基于固态硬盘的在线全文索引管理策略研究
2013-07-25聂玉峰陈雪帆
聂玉峰,陈雪帆
(1.武汉科技大学城市学院信息工程学部,湖北武汉430083;2.华中科技大学计算机学院,湖北武汉430074)
0 引言
全文检索是指以文本为检索对象,允许用户以自然语言根据资料内容而不仅是外在特征来实现信息检索的技术。进行全文检索首先需要构建索引,目前最常用的索引结构是倒排索引,它由一列术语及其记录列表组成,记录列表中的每一项记录了该术语在某篇文档中的一次出现信息,主要包括文档编号、位置等。在检索时,如果命中了某术语,便可以通过其记录列表快速地定位包含了该术语的文档并进行结果排序和生成摘要等操作。文献[1]详细介绍了基于倒排索引的全文检索模型。
倒排索引数据量巨大,通常存储在磁盘中。但磁盘的读写性能与CPU和内存之间的差距较大,使全文检索系统存在磁盘瓶颈。幸运的是基于闪存的固态硬盘 (solid state drivers,SSD)作为一种纯电子设备,读写速度远胜于磁盘。容量也在不断增大,OCZ已经推出了1TB的SSD产品[2]。当前SSD已被视为取代磁盘的理想选择,全文检索系统也不可避免地需要移植到SSD上。然而现有的索引管理方法都是基于磁盘的,直接应用在物理特性与磁盘完全不同的SSD上不仅无法充分利用SSD优异的读写性能,而且会缩短SSD的使用寿命。因此,设计针对SSD的索引管理策略对于在SSD上部署全文检索系统来说是十分关键的。为此,本文首先分析了传统的在线索引管理策略在SSD上的应用情况并指出了其缺陷。然后提出了一种完全针对SSD的在线索引管理方法:基于分块的部分合并策略。该方法避免了索引构建过程中对SSD有害的随机写操作,并利用SSD的高速随机读特性极大地减少了对SSD的写操作。最后对本文所提出的在线索引管理策略进行了实验评估,结果表明该策略能够更好地适应SSD环境。
1 在线索引管理与固态硬盘技术
1.1 在线全文索引管理
全文索引管理技术分为离线管理和在线管理两类。前者用于静态文档集。而后者则用于处理动态增长的文档集,不仅要随时更新现有索引信息,还要响应检索请求,较离线管理要复杂许多。在索引构建过程中,完整的索引信息由两部分组成,一部分在内存中,称为内存索引。另一部分则在磁盘上,称为磁盘索引。新文档产生的索引会首先被写入内存,内存索引膨胀至一定程度时,便将内存索引更新至磁盘索引中,整个过程如图1所示。目前有两种常用的更新磁盘索引的思想:原地更新以及合并更新,它们区别了两类在线索引管理策略。原地更新方法通过将术语的新的记录列表直接追加写入到磁盘中该术语已有的记录列表的后面来更新磁盘索引。合并更新方法则通过将内存索引与磁盘索引进行合并来更新磁盘索引,在合并过程中,术语已有的记录列表会被读出然后与新的记录列表一起被连续地写回磁盘上。由于磁盘的物理特性,这两种方法都尽量让同一个术语的记录列表信息在磁盘上能够连续存储,从而保证了读取索引信息的速度。
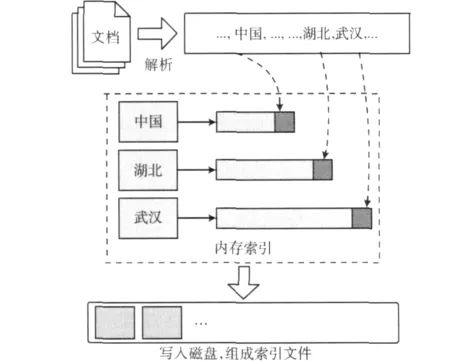
图1 索引构建过程
现有研究表明,基于合并更新的方法在索引构建速度上要优于基于原地更新的方法[3]。这是因为合并更新虽然理论上需要更多写磁盘操作,但这些写操作完全是顺序的。相反原地更新方法却会产生大量随机写磁盘操作,在实践中索引性能反倒不如合并更新。因此现有的全文检索工具如Lucene[4],一般都采用基于合并的索引管理策略。
1.2 固态硬盘技术
SSD的存储介质闪存具有完全不同于磁盘的物理特性:首先,闪存由许多块组成,每个块包含一定数目的页,读写操作以页为单位。其次,闪存不支持覆盖写,在对页进行复写时需要先擦除包含该页的整个块。擦除所需的时间比写入多一个数量级,而且每个块允许的擦除次数是有限的,一般为一万至十万次[5],超过这个次数后该块便被认为是坏块。因此,SSD专门引入了FTL技术[6]来管理闪存,它的块映射机制屏蔽了闪存特殊的存取方式,将其模拟为磁盘。此外FTL还具有损耗均衡和垃圾回收等功能。
由于擦除次数的限制,SSD的使用寿命需要密切关注,它主要受制于两个方面:首先是写操作的量,擦除是由写入触发的,减少写操作自然能够延长使用寿命。SSD厂商通常建议用户使用高档SSD来应对写密集型的应用[7]。其次是FTL,高效的FTL算法能够减轻随机写操作对闪存的影响。众所周知,随机写是不利于闪存的,不仅速度较顺序写要慢得多,而且会触发更多擦除,在使用SSD的过程中要尽量避免。
2 现有索引管理方法存在的问题与分析
本节中我们通过实验分别考察了两类索引管理策略在SSD上的运行情况,并根据实验结果指出了现有策略的不足之处。实验的硬件环境为2.0GHz处理器 (Intel Dual E2180),2GB内存,320GB的磁盘以及40GB的SSD(Intel X25-M)。数据集收集自维基百科网站[8],其中包含大约100万篇网页文档。
2.1 原地更新
在磁盘上原地更新方法的整体性能不如合并更新,而在SSD上原地更新的总体效率依然要低于合并更新。表1给出了在SSD上对两种策略的索引和检索性能进行测试的结果,其中原地更新方法来自文献 [9],合并更新方法则是常用的几何分区合并策略[10],从中可以发现两种方法的检索性能基本相同,但原地更新的索引构建耗时大约是合并更新的3.5倍。这是因为原地更新方法在索引过程中产生了大量的随机写,SSD的随机写性能虽然较磁盘有了较大提升,但还是不如顺序写。而且这些随机写显然会对SSD造成比较严重的损耗。上述问题是由原地更新方法的设计思想造成的,难以进行改进。

表1 原地更新与合并更新的性能对比
2.2 合并更新
合并更新方法效率高,写操作也是顺序的,但这类方法的缺点是写入数据量过大。表2给出了几何分区合并策略在索引管理时写入的数据量与有效索引数据量的对比,索引到50万篇文档时,几何分区合并算法实际写入SSD的数据量大约是有效数据的3.2倍,而到100万篇时已经达到了4.8倍。而过多的写入会引发大量擦除操作,影响SSD的使用寿命。
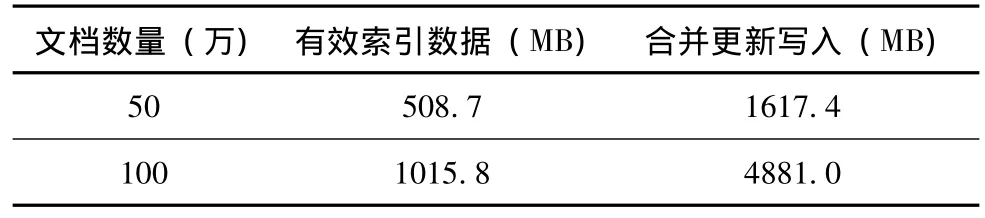
表2 写入数据量统计结果
这些额外的写入是由索引的合并产生的,目的是为了避免随机写,同时让索引在磁盘上连续存储,提高读取索引的速度。磁盘具有很长的使用寿命,因此用额外的写入来换取更高的性能是完全值得的。然而由于擦除次数的限制,现阶段SSD的使用寿命远不如磁盘,如果把合并更新方法不加改进地直接应用于SSD,大量写操作会直接造成SSD的过分损耗。
另一方面,SSD的随机读性能相对于磁盘有了极大提升,表3给出了几何分区合并策略与不合并策略分别在磁盘和SSD上的检索性能对比结果。从中可以发现在磁盘上几何分区策略的检索速度大约是不合并策略的16.5倍,但在SSD上却只有约3.3倍。这说明通过频繁合并保持索引连续存储的必要性已经大为降低了。

表3 不同设备上的检索性能对比
通过上一小节以及本小节的分析,我们发现基于原地更新的索引管理策略存在着性能低下和随机写的问题,而基于合并更新的管理策略的问题在于会产生大量额外写入。总之,传统的在线索引管理方法都不宜在SSD上直接使用。
3 基于分块的部分合并策略
3.1 设计思想
所有的在线索引策略第一步都是更新内存索引,区别只在于如何更新辅存索引。在上一节中,我们发现基于合并的方法虽然会产生额外的写入,但完全可以通过适当减少索引合并来加以改进。由此我们总结了针对SSD的索引管理策略的核心思想:利用SSD较高的随机读速度改进合并更新策略,对高频词索引要积极合并,保证其检索效率,同时减少意义不大的低频词索引的合并,从而在不影响性能的前提下,减少对SSD的写操作。
上述思想是考虑到两个方面的因素:首先,文档集内不同的术语被检索到的频率有着极大的差别,高频词记录列表数据量较大,被检索到的频率远远大于记录列表数据量较小的低频词。其次,即使减少了低频词索引的合并操作使其存储的连续性降低,但因为低频词的索引量小,SSD远胜于磁盘的随机读性能完全可以保证读取性能,这一点我们在第2.2小节中已经有过分析。因此,低频词索引的合并开销完全可以适当节省。但由于SSD随机读的速度还是不如顺序读,因此对于索引数据量大的高频词索引还是应当积极地合并,保持其连续性。
据此我们提出了基于分块的部分合并策略,在该策略中只有记录列表数据量积累到一定程度的高频词的索引才会进行合并更新,这一过程我们称之为部分合并。但是如果仅仅只是在现有策略的基础上进行部分合并是不合适的。因为在现有策略中高频词的记录列表会分布在全体索引文件中,要得到其完整的索引信息就必须扫描所有的索引文件,如图2(a)所示,造成部分合并的效率不可避免地受到整体索引规模的影响。因此,本策略对内存索引按术语分块写入,将高频词的记录列表信息抽取出来,使得部分合并的效率只与术语的索引规模相关,如图2(b)所示。以下小节将详细介绍上述过程。
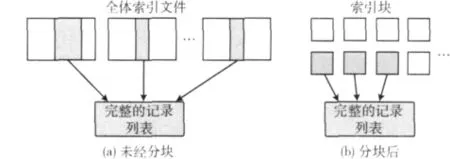
图2 不同情况下读取某术语完整记录列表的过程
3.2 内存索引按术语分块
在基于分块的部分合并策略进行内存索引写SSD的过程中,会对内存索引进行分块写入,使内存索引在SSD上形成按术语划分成的索引块文件。每一个索引块中至少包含一定数量的记录列表数据,我们设置了一个参数Bp来表示这个设定的数据量。内存索引中记录列表数据量超过Bp的术语将占据一个完整的索引块,即该索引块保存的全部是属于该术语的记录列表信息。而索引数据量没有达到Bp的术语则要与其他情况相同的术语共享一个索引块,它们的记录列表信息会被保存在同一个索引文件中。上述过程如图3所示,其中free,www等高频词各占用一个索引块保存记录列表信息。而pass等低频词的记录列表则被写入同一个索引块。
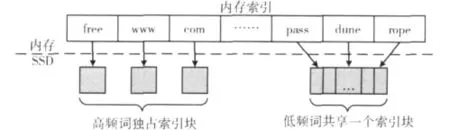
图3 内存索引分块写入
有的术语可能在上一次内存索引写SSD时占据了一个完整的索引块,而在这一次内存索引写SSD时其记录列表信息量达不到Bp,那么在这一次写SSD时该术语便不能占据整个索引块。相反,若上一次某术语只能与别的术语共享索引块,而这一次可以独占一个索引块,那么在这一次写SSD时便可以独占索引块。总之,能否独占索引块只与这一次的内存索引中的记录列表数据量相关。
这样,在一次内存索引写SSD结束后,记录列表数据量较大的高频词在SSD上独占了一个或多个索引块。而余下记录列表数据量较小的低频词则共享了一个索引块。因此在经过了内存索引按术语分块后,高频词的索引信息基本上都位于被独占的索引块中。在需要合并某高频词的索引时,就可以直接对其独占的索引块进行操作,使得合并的开销与整体的索引规模无关而只于该术语的索引量有关。
3.3 索引块部分合并
在内存索引分块写入SSD的过程中,如果某个高频词独占的索引块达到了一定数量,便会触发索引合并,这里我们采用了二路对数合并策略[11]对其进行管理。而对于共享索引块则不会进行任何合并操作。这一点与传统的基于合并更新的索引策略不同,在传统策略中,索引合并是针对全体索引文件的,所有的术语都有可能参加索引合并。而在本文的索引管理策略中,只有被高频词独占的索引块才能参与合并。以下是基于分块的部分合并策略的完整步骤:
输入:已达到容量上限待写入SSD的内存索引
输出:经过更新的SSD索引
begin
创建列表termList
将内存索引中的术语按记录列表的数据量从大到小的顺序写入termList
T=termList中第一个术语
while(T的记录列表数据量≥Bp){
为T创建一个索引块Bt并将其全部记录列表写入
if(T触发了索引块合并条件){
其中值得强调的就是限额采伐以及科学经营,这是国内相关法律规定的重要制度,同时也是对森林资源进行控制的关键性措施。在以往的多年以来国内的森林资源已经是得到了严格的控制,整体上呈现出非常好的态势,但是国内依旧是在林木资源上比较缺乏的,这方面的管理还是需要进一步强化。
对T独占的索引块进行二路对数合并
}
T=termList中下一个术语
}
创建一个索引块Bshare
写入T的记录列表
while(true){
T=termList中下一个术语
向Bshare写入T的记录列表
break
}
end
需要强调的是,某个术语能否独占一个索引块来存储其记录列表在每次内存索引写SSD时都要进行判断。这是考虑到术语在文档集中可能并不是均匀分布的,很可能只是在某一部分频繁出现。就像某个热点问题只会在某一段时间被集中关注。因此,只需要合并其频繁出现的部分的索引,保证检索效率。
4 实验结果与分析
本节对我们提出的基于分块的部分合并索引策略进行了实验评测,指标包括索引与检索性能以及写入SSD的数据量,并引入了几何分区合并策略以及不合并策略作为参照。几何分区合并是一种常用的具有较高性能的在线索引管理方法,不合并策略不进行任何合并,因此具有最快的索引构建速度,写操作数据量也与有效索引数据量相同。实验的硬件环境与第2节中所介绍的相同,但增加了文档数量,达到了400万篇。内存索引的大小为100MB左右,参数Bp的值为1MB。
每一次SSD索引更新结束后,便对上述指标进行一次统计,其中一次检索操作由读取10000个检索词的全部记录列表信息组成,这些检索词来自AOL从真实环境中收集的检索记录[12]。图4、图5分别给出了索引与检索性能的实验结果。其中横坐标表示内存索引写SSD的次数。纵坐标表示的分别是这次内存索引写SSD结束后索引构建操作的总用时以及此时进行一次检索所耗费的时间。在索引构建性能方面,如图4所示,基于分块的部分合并策略索引构建的用时与不合并策略相比仅仅是其1.6倍,而常用的几何分区合并策略的用间达到了不合并策略的4.3倍。这主要是因为我们大幅减少了索引合并的数量,避免了频繁进行合并更新的巨大开销。在检索性能方面,从图5中可以看到完成一次检索新方法的用时大概只有几何分区策略的60.4%,其原因在于我们对访问频繁的高频词采用了更积极的合并策略,因而增强了其存储的连续性。虽然对于低频词索引存储的连续性减弱了,但由于单个低频词索引数据量较小,SSD优异的随机读性能依然保证了其读取效率。而且低频词由于被命中次数少,因此总的来说对检索速度的影响也很小。
另一方面,基于分块的部分合并策略显著减少了对SSD的写操作。图6给出了实验结果,其中横坐标表示的是当前内存索引写SSD的次数,纵坐标则表示此时对SSD的写操作总的数据量。从中可以看到本文所提出的策略产生的写操作的数据量大概是不合并策略的2.1倍,但相对于几何分区合并策略,本策略写入的数据大概只是其37.4%。这还是由于我们大量减少了会产生额外写操作的索引合并的缘故。最后图7给出了参数Bp的不同取值对本策略的检索性能的影响。Bp取值越大,能够参与索引合并的术语减少,会降低检索速度:Bp取值为4MB时完成一次检索的用时比Bp取值0.5MB时多了1.4秒左右,比Bp取值1MB时多了大约0.6秒。但相应的索引合并操作也会减少。为了平衡检索性能与写入的数据量,我们设Bp的值为1MB。
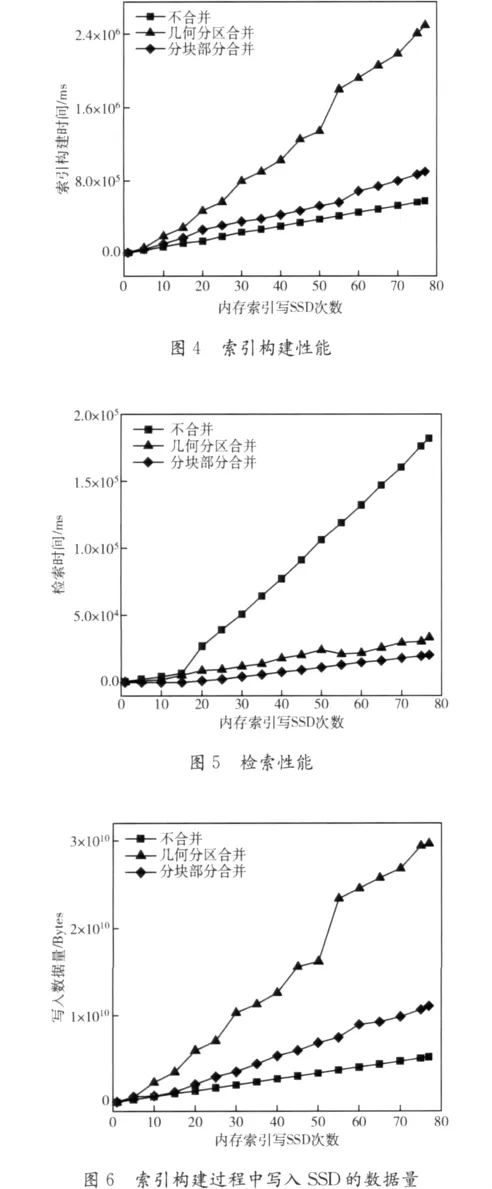
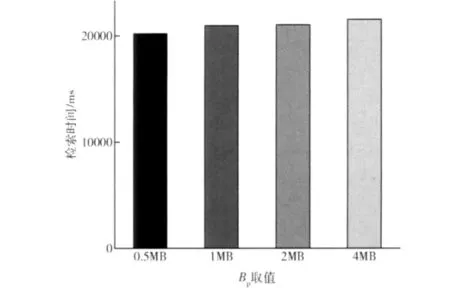
图7 参数Bp的取值对检索性能的影响
5 结束语
本文首先通过实验分析了现有在线索全文引管理策略在SSD环境下的不足之处,并以此为基础提出了一种针对SSD的全文索引管理策略:基于分块的部分合并策略。该方法沿用了通过合并操作更新SSD索引的思想,在索引构建过程中对内存索引按术语分块并对划分的索引块进行部分合并,充分利用了SSD高效随机读的特性减少了意义不大的合并操作。实验结果表明,新策略不仅具有优越的索引构建与检索性能,而且显著降低了对SSD的损耗,与传统策略相比能够更好地适应SSD的环境。下一步的工作是尝试引入参数Bp的动态适应机制,提高该策略对不同硬件环境和数据集的适应性。
[1]Zobel J,Moffat A.Inverted files for text search engines[J].ACM Computing Surveys,2006,38(2):1-55.
[2]OCZ Technology.RevoDrive X2(PCI-E solid state drives,220GB-960GB,MLC NAND)[EB/OL].[2012-01-12].http://www.ocztechnology.com/ocz-revodrive-x2-pci-express-ssd.html.
[3]Lester N,Zobel J,Williams H E.Efficient online index maintenance for contiguous inverted lists[J].Information Processing and Management,2006,42(4):916-933.
[4]GUAN Jianhe,GAN Jianfeng.Design and implementation of web search engine based on Lucene[J].Computer Engineering and Design,2007,28(2):489-491(in Chinese).[管建和,甘剑峰.基于Lucene全文检索引擎的应用研究与实现[J].计算机工程与设计,2007,28(2):489-491.]
[5]ZHENGWenjing,LIMingqiang,SHU Jiwu.Flash storage technology [J].Journal of Computer Research and Development,2010,47(4):716-726(in Chinese).[郑文静,李明强,舒继武.Flash存储技术 [J].计算机研究与发展,2010,47(4):716-726.]
[6]Chung T S,Park DJ,Park SW,et al.A survey of flash translation layer[J].Journal of Systems Architecture-Embedded Systems Design,2009,55(5-6):332-343.
[7]CHEN F,LUO T,ZHANG X D.CAFTL:A content-aware flash translation layer enhancing the lifespan of flash memory based solid state drives[C]//San Jose,U.S.A:USENIX Conference on File and Storage Technologies,2011:77-90.
[8]Wikipedia static HTML dumps [EB/OL].[2011-07-21].http://static.wikipedia.org.
[9]Shieh W Y,Chung CP.A statistics-based approach to incrementally update inverted files[J].Information Processing and Management,2005,41(2):275-288.
[10]Lester N,Moffat A,Zobel J.Efficient online index construction for text databases [J].ACM Transactions on Database Systems,2008,33(3):1-33.
[11]Büttcher S,Clarke CL A.Indexing time vs query time:Trade-offs in dynamic information retrieval systems[C]//Bremen,Germany:International Conference on Information and Knowledge Management,2005:317-318.
[12]Pass G,Chowdhury A,Torgeson C.A picture of search[C]//Hong Kong:International Conference on Scalable Information Systems,2006:1-7.
