基于MySQL数据库的优化
2013-04-25吴沧舟兰逸正
吴沧舟,兰逸正,张 辉
(西安电子科技大学 技术物理学院,陕西 西安710071)
在3G与社区网站进行融合的时代,微博、人人网等相关的动态实时信息比重正在不断增长,网站所面临高并发、高流量、大数据量等问题也成为互联网时代的特色。而处于网站存储核心的数据库,其优化问题已成为各大门户网站的重点。而在各类数据库中MySQL由于其低成本及开源等特性被广大网站开发者所热爱。在TechTarget发起的2012年中国数据管理优先度调查中显示,有45.5%的用户表示愿意迁至MySQL数据库平台。
1 基础优化
1.1 MySQL存储引擎的选择
MySQL默认配置了许多不同的存储引擎[1],可以预先设置或者在MySQL服务器中启用。其类型有:MyISAM、InnoDB、MERGE、MEMORY(HEAP)、BDB(BerkeleyDB)、EXAMPLE、FEDERATED、ARCHIVE、CSV、BLACKHOLE。每一种类型,都有其特别之处,这里对几种常用的存储引擎进行分析其余的都略作解释:
MyISAM[2]。适用于以读为主,数据一致性要求不是太高。
(1)不支持事务。表级锁定:其锁定机制是表级索引,这虽然可以让锁定的实现成本很小但也同时大幅降低了其并发性能。读写互相阻塞:不仅会在写入时阻塞读取,MyISAM还会在读取的时候阻塞写入,但读本身并不会阻塞另外的读。InnoDB:行级锁定对高并发有较好的适应能力,但需要确保查询是通过索引完成,适用于数据更新较为频繁的场景。具有较好的事务支持:支持4个事务隔离级别,支持多版本读。行级锁定:通过索引实现,全表扫描仍然会是表锁,注意间隙锁的影响。
(2)读写阻塞与事务隔离级别相关。具有高效的缓存特性:能缓存索引,也能缓存数据。BDB:可替代InnoDB的事务引擎,支持COMMIT、ROLLBACK和其他事务特性。Memory:将所有数据保存在RAM中,在需要快速查找引用和其他类似数据的环境下,可提供快速的访问。Merge:允许MySQL DBA或开发人员将一系列等同的MyISAM表以逻辑方式组合在一起,并作为1个对象引用它们。对于诸如数据仓储等VLDB环境较适合。Archive:为大量较少引用的历史、归档、或安全审计信息的存储和检索提供了良好的解决方案。Federated:能将多个分离的MySQL服务器链接起来,从多个物理服务器创建一个逻辑数据库。适合于分布式环境或数据集市环境。Cluster/NDB:MySQL的簇式数据库引擎,尤其适合于具有高性能查找要求的应用程序,这类查找需求还要求具有最高的正常工作时间和可用性。Other:其他存储引擎包括CSV,Blackhole,以及Example引擎。
显然MySQL为对应各种不同的状况,其本身便已划分了很多存储引擎,选择合适的存储引擎不仅可以获得稳定的服务还能额外增长数据库处理数据的速度
1.2 索引优化
MySQL建有索引机制,而所谓的索引就是用于快速地寻找那些具有特定值的记录,所以MySQL索引都以B-树的形式保存。如图1所示。

图1 student表中的学生数据
现有100个学生的成绩,当执行Select语句查询不及格的学生有多少时,若没有索引,MySQL便会遍历全表,逐个比较。但若在Achievement上建立索引,MySQL便会先查询索引里符合条件的同学,然后再执行数据库读取指定的学生数据,也就是说,数据库的读写操作次数变少了。当然在表格数据较少的情况下,区别不大。
但若假设现在数据库中建有50万张数据的表,如果没有索引,MySQL将会从头到尾检索一次,这样的执行效率将会相当低。可见索引的存在将会大幅的提高检索效率,当然索引也存在一些缺点。索引文件要占磁盘空间。如果有大量的索引,索引文件可能会比数据文件更快地达到最大的文件尺寸。其次,索引文件降低了大多数涉及写入的操作的时间,因为写操作不仅涉及数据行,而且还常涉及索引。
1.3 存储过程
存储过程[3]即为以后使用而保存一条或多条MySQL语句的集合,即批文件。使用存储过程的优点即简单、安全、高性能,而且重要的是与基本的SQL语句相比,它的处理速度更快,但其编写较SQL语句更复杂,对编写者有较高的要求。
1.4 硬件上的提升
以空间换时间,或以时间换空间,可谓是伴随着计算机诞生以来一直存在的事物。如果只是学习,任何一台老式计算机做服务器都没有问题,因为不必担心处理数据耗费的时间问题,但是作为一个高访问量的网站,一台专门的数据库服务器是必要的。以更大的内存节省计算机计算时间,以更出色的硬件性能来完成数据库的存储问题。
2 Sharding
Sharding意为数据切分,涉及的具体步骤是分库分表。数据库的Sharding分为2种,水平切分和垂直切分[4]。前者适合表不多,但每张表的数据较多,后者适合因为表多而导致数据也多,当然多数时候两者可以结合,如图2所示,DB指数据库端,Shard指切分后的数据库。
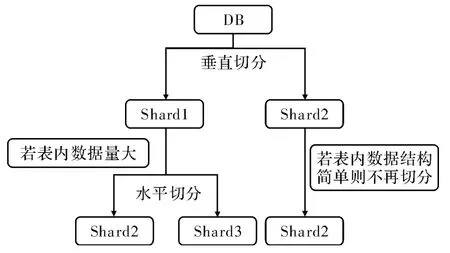
图2 数据库切分示意图
2.1 垂直切分
所谓垂直切分是将组成数据库的表垂直的切开,然后将其分散到多台数据库主机上。例如现有3张表,Student,Teacher,Achievement。那 么Student和Achievement需分到一个库,Teacher分到另一库。这样分的原因是表关联是无法在数据库级别完成的,所以垂直切分中分库的表都是没有关联的。
2.2 水平切分
水平切分是给一个表规定适合的记录数,把超过记录数的记录放入新的表中。例如现在有一张记有500万数据量的单张数据表,切分成10份,分别放入Table1,Table2以此类推至Table10,那么当往表里再更新数据时,就是往任一一个只有50万的数据表中插入数据,此时更改的索引量与原来500万相比将呈指数级下降。实际上便是分表操作。
当然水平切分主要有两种思路[5]:一种是使用MD5哈希,做法是对UID进行md5加密,取前几位,然后就可以将不同的UID哈希到不同的用户表(user_xx)中,如图3所示。
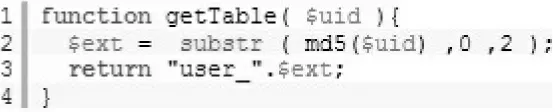
图3 MD5哈希代码
然而这种算法无法扩展表,一旦用户数量过多,则会造成单张表单数据量过大的问题。另一种则是使用移位,方法如图4所示。

图4 移位代码
如图所示,其意思是将uid向右移动20位,这样就可以将约前100万的用户数据放在第一个表user_000,第二个100万的用户数据放在第二个表user_001中,如此循环。直到user_999,可分1 000张,若不够,则改后缀即可。
3 集群
集群(Cluster)技术是使用特定的连接方式,将价格相对较低的硬件设备结合起来,同时也能提供高性能相当的任务处理能力。
如上文提到的提升硬件性能,但是多数时候单台计算机已无法满足软件的需求,便引入集群的概念,即AP+DB的架构:AP指应用程序,DB指数据库端,AP放在一个服务器上,DB放在另一个服务器上,又或者是多台服务器运行一个DB,集群利用的是将一台计算机需要做的事,分散到多台上去完成,就可以更高效地完成单台计算机无法完成的事。
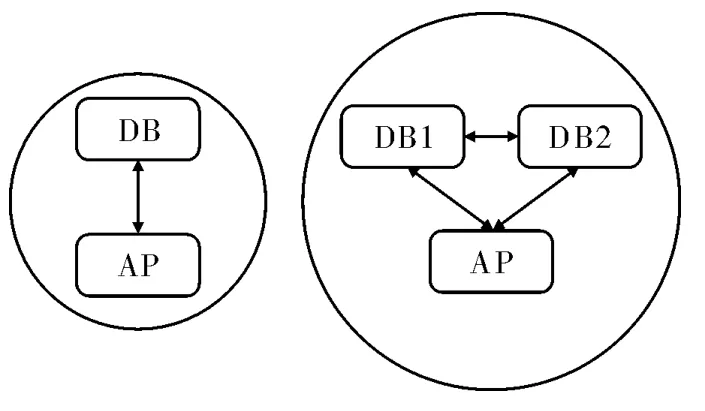
图5 集群示意图
4 结束语
虽然数据库的优化手段有多种,但在面对大流量、高并发量的数据时,有时依然不能很好地解决问题,硬件的读写速度从某种角度讲较大程度上限制了数据库的性能,但以上的优化手段还是可以很好地提升其服务性能。
[1]SABA P.深入理解MySQL核心技术[M].李芳,于红芸,邵健,译.北京:中国电力出版社,2009.
[2] 简朝阳.MySQL数据库性能优化之存储引擎选择[EB/OL].(2012-09-10)[2012-11-05]http://isky000.com/database/mysql-performance-tuning-storage-engine.
[3] 刘晓霞,钟鸣.MySQL必知必会[M].北京:人民邮电出版社,2009.
[4] 简朝阳.MySQL性能调优与架构设计[M].北京:电子工业出版社,2012.
[5]Veda.数据库水平切分的两个思路[EB/OL].(2012-03-02)[2012-11-07]http://www.nowamagic.net/librarys/veda/detail/1528.
[6] 王威.MySQL数据源代码分析及存储引擎的设计[D].南京邮电大学,2012.
[7] 胡要,李燕.MySQL数据库存储引擎探析[J].软件导刊,2012,11(12):129-131.
