一种分布式的舆情分析系统架构
2013-08-10黄宇鹏郝志峰蔡瑞初肖晓军
黄宇鹏 ,袁 畅 ,郝志峰 ,蔡瑞初 ,肖晓军 ,卢 宇
(1.广东工业大学计算机学院 广州 510006;2.广州优亿信息科技有限公司 广州 510630)
1 引言
随着互联网用户数量的快速增长,网络越来越成为人们获取与发布信息的主要渠道[1],特别是社交网络(如Twitter、Facebook、微博等)的出现,使得人们获取和发布信息更加快速和方便。与此同时,网络上也产生大量对各行各业的舆论信息,这些信息可能包括正面评论,也有可能包含负面议论,有可能会对个人、企业甚至是整个社会产生重要的影响。另外,社交网络数据中还潜在着巨大的商业价值。例如,对于电信企业来说,客户的社交网络分析(SNA)是非常有价值的,通过测算识别客户与客户之间关系所形成的圈子以及圈子中各客户角色的判定(领袖者是谁,追随者是谁),形成企业对各个客户影响力和价值的判断,在此基础上,利用对这些圈子、角色和影响力的认识,帮助企业实现相关营销活动或产品套餐的推广,提高企业营销和运营管理的效率[2]。
面对互联网数据的不断增多以及社交数据的出现,如何利用计算机和网络技术设计相应的舆情系统,以能够快速有效地收集、分析这些数据,并生成有用的舆情汇报信息,是许多学者关心的问题。目前,国内外学者在舆情分析方面做了许多相关的工作。
[3]通过对系统的业务流程和功能进行分析,给出了舆情分析系统的组成模块,分别为舆情信息源选择、舆情信息采集、舆情信息分析和舆情信息报告,并由此把系统架构设计为舆情搜索引擎和舆情分析引擎两大部分。参考文献[4]中,根据系统的需求,分析整个数据处理的流程,将系统分为两个模块:网络爬虫模块和舆情分析模块。参考文献[5]采用3层架构,分别为数据资源层、系统分析层和应用层。大多数舆情分析系统都考虑了数据的收集和分析,但如何应对海量数据的处理也是系统设计所必须考虑的问题。在海量数据处理方面,学者们也做了许多相关的工作。闻剑峰和石屹嵘[6]提出以分布式计算实现电信数据分析业务加速的研究,并对比传统的方案做了对比,达到了很好的加速效果。黎宏剑、刘恒等[7]基于Hadoop分布式云平台对电信的海量数据进行处理,解决了电信运营商对海量电信数据管理和分析难的问题。可见,采用分布式计算技术(如MPI),建立并行计算环境,成为提升系统分析效能的主要手段[8]。
本文以分布式平台为基础,搭建了舆情分析系统的架构,以解决海量数据的存储与分析问题。架构适用于不同应用的数据分析,并能够集成多种数据分析算法,为舆情分析应用提供了一个宽广的空间。从多个方面对架构进行分析,根据分析结果进行设计,最后针对新浪微博,给出架构的实例应用,验证了架构的可行性。
2 系统架构
2.1 架构分析
目前大多数舆情分析系统都是基于某类特定算法实现的,并且系统的设计大多也基于单机模型。对于一些应用,可能需要多种算法进行分析,或者面对庞大的数据量,现有的系统难以进行处理或者扩展。
针对现有舆情系统的不足,分布式舆情分析系统架构的设计从以下几个方面进行分析。
·可扩展性:对于新的需求和功能,能够很好地添加到系统中。系统能够容纳多种分析算法,新的算法可以方便地移植到系统中。这些都不需要改变系统的架构。
·可维护性:架构中各个模块之间的耦合性低,一个模块的改变不会影响到其他模块,模块之间通过定义的接口进行通信。后续对于模块的优化可以单独进行。
·适用性:对于不同类型应用的分析,架构不需要改变或者做适当的调整就可以直接使用,也可以把多种应用的分析集成在一起。
·合理性:根据任务的复杂度,合理分配资源进行处理。例如,对于简单的任务,用单线程进行处理;对于数据规模大或者复杂性高的任务,进行分布式并行处理,以提高系统的整体效率。
·部署:各个模块能够单独进行部署,当网络环境发
生变化时,只需要改变相应的IP地址和端口号。
·实时性:能够保证系统及时收集到实时的数据,并且能够快速地进行分析处理。对于用户的请求,能够及时做出响应。
·可用性:系统以Web页面的形式向用户提供大量的可视化界面,保证用户能简单地使用系统。
2.2 架构设计
考虑以上分析,把系统分成三大模块,分别为爬虫模块、Web模块、分布式平台模块,如图1所示。
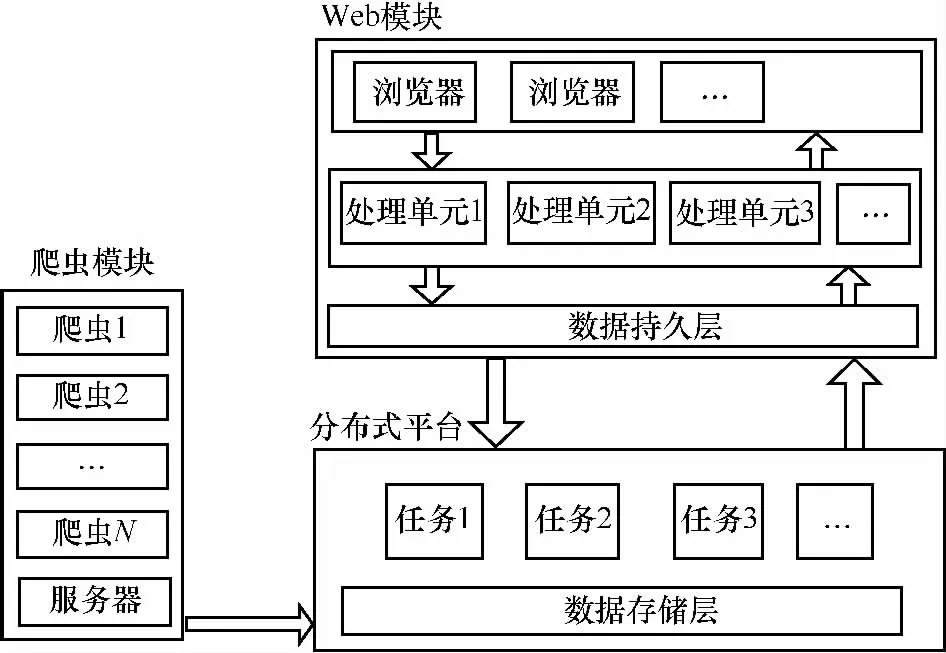
图1 系统架构
2.2.1 爬虫模块
对于舆情分析系统来说,数据是非常重要的,而爬虫模块的主要功能是数据的收集。为了能够高效地爬取数据,系统采用并行爬取策略,由一台服务控制器和多个爬虫客户端组成。服务控制器负责与客户端连接以及每个客户端爬取时间的控制;另外,还有一个任务分配器,负责给每个客户端分配爬取任务。对于爬取的数据,经过格式转换器,按照一定格式存储到分布式平台。爬取流程如图2所示。

图2 爬取流程
2.2.2 Web模块
考虑系统的可扩展性、可用性等,将Web模块分为表现层、业务逻辑层和数据访问层,并采用MVC设计模式,每层所实现的功能都不相同,表现层与业务逻辑层的分离更加明确。表现层主要实现数据可视化展示以及为用户提供一个良好的操作界面;业务逻辑层主要实现两类逻辑处理,第一类是使用用户相关的逻辑处理,第二类是复杂度较低的数据处理,如少量数据的统计分析、简单算法的数据处理等;数据访问层主要负责对用户相关的数据进行持久化操作。
2.2.3 分布式平台模块
采用分布式平台,主要针对大数据量的处理,因为单机系统已经无法满足大量数据处理的要求。舆情系统的核心在于数据的存储、分析以及检索。对于海量数据,分布式平台提供了分布式的存储方案;对于复杂的任务,能够进行并行计算,提高处理效率,以在短时间内产生舆情信息。该模块基于分布式平台实现了数据的存储、检索(搜索引擎)以及数据量大或者复杂度高的计算。在舆情系统中,该模块属于核心部分,对外接收爬虫模块爬取的数据,同时接收Web模块的请求并向其提供服务。
3 架构应用实例
随着社交网络的出现,网络产生了大量的信息。在国内,就新浪微博来说,每天产生的微博数量有过亿条,而且这种数据具有更新快和传播快等特点。为了能够及时对这些数据进行分析处理,基于上述系统架构的设计,实现了一种舆情分析系统。系统实现了对新浪微博的监控、预警、分析和引导四大功能,每个功能模块包括若干子功能,如图3所示。
系统的架构如图4所示,开发涉及的技术和工具包括MapReduce、Lucene、IKAnalyzer、thrift、Java、Spring、Struts2.0、JavaScript、HTML、CSS 等,数据存储使用了 HDFS、Hbase、MySQL、Redis等,开发环境是 Linux+Hadoop+MyEclipse+Tomcat。

图3 系统详细功能
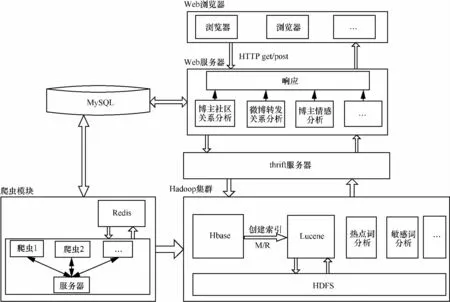
图4 系统架构
3.1 Hadoop分布式集群
Hadoop是一个开源的分布式系统基础架构,由Apache基金会开发。对于该框架,用户可以在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群的高速运算和存储功能[9]。与其他分布式计算的不同主要体现在以下几点[10]:
·方便,运行在由一般商用机构成的大型集群上;
·顽健,致力于在一般商用硬件上运行,其架构假设硬件会频繁地出现失效,可以从容地处理大多数此类故障;
·可扩展,通过增加集群节点,可以线性地扩展以处理更大的数据集;
·简单,允许用户快速编写出高效的并行代码。
基于Hadoop的分布式文件系统(HDFS)和分布式数据库(Hbase)为海量数据的存储提供了很好的解决方案。HDFS有着高容错性的特点,并且用来部署在低廉的硬件上,提供高吞吐量来访问应用程序的数据,适合有着超大数据集的应用程序;Hbase是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用Hbase技术可在廉价PC服务器上搭建起大规模结构化存储集群。
Hadoop的核心部分MapReduce提供一种可用于数据处理的编程模型,能够很好地和HDFS、Hbase结合编写处理大量数据的并行处理程序。
基于Hadoop的以上优点,系统使用Hadoop集群作为分布式平台进行数据的存储、检索以及复杂任务的计算。在系统的实现上,Hbase用于爬取数据的存储,包括用户的信息和微博的信息,并向系统提供检索服务。基于Hadoop使用Lucene搭建搜索引擎,编写MapReduce程序创建索引,并将索引表写到HDFS上。对于实时爬取的微博,能够及时地创建索引,提供实时的检索。在大量微博中对热点词和敏感词的分析,也基于MapReduce的并行功能实现。
集群由5台机器组成,其中一台为主用机器,配置为CPU双核、内存4 GB、硬盘100 GB,另外4台配置均为CPU双核、内存4 GB、硬盘100 GB。
3.2 爬虫模块
爬虫模块使用新浪微博提供的API获取数据,由于新浪微博对每个IP地址的访问在时间和次数上都做了限制。这样,对于一台机器来说,每个小时获取到的数据量是比较少的。基于架构的设计,采用多台机器并行爬取的策略可以解决个问题。对于新浪微博来说,爬取的数据包括博主信息(如ID、昵称、好友、粉丝、微博数等)和微博信息(如ID、内容、转发数、评论数等)。爬取过程为:使用微博账号登录→授权→获取分配的任务→开始获取数据→数据格式转换→写入数据库。爬取过程中可能会出现重复爬取博主信息和微博信息,系统采用Redis内存数据库进行控制,把已经爬取过的博主ID和微博ID存到Redis中,如果爬取到博主或微博已在Redis中,则丢弃该条信息。对于爬取的数据,以json格式存在,进行相应的转化后以对象形式(二进制编码)存到Hbase上,Hbase表的结构设计见表1。另外,爬虫模块还提供对特定微博或博主信息的爬取,以实时监控某条微博或者博主的动态。

表1 Hbase表的结构设计
3.3 Web模块
Web模块采用B/S模式开发,前端使用HTML、JavaScript和CSS等技术,后台基于Struts2+Spring3框架搭建。前端使用图形的方式对微博的转发关系、用户的好友关系、传播趋势等进行可视化展示;后台通过Struts2的action响应浏览器的请求,然后通过调用Spring提供服务,最后把结果返回到浏览器。Struts2是一个使用MVC的开发模式框架,使得业务逻辑层与表现层之间的功能变得更加明确,从而也更加容易维护。使用Spring框架实现数据的持久化,并提供相应的服务接口,同时也与Hadoop分布式集群进行通信。使用Spring的annotation进行开发,使得代码简洁、可维护性好。对于使用用户的信息以及操作的相关信息,则保存在MySQL数据库中。
Web模块部署到Tomcat服务器上运行,可以对关键词或者博主名进行搜索,对搜索的关键词和博主进行监控。对搜索返回的微博,可以查看该微博的转发关系、来源分布、区域分布、随时间变化的转发次数趋势,也可以关注博主的信息,包括博主的情感倾向、所发微博中频繁出现的词以及社区关系等。对于用户关注的关键词和博主,在每次登录系统时,如果出现与关注信息相关的微博,系统会自动产生预警。页面还对微博中近段时间(60 min,30 min,15 min)出现的热点词进行敏感词统计分析,以及时发现微博中出现的热点信息。系统还允许用户设定任务,用户可以设定相关的条件,当系统检测到条件满足时,自动执行用户的任务。
3.4 thrift通信
thrift是一个软件框架,用来进行可扩展且跨语言服务的开发[11],允许定义一个简单的定义文件中的数据类型和服务接口,以作为输入文件,编译器生成代码用来方便地生成RPC客户端和服务器通信的无缝跨编程语言[11]。
在系统的Web模块和Hadoop集群之间,采用thrift进行通信。通过thrift定义Web模块调用的接口,能够很好地将这两个模块独立开来,这样就保证了系统有很好的可扩展性和可维护性。例如,系统需要加入对博主的情感分析功能时,首先在Hadoop集群模块添加一个搜索博主相关信息的方法,然后在thrift服务器中定义一个向Web模块提供服务的接口,该接口调用搜索博主相关信息的方法,鉴于返回博主个人的数据量较小,在Web模块中实现情感分析算法,算法的输入数据通过调用thrift服务器中的接口获得,最后在Web页面上设计相关的图形展示分析结果。当需要添加一个新的功能时,只需要在每个模块中添加相应的实现方法或接口即可,具有很好的扩展性。由于thrift通过接口向Web模块提供服务,当Hadoop集群要对某些方法进行修改或者优化时,不会影响到Web模块,具有很好的可维护性。在部署时,thrift服务器可以进行单独部署。
4 结束语
针对如何能够有效地获取和分析互联网不断增加的数据,本文提出一种分布式的舆情分析系统架构。该架构结合分布式技术,能够有效地对网络中的海量数据进行存储和分析。在分布式平台上,进行了Web应用开发。在这个架构中,包含三大模块,分别为爬虫模块、Web模块和分布式平台。以分布式平台为核心,将爬虫模块和Web模块结合起来,数据从爬虫模块流向分布式平台,经过分析处理,向Web模块提供服务。最后,针对社交网站新浪微博,给出了架构的实例应用,验证了架构的可行性、可扩展性等。
参考文献
1 张姝,赵铁军,郑德权等.基于浅层分析的多文档自动文摘技术.哈尔滨工业大学学报,2007,39(7):1102~1103
2 漆晨曦.电信企业大数据分析、应用及管理发展策略.电信科学,2013,29(3):12~16
3 刘磊.网络舆情分析系统研究.情报探索,2010(10):106~107
4 邹星汉.互联网舆情信息采集与分析系统的设计和实现.哈尔滨工业大学博士学位论文,2010
5 何顺兰,王兴起,胡宏宇等.多媒体舆情分析系统设计与研究.杭州电子科技大学学报,2010,30(5):174~176
6 闻剑峰,石屹嵘.以分布式计算实现电信数据分析业务加速的研究.电信科学,2012,28(2):23~25
7 黎宏剑,刘恒,黄广文等.基于Hadoop的海量电信数据云计算平台研究.电信科学,2012,28(8):80~81
8 何忠育,王勇,王瑛等.基于分布式计算的网络舆情分析系统的设计.警察技术,2010(3):19
9 Hadoop百度百科.http://baike.baidu.com/view/908354.html
10 Lam C.Hadoop in Action.韩翼中译.北京:人民邮电出版社,2011
11 Thrift百度百科.http://baike.baidu.com/view/1698865.html
