基于众包的词汇联想网络的获取和分析
2013-04-23车万翔张梅山
丁 宇,车万翔,刘 挺,张梅山
( 哈尔滨工业大学 计算机学院社会计算与信息检索研究中心,黑龙江 哈尔滨 150001)
1 引言
词典是中文自然语言处理的一项基础资源,它为很多中文自然语言处理的相关任务提供了支撑,例如中文分词[1]、命名实体识别[2]、 词义分析[3]等。
目前在中文自然语言处理领域影响较大的词典包括《知网》[4]、《同义词词林》[5]等。“《知网》是一个以汉语和英语的词语所代表的概念为描述对象,以揭示概念与概念之间以及概念所具有的属性之间的关系为基本内容的常识知识库”[4],其结构复杂不易扩展,需要很深的语言基础才能理解,因此编撰这一词典需要很大代价,作者董振东先生就用了逾十年时间才建立了这个约9万词的词典。《同义词词林》由梅家驹等人于1983年编纂而成,一共包含了近7万词汇,和《知网》相比易于理解,是一部汉语分类词典,其语义建立在近义和反义基础上,因此所表示的语义信息没有《知网》丰富。很显然,以上词典都是专家构造的手工词典。
众包是群体智慧的一种体现形式,它是一种新的资源建设的手段,并且这种资源建设的手段代价更低。例如,ESPGame[6]以游戏的形式让用户为图像打标签,是首个成功地用众包的思想免费收集到大量标注数据的案例;亚马逊土耳其机器人(Amazon Mechanical Turk)是亚马逊公司提供众包服务的网络平台,已有很多自然语言处理相关的工作通过这一平台来采集有用的语料,例如Irvine and Klementiev,2010;Jha et al., 2010;Lawson et al.,2010[7-9]。
本文将众包和词典构建相结合提出了一种代价更小的方式自动构建语义相关性词典。首先面向互联网设计一个网页游戏,提供利于用户进行自然联想的环境。词典的获取方式是给用户提供触发词,用户填写由该触发词联想到的词,从而得到词语之间由联想关系组成的网络,因此将语义相关性词典命名为词汇联想网络。因为用户的每一次相关联想产生的词语对,两个词语之间都存在语义相关性或相似性,因此,词汇联想网络中带有很强的词汇语义信息。获取词汇联想网络后,任意两个词语的相关度使用随机游走算法进行计算。随后,本文对词汇联想网络和知网、同义词词林以及微博ngram文本进行了对比,表明了词汇联想网络与其他词典是有着比较大的差异的,而且更符合人对词语的理解,从而体现了词汇联想网络的价值。
本文内容如下组织: 第2节介绍词汇联想网络;第3节介绍众包设计数据获取;第4节介绍使用随机游走的方法利用获取的数据构建词汇联想网络,以及对词汇联想网络的分析;第5节将词汇联想网络与知网、微博ngram文本、同义词词林进行比较和分析;最后给出总结和未来的工作。
2 词汇联想网络
2.1 定义
为了能够更好地表达词汇联想网络中词语之间的相关程度和拓扑关系,将词汇联想网络建立成图结构;图结构能够更加直观形象地刻画出词汇联想网络的形态。下面将词汇联想网络从图结构的角度重新定义。
词汇联想网络词汇联想网络是由一个带权重的图结构G=(V,E,W)组成,其中V代表图中的节点,由词语组成,E是边,边上的权重由W给出,边和权重反应了词语之间联想的紧密程度,权重越高,表明这两个词越容易组成联想对。
同一联想串中,后一个词是在前一个词的基础上联想出来的,因为很多情况下联想关系是不对称的,如由“踢”能想到“足球”,而很难从“足球”联想到“踢”。所以图G=(V,E,W)是有向图。
图1为词汇联想网络的一部分,图上边的权重最高的为“踢”→“足球”,这表明人们很容易从“踢”联想到“足球”。权重赋值将在词汇联想网络的构建中讨论。

图1 词汇联想网络局部截图
2.2 相关度计算
2.1.1 随机游走
随机游走算法[10]假设存在一个粒子沿着图上的边随意漫游,而粒子每次移动都移动到一个特定词语的邻居节点上,一段时间后粒子将周期性地、以相同的顺序遍历图上的节点,从而得到关于某个词语的概率平稳分布。随机游走算法的优势是将词语的直接关系和间接关系结合起来计算词语相关度;另外,通过遍历所有词语间的联系,游走的过程将局部相关性统计信息聚集起来并扩散到整个图中。

P是转移矩阵,词汇联想网络中任意两个词语i和j,若i和j出现在同一个联想串中且词语i紧随
词语j出现,则计算从j到i的概率p(ni|nj),否则p(ni|nj)=0。而粒子在每一步转移时都以概率β返回到θ(0),发现θ(0)收敛到分布θ(∞)的迭代次数与β-1成正比,通过实验一系列的β值,发现结果对参数β不敏感。设定收敛准则为‖θ(t)-θ(t-1)‖<10-8,对于本文得到的图,设置β=0.08,平均收敛次数是50。
下面用三个顶点构成的图进一步说明算法过程。

图2 三个点的有向图,随机游走从顶点A开始
2.1.2 相关度计算
通过以上方法已经得到了词语的概率平稳分布,下面讨论词语的相关度计算。直观来讲,如果随机游走过程分别从两个词语出发,都倾向于漫游到相同的节点上,那么这两个词语语义相关更强。因此,任意两个词语的相关度可以通过衡量关于这两个词语的概率平稳分布的差异得到。
假设待计算相关度的两个词语,它们对应的游走概率平稳分布分别是P和Q, 一个普遍的选择,
是将分布P和分布Q看作两个一维向量,从而用余弦相似度衡量P和Q的差异,如式(2)所示。
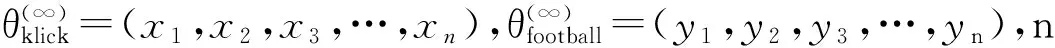
3 众包设计
本文将词汇联想任务设计成网页小游戏,游戏名称是“心有灵犀对对碰”。游戏以完成任务的形式进行,每个任务开始,系统都给出一个触发词,用户填写由该触发词最先联想到的词,然后,系统将触发词按照用户填写的词语切换,用户再进行下一步的联想,如此往复,最终得到一个长度大于某一阈值的词语串,任务完成。游戏记录完成该任务所用的时间,通过结合联想串的内容和联想用时进行相关计算,给出用户通过每次联想任务寻找到的心有灵犀伙伴。
从用户的角度讲,游戏的目标是寻找心有灵犀的伙伴,心有灵犀对象是与已知联想串“相悦”指数最大的 3个(3是最大值)联想串和联想用户。“相悦”指数是当某个词在联想串集合中两个以上的联想串中出现,那么这些联想串彼此之间“相悦”指数就加1,若有多个“相悦”指数相同的联想串存在,则用时短的联想串被优先选择。用户只有填入正规词才可能寻找到更多的心有灵犀伙伴。心有灵犀结果在同一时刻分别推送给“被心有灵犀”的3个用户,如图3弹出窗口所示, 使得心有灵犀成为一种实时的、相互的关系。从心理学角度讲,当人们找到心有灵犀对象即与他人产生共鸣时会倍感兴奋,因此,这大大增加了游戏的趣味性。
图3 “心有灵犀对对碰”游戏界面
为提高获取到的数据的质量,游戏对用户的输入进行了一定的约束。用户每次输入的内容只能是汉字,若出现英文字母、标点符号等,系统会给出错误提示,并给出正确输入引导,如图4所示。另外,在同一个任务中,用户输入的词语前后不能重复。

图4 错误输入提示

图5 心有灵犀显示
只有用户最自然最直观的联想,才能使得具有联想关系的两个词语间存在语义相关性的事实更可信,因此游戏中不能出现任何元素干扰用户联想,而从以下几方面努力吸引用户参与,第一,增强界面美观程度;第二,增强游戏易用性;第三,提高交互设计,增强用户体验。
在交互设计方面,游戏在用户做联想任务时,给用户的每次输入打出一个经验值,并用动画累加到经验值积分区,积分区在图3右上角,不同的经验值动画呈现的颜色不同,按照分数从低到高的顺序颜色逐渐由暗到亮变化。游戏还设置了积分和经验值排行榜激励用户完成更多的任务。
4 词汇联想网络构建
为了描述词汇联想网络的性质,也为了便于对其进行分析,本节详细说明词汇联想网络的构建过程。由于词汇联想网络也是一个语义相关性词典,所以本文除了构建词汇联想网络,还提供计算词语相关度的接口。
4.1 数据预处理
4.1.1 数据过滤
词汇联想网络来自互联网用户,因此难免出现类似语气词、短句和过于个性化,这几类词对于词汇联想网络都是噪声,构建词汇联想网络之前需要去噪。
S代表收集到的联想串集合,M代表S中的词语集合。互联网上收集的数据普遍具有冗余性,所以首先统计词频,将频数小于阈值γ(本文γ取1)的词语过滤出来形成集合{M′},然后人工检查{M′}中的每个词是否属于噪声词。为了降低人工检查的工作量,将{M′}与大规模词脉取交集,得到集合{M′},再人工检查{M″}。因为大规模词脉是最新建立的词典,融入了网络新词,收纳的词汇量更多,因此将{M′}与大规模词脉取交集,能极大地缩小{M″}的规模,从而减少了人的工作量。若找到噪声词,则将联想串从噪声处截断,因为噪声词后面的词语是经由该噪声词联想出来的,并不能与噪声词前面的词语构成合理的相关联想串。
4.1.2 图构建与权重赋值
将词汇联想网络表达成图结构,优势在于词语之间关联度的强弱可以由顶点之间关联度的强弱表示,即由连通顶点之间的边的权重表示。
G=(V,E,W)中的每一条边都被赋予权重,权重定义如下:
其中,若vi和vj在s中紧邻出现,则weight(s;vi,vj)的值为1.0,否则为0。如果两个顶点没有在任何一个词语串中紧邻出现,则它们之间的权重设为一个正极小值。
4.2 实验结果与分析
“心有灵犀对对碰”于2012年 5月17日上线,截止到今年8月1日,共有216名用户参与游戏,其中登录用户121个,匿名用户95个。
游戏初始从大规模词脉中选取2 500个通用词作为触发词,词语类型包括人和动作两个类别。游戏上线两个半月共收集长度大于4的联想串3 650个,词语26 892个,获得的数据中最长的联想串包含词语15个,平均每个联想串的词语数为5.65。按照前文方法进行数据过滤并建图,得到 9 150个顶点。运用3.2节的方法计算词语的相关度。
汉语词语相关度度量目前并没有一个统一的标准,在条件不具备的情况下,对随机游走计算相关度的评价方法是,先将词语对按照计算得到的相关度数值降序排列,再将排序后的词语列表和人的直觉比较。

表1 词语对按相关度结果降序排列
从表1可以发现,绝大多数相关度计算结果是符合人的直觉的。相关度比较高的词对,例如“结婚”和“小三”,“结婚”和“男人”,相关度高说明人们容易从“结婚”直接联想到“小三”和“男人”,而现今社会,人们对“小三”的关注程度确实比较高。从这个角度讲,本文的相关度结果也能反应出社会大众的普遍观点。而“结婚”和“帅气”,“结婚”和“贫穷”的相关度比较低,表明人们很少从“结婚”立刻想到“帅气”和“贫穷”,而实际上“帅气”和“贫穷”是两个修饰人的形容词,而“结婚”是抽象名词,因此较低的相关度结果也是合理的。
5 词汇联想网络与其他词典比较
5.1 词汇联想网络与《知网》比较
度量词语关系有相似度和相关度两个指标。与词语相似度比,相关度更侧重反应词语的语义关联程度,例如“医生”和“疾病”相似性非常低而相关性却很高。此外相关度和相似度又有着密切的联系,一般词语的相似度若比较高,那么相关度也会比较大,反之则不然。
为了进一步探究词语相关度和相似度概念间的联系与差别,本文将计算的相关度结果与词语相似度结果进行比较。因为目前基于词典的相似度计算多是针对《知网》进行的,故选择刘群,李素建(2002)[12]的结果进行对比。
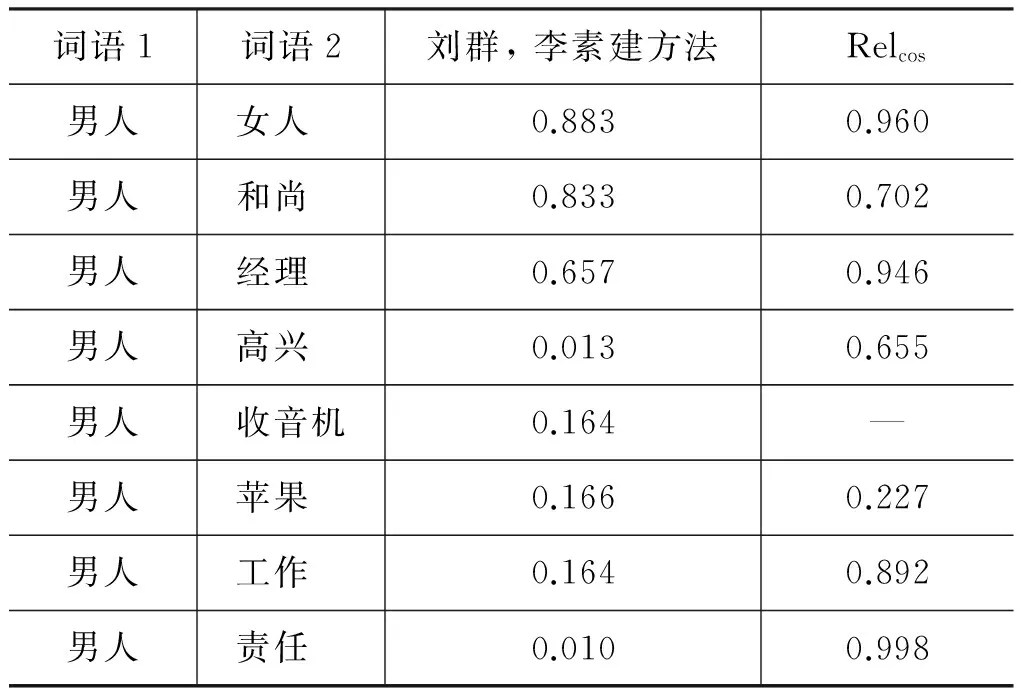
表2 相关度结果与基于《知网》的相似度结果比较
从表2可以看出,多数词语的相关度与基于《知网》的相似度结果相接近,例如“男人”和“女人”,“男人”和“苹果”等,但也存在差异如“男人”和“高兴”,即不同词性的词语相似度一般比较低而相关度比较高,因为“高兴”和“男人”之间存在修饰关系,并且“高兴”多是修饰人的情绪的,因此较高的相关度是符合实际的,从这一点可以发现,相关度能够更准确地描述出词语之间的关系,如修饰关系、补充关系等。
另外,表格中“男人”和“工作”,“男人”和“责任”的相似度很低,而相关度数值较高,这和“医生”、“疾病”类似,因为词语之间的某一些属性不同因此相似度很低,而词语的语义关联程度实际上很高。本文的数据来自人脑,因此可以获取到更多这种符合人们的认知的词语对。
5.2 词汇联想网络与微博文本ngram比较
直觉上可以发现,对于一些人们很容易产生联想的词语对,其在微博ngram中共现时的距离应该越近,因为微博也是人们思想的一种表达,也就是说词汇联想网络获中的词语对在微博ngram文本中的共现情况比较高。为了探究这一问题,我们筛选出词汇联想网络中共现次数最大的120个词语对,查找其在微博文本中的共现情况。
微博文本包含新浪微博987 743条,平均字数为25。分别查找每个词语对在每条微博中是否共现,若共现则记录两个词语的最近间隔字数,共现距离用所有间隔字数距离的平均值表示。

图6 词语对在微博文本中的共现距离
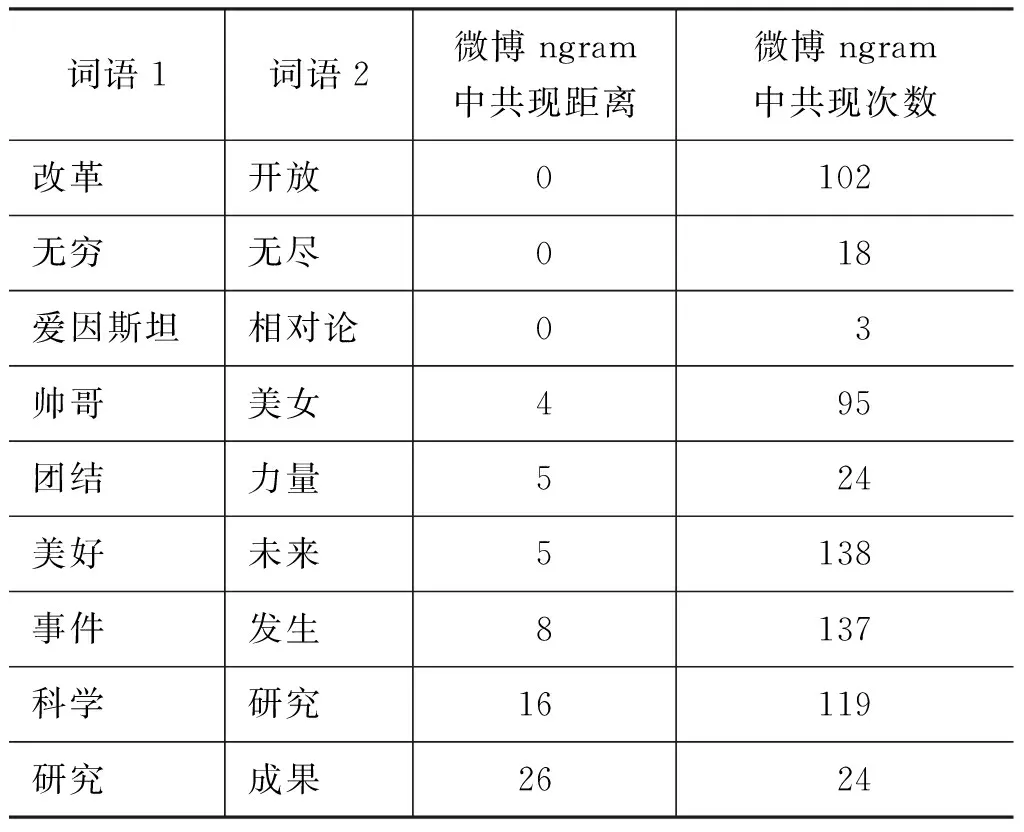
词语1词语2微博ngram中共现距离微博ngram中共现次数改革开放0102无穷无尽018爱因斯坦相对论03帅哥美女495团结力量524美好未来5138事件发生8137科学研究16119研究成果2624
200个词语对中105个在文本中共现,共现的105个词语对中共现距离大于6的占69.5%,共现距离大于 10 的占38.1%。
图6表示在微博ngram中共现距离在0~3个字之间的词语对数目是15,共现距离在4~7个字之间的词语对数目是25等等。
从图6可以看出大多数词对在微博ngram中的共现距离比较小,尤其像改革开放、无穷无尽这种,但凡出现必然两词共现。而另外存在小部分词对,虽然语义关联也很强,在微博中共现距离很远。这充分说明词汇联想网络中的词语对在微博ngram文本中的共现情况较高。从另一个角度讲,这部分共现距离远的词对能够说明,词汇联想网络的获取手段是不能被替代的,即词汇联想网络中的词语对不能完全从微博中抽取出来。
5.3 词汇联想网络与《同义词词林》比较
词汇联想网络包括同义词、同类词、语义相关联的词等,这点与《同义词词林》很相似。由于《同义词词林》将同类词组织到同一个小类中,所以考虑将词汇联想网络进行聚类,将聚类后得到的词语集合与词林中对应的小类比较,从而对比两者在词语的组成和组织结构上的差别。
考虑到聚类开始前并不知道可能的聚类中心点和类的个数,本文在词汇联想网络构建的图结构上选择Affinity Propagation(Frey and Dueck, 2007[13])聚类,AP算法继承随机游走的思想,因此聚成一类的词语将是语义相近或相关的。
随机选择聚类后的一个词语集合,找到词林中对应的小类,表4分别列出两个词语集合中关于“病人”的相关词语。

表4 词语相关度结果与基于《知网》的相似度结果比较
从表4可以看出,小类中的词群是由同义词和反义词以及同类词组成的,每个词群又是由同义词组成。另外,同义词词林是从语言学的角度整理词语的,词语中包含有常用词和规范书面词。词汇联想网络中的类是由一系列跟中心词有关的事物组成,不仅仅局限于同词性的词,另外,词语多是常用词,也包括网络新词,如脑残、高护。因此,两个词汇集合不仅结构不同,组成词汇集合的词语本身也存在差异。词汇联想网络的特点不仅能获取流行的网络新词,而且在不同时期,词汇联想网络的词语将会不断更新,某些词语之间的联想关系也会发生变化,体现出很强的扩展性。
从表4还能发现,虽然目前获取的数据量不是很大,但是对一个中心词的关联事物展现的还是比较全面的,与“病人”相关的“家属”、“医院”、“医生”、“疾病”、“病情”等几大类事物均有出现,构成了一个关于“病人”更大更全面的网络,这些词与同义词词林中的对应小类中的词语有交叉,若将同义词词林中的词语融合到词汇联想网络中,加入更多同义词,那么会使关于“病人”的周边词汇更加全面。另外,因为同义词词林中的词有部分并不是常用词,所以即使有更多的用户参与联想,也很难收集到这部分词语。
6 结论
本文将众包与词典构建相结合,提出了一种代价更小的方式自动构建语义相关性词典,这个语义相关性词典也是一个词汇联想网络。对收集到的数据进行一定步骤的处理以后建立图结构,使用随机游走算法计算词语相关度。实验表明,词汇联想网络是解读人脑而来,本文计算的相关度结果非常符合人的直觉。另外,通过实验将词汇联想网络分别与《知网》、微博文本ngram和《同义词词林》比较,结果更是表明词汇联想网络不同于已有的其他词典,能表达出词语之间更密切的语义联系,并且词汇联想网络中的词汇是动态更新的,扩展性强。
综合全文,词汇联想网络的众包获取手段为构建大规模语义词典资源提供了一个非常廉价且有效的方式。
下一步的工作,首先,希望将词汇联想网络与其他现有词典相融合,如《同义词词林》、《知网》,词汇联想网络中更加充分的词语关系将提升现有词典的性能。另外,探究融合后的词典在语义分析实际应用中的效能。
[1] 张梅山, 邓知龙, 车万翔,等. 统计与词典相结合的领域自适应中文分词[C]//第十一届全国计算语言学学术会议(CCL2011), 中国洛阳,2011:28-33.
[2] Amit Chandel, P C Nagesh, S Sarawagi. Efficient batch top-k search for dictionary-basedentity recognition[C]//Proceedings of the 22nd International Conference on Data Engineering, 2006:28.
[3] Simonetta Montemagni, Lucy Vanderwende. Structural patterns vs. string patterns for extracting semantic information from dictionaries[C]//Proceedings of the 14th conference on Computational linguistics, August,1992: 23-28.
[4] 董振东,董强. 知网. http://www.keenage.com[M]. 2000.
[5] 梅家驹,竺一鸣, 高蕴琦,等. 同义词词林(第二版)[M]. 上海辞书出版社.1996.
[6] Luis von Ahn, Labeling Images with a Computer Game[C]//ACM Conf. on Human Factors in Computing Systems, CHI 2004: 319-326.
[7] Ann Irvine, Alexandre Klementiev. Using Mechanical Turk to Annotate Lexicons for Less Commonly Used Languages[C]//Proceedings of the NAACL HLT 2010 Workshop on Creating Speech and Language Data with Amazon’s Mechanical Turk, pages 108-113, Los Angeles, California, June 2010.
[8] Mukund Jha, Jacob Andreas, Kapil Thadani, et al. Corpus creation for new genres: a crowdsourced approach to PP attachment[C]//Proceedings of the NAACL HLT 2010 Workshop on Creating Speech and Language Data with Amazon’s Mechanical Turk, Los Angeles, California. Bremaud. Markov chains: Gibbs fields, montecarlo simulation, and queues.Springer-Verlag. 1999: 13-20.
[9] Nolan Lawson, Kevin Eustice, Mike Perkowitz, et al. Annotating large email datasets for named entity recognition with mechanical turk[C]//Proceedings of the NAACL HLT 2010 Workshop on Creating Speech and Language Data with Amazon’s Mechanical Turk, Los Angeles, California, 2010:13-20.
[10] Thad Hughes, Daniel Ramage. Lexical Semantic Relatedness with Random Graph Walk[C]//Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, Prague, June 2007: 581-589.
[11] Bremaud. Markov chains: Gibbs fields, mon-tecarlo simulation, and queues[M]. Springer-Verlag,1999.
[12] 刘群,李素建. 基于“知网”的词汇语义相似度计算[C]//计算语言学与中文语言处理——第三届汉语词汇语义学研讨会论文集. 2002:59-76.
[13] Brendan J Frey, Delbert Dueck. 2007. Clustering by passing messages between data points[J].SCIENCE, 2007, 315: 972-976.
