基于分类矩阵ID3决策树的数据预处理技术研究*
2013-07-11崔良中
林 超 崔良中 周 钢
(1.92941部队 葫芦岛 125001)(2.海军工程大学电子工程学院计算机工程系 武汉 430033)
1 引言
在数据挖掘的实际数据处理中,经常遇到冗余数据、缺失数据、不确定数据和不一致数据等情况,在这些“脏数据”基础上进行数据挖掘,会使得分析和评估不准确、不全面,进一步影响从数据集中抽取模式的正确性和导出规则的准确性,从而导致错误决策和预测。因此,在进行数据挖掘之前进行数据预处理具有重要意义。一般来讲,预处理工作一般要占整个数据挖掘的40%~90%的工作量[1]。数据预处理方法主要包括数据清理、数据集成和变换、数据规约[2]。本文主要研究数据清理中的缺失数据填补和异常数据处理的问题。
文献[3]中研究了贝叶斯、决策树等方法在数据预处理中的应用,并得出决策树方法具有更好效果的结论。本文主要对常见决策树ID3算法进行分析,并针对ID3算法存在的问题,引入分类矩阵方法,着力在克服多值偏向性和提高分类速率方面进行改进,并用实例进行测试验证,最后给出该算法在数据预处理中缺失数据填补和异常数据处理上的具体应用。
2 ID3决策树算法
决策树分类算法以其易用提取显式规则、计算量相对较小、可以显示重要的决策属性和较高的分类准确率等优点而得到广泛的应用。其中,ID3算法是J.R.Quinlan于1986年首先提出的一个经典决策树算法,该算法以信息论为基础,把信息增益度量属性选择,选择分裂后信息增益最大的属性进行划分[4]。ID3算法根据不同的特征,以树型结构表示分类或决策集合,发现规律并产生规则,其主要优点是描述简单,分类速度快,特别适合大规模的数据处理[5]。
2.1 ID3决策树分类过程
决策树分类的建立过程与决策树分类模型进行预测的过程实际上是一种归纳演绎过程。归纳过程就是由用于分类的数据得到决策树分类模型的过程,而演绎过程就是用决策树分类模型对未分类数据进行分类的过程。但是为了保证演绎的准确性,需要增加测试集测试的环节,因此决策树分类的过程就是对训练集归纳,用测试集测试,最后演绎未分类数据的过程,如图1所示:

图1 决策树分类过程
2.2 ID3决策树的建立
建立决策树就是以实例为基础的归纳学习,即从一组无次序、无规则的事例中推理出决策树表示形式的分类规则,从而形成决策树。其实质是利用训练样本集来建立并进化出一棵决策树,建立决策树模型。目的是利用建立的决策树生成分类规则,从而再根据各个数据的属性值实现对数据集的分类[6]。
对于分类属性A,假设具有v个不同的值(a1,a2,…,av),那么数据样本总集合S可以划分为v个子集(s1,s2,…,sv),其中Sj是S中具有aj的样本,sij是子集Sj中Ci的样本数。那么,在属性A上划分子集的熵为

那么,针对属性A划分的信息增益为

ID3算法策略如下:1)判定树以代表训练样本的单个节点开始;2)如果样本都在同一个类,则该节点成为树叶,并用该类标记;3)否则,使用称为信息增益的基于熵的度量Gain(C,T)作为启发信息,选择最好将样本分类的属性作为该节点的“测试”或“判定”属性;4)对测试属性的每个已知的值,创建一个分枝,并以此为根据划分样本;5)使用同样的过程,递归地形成每个划分上的样本判定树。当出现下列情况时停止递归划分:给定节点的所有样本属于同一类:没有剩余属性可以用来进一步划分样本;没有剩余样本。
2.3 ID3决策树算法的局限性
ID3算法作为最典型的决策树算法,具有较好的分类效果和决策预测能力,但是ID3算法也有一些局限性[7],主要集中表现在:
1)这种基于信息熵的计算方法容易产生多值偏向问题,即偏向于选择属性取值较多的非类别属性,而属性值较多的非类别属性并不总是最优的;
2)数据集越大,非类别属性越多,需要的计算时间就会急剧增加;
3)ID3算法对噪声比较敏感。Quinlan定义的噪声是训练集合中的错误,这种错误包含两种:一种是属性取值错误,另一种是类别错误。
3 基于分类矩阵的ID3算法
为了针对ID3算法局限性进行改进,本文定义了一种用于决策树分类的矩阵,通过将矩阵作为增益参数来进行改进。
3.1 基于分类矩阵的ID3算法定义
在给定的一个训练集T中,若按照其中任意一个非类别属性X= {X1,X2,…,Xm}将T分为集合T1,T2,…,Tm,其中Ti(i=1,2,…,m)又按照类别属 性C={C1,C2,…,Cn}分为了m×n个部分,形成了X到C的映射,本文将这种映射定义为分类矩阵,记为分类矩阵AX,C,且

其中AX,C中的任一位置元素定义为aij(i=1,2,…,m;j=1,2,…,n;aij是非负整数)表示在训练集T中,同时对应属性值Xi和属性值Cj的实例个数,而所有元素之和就是训练集T的总个数。属性X和属性C的各个属性值可以是无序的,因此任意对分类矩阵AX,C进行行交换或列交换,得到的矩阵仍然属性X到属性C的映射矩阵,只不过交换后矩阵元素对应的属性值应做相应的交换。
根据分类矩阵特征,用Gain(AX,C)代替增益Gain(X,T),经推算基于分类矩阵的增益公式如下:

根据式(1)定义,Gain(X,T)具备性质:
1)增益非负性。根据增益的定义可知信息量恒为非负值,即在任意非空的训练集T中,对于任意非类别属性X都存在Gain(X,T)≥0。
2)矩阵扩展后增益不变。对于上述矩阵Q,根据Gain(X,T)定义可知若存在任意矩阵U:

(其中O为相应维数的零矩阵)都有

3)无序性。任意对分类矩阵AX,C进行行交换或列交换,得到的新的分类矩阵A*X,C,其基于分类矩阵的增益仍不变,即

3.2 多值偏向性的克服
文献[8]仅指出了ID3算法多值偏向,为克服ID3算法的多值偏向,基于分类矩阵的决策树算法引入一个权重因子t,将增益与权重因子的乘积暂时作为属性选择标准,其中t=1/log2m,m为属性X的取值个数,即属性的选择标准暂时修改为式(2)如下:

引入权重因子t原因如下:
1)对于任意训练集,其增益都为非负且不大于log2m,而且log2m是定值,其计算速度相对于增益的计算可忽略。
引入权重因子t,并将因子值定为t=1/log2m,可以使增益缩放到[0,1]范围内进行比较,从而使比较更固定,更准确,同时又基本保持了其原有的计算速度。
2)引入权重因子t,克服了ID3算法的多值偏向性。根据文献[9]分析可知,引入权重因子t后,如果有式(3)如下

该式(3)恒成立,则说明改进的决策树算法在建树过程中仍具有多值偏向。反之则该算法不具有多值偏向性。
根据Gain(AX,C)性质1,Gain(AX,C)都是非负的,那么必然存在任意m×n阶的分类矩阵AX,C,使Gain(AX,C)>0,现假设AX,C就是这样的矩阵(一般情况下,在属性选择时将不会选择增益为0的非类别属性,因此讨论增益为0的情况也是没必要的),同时令新映射:
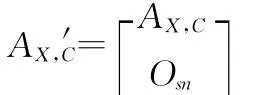
其中Osn为s×n阶的零矩阵,s>1,那么由Gain(AX,C)性质2和性质3,可知

同时m+s-1>m,那么有

以上假设说明,引入权重因子t后,新映射的增量存在小于0的情况,式(3)非恒成立,因此避免了算法的多值偏向,从而使分类时,尤其是在各个非类别属性取值个数差别较大时,能更加准确地选择非类别属性,提高分类准确率,即降低了分类的噪声敏感性。
3.3 分类速率的改进
当数据集越来越大,非类别属性越来越多时,分类时间问题就凸现了出来。分类的时间大部分用于了增益的计算上,分析基于分类矩阵的增益Gain(X,T)定义式(1)可知:
1)算法的计算环节需要不断的进行形式为xlog2x的计算(x为0到训练集总个数之间的整数),而这种对数计算的时间复杂度相对与从数组中读取是很高的。
2)对于任意给定的一个训练集T,其类别属性的信息量Info(T)即
是不变的,那么对应于定义式(1)则其前两项是不变的。
3)对于任意给定的一个训练集T,定义式(1)的除数项都是不变的。
因此若要加快分类速率,减少分类时间就必须针对以上问题改进,本文改进的方案是:
(1)在实际的应用过程中,我们可以事先利用数组来存放形式为xlog2x的对数值,计算过程中只需要不断的从数组中读取即可。例如本文在MATLAB仿真中利用数组arr(1)~arr(sum+1)来存放xlog2x的从0到1*log21~sum*log2sum的数值(sum表示训练集的总个数),从而大大缩短了计算的时间。
(2)在非类别属性个数较多时,只计算一次定义式(1)的前两项。
(3)去除式(1)的除数项,从而减少不必要的计算开支。
因此,综合以上改进方法,引入权重因子t后,Gain(X,T)定义式(1)可以更改为
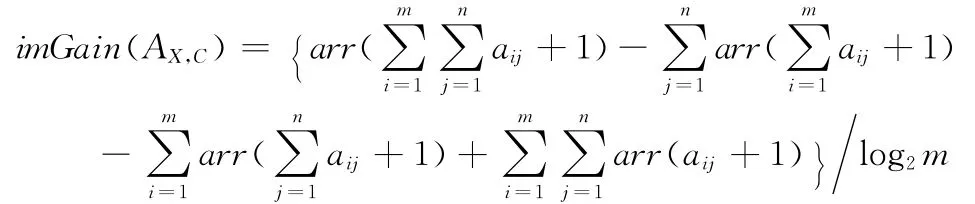
用imGain(AX,C)代替Gain(X,T)作为非类别属性的选择标准来对数据集进行分类,明显地将克服多值偏向性并且能提高分类的速率。
4 实例验证和应用
4.1 实例数据验证
为了测试本文方案的改进程度,本文采用UCI机器学习数据库(其网址为:http://archive.ics.uci.edu/ml/datasets.html)中的Car Evaluation数据集和Nursery数据集进行对比验证。验证的方法是采用对较小数据集Car Evaluation从第1条数据开始每4条数据进行一次抽样,得到432条数据作为训练集,其余作为测试集,而对于较大数据集Nursery从第1条数据开始每8条数据进行一次抽样,得到的1620条数据作为训练集,其余作为测试集。
在同一台电脑上,利用MATLAB对以上数据集各进行50次实验,每次实验都对训练集经行1000次连续重复分类,而且每次分类都让决策树完全生长。求其单次分类平均值、得到的叶子节点个数和利用测试集测试出分类的精确率,得到的实验数据如1所示。
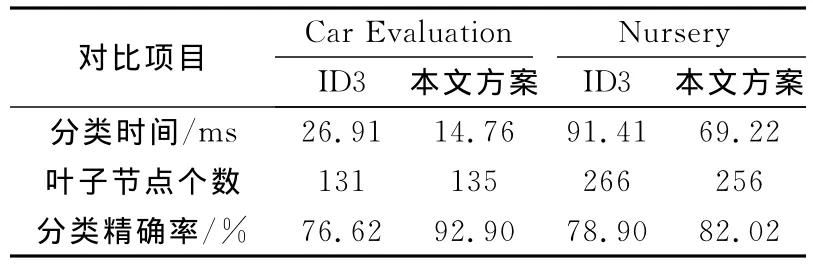
表1 决策树完全生长的实验结果
由于上述实验得到的决策树是完全生长的,很多叶子节点都只有一个或两个实例,相对于训练集的样本个数是可以忽略不计的,而且适量的减少节点可以使决策树得到简化,从而使分类规则更容易理解。本文使用预剪枝的方法,设定其阈值为3,即实例个数小于3时,将停止相应树枝的生长。在此情况下,再次对上述数据集进行比较,得到的实验数据如表2所示。

表2 阈值设为3时的实验结果
对比表1和表2的叶子节点数可知,设定阈值后叶子节点数,即分类规则,将大大减小,从而更能说明分类方案的优劣。对比表3的各项可以说明,决策树规则生成过程中,相比于ID3算法,使用本文改进算法发现:分类速率大大提高;生成规则个数有所减少;分类精确率有所提高。从而达到了对原有算法改进的目的。
4.2 算法应用
用基于分类矩阵的决策树算法建立分类模型,在数据挖掘的数据预处理中实现缺失数据的填补和异常数据的处理。这里主要介绍该算法在这两个方面的具体应用方法:
1)缺失数据的填补。
对于缺失值的处理,分为删除存在缺失值的个案和缺失值插补两种方法[10]。在缺失数据填补的过程中,需要删除含有较多缺失值的数据、较少完整值的属性和独立的属性。缺失值较多将导致数据无法填补,独立的属性应当删除。然后缺失数据的子集按照完整数据子集建立的规则进行填补,最后进行合并,就得到了填补的数据集。
2)异常数据处理
在数据挖掘过程中,数据集可能包含一些数据对象,它们与其他数据的一般行为或模型不一致,这些对象便成为异常数据。异常数据是指在数据集中与众不同的数据,使人怀疑这些数据并非随机偏差,而是产生于完全不同的机制[11]。
异常数据处理的方法有多种,比如基于统计的方法、基于距离的方法、基于偏离的方法、基于密度的方法等[13]。按本文算法的异常数据处理方法,需要首先对连续属性离散化,对离散化后的数据建立决策树分类规则,然后利用规则对数据集进行规则匹配,找出异常数据,并通过人工干预决定数据的修改或删除,最后得出规则的数据集。
对于缺失数据和异常数据,人工的干预是必不可少的,以保证用来进行数据挖掘进行预测和决策的准确性。
5 结语
本文提出了一种基于分类矩阵的ID3算法,该算法引入分类矩阵方法,对ID3算法的多值偏向性和分类速率进行改进,并利用实例对改进效果进行验证同时给出了数据挖掘的预处理中,本改进算法在缺失值填充和异常数据处理中的具体应用。通过分析,可以知道该改进算法能有效克服多值偏向性并提高分类速率,并在数据预处理中有很好的应用。
[1]Garcia-Laencina P J,Sancho Gomez J L,Figuesiras Vidal A R,Verleysen M K.nearest neighbors with mutual information for simultaneous classification and missing data imputation[J].Neurocomputing,2009,72(7-9):1483-1493.
[2]李雄飞,李军.数据挖掘与知识发现[M].北京:高等教育出版社,2003:23-25.
[3]周钢,李昂新.两种填充空缺值方法在技术级别判定中的应用比较[J].舰船电子工程,2011(7):109-112.
[4]Quinlan J R.Induction of decision tree[J].Machine learning,1986(1):81-86.
[5]邹志文,朱金伟.数据挖掘算法研究与综述[J].计算机工程与设计,2005,26(9):2304-2307.
[6]武献宇,王建芬,谢金龙.决策树ID3算法研究及其优化[J].微型机与应用,2010,29(21):7-9.
[7]张凤莲,林健良.新的决策树构造方法[J].计算机工程与应用.2009,45(10):141-143.
[8]Quan Liu,Daojing Hu,Qicui Yan.Decision Tree Algorithm Based on Average Euclidean Distance[C]//2010 2nd International Conference on Future Computer and Communication(ICFCC),2010:507-511.
[9]狄文辉,李卿,楼新远.基于修正系数的决策树分类算法[J].计算机工程与设计,2008,29(24):6344-6346.
[10]武森,冯小东,单志广.基于不完备数据聚类的缺失数据填补方法[J].计算机学报,2012(8):1726-1738.
[11]郝慧丽,刘先勇.含噪点云预处理技术研究[J].微型机与应用,2012(12):68-71.
[12]李小飞.基于BP网络的GDP预测数据预处理方法研究[J].计算机与数字工程,2011(9).
[13]陈文伟,黄金才.数据仓库与数据挖掘[M].北京:人民邮电出版社,2004:42-44.
