上陆源营养盐的作用,因此在渤海湾近岸西南部出现悬浮泥沙浓度高、叶绿素浓度高等特征。
3.2 基于Apriori算法的渤海湾水生态环境关联分析
通过关联分析,提取出大于最小支持度和最小可信度的指标之间的关联规则,可以了解渤海湾各生态环境指标之间的联系。Apriori关联规则算法是一种最有影响的挖掘布尔型关联规则频繁项集的基本算法,货篮分析就是采用这种算法进行的。
关联规则挖掘通常适用于指标值为离散值的情况。由于生态环境遥感数据库中的指标值是连续的数据,故在关联规则挖掘之前应该进行适当的数据离散化(即把某个区间的值映射为某个值)。本文采用聚类离散化方法,利用3.1节分析的聚类中心对各指标的遥感数据进行离散处理,将每个指标按离中心的远近分成三类,各指标值从小到大分别标记为“低”、“中”、“高”。
利用Apriori算法对离散化处理后的渤海湾遥感数据进行关联分析。取最小支持度min_sup为0.08,最小可信度min_conf为0.5,关联分析的结果见表2和表3。
表2显示了从渤海湾遥感数据中提取的极大频繁集,2008和2009年的极大频繁集中都包括:高CHL、低 SDD、高 SSC及高 SST;中 CHL、中SDD、中SSC及中SST。表明它们在整个渤海湾遥感数据集中出现频率较大,表现出较强的关联性。需要指出的是,获得的关联规则并没有包含各指标的内在机理性联系,因此其是否具有因果关系还需进一步验证。

表2 遥感数据关联分析的极大频繁集

表3 遥感数据的关联规则及可信度
表3给出了Apriori算法计算的渤海湾遥感数据的关联规则及其可信度情况。从大于0.9可信度的情况来看,2008年遥感数据有两条关联规则“高SSC,高SST,高CHL=>低SDD”和“高SSC,中SST,高CHL=>低SDD”,联合这两条规则(至少从数据上)可表明:高SSC、高CHL以及SST不低的时候SDD就会低。2009年遥感数据中关联规则“高 SDD,低 SSC,低 SST=>低 CHL”和“低SDD,高SSC,高SST=>高CHL”的可信度也大于0.9。对2008年和2009年各指标因子的年均值进行相关性分析,两年的相关性分析结果都表明了CHL与SSC和SST有较好的正相关关系,而与SDD有负相关关系。以上几条关联规则与相关性分析的结果相互吻合。
3.3 基于CART算法的渤海湾水生态环境决策树分析
决策树学习是当前应用最广泛的归纳推理方法之一,对噪声数据也有比较好的鲁棒性,且能够直接得到学习的析取表达式。由于CART算法只产生二叉,计算速度快,且适合于混合数据问题的处理,因此本文采用CART算法对渤海湾生态环境遥感数据进行分析。
由于叶绿素浓度是表征浮游植物生物量的重要指标之一,了解叶绿素浓度可掌握水体初级生产力情况和富营养化程度。因此,本文水生态环境的决策树分析以叶绿素浓度为标签向量,其它3个变量——SDD、SSC、SST为属性向量对叶绿素浓度进行分类研究。叶绿素浓度采用3.2节的聚类离散化方法,离散为3个值:“低CHL”、“中CHL”、“高CHL”。而对其它3个指标不做离散化处理,仍为连续值。
利用CART算法对2008和2009年渤海湾生态环境遥感数据进行决策树分析。在运算过程中,构建分类树第一步骤时产生的最大树Tmax时,分支有很多个,共有1千余个,其准确率也较大(2008年准确率为89.35%;2009年准确率为90.93%)。但是由于过多的分支使得分类较困难,也失去了决策树快速分类的优势,因此需要进行一定的修剪操作。通过一次修剪后所构建的决策树如图4所示。图中决策树各非叶节点右侧的不等式表示该节点的测试准则,左分支表示满足测试属性,右分支表示不满足测试属性。SDD、SSC和SST的单位分别为m、mg/L和℃。
通过一次修剪后,2008和2009年渤海湾水生态环境数据的决策树具有了一定的可读性,叶绿素浓度的分类准确率分别为74.29%、79.18%。虽然其准确率有所降低,但分支数大大减少,也避免了“过拟合”的问题,可进行实际情况的分类操作。为进一步地提高决策树的可读性以及便于分析,对以上两个决策树进行了二次剪枝操作,剪枝后的决策树如图5所示。
从图中可以看出,通过二次修剪后,得到的水生态环境数据决策树分支较少,可读性很强。这两棵决策树对2008和2009年渤海湾叶绿素浓度分类的准确率分别是72.01%、76.94%,准确率较高。与第一次修剪后决策树的准确率相比,下降得并不明显。

图4 2008和2009年渤海湾水生态环境数据的决策树(一次修剪)
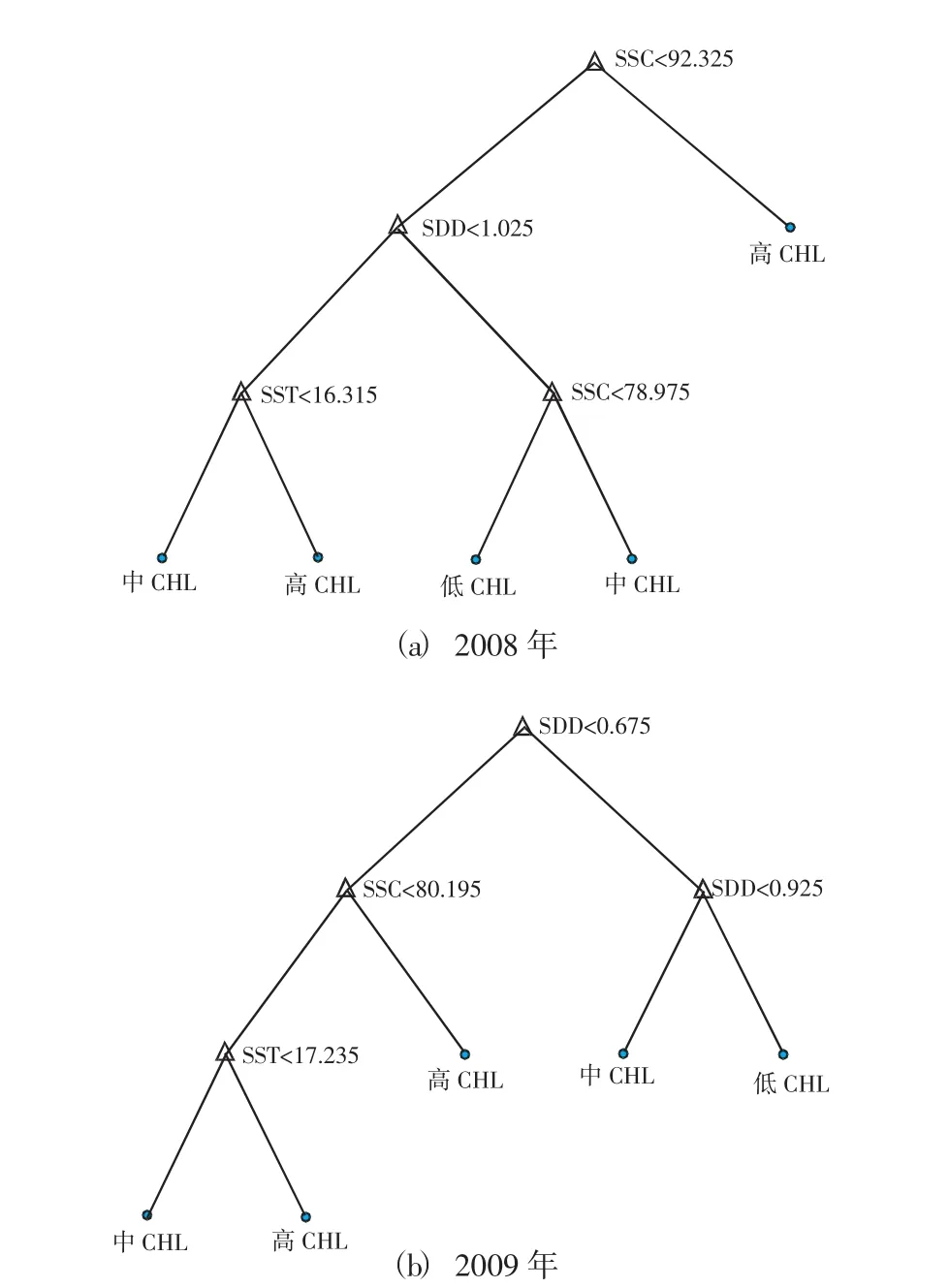
图5 2008和2009年渤海湾水生态环境数据的决策树(二次修剪)
这两棵决策树都含有5个叶节点,可分别对应5个分类准则。如2008年的最简洁的一个分类准则“SSC大于或等于92.325 mg/L时,叶绿素浓度较高”;2009年的一个分类准则“SDD小于0.675m,且SSC大于或等于80.195 mg/L时,叶绿素浓度较高”。其它的分类准则可类似地得到。通过这些分类准则可对渤海湾遥感叶绿素浓度进行快速地分类判别,以及进行相应的特性研究。
4 结论
本文对海洋数据挖掘的理论和方法进行了研究,以渤海湾为研究背景,利用海洋环境卫星遥感数据,对渤海湾水生态环境特性进行聚类分析、关联分析和决策树分析等一系列的数据挖掘研究,得出了如下的结论:
(1)利用k-means算法对2008和2009年渤海湾生态环境的年均遥感数据分别进行了聚类分析。将渤海湾遥感数据共聚成3类,聚类结果表现为较强的空间分布特征。第Ⅰ类主要分布在渤海湾东北部,表现出低CHL、低SSC、高SDD和低SST的特征。第Ⅲ类主要分布在渤海湾西南部,表现出与第Ⅰ类相反的特征。第Ⅱ类聚类中心的各指标值在第Ⅰ和第Ⅲ类聚类中心值的中间,同时在空间上也处于中间过渡区域。
(2)利用Apriori关联规则算法对聚类离散化处理后的渤海湾生态环境遥感数据进行了关联分析。2008和2009年的极大频繁集里都包括了“高CHL、低SDD、高SSC、高SST”和“中CHL、中SDD、中SSC、中SST”。表明它们在整个渤海湾遥感数据中出现的频率较大,表现出较强的关联性。通过关联分析还得出了渤海湾遥感数据的一些关联规则及其可信度情况。
(3)利用CART算法对2008和2009年渤海湾生态环境遥感数据进行了决策树分析。以聚类离散化处理后的叶绿素浓度为标签向量,其它三个变量——SDD、SSC、SST为属性向量对叶绿素浓度进行分类研究。通过两次修剪后,分别得到了分支少、可读性强的2008和2009年渤海湾生态环境遥感数据决策树。这两棵决策树都含有5个叶节点,可分别对应5个分类准则。通过这些分类准则可对渤海湾遥感叶绿素浓度进行快速地分类判别,以及相应的特性研究。
需指出的是,数据挖掘得出的结论来源于数据本身,而其中内在联系还需结合海洋生态环境的内部作用机理加以分析。本文将数据挖掘方法引入到海洋生态环境的研究中,可为日益增长的海洋生态环境海量数据分析提供新手段、新思路。
致谢:本文采用的卫星遥感数据是国家卫星海洋应用中心提供的海洋一号卫星HY-1B的遥感数据,在此对国家卫星海洋应用中心表示感谢。
Bridges S,Hodges J,Wooley B,et al,1999.Knowledge discovery in an oceanographic database.Applied Intelligence,11(2):135-148.
Kitamoto A,2002.Spatio-temporal data mining for typhoon image collection.Journal of Intelligent Information Systems,19(1):25-41.
Takahiro Iida,Sei-Ichi Saitoh,2007.Temporal and spatial variability of chlorophyll concentrations in the Bering Sea using empirical orthogonal function(EOF)analysis of remote sensing data.Deep Sea Research Part II:Topical Studies in Oceanography,54(23-26):2657-2671.
毕玲玲,2006.胶州湾悬浮物组成特征及对营养盐的吸附解吸作用研究.学位论文,青岛:中国海洋大学.
廖芹,郝志峰,陈志宏,2010.数据挖掘与数学建模.北京:国防工业出版社.
马超飞,刘建强,2003.遥感图像多维量化关联规则挖掘.遥感技术与应用,18(4):243-247.
宁勇,2008.数据挖掘在海洋环境在线监测及赤潮灾害智能预警系统中的应用.济南:山东大学.
王勇智,2006.渤、黄、东海悬浮物浓度及输运季节变化的数值模拟.学位论文,青岛:中国海洋大学.
魏红宇,张峰,李四海,2008.海洋数据挖掘技术应用研究.海洋通报,27(6):82-87.
夏登文,石绥祥,于戈,等,2005.海洋数据仓库及数据挖掘技术方法研究.海洋通报,24(3):60-65.
向先全,陶建华,2011.基于GA-SVM的渤海湾富营养化模型,天津大学学报,44(3):215-220.
于炜,2011.渤海表层悬浮物分布变异规律的研究.学位论文,青岛:中国科学院海洋研究所.
