基于MapReduce的数据挖掘平台设计与实现
2013-07-25许舒人
黄 斌,许舒人,蒲 卫
(1.中国科学院软件研究所软件工程技术中心,北京100190;2.中国科学院研究生院,北京100190;3.解放军卫生信息中心,北京100842)
0 引言
2009年全球存储的信息总量达到为8000亿Gbt。IDC预测到2020年,全球将会存储35Zbt(1Zbt=240Gbt)的信息量。社交网络、电子商务、微博、音视频分享等互联网领域以及研究机构科学实验源源不断地产生大量的数据,单一数据库存储服务已经无法满足数据多元化与大规模数据挖掘的需求。
在商业领域,从商业决策、搜索引擎、社交网络、推荐系统,到垃圾邮件检测与广告投放,对大规模数据进行及时、有效地分析已成为这些商业应用能在竞争中脱颖而出的重要因素;在科学研究领域,天文学的图片数据、生物学中的人类基因组数据以及物理学中粒子加速器产生的实验数据的数据量都非常大,大数据量给科学分析带来困难。
面对增长迅速的数据量,如何从数据中发掘有用的信息成为当前大多数数据挖掘系统面临的问题。对于此类大数据集的数据分析与挖掘系统,Cohen等人在文献 [1]中总结了这类系统需要具备的特性:
(1)数据适应性:系统可接受多种类型的数据,避免系统对存储的数据的类型、结构和数据完整性的强要求,从而避免通常的数据仓库对数据的强要求带来的问题;
(2)敏捷性:系统能够适应数据递增且更新频繁的应用场景;
(3)分析深度:提供对数据分析多角度、多切面的分析,可便捷得加入复杂的概率统计和机器学习算法,适应多类型数据分析需求。
迫于数据量的急剧增长,大量的数据存储在数据库与数据仓库中,关系型数据库通常提供进行数据分析与挖掘的数据分析工具,例如,SAP BusinessObjects Explorer[2]、Matlab Spider[3]、SQL Server Analysis Services[4]、weka[5]等都提供了此类工具。然而,以关系型数据库为基础的数据挖掘系统存在以下几个弊端:
(1)在庞大数据量背景下,数据迁移所带来的时间损失巨大,在此种情况下,把计算力移向数据是比数据迁移到计算系统更有效率的方法;
(2)大多数数据库分析系统需要将所有的数据放入内存中,对于占多数的大数据集,一般只能通过抽样的方式使得数据量缩小到内存可接受的范围内,数据的抽样通常会导致数据信息量丢失;
(3)在处理速度上,不断增加的数据很容易造成数据库索引的不断增加,索引增加的滞后性容易导致数据库的处理速度降低。
数据库系统在数据处理效率和可处理的数据量无法满足当前数据的爆炸式增长,效率与容量成为以数据库为基础的数据挖掘系统的最大瓶颈。
基于模型驱动的开发方法与组件开发技术,本文提出一种可扩展数据挖掘平台,运用MapReduce框架的扩展性与并行能力,定义可重用的数据挖掘组件和Connector组件,提高了数据挖掘过程敏捷性。系统主要解决以下3个方面的问题:
(1)定义数据挖掘过程中的挖掘组件模型,用户可复用系统提供的数据挖掘组件来快速定义数据挖掘过程;
(2)通过GMF技术实现对数据挖掘过程的可视化定义,并通过代码生成引擎实现挖掘过程到可执行代码的转换;
(3)定义Connector可重用组件,实现对多种数据存储系统的数据访问。
1 研究背景
Google 提出的分布式文件系统 GFS[6]和 MapReduce[7]框架为大规模并行数据计算与分析提供了重要的参考。MapReduce框架将数据的运算抽象成“Map”和“Reduce”两个阶段,以分而治之的思想简化了大规模数据集的并行计算过程。Hadoop是MapReduce框架与分布式文件系统GFS的开源实现,它实现的MapReduce框架和HDFS分布式文件系统使得在成本可控的情况下处理海量数据成为可能。业界围绕着Hadoop发展起来了一系列工具,这些工具扩展了Hadoop的运用场景与应用领域。如图1展示了Hadoop软件栈 (Hadoop software stack),以Hadoop为核心,出现了在数据存储、处理、访问、管理、数据连接等几个层次的软件。它们提升了Hadoop的易用性、可维护性以及对多种编程语言的支持能力。
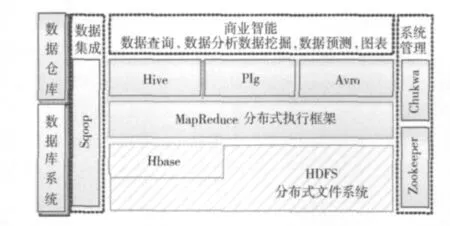
图1 Hadoop Software Stack
其中,Hbase[8]是一个以 BigTable[9]为原型的高性能、面向列、强一致性存储系统;Hive[10]是一个基于Hadoop实现的数据仓库工具;Pig使用户可以通过Pig-latin语言定义运行于Hadoop上的数据流程;Avro是一个面向Hadoop的数据序列化系统;Sqoop[11]是一个用于关系型数据库与HDFS之间数据迁移的工具;Zookeeper用于分布式应用中的集群管理、状态同步服务、同步锁服务;Chukwa是一个用于进行集群运行日志收集、分析和展示的管理工具。
以上软件与工具在一定程度上提升了Hadoop的易用性和数据分析的能力,然而Hadoop对数据分析、数据挖掘算法以及可视化支持的缺乏使用户在运用Hadoop进行数据挖掘过程中暴露出效率低下、重复开发等问题。目前还没有基于MapReduce实现的面向数据密集型的可视化数据挖掘框架。用户在使用Hadoop提供的任务提交机制进行数据挖掘操作时,往往需要根据需求去设计特定的Hadoop任务代码。例如,对于一个SNS网站,若需要对20-30岁的用户花费在社交网络上的时间进行统计,开发人员需要针对特定的需求编写MapReduce代码 (包括条件过滤、数据统计和数据展示等几个任务),然后交给Hadoop去进行计算。该开发过程花费时间长,大部分时间都花费在重复开发上。
2 基于MapReduce的数据挖掘平台
基于MapReduce实现的数据挖掘平台的系统架构主要包括数据挖掘过程模型、代码生成引擎、数据挖掘组件模型、MapReduce执行框架4个模块,如图2所示。
数据挖掘过程模型:用户通过可视化的界面来定义数据挖掘过程,并配置相关的组件信息,该部分通过基于E-clipse 的 EMF[12]、GEF[13]和 GMF[14]实现图形化的数据流程处理模型。
代码生成引擎:为了避免让用户重复编写通用代码,系统具备生成符合Hadoop规范代码的功能,用户通过系统提供的参数配置界面配置需用户定义的参数,这些参数最后将会反映到最终生成的代码中。从用户定义的数据挖掘过程模型转换成可在Hadoop上运行的代码有一个过程分析与代码生成过程,该过程由代码生成引擎完成,主要包括了过程模型分析、依赖关系分析、代码模板解析等工作。
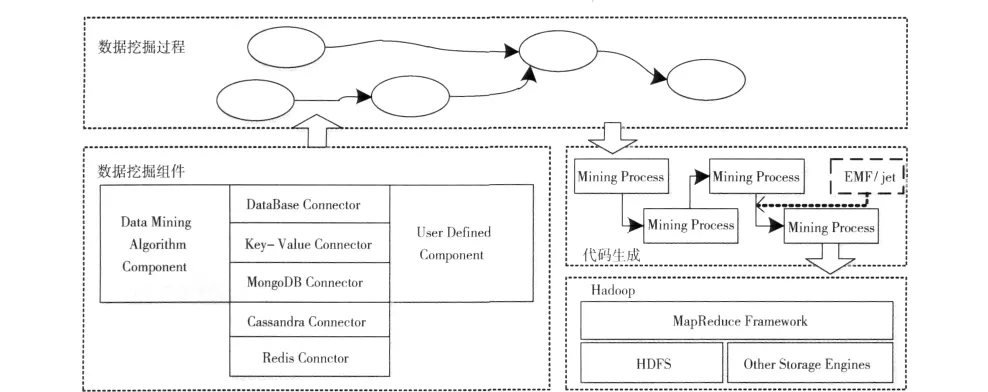
图2 基于MapReduce数据挖掘处理平台架构
数据挖掘组件模型:数据挖掘过程是通过将组件连接起来构成的,组件为了实现不同的功能,将封装不同的数据操作逻辑。数据挖掘组件主要分成数据挖掘算法 (datamining algorithm)组件、Connector组件、用户自定义组件(user defined component)三大类。
MapReduce执行框架:系统以Hadoop提供的MapReduce框架作为数据挖掘过程执行平台,通过向MapReduce框架提交代码的形式,运用MapReduce的并行计算能力实现挖掘过程的并行化。
运用基于模型驱动的开发方法,系统将软件过程中使用的算法提取出来形成抽象模型。该方法可使用户无需关心特定算法实现细节,系统以面向组件的方式简化数据挖掘流程定义和算法组件定义。面向模型驱动的开发方法提高了系统的抽象层次,系统以一种可扩展的方式实现了数据挖掘平台的低耦合、高内聚。
2.1 数据挖掘过程模型
用户通过系统提供的模型组件来定义数据挖掘过程,该过程是一个符合过程逻辑模型的挖掘过程。在逻辑模型中,挖掘过程中的每一步数据操作被抽象成一个数据操作节点,该节点可称为逻辑节点。系统通过解析逻辑节点的输入输出信息、用户配置参数、节点对应的系统组件元信息来构建物理过程模型。逻辑过程模型与具体实现技术无关。物理模型则是从计算机系统的角度来定义,该模型与系统的实现平台、编程模型和MapReduce任务调度策略相关。逻辑模型经过系统的后台解析转换成物理模型后才能在系统中执行。
过程模型使用EMF技术实现逻辑模型到物理模型的转换。同时,通过GEF技术,用户可通过模型的图形化方式来实现逻辑模型的定义。物理模型与具体实现相关,物理模型包含了数据挖掘组件模型、Jet模板代码生成技术以及与MapReduce相关的Mapper与Reducer定义、Job类型等相关内容。这些内容将分别在2.3节代码生成引擎和2.4节数据挖掘组件介绍。
数据挖掘过程包括数据准备、数据预处理、数据挖掘和结果展示几个步骤。如图3所示,数据准备主要是指定义一个或多个数据来源,并在执行过程中完成数据抽取工作,用户可通过定义不同的Connector组件来实现对不同数据源的数据抽取。数据预处理包括了数据清理 (去噪和去除不一致数据)、数据集成 (多数据源的组合)和数据选择 (定义数据过滤规则)。用户通过定义过滤、正则匹配等组件来实现该步骤。数据挖掘运用数据挖掘算法对经过预处理的数据执行挖掘算法。最后,结果展示步骤将执行结果以数据或图表的形式展示给用户。

图3 数据挖掘过程
2.2 代码生成引擎
代码生成引擎主要完成从逻辑模型到可被MapReduce框架执行的可执行代码的转换过程,如图4所示,大致可分成模型解析与代码生成两步。
第一步是模型解析,模型解析的主要工作是解析逻辑模型,系统根据数据挖掘过程模型定义的节点信息来划分操作子流程,以Reduce操作节点为划分点,以mapper+/reducer/mapper* (通过 ChainMapper[15]和 ChainRedu-cer[15]实现多个mapper和reducer在一个任务中执行)为子流程形式构造MapReduce任务集,并根据流程的连接顺序来定义子流程之间的依赖关系。
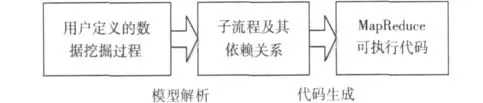
图4 代码生成引擎工作原理
第二步是代码生成,如图5所示,根据第一步模型解析得到的子流程以及依赖关系,系统通过jet[16]模板解析的方式来生成MapReduce代码。数据挖掘组件接收与其相连组件的输入输出类信息。根据输入输出类型信息和组件代码模板,使用jet代码模板生成相应的代码,并将处理后的输出按照输出模式存放。组件模型包含组件ID、jet代码模板、用户定义参数类与组件元信息。组件ID用于标识组件的唯一性;jet代码模板包括了Job配置模板、Mapper类模板、Reduce类模板以及Key/Value类模板等与MapReduce执行平台相关的模板信息;用户自定义参数类是用户输入的参数;组件描述元信息包含了组件描述、可视化图标、模板路径等元数据。数据挖掘过程模型最终会转换成Java可执行代码。这些类包括数据操作节点的Mapper类和Reducer类、数据连接输入输出类。最后,系统会生成一个以用户定义的数据挖掘过程名称为类名的主类来控制整个数据挖掘过程,并通过Hadoop Job Configuration模板提供的信息在runJob方法中按照模型解析获得的任务依赖关系构建挖掘代码。
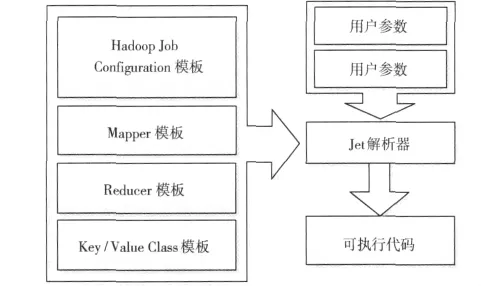
图5 Jet代码模板解析器工作方式
图6 描述了代码生成引擎的部分类的类图,引擎主要包括了用于对代码生成进行控制的MapReduceTransfer类;用于对过程模型进行实例化的物理模型类PhysicalProess、PhysicaNode、PhysicalConnection、ChainHadoopJob;用于对代码生成过程进行管理的DataMiningCodeManager类。
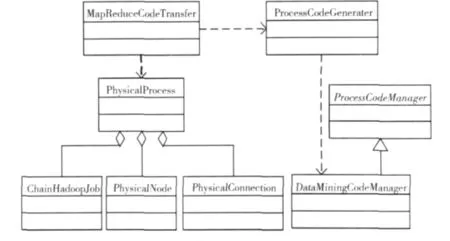
图6 代码生成引擎部分类
2.3 数据挖掘组件
数据挖掘组件是系统实现挖掘、数据连接等功能的数据操作单位,组件封装了特定的数据操作逻辑。系统基于Eclipse来开发,可通过用户自定义组件来扩展功能。数据挖掘组件在 OSGi[17]标准框架 Equinox中以组件的形式存在,系统提供标准扩展点,数据挖掘组件在plugin.xml中定义符合扩展点schema规则的组件元信息。
系统通过定义组件模型来规范化组件在系统中的生命周期。如图7所示,组件模型定义了该组件的输入流与输出流,并通过Configure Interface接受用户参数。
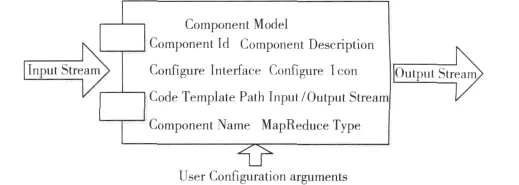
图7 数据挖掘组件模型
组件模型定义了组件的类型、输入接口、输出接口、组件MapReduce类型等元信息。表1展示了数据挖掘组件模型Schema规范。
组件主要包括了ConfigInterface,Description,Icon,Id,MapredType,oType,TemplatePath以及 Input和 Output几项属性。表1描述了各项属性的含义。
通过定义符合规则的schema,组件作为数据挖掘过程中标准组件的形式存在于系统中,并由系统对其进行加载、调用、销毁等生命周期管理。上述schema的定义没有规定组件内部的算法逻辑的实现,算法的实现主要通过每个组件各自的TemplatePath中的代码模板来定义。代码模板可根据组件需要实现的特定功能来实现算法,这种松耦合的架构为系统的可扩展性提供了保障。用户可通过实现自定义的代码模板来添加自定义组件。同时,代码模板也可以方便得用于调用现成的算法库,例如基于Hadoop实现的Mahout[18]算法库。

表1 组件schema描述表
2.3.1 数据挖掘算法组件
数据挖掘算法组件封装了挖掘算法逻辑。在数据挖掘算法组件中,数据以SequenceFile类型存储。如图8所示。SequenceFile存储类型是Hadoop内置的一种数据存储类型,用于存储二进制形式的key/value。该存储方式支持压缩,可定制为基于Record或Block压缩压缩粒度。
基于hadoop的机器学习算法库mahout实现了部分并行算法,用户可通过参考系统定义的数据挖掘组件扩展点schema将mahout算法包装成数据挖掘算法组件。
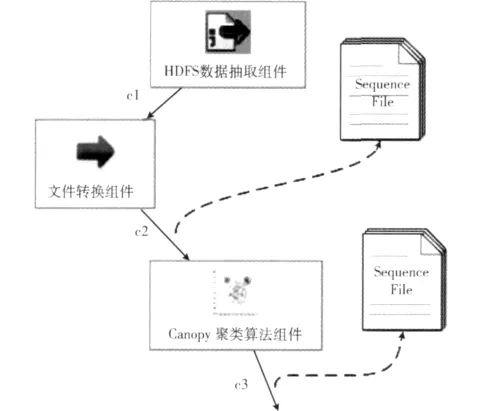
图8 数据挖掘算法组件SequenceFile数据转换
图9 展示了基于MapReduce框架的K-means聚类算法,与传统的K-means算法比,该算法实现了并行化。该算法分成三步:第一步实现文件的转换,为后续步骤做数据准备;第二步对数据进行了分布式的Canopy算法,用于确定K-means算法初始的K个簇中心;第三步根据用户配置的参数进行K-means迭代算法。该算法参考了mahout中的实现。
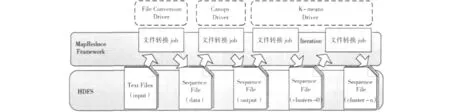
图9 分布式K-means聚类算法
2.3.2 Connector组件
Connector组件用来实现系统与其它存储系统的数据访问功能。该类组件通过将定义系统与各类存储系统的数据访问接口与数据访问格式来实现数据读写访问。主要包括关系型数据库Connector组件和key-value数据库Connector组件两大类。例如,MySQL Connector用于访问存储在MySQL数据库中的数据。对于关系型数据库的Connector组件,系统参考Cloudera Sqoop框架的实现。
3 实验与分析
实验与分析主要是通过数据挖掘平台向量聚类挖掘过程的可视化开发过程来说明基于MapReduce数据挖掘平台的易用性以及在面对多变需求时的敏捷性。
3.1 实验设置
聚类算法能够在没有训练样本的条件下产生聚类模型。作为数据挖掘的一种重要手段,聚类在Web文档的信息挖掘、信息分类中有着重要作用。对于需要聚类的文档,传统的做法是通过分词与TF-IDF[19]统计等方式将文档转换成向量。然后通过Canopy、K-means等聚类算法对向量进行聚类分析。
用户通过系统提供的可视化开发界面定义挖掘过程。如图10所示,HDFS数据抽取组件定义输入路径;文件转换组件将原始文件转换成K-means聚类算法组件可接受的SequenceFile存储类型;最后K-means聚类算法组件执行聚类分析。

图10 K-means向量聚类流程
对于K-means聚类算法组件的需要配置的参数,用户可通过系统提供的组件属性配置界面进行参数配置。如图11所示,通过配置界面,可定义用于K-means算法的特定的属性值 T1,T2,向量距离测量方式,算法迭代次数等参数。

图11 K-means聚类算法组件参数配置面板
在用户配置完数据挖掘流程后,系统将自动生成代码并上传到Hadoop集群进行计算。图12展示了8000个向量进行K-means聚类的结果。对于二维向量,系统提供聚类图形化的选项 (如图11所示)。通过系统的可视化工具,可将聚类结果以图形化的方式展现给用户。该聚类结果是在合理配置T1,T2,数值范围、收敛指数等参数后的聚类结果。

图12 K-means二维向量聚类
通过系统提供的挖掘过程定义界面与组件配置功能,用户可在不关心K-means算法实现细节与算法并行化技术的基础上,实现了对向量数据的聚类分析。同时,通过系统提供的可视化工具,实现对聚类结果的可视化展示。该过程简化了在Hadoop平台上的数据挖掘过程,提高了开发效率。
4 相关工作
Wegenner[20]等人针对数据挖掘算法的并行化问题,提出了针对MapReduce环境下通用数据挖掘工具。该研究表明MapReduce并行化计算大幅提高了挖掘算法对大数据集的挖掘效率。
Weka Parallel[21]将Weka扩展到多核环境下,通过实现Weka多核环境下并行化交叉验证,缩短需进行交叉验证的分类、聚类等挖掘算法的执行时间。
Lai[22]等人提出了在Hadoop上构建数据索引,该文运用决策树算法建立索引的方式实现了比Hadoop提供的Map-File索引跟高效的访问效率。同时,运用Java持久化API(JPA)与MySQL集群构建基于Hadoop的数据挖掘系统。
本文提出的基于MapReduce的数据挖掘平台从开发效率和扩展性出发,运用过程建模与组件复用技术,实现挖掘过程可视化与挖掘算法组件化,提高挖掘效率。
5 结束语
本文提出了一种基于MapReduce编程模型的数据挖掘平台设计与实现,为Hadoop在构建数据挖掘、数据可视化以及商业智能应用提供参考。该平台以OSGi为基础,以一种可扩展、低耦合的构建方式,用户可方便地利用现有的算法对平台进行功能扩充。面对互联网和科学计算产生的海量数据,该平台充分利用了Hadoop对海量数据的处理能力和OSGi框架对组件完善的管理能力,构建一种可适应数据挖掘领域需求变动快、数据来源多样等特点的海量数据挖掘平台。
[1]Jeffrey Cohen B D,Mark Dunlap.MAD skills:New analysis practices for big data [J].Proceedings of the VLDB Endowment,2009,2(2):1481-1492.
[2]Business objects explorer home page on the sap community network[EB/OL].http://www.sdn.sap.com/irj/boc/explorer,2012.
[3]The spider is intended to be a complete object orientated environment for machine learning in Matlab[EB/OL].http://people.kyb.tuebingen.mpg.de/spider/,2012.
[4]Microsoft SQL server analysis services(SSAS)[EB/OL].http://msdn.microsoft.com/en-us/library/ms175609(v=sql.90).aspx,2011.
[5]Mark Hall E F,Geoffrey Holmes,Bernhard Pfahringer,et al.The WEKA data mining software:An update[J].ACM SIGKDD Explorations Newsletter,2009,11(1):10-18.
[6]McKusick K,Quinlan S.GFS:Evolution on fast-forward [J].Communications of the ACM,2010,53(3):42-49.
[7]Dean J,Gheawat S.MapReduce:Simplified data processing onlarge clusters[J].Communications of the ACM-50th Anniversary Issue:1958-2008,2008,51(1):107-113.
[8]Khetrapal A,Ganesh V HBase.Hypertable for large scale distributed storage systems[EB/OL].http://www.ankurkhetrapal.com/downloads/HypertableHBaseEval2.pdf,2008.
[9]Chang F,Dean J,Ghemawat S,et al.Bigtable:A distributed storage system for structured data[J].ACM Transactions on Computer Systems,2008,26(2):205-218.
[10]Thusoo A,Sarma JS,Jain N,et al.Hive:A warehousing solution over a map-reduce framework[J].Proceedings of the VLDB Endowment,2009,2(2):1626-1629.
[11]Hadoop Sqoop.SQL-to-Hadoop database import and export tool[EB/OL].https://github.com/cloudera/sqoop/wiki,2010
[12]Eclipse modeling framework project(EMF)[EB/OL].http://www.eclipse.org/modeling/emf/,2012.
[13]Eclipse consortium,eclipse graphical editing framework(GEF)[EB/OL].http://www.eclipse.org/gef/,2012.
[14]Eclipse consortium,eclipse graphical modeling framework[EB/OL].http://www.eclipse.org/modeling/gmp/,2010.
[15]White T.Hadoop:The definitive guide[M].2nd ed.O'Reilly Media/Yahoo Press,2010:165.
[16]Eclipse consortium,Java emitter templates(jet),eclipse modeling framework-version 2.6.1,2010[EB/OL].http://www.eclipse.org/emf,2010.
[17]OSGi Alliance.OSGi-the dynamic module system for Java[EB/OL].http://www.osgi.org,2009.
[18]Sean Owen R A.Mahout in action[M].Manning Publications,2010.
[19]Wu H C,Luk R W P,Wong K F,et al.Interpreting TF-IDF term weights as making relevance decisions[J].ACM Transactions on Information Systems,2008,26(3):2-36.
[20]Wegener D,Mock M,Adranale D,et al.Toolkit-based high-performance data mining of large data on MapReduce clusters[C]//Washington:IEEE Computer Society,2009:296-301.
[21]Celis S,Musicant D R.Weka-parallel:Machine learning in parallel[EB/OL].http://sourceforge.net/projects/weka-parallel/,2009.
[22]Lai Y,ZhongZhi S.An efficient data mining framework on hadoop using java persistence API[C]//Bradford:IEEE Computer Society,2010:203-209.
