基于GPU的遥感图像融合并行算法研究
2013-05-14刘昌明张丽萍
赵 进,刘昌明,宋 峰,张丽萍
(1.海军计算技术研究所,北京100086;2.68310部队,陕西 西安710600;3.91731部队,北京102200)
随着遥感传感器技术的发展,获取遥感数据的方式已经由单一可见光模式发展成多种传感器模式。每一种传感方式获取的数据信息相对单一,融合不同传感方式获取的数据信息可以有效提高数据信息量,提供更为精确的遥感图像信息。
POHL C和GENDEREN J L[1]对图像融合给出了如下定义:通过特定算法将两幅或多幅图像合成一幅新的图像。图像融合可以分为像素级、特征级和决策级3个层次,其中像素级融合需要处理的数据量最大,计算过程也最复杂。随着遥感图像的时间、空间和光谱分辨率逐步提高,融合算法处理结果的精度要求同时在逐步提高,导致图像融合的处理速度需求逐步增大,计算量大、计算过程复杂的遥感图像融合在处理速度上面临着新的问题与挑战。近几年来,基于GPU的异构平台在通用计算领域得到快速发展,已经在许多方面得到了有效应用[2-4],为遥感图像融合快速处理技术研究提供了新的思路。
结合CPU-GPU异构平台面向通用计算领域的性能优势,针对遥感图像融合面临的处理速度问题,通过分析图像融合处理过程的特点,将像素级融合的BROVEY变换和YIQ变换融合算法在基于GPU平台上进行了并行研究与实验,获得了突出的性能。
1 研究背景
1.1 CUDA编程模型
NVIDIA公司的CUDA[5]语言是基于C语言的扩展,主要使用API调用底层功能进行处理与计算,使熟悉C语言的编程人员能够快速运用CUDA开发通用计算程序。在CUDA结构中,CPU端被称为Host,GPU端被称为 Device,采用 SIMT(Single Instruction Multiple Thread)模式执行程序[5]。用户把可以放在GPU上并行执行的程序组织称为Kernel内核程序。在CPU端执行的程序称为Host宿主程序,控制Kernel的启动、加载或保存与 GPU的通信数据,以及执行部分的串行计算。Device端在执行时创建很多的并行线程Thread,线程组织成线程块Block,而 Block再组成网格 Grid。每个 Thread执行自己的程序Kernel,Block内的线程通过共享存储器(Shared Memory)分享数据。并行线程通过GPU上的众多计算内核实现并行处理,实现整个程序的性能加速[5]。
1.2 两种典型的像素级融合算法
遥感图像融合在遥感图像配准基础上进行,待融合的两幅遥感图像具有相同大小,每个像素点的融合或是独立执行,或者只需要少量周围像素点数据协助执行。
1.2.1 BROVEY变换融合算法
BROVEY变换融合算法[6]是一种基于色度的变换,属于彩色空间的方法。它是将多光谱的色彩空间进行分解得到色彩与亮度,再用其全色图像进行计算。这种算法像素点彼此单独执行,具有良好的并行性,算法执行简单,在保留了较多光谱信息的同时,也具有较快的处理速度。
1.2.2 YIQ变换融合算法
YIQ颜色系统是一种用于电视信号传输NTSC制式的彩色编码系统。其中,Y对应亮度信息,I、Q分量反映图像与硬件相关的彩色信息。YIQ变换融合算法[7]属于彩色空间的方法,计算较为复杂,像素点在变换到YIQ分量后,需要使用直方图匹配,具有一定的并行性。
2 并行设计及优化实现
2.1 优化策略
2.1.1 数据异步传输
遥感图像融合CUDA并行计算程序在CPU-GPU异构平台上执行,该平台上CPU与GPU工作任务不同。CPU为GPU准备执行数据,同时执行逻辑控制等复杂事务。CPU加载数据时,采用同步方式启动传输指令;传递数据时,CPU处于空闲状态,计算资源不能得到充分利用。优化时CPU采用异步方式传输数据,启动传输指令后直接进行后续事务处理,使CPU执行与加载数据重叠,提高资源利用率。
坐标转换矩阵在运动学中是用4×4矩阵来描述两个刚体的空间几何关系。基于几何变动在装配体中的传递方式,本文用坐标转换矩阵来表达零件间特征或要素间的几何关系。两个不同坐标系之间的平移和旋转关系可用转换矩阵T表示[5]:
2.1.2 访存优化
GPU线程对全局存储器(Global Memory)进行一次访存需要400~600个时钟周期,对共享存储器(Shared Memory)、寄存器(Register)等快速存储部件访存一次只需要 4个左右的时钟周期。优化时充分利用GPU显存中的多层次存储部件,发挥快速存储部件读取数据优势,最大化提高执行性能。
2.2 融合算法的CUDA并行实现
综合融合算法CUDA优化策略,进行融合算法CUDA程序并行设计与实现时,重点研究以下问题。
2.2.1 线程块参数与网格参数的设置
CPU-GPU异构计算模式中,每个线程块只能拥有有限线程数,每个流处理单元SP最多可同时执行256整数倍线程,根据遥感图像数据以二维方式组织的特点,将块Block设置为16×16二维形式,每个块有256个线程,使每个SP单元能够满负载执行,最大限度地提高资源利用率。设计实现时,线程网格大小的设置与图像大小有关,网格的宽度设置成(imagewidth+dimBlock.x-1)/dimBlock.x,高度设置成(imageheight+dimBlock.y-1)/dim-Block.y,保证线程块是一个整数。线程块规模与遥感图像规模有关,与GPU处理核心数量无关。这样同一问题能够在不同型号的GPU上执行,形成CUDA并行程序良好的可移植性。
2.2.2 线程网格规模大于图像规模
令i为线程网格宽度索引号,j为线程网格高度索引号,imagewidth为图像宽度,imageheight为图像高度。通过 加 入 if(i<imagewidth&&j< imageheight) 语 句 控 制 线 程执行对应像素点。空执行线程最多可以为255×I+255×J-255×255个,其中,I是线程网格的宽度,J是线程网格的高度。与具有的大量执行线程相比,空执行线程占很小比例,几乎不需要执行时间。与并行加速获取的提升时间相比,空执行少量线程浪费的时间可以忽略。
3 实验与结果分析
实验硬件为:Inter(CR)Core(TM)i5四核2.67GHz CPU,2 GB内存,NVIDIA GeForce GTX 460 GPU,1GB显存,336个SP计算单元。操作系统为Linux Ubuntu 10.10,串行程序为C语言实现的标准程序。融合的图像是IKONOS扫描北京故宫的遥感卫星图像。
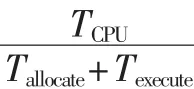
(1)CPU-GPU异构计算平台拥有更多的计算资源,使Texecute<TCPU。
(2)图像规模与算法计算复杂度都较小时,Tallocate>(TCPU-Texecute),出现CPU-GPU异构平台并行执行时间大于CPU串行执行,性能下降。随着图像规模与算法计算复杂度某一项或同时增加出现 Tallocate<(TCPU-Texecute), 总执行时间在CPU-GPU异构平台上得到加速。
(3)在相同的计算复杂度下,图像规模使GPU计算核心执行达到饱和时,speedupexecute趋于稳定甚至下降。但因为计算资源的优势,总加速性能仍有提升。
对于融合算法CUDA的并行执行,定义为:

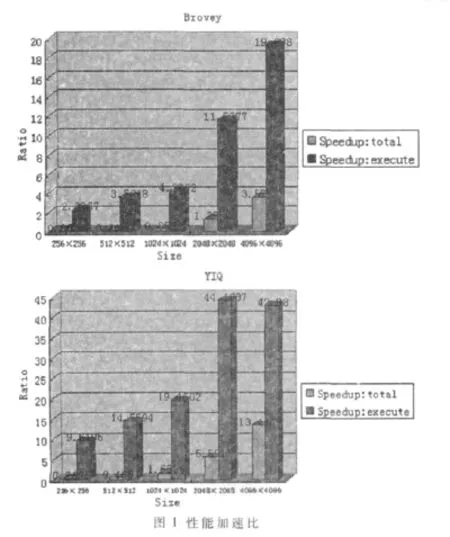
两种融合CUDA程序中Tallocate与Texecute的关系如图2所示。

从图中可以看出,图像规模(如 256×256和 512×512)小时,Pexecute小,算法计算复杂度的不同导致加速比出现不同情况。因此,为进一步提升加速性能,融合算法CUDA并行执行需要最大化地提高Pexecute。
从实验结果可以得到,随着算法计算复杂度与问题规模的增大,加速性能逐渐增加。实验表明,GPU并行处理能够很好地应用于遥感图像融合的算法,将GPU应用到遥感加速处理领域具有很好的应用前景。
本文从遥感图像融合处理背景出发,阐述了研究融合处理加速的意义,然后针对近些年兴起的CPU-GPU异构加速平台,对BROVEY变换和YIQ变换遥感图像融合算法进行了CUDA并行优化实现。研究表明,GPU通用计算技术在遥感图像融合领域具有广阔的应用前景。
[1]POHL C,Van Genderen J L.Multisensor image fusion in remote sensing:concepts,methods and applications[J].International Journal of Remote Sensing,1998,19(5):823-854.
[2]OWENS J,LUEBKE D,GOVINDARAJU N,et al.A survey of general-purpose computation on graphics hardware[J].Computer Graphics Forum,2007,26(1):80-113.
[3]GARLAND M,GRAND S,NICKOLLS J,et al.Parallel computing experiences with CUDA[J].IEEE Micro,2008,28(4):13-27.
[4]LAHABAR S,AGRAWAL P,NARAYANAN P J.High performance pattern recognition on GPU[J].National Conference on Computer Vision Pattern Recognition Image Processing and Graphics,2008:154-159.
[5]NVIDIA.NVIDIA CUDA compute unified device architecture,Programming Guide,Version 2.0.NVIDIA,2008.[EB/OL].http//www.nvidia.com/object/cude_home_new.htm l.
[6]GILLESPIE A R,KAHLE A B,WALKER R E.Color enhancement of highly correlated images-II.channel ratio and chromaticity transformation techniques[J].Remote Sensing of Environment,1987,22:343-365.
[7]Dong Guangjun,Huang Xiaobo,Dai Chenguang.Comparison and analysis of fusion algorithms of high resolution Im-agery[C].International Symposium on Photoelectronic Detection and Imaging:Related Technologies and Applications,Proceedings of SPIE,2008,6625(66250H).
