使用随机策略进行运动目标检测方法研究
2013-07-20胡雄鸽王耀南
胡雄鸽,王耀南
湖南大学 电气与信息工程学院,长沙 410082
使用随机策略进行运动目标检测方法研究
胡雄鸽,王耀南
湖南大学 电气与信息工程学院,长沙 410082
1 引言
视频序列中,运动目标检测在视频监控、智能交通、汽车自动驾驶与辅助驾驶等领域中是一项基础而又关键的任务。Intel公司在智能视觉监控系统计算机工作量分析中表明[1],前景目标检测所耗费的程序执行时间约占整个智能视频监控程序的80%~95%,开发一种简单高效,占用计算机资源少的算法成为很多应用项目的关键。在已有方法中,减背景是一种最常用的方法,它的基本思想是用当前视频帧与背景帧相比较,如果相同位置的像素特征、像素区域特征或者其他特征之间存在一定程度区别,则当前视频帧中的这些像素点或者像素区域就判定为运动目标。最常见的减背景方法包含两种,一种是当前视频帧与固定的背景帧之间进行比较,另一种是连续两帧视频帧之间的比较;通常设定一个阈值T,凡是大于阈值T的像素点则被判定为运动点。这种方法原理简单,但是容易受噪声和光照等条件影响,特别是当场景中存在诸如随风摆动的树枝,水面的波纹,闪烁的屏幕,突然的开灯关灯,运动物体进入场景后停留一段时间后又移出等情况时,这种方法的缺点就更加突出。均值滤波算法的中心思想是建立一个视频序列时间窗来缓存N张视频帧,然后把所有视频帧同位置像素的平均值作为背景来处理该像素的值。一种改进的方法就是滑动平均算法(running average)[2],其核心想法就是引入一个学习率a,这里a通常取值为0.003~0.050,a值越小,则表明前景的变化对背景影响越小,公式(1)为其更新等式:

Friedman提出利用3个高斯分布[3]来对交通道路场景中的道路、阴影、车辆的像素进行分别建模。由Stauffer和Grimson所提出的混合高斯背景建模算法[4-5]得到了广泛的研究,衍生出很多改进型算法[6-8],主要集中在背景模型的初始化、参数选择、更新等式这几个方面。其基本思想就是对每一个像素点建立混合高斯模型(高斯模型一般为3~5个),检测过程中判断当前像素点是否符合该分布,若符合,则判定为背景点,若不符合,则判定为运动点。
本文提出的方法不像混合高斯模型那样依赖于具体而精确的统计模型,而是基于一种随机取值的思想,主要体现在背景模型的初始化过程中样本点选择上和背景模型更新过程中对样本点的选取与替换上。下面将详细阐述背景模型的建立、初始化以及更新过程。在实验部分讨论了实验参数的选择,并且通过与滑动平均、改进的混合高斯法进行对比,验证了本文方法的有效性。
2 背景模型实现过程
从视频序列中提取的像素点特征通常可以归为3类:光谱特征、时间特征、空间特征[9]。基于随机策略的运动目标检测方法对每个像素所建立的样本序列中包含这3种特征,光谱特征利用像素点的灰度值,时间特征使用同一位置像素点在不同帧的取值,空间特征使用像素点8邻域像素值。图1为使用随机策略进行运动目标检测的流程图。下面将分3个小节,详细对背景模型的建立、初始化、更新过程进行论述。

图1 使用随机策略进行运动目标检测流程图
2.1 背景模型的建立
对每一个像素点建立一个包含N个样本点的样本序列(即背景模型,N≥1),记当前像素点位置为(a,b),当前像素位置(a,b)的样本点序列记为{si(a,b)|i=1,2,…,N},xt(a,b)代表在t帧时位于(a,b)位置的像素值。当前像素点xt(a,b)的N个样本点的取值可以分为两类:一类是在同一位置在之前视频帧像素值;另一类是之前视频帧同一位置的8邻域像素值。通过这种取值方式,使样本点包含光谱、空间、时间3种特征信息。对在(a,b)位置的新视频帧在t时刻灰度值xt(a,b)与它的N个样本点相比较,Tv为灰度值阈值,如公式(2)所示:
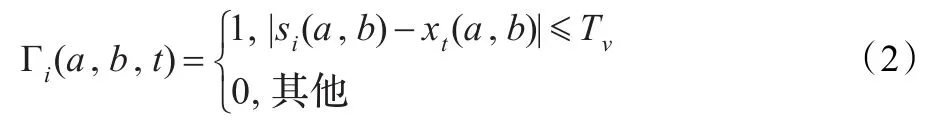
设置另一个次数阈值Tn,用来对符合式(2)的次数进行计数,通过次数判定当前像素点是背景点还是运动点,如公式(3)所示:
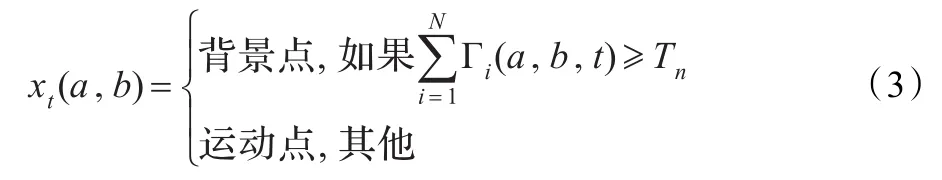
这个判定规则可近似用二项分布理论来加以解释:当前像素值与样本序列中N个样本点进行比较,相当于做了N次实验,|si(a,b)-xt(a,b)|≤Tv概率为p,以X记为N次比较中绝对值小于等于Tv的次数,则X大于等于次数阈值Tn这个事件的概率可以用公式(4)表示:
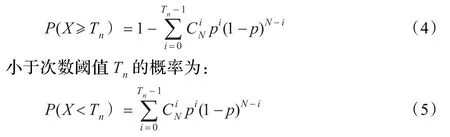
在理想情况下认为|si(a,b)-xt(a,b)|≤Tv的概率与|si(a,b)-xt(a,b)|>Tv的概率近似相等,即p=0.5,在N取值较大及Tn取值较小的条件下,由式(4)得出P(X≥Tn)概率很大,式(5)算出P(X<Tn)概率很小;据此推断如果xt(a,b)与它的每一个样本点{si(a,b)|i=1,2,…,N}相比较,其绝对值小于灰度值阈值Tv的次数大于次数阈值Tn,则该点为背景点的概率很大,即被判定为背景点;反之,则被判定为运动点。通过上述特定的判定规则完成对当前像素点的判定过程;通过对当前视频帧的每一个像素点进行判定,完成对当前帧的运动目标检测过程。
2.2 背景模型的初始化
为了快速完成对背景模型的初始化,本文提出利用第1帧像素点的空间特征进行初始化。由于在第1帧并无时间特征可以利用,所以考虑其空间特征。在对视频序列第1帧的(a,b)位置像素点xt=1(a,b)的N个样本点进行初始化时,使用该像素点的4邻域、8邻域甚至16邻域的像素点灰度值,在文中使用8邻域,即xt=1(a+1,b),xt=1(a-1,b),xt=1(a,b+1),xt=1(a,b-1)这4个上下左右邻域点,加上对角像素点xt=1(a+1,b+1),xt=1(a+1,b-1),xt=1(a-1,b+1),xt=1(a-1,b-1),构成8邻域像素点。通过对8个邻域像素点灰度值和xt=1(a,b)(当前像素点灰度值)共9个像素值,进行N次概率均等(每个点被选择的概率为1/9)的随机取值,完成背景模型的快速初始化过程。结果可能某一像素值被选择了几次,有的像素值一次都没有被选择过,这对于整体检测效果并无太大影响。实际上,对于一个固定测试的视频序列,因为在2.2和2.3小节的背景模型初始化、背景模型更新中使用随机策略,每次实验结果都会有细微的不同,但并不妨碍运动目标检测的精度。
2.3 背景模型的更新
背景模型的更新涉及两个重要问题:一是对哪些样本点进行操作;二是每一个样本点的存在时间。本文使用一种概率均等的随机取值更新策略,不仅随机更新当前像素点的样本序列,同时更新其邻域像素点的样本序列;对位于(a,b)位置的样本序列{si(a,b)|i=1,2,…,N}中的哪一个样本点进行操作并不固定,对于该像素点的8邻域之中的哪一个像素点的样本序列进行更新并不固定。采取这种更新策略的出发点在于已经出现的背景点像素值可以保留在样本序列中,而并非经过一段时间即被强制替换;并且运动点像素值不能进入样本序列来保持样本序列的纯净。使用这种更新机制的限制条件就是当前视频帧中被判定为运动点的像素值不能用于更新该位置的样本序列,必须再通过公式(3)确定该像素点在t时刻为背景点之后才能用该像素值进行更新操作,如果判定为运动点则该位置的样本序列保持不变。
在进行样本序列更新之前,需初始化另一个参数Ts,作用是降低样本序列更新速度。本文方法中,如果N取值较小的话,每一个位置的样本序列的更新速度非常快,结果使得低速运动目标被背景快速侵蚀,在运动目标内部形成空洞,影响运动目标检测效果;当运动目标停止运动后,迅速转换为背景。为达到理想的检测效果,有两种解决途径:一是增大样本点个数N的取值,这样会增大内存的消耗量;另一种方法是增加一个参数为Ts的随机取值判断过程,随机取值的范围是[0,Ts],通过增加一次判断过程,使得样本序列的更新速度减缓。这种途径可以从另一个方面来解释,由于N个样本点中的每一个样本点被选择的概率降低了1/Ts,相当于样本序列包含的样本点个数扩大为N×Ts,与第一种途径扩大样本点N个数达到同样的效果,但并没有增加内存的消耗。通过上述分析,为了减少内存消耗,本文采用第二种方式。
在对位置(a,b)的样本点序列进行更新后,随机选择8邻域像素点之一,使用xt(a,b)对其样本点序列进行更新。每一个邻域像素点被选择的概率是1/8,这个被选择的邻域像素点的一个样本点被更新的概率是1/N。
文献[10]中指出,运动目标检测主要存在以下难点:(1)现实情况中,由于光照条件的影响,不可避免地存在阴影的现象,而阴影与真正运动目标实体之间的区分是一个的难题。(2)运动目标进入场景后,经过一段时间停止运动后,应该逐渐转变为背景。(3)运动目标从静止变为运动时,或者以较低速度前行时,要避免出现幻影现象,也就是运动目标离开之处应当迅速融入背景。(4)要能够适应场景中诸如光照条件逐渐变化,随风飘动的树叶等情况变化。
下面阐述本文方法在复杂场景条件下,对提高运动目标检测效果的有效性的原因:
(1)因为阴影区域像素点与周围背景像素点灰度值差异相对较小;在更新过程中,阴影区域周边的背景像素点灰度值快速融入阴影点的样本点序列,根据公式(2)、(3),阴影点被判定为背景点的概率变大,在被判定为背景点后,这个阴影像素点灰度值又不断进入它周围的阴影像素点样本点序列,通过不断的扩散,最终阴影区域将快速融入背景。而运动目标实体边界像素点与周围背景点的灰度值相差较大,即使周围背景像素点灰度值扩散运动点样本序列,但是根据式(2),由于与背景点灰度值差异大,仍然会被判定为运动点,这样使得真正运动目标区域的像素点的样本点序列并未被背景点所侵蚀,相当于起了一层保护膜的作用。通过这种机制,能够对阴影区域进行有效抑制。
(2)运动目标如果在一段时间内的保持静止状态,由于运动目标边界区域像素点的样本点序列不断被背景点灰度值所侵蚀,当停留时间较长时,边界像素点存在一定的被判定为背景点的可能性,加上运动目标区域内部不可避免地出现噪声点,这些噪声点灰度值也会扩散到运动点的样本点序列,根据公式(2)、(3),这些位置的运动点可能会被判定为背景点;这些被判定为背景点的像素点,不断向周围进行扩散侵蚀,最终长时间停留的运动目标区域将被完全侵蚀成为背景。
(3)当运动目标离开后,原来所停留的区域由于灰度值与周围背景点的灰度值近似,并且整个区域都被背景点所环绕,所以背景点对所留下的幻影区域能够进行快速地侵蚀,使得整个区域迅速变为背景;对于低速运动的目标,通过同样的方式,能够达到抑制幻影的效果。
(4)对于场景中的光照条件变化,树叶的摇摆等情况,处理过程与阴影、幻影的处理过程类似,也是通过周围背景点灰度值扩散到运动点的样本序列,从而达到抑制场景变化对运动目标检测所带来不利影响的效果。
3 实验部分
为了验证基于随机策略运动目标检测方法的有效性,实验中选择经典的滑动平均法、混合高斯法与本文方法进行对比,为突出效果,整个实验过程中并没有进行诸如滤波、膨胀、腐蚀等辅助性操作。所采取的视频为ICVS-PETS2002室外视频序列,大小为384×288,所用电脑CPU为Intel的P7350,处理速度2 GHz,内存2 GB,编程环境为VC++6.0结合OpenCV。实验部分分为参数选择与对比结果两方面。
3.1 Tv、Tn、Ts参数的确定
基于随机策略运动目标检测方法涉及3个重要的参数;
(1)灰度阈值Tv,与经典的减背景方法类似,一般设置为15~45,取值过高,使正常的运动点判定为背景点,使得运动目标区域形成空洞;取值过小,会引入大量噪声,在本实验下,Tv取值为25。
(2)参数Ts,其作用为通过增加一次随机取值判定来降低样本序列更新速度,具体取值需依据实验环境中CPU处理速度来确定取值,在本实验中,取值设置为10,可以使得样本序列更新速度较为适中。
(3)根据公式(4)、(5)可以看出,P(X≥Tn)的概率与样本序列N大小及次数阈值Tn有关,为使概率值较大,需N取值较大,Tn取值较小,在此处,样本序列大小N取值固定为20可使得样本序列大小适中,既能提高检测精度,又减少内存消耗。
在固定N、Tv、Ts条件下,在上述实验环境中设置Tn的不同取值来观察实验结果。图2为当Tn取不同值时,对第880帧进行检测的情况,这一帧中人车多,场景复杂,易于对比检测效果。

图2 不同取值检测情况(N=20,Tv=25,Ts=10)
从实验结果可以看出,当Tn取值较小,如图2(b)、(c)所示,检测效果较好;当Tn取值变大时,噪声点增多,甚至背景点当成运动点检测出来,检测效果变差,如图2(d)、(e)、(f)所示;图2(b)与(c)对比发现,(c)中小车与右侧行人检测更为完整,所以实验中选择Tn=2较为理想。
3.2 实验结果对比
混合高斯法采用的是文献[6]提出的改进的混合高斯算法。滑动平均法选用的阈值为25,学习率a为0.003,本文方法中Tn为设置为2,Tv设置为25,Ts设置为10,每个像素点的样本点个数N为20,改进的混合高斯模型参数设置为高斯模型个数为5,初始权值为0.05,初始方差为30,背景阈值设置为0.7。实验结果的对比主要集中在3个方面:一是初始化情况;二是幻影校正情况;三是检测精度情况。实验结果如图3、图4、图5所示。
从图3中可看出,第2帧结束后,滑动平均法并未完成初始化,改进的混合高斯法背景能够完成初始化,但检测结果中有较明显的白色噪声点。本文方法在对第2帧进行检测时,只有零星的孤立点,没有成片的斑点,检测效果改善明显。
在图4中,原始视频从第1 601帧开始,右下角小车开始倒车,1 890帧表示该小车倒车结束,并短暂停留一段时间,2 006帧表示该小车已经停留足够长的时间,即将有行人从右下角进入视频场景。从图4(d)可看出,在滑动平均法下,第1 601帧检测结果中有着非常明显的幻影,在图4(f)中,小车直到第2 006帧结束后,依然被检测为运动目标。在混合高斯法下,图4(h)中显示幻影在1 890帧以前就已经消失,图4(i)显示在第2 006帧时,小车部分融入背景。在本文方法下,图4(k)显示在第1 890帧时,小车的幻影已经检测不到,并且小车开始部分融入背景。在2 006帧时,图4(l)显示小车已经大部分融入背景。

图3 背景模型初始化情况对比

图4 幻影的校正情况对比

图5 检测精度情况对比
从图5可看出,第941帧中存在的人、车运动目标相对较多,且3个行人左侧的小车已经停留一段时间。从检测结果来看,在滑动平均法下,那辆停留较久的小车依然作为运动目标被检测出来。在混合高斯法下,运动目标的阴影被误检出来,阴影抑制情况不理想,导致3个行人间无隔断,连成一整片。本文方法检测效果下,首先阴影抑制效果非常明显,3个行人之间并未连接起来。其次,停留的小车能够顺利融入背景。
内存消耗方面,在当前实验条件下,滑动平均法内存消耗量为9.392 KB,混合高斯法的内存消耗量为44.212 KB,本文方法的内存消耗量为10.160 KB。通过上述实验结果可以看出,本文方法能够有效抑制阴影、幻影等对运动目标检测带来的不良影响,初始化速度快,检测精度高,内存消耗量较小。
4 结论
本文提出一种基于随机策略的运动目标检测方法,能够通过视频序列第1帧进行背景模型的快速初始化,采用新颖的背景点、运动点判定准则,在背景模型的更新过程中兼顾样本点的光谱、时间、空间特征;相对于混合高斯法和滑动平均法,本文方法易于编程实现,降低了算法的复杂程度和内存消耗量,具有较强的可操作性和实用性。通过实验证明该方法有着良好的检测效果,能够有效抑制阴影、幻影,对场景变化具有较强的适应性。
[1]Chen T P,Haussecker H.Computer vision workload analysis:case study of video surveillance systems[J].Intel Technology Journal,2005,9(2):109-118.
[2]Cucchiara R,Grana C,Piccardi M,et al.Detecting moving objects,ghosts,and shadows in video streams[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2003,25:1337-1342.
[3]Friedman N,Russell S.Image segmentation in video sequences:a probabilistic approach[C]//Proceedings of the 13th Conference on Uncertainty in Artificial Intelligence,1997.
[4]Stauffer C,Grimson W E L.Adaptive background mixture models for real-time tracking[C]//Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition,1999.
[5]Stauffer C,Grimson W E L.Learning patterns of activity using real-time tracking[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2000,22(8):747-757.
[6]Kaewtrakulpong P,Bowden R.An improved adaptive background mixture model for real-time tracking with shadow detection[C]//Proceedingsofthe2ndEuropeanWorkshop on Advanced Video Based Surveillance Systems,2001.
[7]Lee D S.Effective gaussian mixture learning for video background subtraction[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2005,27(5):827-832.
[8]Zivkovic Z.Improved adaptive Gaussian mixture model for background subtraction[C]//Proceedings of the 17th International Conference on Pattern Recognition,2004,2:28-31.
[9]Li L,Huang W,Gu I Y,et al.Statistical modeling of complex backgrounds for foreground object detection[J].IEEE Transactions on Image Processing,2004,13(11):1459-1472.
[10]Piccardi M.Background subtraction techniques:a review[C]// Proceedings of the IEEE International Conference on Systems,Man and Cybernetics,2004.
HU Xiongge,WANG Yaonan
College of Electrical and Information Engineering,Hunan University,Changsha 410082,China
A method for finding moving objects by using random strategy is discussed.There are several innovations:firstly,the background model is initialized by the first frame of the video sequence;secondly,a unique decision rule is established to discriminate the moving pixels and the background pixels;thirdly,when updating the background model,not only updates the sample sequence of the current pixel,but also updates the neighborhood’s sample sequence.The random strategy is used in the process of initialization and updating.The spectral,spatial and the temporal features of pixels are exploited.The proposed method, compared with the running average method and the improved Gaussian mixture model method,is proved to be simple but efficient with lower computational cost and higher accuracy.
sample selecting;decision rule;background updating;random strategy
提出一种基于随机策略进行运动目标检测的方法。方法的主要创新点:(1)利用视频序列第1帧完成背景模型的初始化;(2)建立特定的运动点与背景点判定规则;(3)背景模型更新过程中不仅更新当前像素点的样本序列,同时更新其邻域的样本序列。在背景模型初始化与更新过程中,使用随机策略进行样本序列的更新。该方法利用了像素点的光谱、空间和时间特征,从而提高了检测效果。通过与滑动平均算法、改进的混合高斯模型算法进行实验比较,结果证明该方法是一种运算量小,准确率高,简单高效的运动目标检测方法。
样本选择;判定规则;背景更新;随机策略
A
TP391.41
10.3778/j.issn.1002-8331.1110-0601
HU Xiongge,WANG Yaonan.Research on moving objects detection by using random strategy.Computer Engineering and Applications,2013,49(13):128-132.
国家自然科学基金(No.60835004);国家高技术研究发展计划(863)(No.2007AA04Z244)。
胡雄鸽(1985—),男,硕士研究生,主要研究领域为计算机视觉;王耀南(1957—),男,教授,博士生导师。E-mail:278409580@qq.com
2011-11-02
2012-01-02
1002-8331(2013)13-0128-05
CNKI出版日期:2012-03-21http://www.cnki.net/kcms/detail/11.2127.TP.20120321.1735.050.html
