藏文音节规则库的建立与应用分析
2013-04-23格桑多吉扎西加高红梅
珠 杰, 欧 珠, 格桑多吉, 扎西加, 高红梅
(1. 西南交通大学 信息科学与技术学院,四川 成都 610031;2. 西藏大学 工学院 计算机科学与技术系,西藏 拉萨 850000)
1 前言
随着现代信息技术的发展和互连网的普及,藏文信息处理技术有了较快的进步。从藏文的属性统计工作开始[1],许多专家通过几十年的努力,从多格局编码的状况[2]到统一编码的时代[3],从多键盘布局的设计到统一键盘布局的出台[4],解决了藏文在计算机中的输入、输出,并在现代互联网上实现了藏文信息的共享。现在不少高校和科研机构,在前人研究的基础上不断探索,开始在藏文语音识别[5]、文字识别[6-7]、分词、词类标记[8]、机器翻译[9]等领域着手研究,并取得了一些研究进展。
随着藏文信息处理技术的进一步发展,藏文文本处理成为藏语自然语言处理的研究内容。藏文音节作为文本组成的重要成分,对其分析是一个基础性工作。根据文献[10]所述,从书面藏文的信源属性来看,藏文文本中的音节有72%的冗余度,这说明3/4的藏文字母是保证依据语法规则来组合藏文音节的,只有28%是可自由选择的[10]。根据此特点,本文以“预组合”的形式建立一个规则库,并分析了在藏文信息处理研究领域中应用的可能性。
本文的结构如下: 第2节介绍了藏文音节的结构;第3节介绍了藏文音节规则库的建设原则、规则库建设、组合情况统计、该组合音节的频率统计和歧义规则的处理内容;第4节介绍了藏文音节规则库的应用范围,包括自动拼写藏文音节、拼写检查、藏文排序和信息提取等领域中的应用;第5节是结论与展望。
2 藏文的结构
藏文音节结构是以基字为核心既有横向拼写又有纵向拼写,前加字、基字、后加字、再后加字是横向拼写;上加字、基字、下加字和元音符是纵向拼写。藏文音节结构十分复杂,字符在音节中的特定位置可以称为“构造位”,根据藏文的文法,各个构造位上出现的字符其性质与数量均有一定的限制,相互之间也形成一种约束关系。
不包括梵音撰写藏文,藏文音节结构中的构造位共有 7 个,例如图1所示。

图1 藏文音节基本结构
每个构造位在藏文字中的表示为: 1是前加位,2是上加位,3是基字位,4是下加位,5是元音位,6是后加位,7是再后加位,分别有前加字、上加字、基字、下加字、元音、后加字、再后加字来表示,在字中的位置如图2所示。
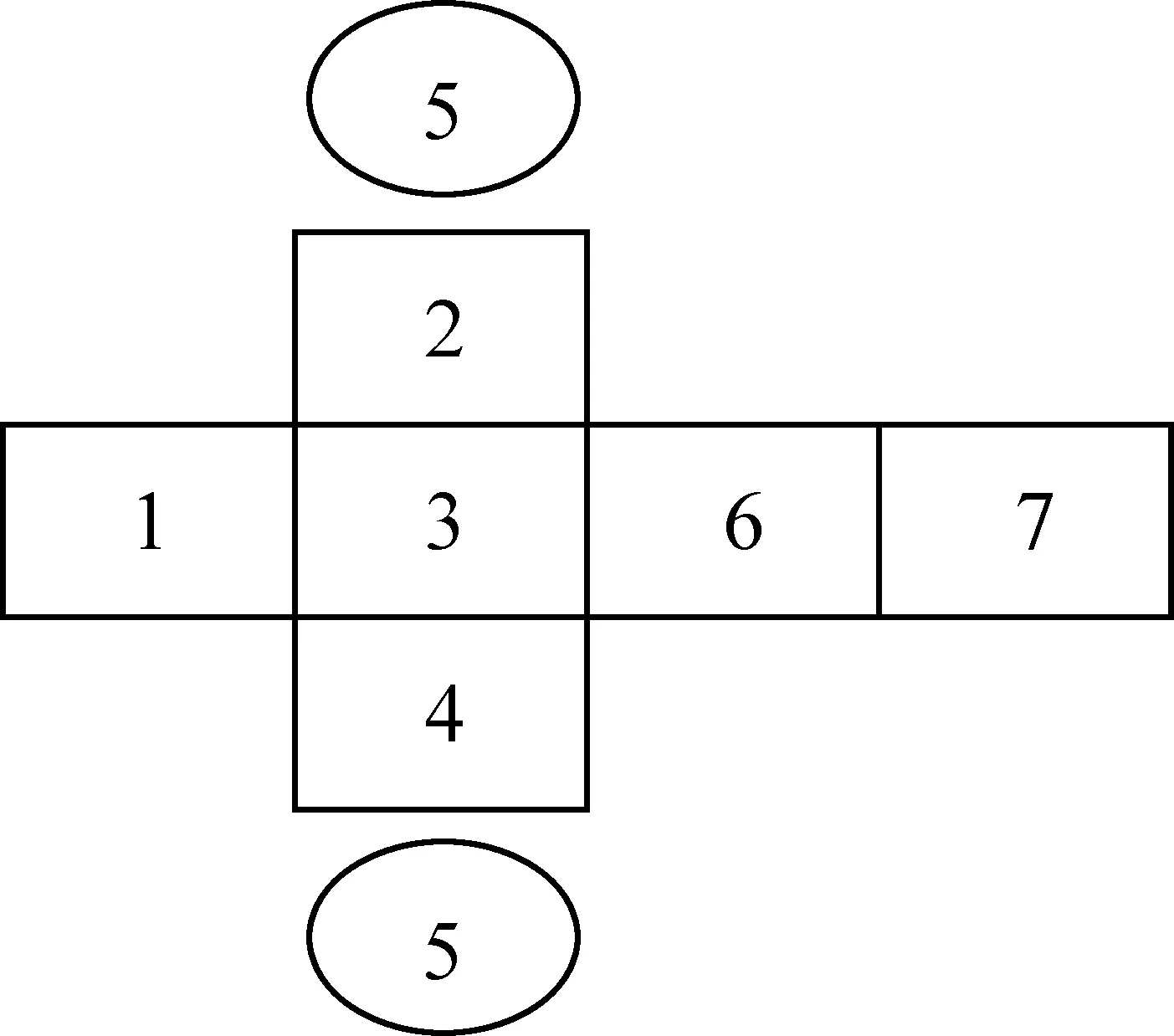
图2 构造位
定义1: 构造位上的字符称为构件,根据不同位置分别称为前加字、上加字、基字、下加字、元音、后加字和再后加字。

3 藏文规则库的建立
3.1 规则库建立原则
首先,根据藏语的语音理论体系,藏语语音可以分为元音和辅音。藏文的语音特性中,对于30个辅音字母进行了字性分类,分为阳性、中性、阴性3种,其中阴性又分为准阴性、极阴性、纯阴性3种,共计5种字性。辅音字母中提取出来的前加字、后加字构件又进行了上述5种的分类。根据每个构件的发音特性,字母组合上有很多限制,以这些限制条件为依据,建立符合文法的藏文规则,本文主要依据前加字与基字、上下字与基字、叠加字符与前加字之间的组合关系来形成固定的字符串,建立藏文的规则库。
其次,3个上加字和4个下加字与基字组合上,有它自身的组合规律,根据这些规律建立规则库。
最后,选择30个辅音字母和10个藏文数字作为规则库的内容之一。4个元音符号、10个后加字、2个再后加字作为动态组合的成分。
3.2 藏文规则库
定义3: 根据藏文的组合关系能够构成一个音节的称为音节字符。
定义4: 藏文30个字符为辅音字符。
定义5: 藏文数字符号为数字字符。
定义6: 藏文中的特殊符号为特殊字符。
定义7: 根据藏文的组合关系能够构成组合字符串,但不构成一个音节的称为规则字符。
根据规则库建立的原则和“规则”的频率统计,建立了规则表。规则表按藏文字母、上加字与基字组合、基字与下加字组合、上加字与基字与下加字组合、前加字与基字组合的分类方式建立了1到17个规则表,如表1至17所示。表的第一列为每个规则序列,第二列为藏文音节规则,第三列为规则组合形成的音节个数,第四列为每个规则的统计频率。在3.3节中介绍频率统计的过程。
3.3 频率和组合统计
为了得到藏文规则库中字符的频率统计,参考《藏汉大词典》, 统计了每一个规则有多少种组合形式,该组合形式就是规则构成的藏文音节个数;参考《现代藏文频率词典》,统计每个规则组合形成的音节频率,是规则库中频率数据来源的主要依据。
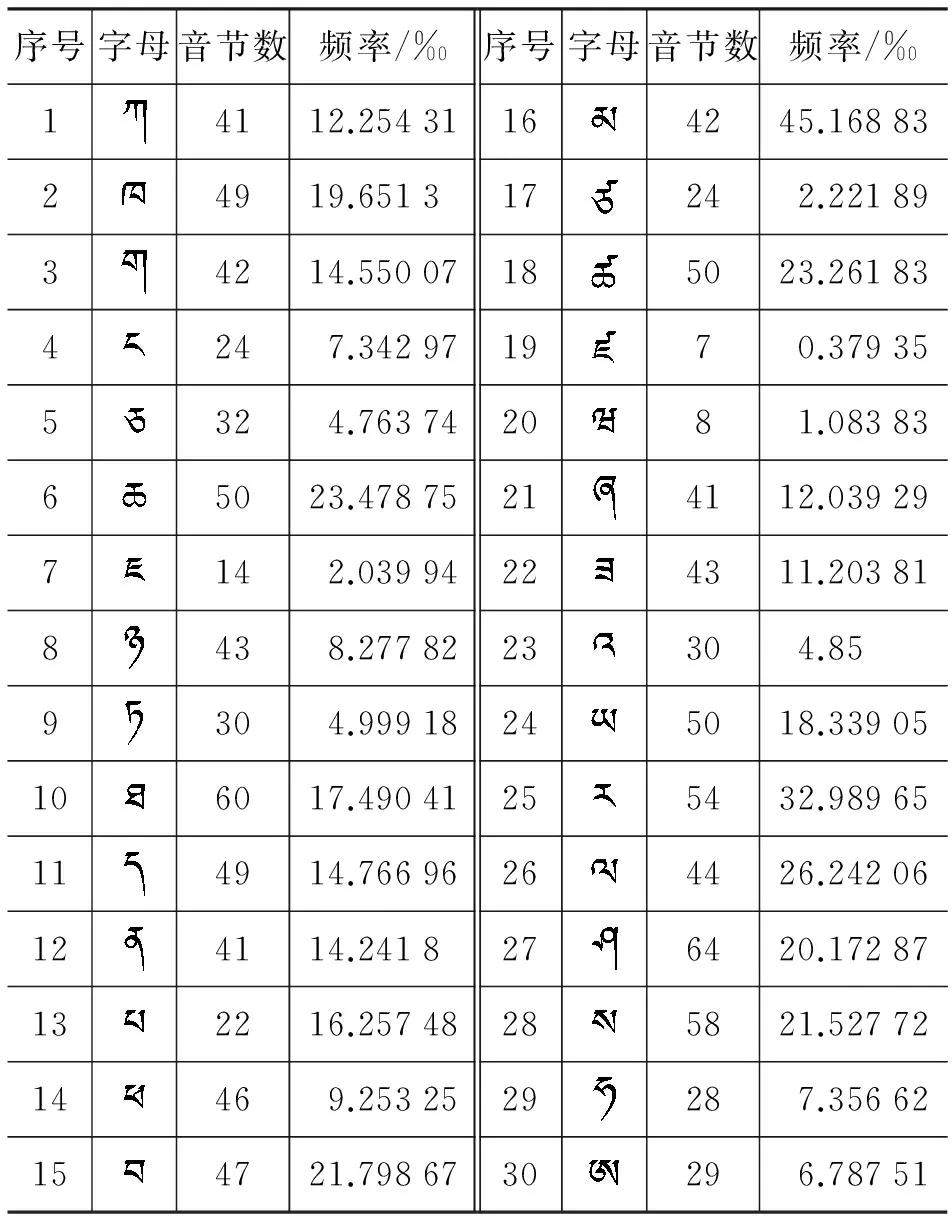
表1 辅音字母规则表
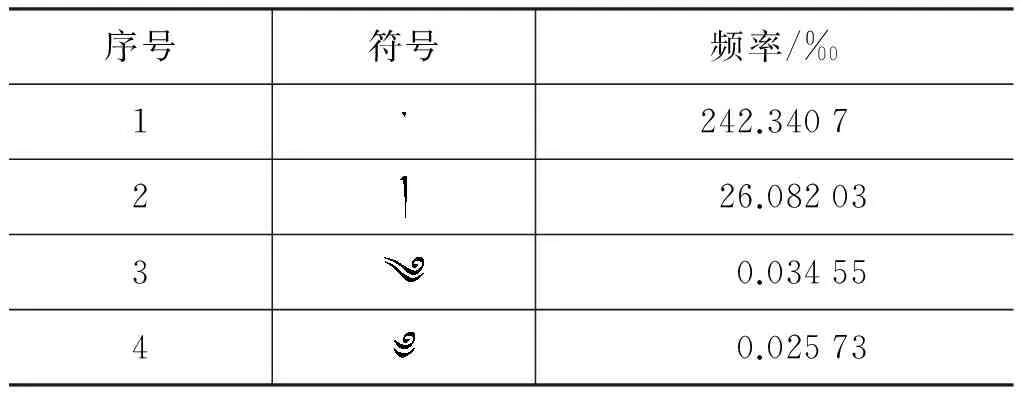
表2 高频符号规则表
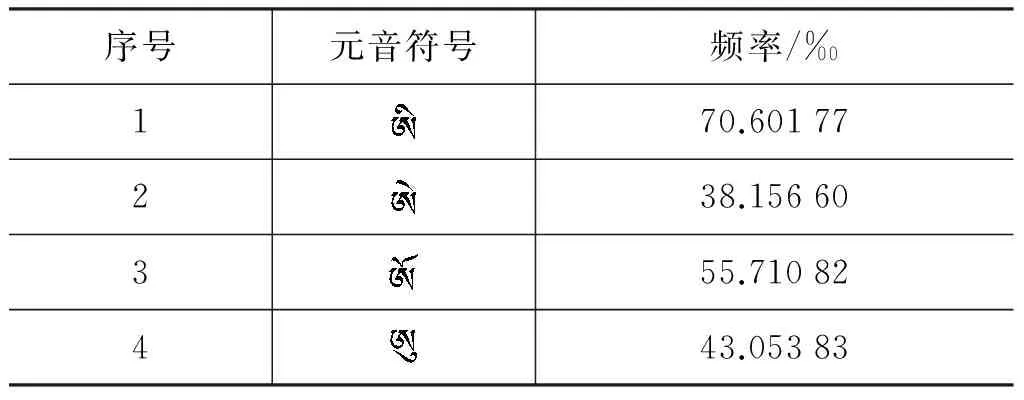
表3 元音字母规则表

表4 上加字规则表之“”
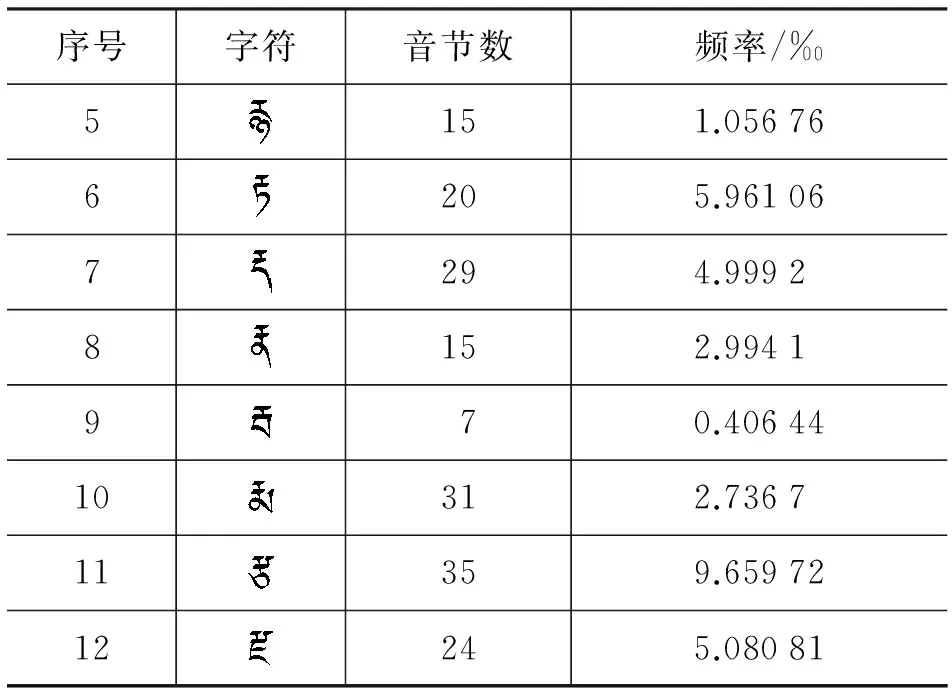
续表

表5 上加字规则表之“”

表6 上加字规则表之“”

表7 下加字规则表之“”

表8 下加字规则表之“”
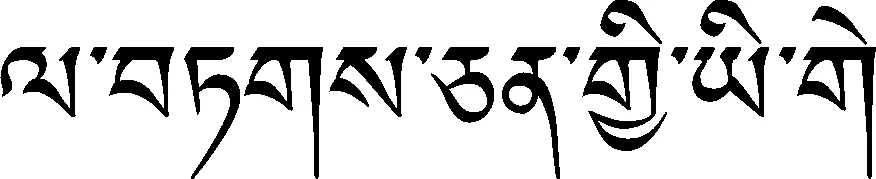
表9 下加字规则表之“”

表10 下加字规则表之“”
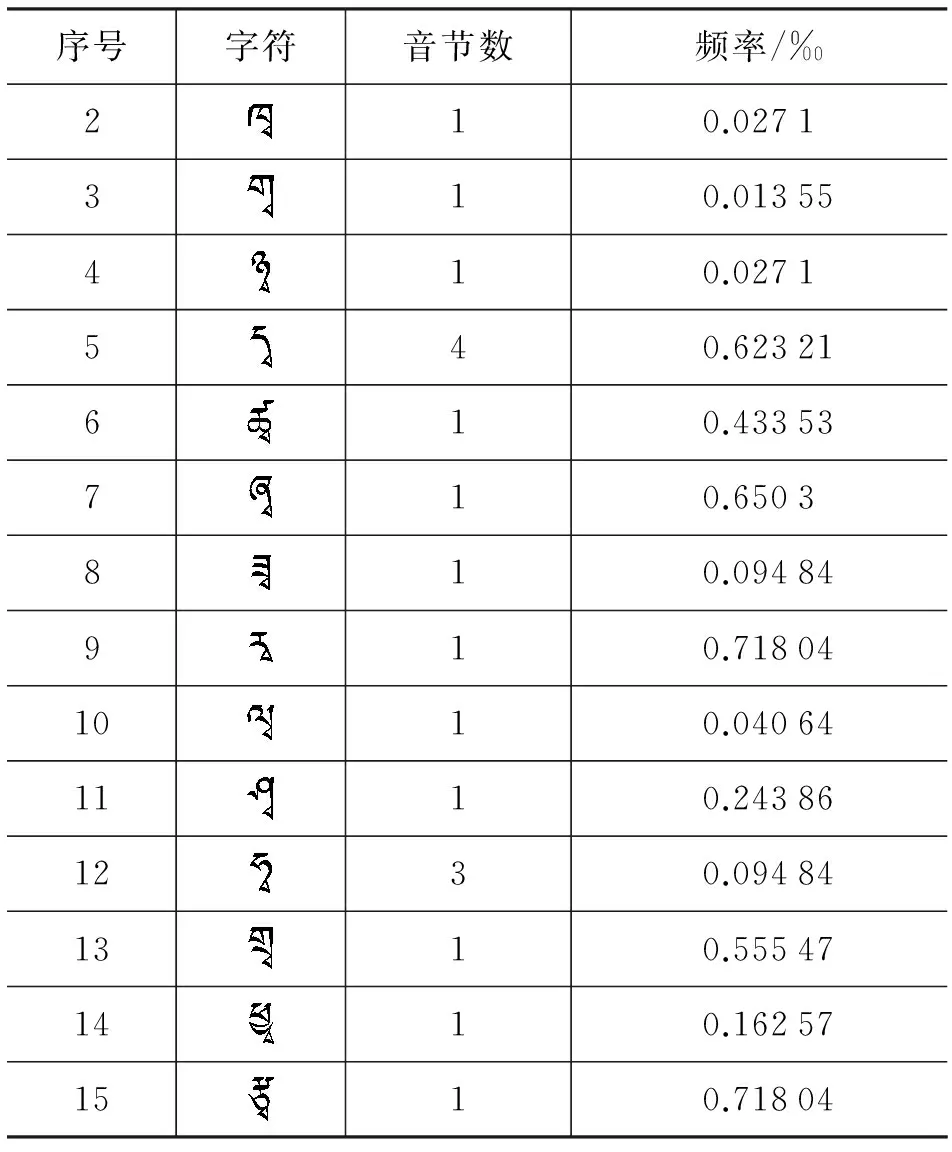
续表

表11 前加字“”匹配规则表

表12 前加字“”匹配规则表
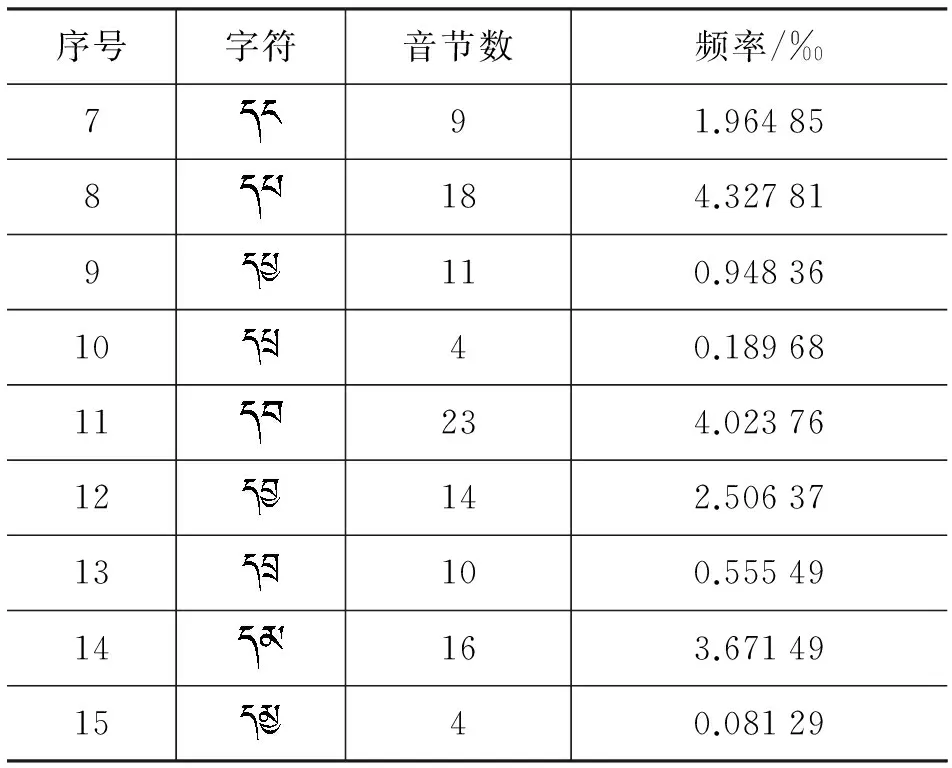
续表
表13 前加字“”匹配规则表
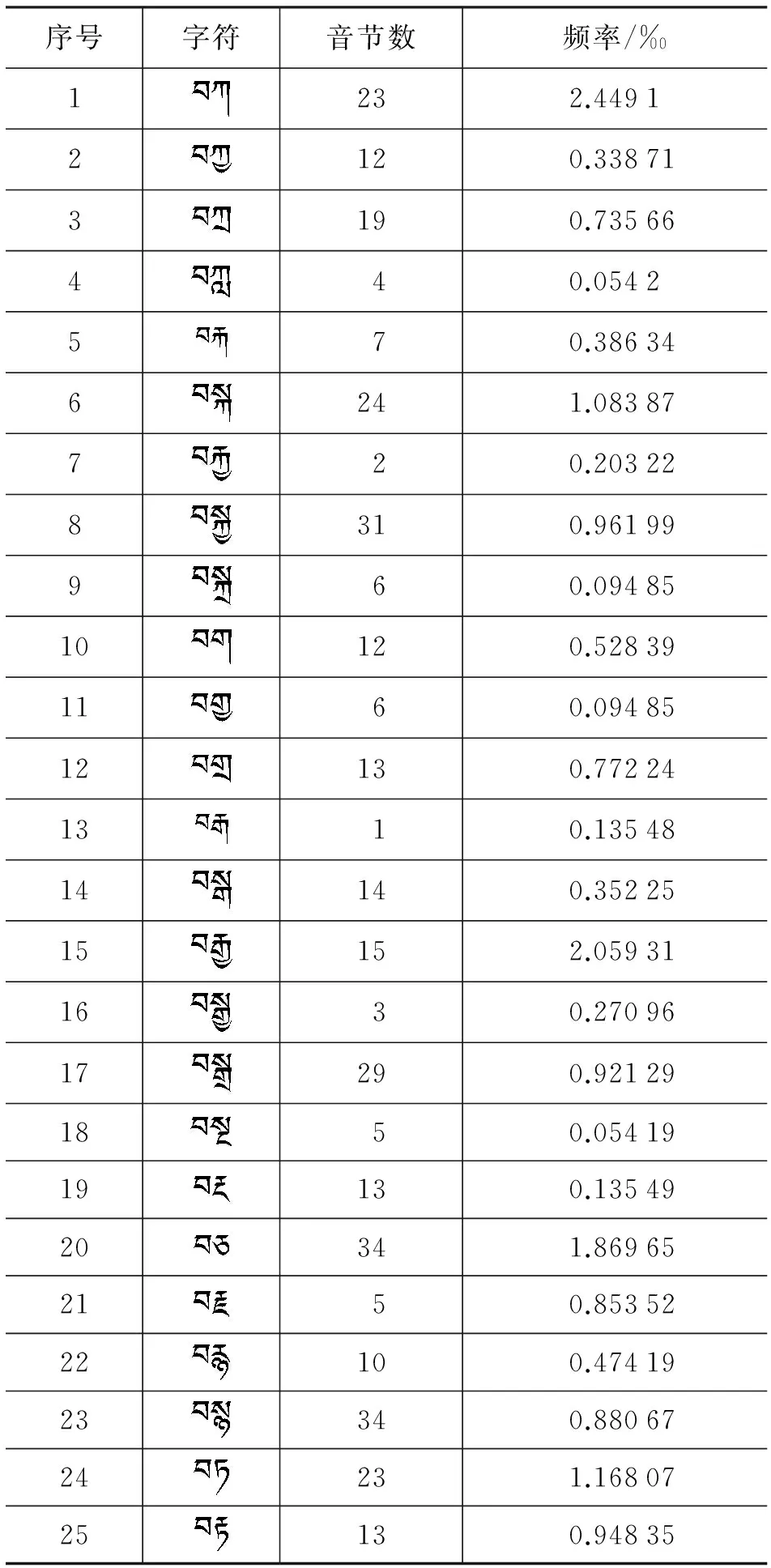
表13 前加字“”匹配规则表
序号字符音节数频率/‰1232.44912120.338713190.73566440.0542570.386346241.08387720.203228310.96199960.0948510120.528391160.0948512130.772241310.1354814140.3522515152.059311630.2709617290.921291850.0541919130.1354920341.869652150.8535222100.4741923340.8806724231.1680725130.94835
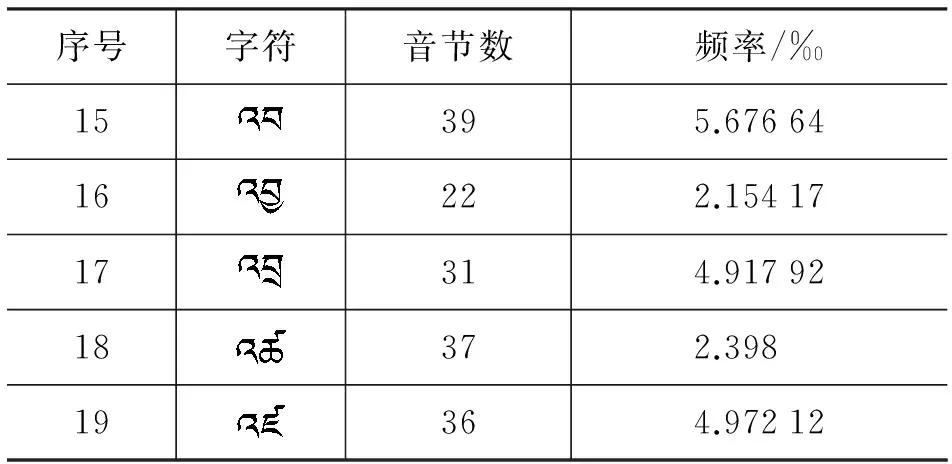
续表

表15 前加字“”匹配规则表
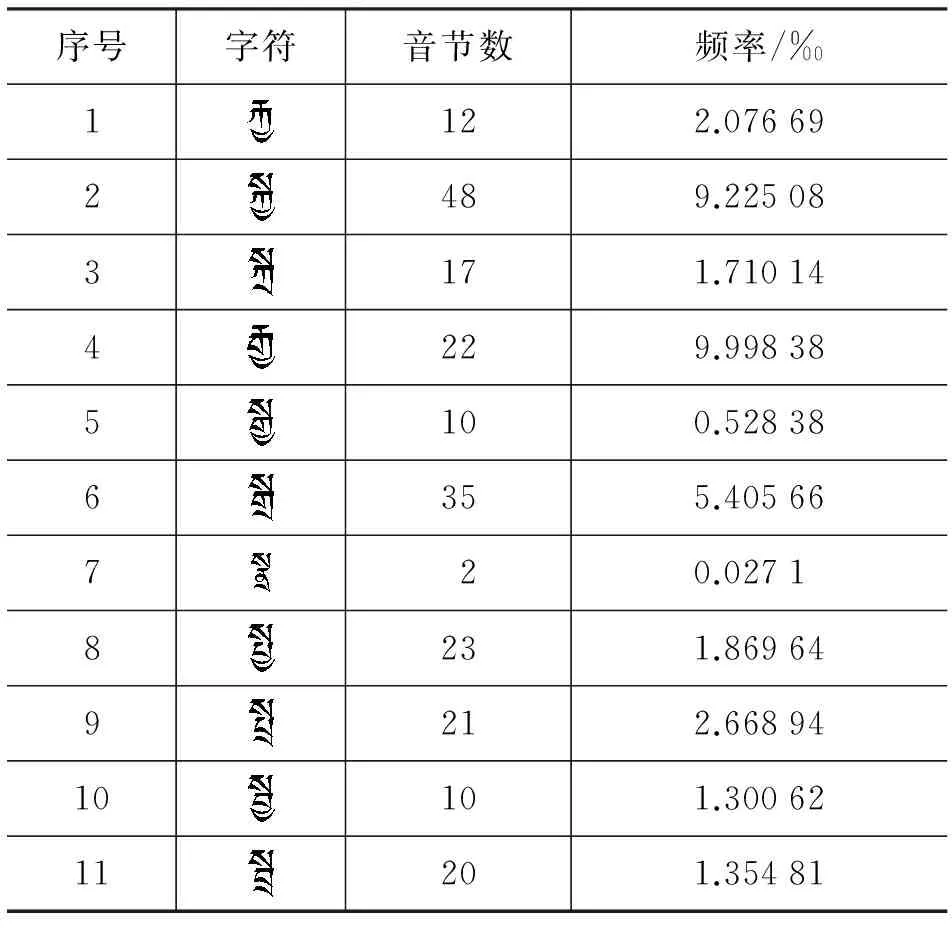
表16 上下叠加匹配规则表
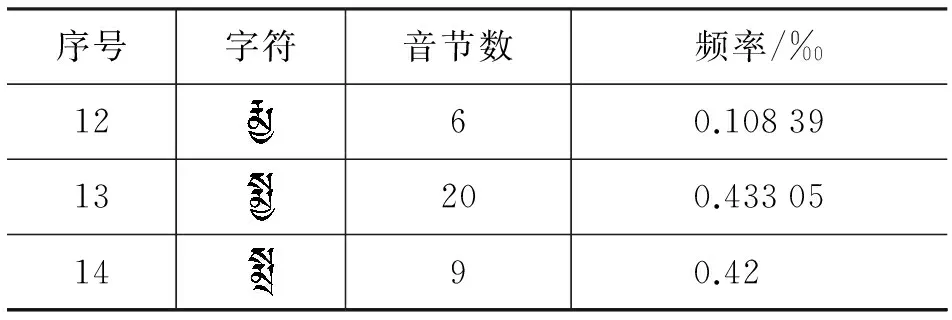
续表
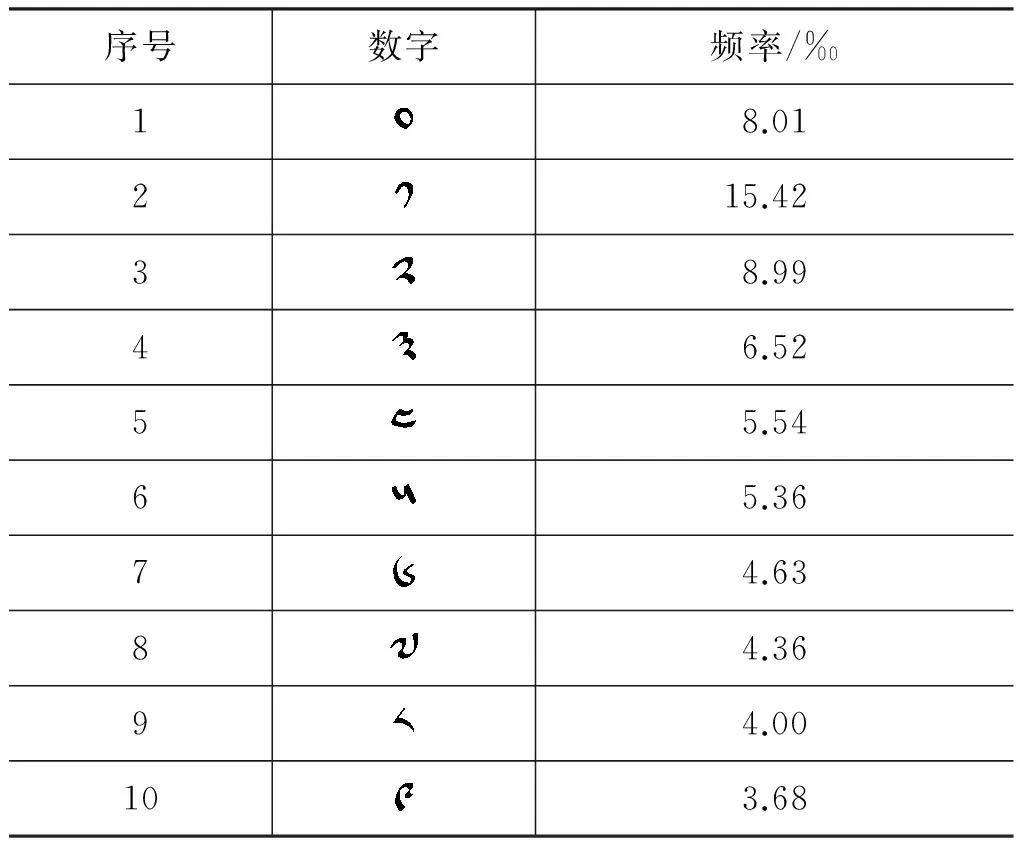
表17 藏文数字字符表
藏文规则库中的规则组合形成的音节数和频率统计过程如下:
设A为藏文音节集合,B为《藏汉大词典》中的音节集合,Cy为《现代藏文频率词典》中的音节集合,则:
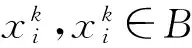
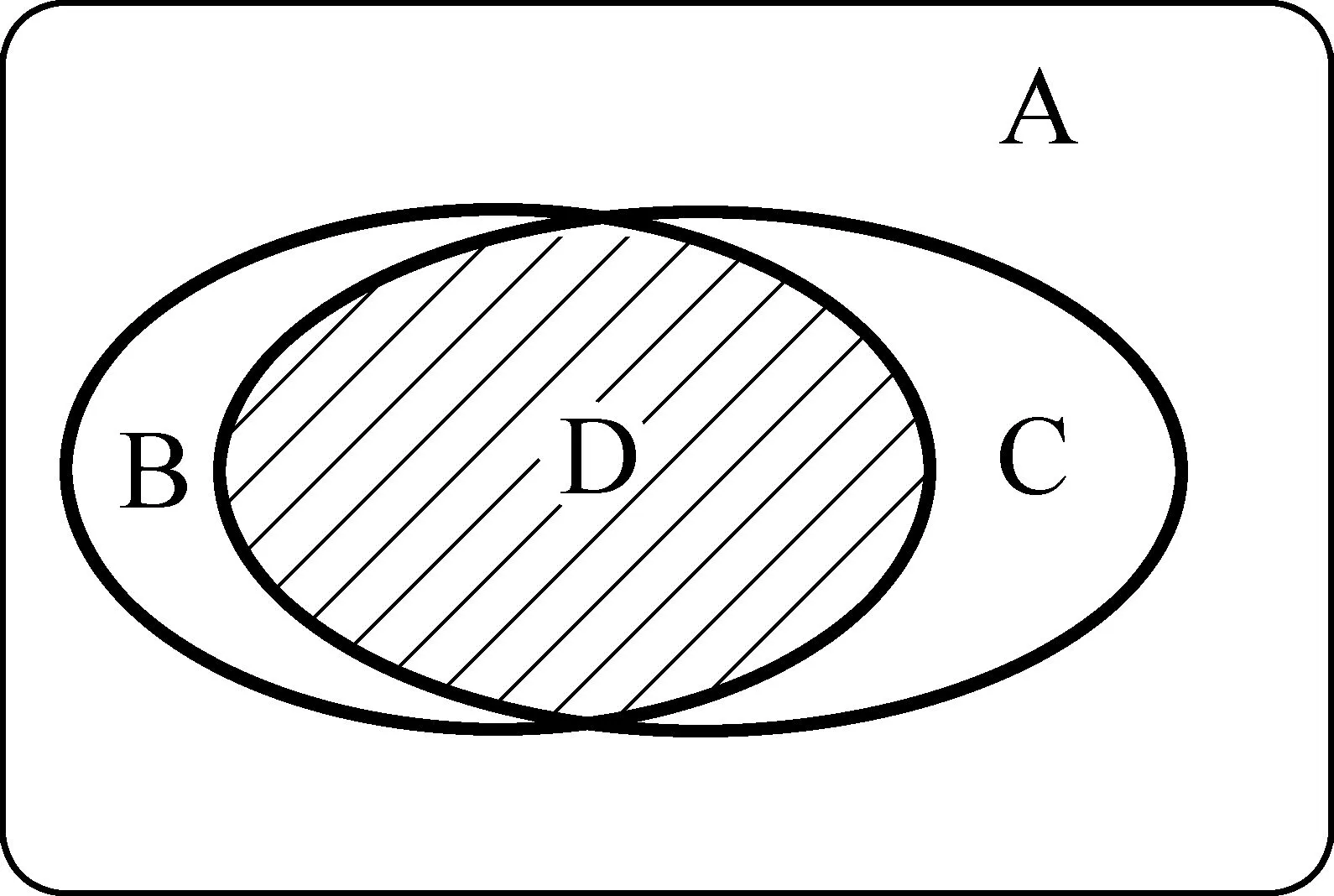
图3 藏文规则库的集合关系

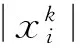
其中xk为第k个规则,k为规则数,公式(1)就是第k个规则的频率统计结果。
3.4 歧义规则处理
在具体应用中针对这14个规则需要另加判断条件,例如判断这14个规则后面是否跟有音节点,若有则为一个音节而非规则;否则为规则。
4 规则库的应用
4.1 自动拼写藏文音节

设基字扩展字符集合为Trule,其元素定义如下:





设归并后的后加字集合为Tpostfix:

设元音字符集合:

根据如下的藏文文法,后加字与任何“基字”可以进行匹配,这里的“基字”可以包含Trule集中的任何“规则”。文法如下所示:

其笛卡尔乘积为:
Trule×Tvowel×Tpostfix={
根据如上所述,自动拼写藏文音节系统如图4 所示。
通过自动拼写藏文音节系统,设计算法如下:
(1) 规则集Trule与Tvowel元音字符集进行组合,构成藏文音节。
(2) 规则集Trule与Tvowel元音字符集、Tpostfix集合进行组合,构成藏文音节。
经过实验测试,算法的第1部分产生1 045个音节,算法的第2部分能够产生17 765个音节,共计18 810个藏文音节。但是所产生的音节中存在一些歧义现象,例如:


(4) 自动产生的一些生僻音节,还需要语言学家的进一步论证。
4.2 拼写检查中的应用
目前藏文音节校对(拼写检查)中,有些学者通过n-gram方法进行研究,有些学者词典匹配模式进行校对,但未曾见到利用规则进行拼写检查的研究论文。
藏文拼写检查中把一个音节拆分成三个部分,即前缀、元音和后缀。在匹配模式中由于总计只有224个规则,比1万8千多个音节中查找和匹配简单的多。本文的拼写检查算法中,总体想法是一个音节的拼写检查归结到局部规则的检查,然后拓宽至整个音节的拼写检查,先进行前缀部分检查、再进行元音和音节点的检查、最后进行后缀部分的检查。具体算法如下:
(1) 当对文本进行拼写检查时,首先装载文本,读取一个音节内容,读取完毕结束循环。
(2) 识别一个音节,若是音节进入(3);否则做错误标记,进入(1)读取下一个音节内容。
(3) 目标音节与规则集Trule进行匹配,若匹配不成功,认为拼写有误,做错误标记并进入(1)读取一下个音节内容;否则进入(4)。
(4) 后面的字符与Tvowel集合和Tpostfix集合中的元素匹配,若匹配不成功,做错误标记并进入(1)读取下一个音节内容;否则拼写正确不做标记,进入(1)读取一个音节内容。
下面是算法的一个测试和实验结果的数据分析:
语料1的测试结果:

语料2的测试结果:


语料3的测试结果:

从以上3个语料的实验情况分析,首先,在音节识别当中需要去除藏文符号、数字、其他语言符号的干扰,经过预处理提取出藏文音节;其次,对藏文音节进行拼写检查,检查错误的拼写情况。针对判断失误的31个规则需要在拼写检查算法中另加判断条件,对于特殊藏文音节、梵音转写藏文音节需要在规则表中添加相应的字符规则;然后,如果剔除干扰因素、不考虑梵音转写藏文音节和特殊藏文音节,算法的检错能力可以达到99.8%(1-31/18810)。
4.3 藏文排序中的应用
在文献[11]中,江荻等人针对藏文的规则特性,提出了了藏文排序中的字符序、构造序概念,并设计了计算机中实现的排序方案。在文献[12]中,Ro-bert R Chilton利用藏文规则,对藏文编码国际标准ISO/IEC 10646字符进行了排序。作者通过“collation element”的概念,建立一个“collation element”表,该表通过对藏文规则建立权重分级的藏文字符排序表,第一级由133个规则字符、4个元音字符和30个后置字符组成一个167个字符的排序表;第二级由9个特殊字符组成的字符表,剩余120个字符不涉及到字典序排序方法中,没有列到权重分级列表中。作者较好地利用了藏文规则,设计了易于实现的排序算法。虽然需要排序的“字符”数量多了许多,但是算法简单并易于实现,该算法在Mysql和MIMER SQL中得到了应用。
4.4 信息提取和文本挖掘中的应用
在文献[13]中,利用藏文音节点的高频率特点,对藏文编码进行了识别,在文献[14]中利用了音节点的上述特点,提取藏文网页中的主体信息。将来在藏文文本挖掘、Web挖掘等研究领域中将起到积极的作用。
4.5 其他领域中的应用
在藏文的字库设计、字符标准制定、语音标注、词典编纂等领域中能够提供参考依据。
5 结论
本文试图从藏文音节的特征来解决藏文信息处理中的自动拼写藏文音节、拼写检查、藏文排序等问题,并在自动拼写藏文音节、拼写检查等研究内容中提出了相应的算法;在藏文排序、信息提取等研究内容中通过举例来说明藏文规则库在实际应用中的可行性。由于本文只考虑了符合藏文文法的现代藏文的规则,没有涉及梵音转写、符号、数字等内容,下一步考虑更多的因素,扩大藏文规则库的解决问题的范围。
[1] 江狄,董颖红.藏文信息处理属性统计研究[J].中文信息学报,1995,9(2): 37-44.
[2] 彭寿全,黄可,张义刚.藏文综合编码方案的研究与实现[J].中文信息学报,1996,10(4): 32-39.
[3] The Unicode Consortium.The Unicode Standard 4.0[S].2004.
[4] 国家技术监督局. GB/T 22034-2008信息技术 藏文编码字符集键盘字母数字区的布局[S].中国标准出版社,2008.
[5] Ngodrup, Dong Cai Zhao, De Qing Drorna. Research on Tibetan Lhasa Dialect Phonetic Feature Extraction Technology Based on LDA-MFCC[C]//IEEE ICIST, 2011, 5: 369-372.
[6] Yongzhong Li, Guang He. Research on Printed Tibetan Character Recognition Technology Based on Fractal Moments[C]//IEEE ICCSIT, 2010, 3: 57-60.
[7] Ngodrup, Dong Cai Zhao. Research on Wooden Blocked Tibetan Character Segmentation Based on Drop Penetration Algorithm[C]//IEEE CCPR, 2010: 1-5.
[8] 扎西加, 珠杰. 面向信息处理的藏文分词规范研究[J]. 中文信息学报, 2009, 23(4): 113-117.
[9] Yauan Lu, Yang Liu, Qun Liu. Multilingual Machine Translation system[C]//IEEE IUCS, 2010: 401.
[10] 江荻.中文信息处理国际会议论文集(书面藏语的熵值及相关问题)[M].北京: 清华大学出版社.1998,01.
[11] 江荻,周季文.论藏文的序性及排序方法[J].中文信息学报,2004,(2):27-31.
[12] Robert R Chilton,Sorting Unicode Tibetan using a Multi-Weight Collation Algorithm[EB/OL]. https://collab.itc.virginia.edu/access/wiki/site/26a34146-33a6-48ce-001e-f16ce7908a6a/sorting%20tibetan.html.
[13] 刘汇丹,芮建武,吴建.藏文网页的编码识别与转换[C]//中文信息处理前沿进展——中国中文信息学会二十五周年学术会议,2006: 573-580.北京: 西苑出版社.
[14] 珠杰,欧珠,格桑多吉.基于DOM修剪的藏文Web信息提取[J].计算机工程,2008,12(27):58-60.
