普通话发音评估性能改进
2013-04-23肖云鹏叶卫平
齐 欣, 肖云鹏, 2, 叶卫平
(1. 北京师范大学 信息科学与技术学院,北京 100875;2. 武汉烽火通信科技股份有限公司,湖北,武汉 430074)
1 引言
基于语音识别的自动发音评估技术的主要应用领域涉及口语水平测试和计算机辅助语音教学的评价与反馈等方面。这项技术可以部分地替代教师及测评专家的工作,提高语音学习及测试的实施效率,因此它在语言教育领域的应用也变得越来越广泛。近年来,发音评估应用于智能化普通话测试,促进了普通话推广进程及普及水平,对加强我国各地区各民族人民之间的相互了解与沟通,促进和谐社会建设具有重要意义,在我国扩大国际交往和对外文化交流中也起到了积极作用。
上世纪末,在语音识别技术发展的带动下,越来越多的国内外研究机构和学者开始关注自动发音评估,并提出了诸如音素置信度算法GOP(Goodness of Pronunciation)[1]等多种评估算法,在语言教学应用方面也取得相应研究成果[2-4]。国内围绕智能普通话水平测试的发音评估研究成果显著,目前已在普通话水平测试中推广使用[5-7]。
智能普通话发音评估相比人工评估具有一致性、稳定性等方面的优越性,但在效果上仍存在不尽如人意之处。普通话测试和普通话语言学习环境的噪声干扰对发音评估性能也有较大影响。因此有必要研究普通话发音评估性能改进。
本文采用普通话测试现场录音做为实验语料,从三方面对普通话发音评估性能的改进问题进行研究。首先,本文探讨了评估系统特征参数的选取问题。2009年,Chanwoo Kim提出一种名为功率归正化倒谱系数(Power-Normalized Cepstral Coefficients,PNCC)[8]的语音特征参数,这一参数有效地提高了语音识别的抗噪声性能。本文将PNCC引入普通话发音评估,提高了噪声环境的评估性能。其次,本文针对声学模型单元的拆分问题进行了深入研究。我们知道,基于隐马尔科夫模型(Hidden Markov Model HMM)的汉语普通话语音识别,可以采用小到音素大到音节尺度的声学模型,不同的声学模型单元拆分对发音评估的性能会有不同程度的影响,本文选取了与传统扩展声韵母模型不同的拆分方式进行建模,提高了发音评估的性能。此外,本文还对训练中各模型单元状态数的配置选择进行了研究,在参考传统扩展声韵母模型关于状态数配置研究相关结论的前提下,本文考察了不同拆分下状态数配置对发音评估性能的影响,在此基础上,本文选择不同状态数描述不同声母介音及韵母,取得了较好的评估效果。
本文第2节简单介绍了所使用的数据库,打分算法等实验配置。第3节介绍了使用PNCC特征参数噪声环境下的发音评估。第4节讨论汉语声学模型单元拆分与评估性能的关系及拆分方法。第5节论述模型状态数选取对评估性能的影响,并提出混合状态数的配置方法。第6节总结全文。
2 数据准备和实验设置
2.1 语料库
本文语音数据源于北京师范大学普通话测试研究中心2005和2006年两次普通话水平考试的录音。考虑到语料为实测录音且环境存在背景噪声,
间或咳嗽、门窗桌椅响动、测评专家语音以及窗外楼道传入的其他干扰等,本文去除了个别重叠有大噪音的音节。
训练语料使用发音质量较好(专家评分为一乙)的149人的测试录音,其中男性为76人,女性73人,语料总计单字14 816个,多字词为7 192个。测试采用不同发音质量等级的50人第一部分单音节发音的语料,评分等级分布于普通话水平“一甲”、“一乙”、“二甲”、“二乙”和“三甲及以下”5个分数段中,每段取男女各5个发音人,语料总计单字4 900个。
2.2 打分算法
本文采用基于混淆网络的后验概率算法[9]进行自动发音评分。通过对Lattice采取紧凑计算后得到混淆网络[10-12],其基本结构如图1所示。

图1 混淆网络基本结构
由此可以计算得到词的混淆网络后验概率:
其中,P(wij)表示第i个弧集合中第j个竞争词的输出概率分布[13]。可以看到此算法是对数后验概率的一种改进算法,通过分子分母相除,减弱了说话人对发音者音质的影响,并且该算法在时间分段上模糊处理的办法也比对数后验概率更具有鲁棒性。
2.3 性能评估手段
2.3.1 打分相关性
本文用自动评估得到的机器评分与专家评分进行相关性计算,评价自动发音评估效果。
由于普通话水平测试现场即时打分受客观环境和主观判断影响,测评专家评分偶有漏判。为了降低错判漏判的影响,本文选取普通话水平测试现场两名专家的打分与实验室从事普通话研究且普通话水平较好的3人事后评分求取平均作为专家打分标准。现场2名专家与事后3专家评分的相关性数据,见表1、表2和表3。

表1 测评现场专家评分相关性

表2 事后3评分相互间相关性

表3 事后3评分与现场专家平均打分的相关性
需要说明的一点是,现场两位专家在第四题评分时往往相互之间有所影响,因而说话人层面相关性较高。而事后3个评分相对独立,所以说话人层面相关性相对较低。
除了客观环境,主观因素对专家打分也存在很大影响,包括专家当场状态和所属地域不同等等,不同专家听辨不同发音的敏感度也有所不同[14],因此可能存在这种情况,即专家间相关性较低,比如评分1和3与评分2相差较大,但是整体评分却更具有全面性更准确。经验证选取此5人的综合评分作为最终的专家打分,将使得专家打分更具有全面性。
2.3.2 识别器性能评价
除打分相关性外,识别器的好坏也是评价系统性能的重要指标。因为语料中有错音和缺陷音,本文采用错音检测常用的错误拒绝率和总错误率作为指标来评价识别器。错误拒绝(False Rejection,FR)指语料中所有“正确读音”(读音与目标文本一致)被识别器识成读音错误的错误。总错误率则包括错误拒绝和错误接受(False Aceptance,FA)两类错误,其中,错误接受是语料中“错误或缺陷读音”(读音与目标文本相左)被识别器识成读音正确的错误。
3 PNCC发音评估
梅尔倒谱系数(Mel Frequency Cepstral Coefficients, MFCC)作为符合人耳听觉特性的特征参数,在当前语音识别和发音评估领域的应用最为广泛。但其缺点之一是在噪声条件下性能下降较快。Chanwoo Kim 在2009年提出了功率归正化倒谱系数(Power-Normalized Cepstral Coefficients,PNCC)[8],由于其更精确地模仿了人耳听觉系统,因而具有更好的抗噪声性能。
基于语音识别的发音评估严重依赖于语音识别的性能,噪声环境对其性能影响极大。本文将PNCC参数引入噪声环境下的发音评估系统,期望评估性能有所改善。
PNCC参数提取流程如图2所示,共分七个步骤:预加重(Pre-emphasis);短时傅里叶变换(Short-Time Fourier Transformation,STFT); Gammatonne频带分析滤波;基于中长时功率谱规正化的背景噪声移除;语音强度的幂函数映射;离散傅里叶变换(Discrete Cosine Transformation,DCT)计算倒谱;倒谱均值归一化(每一维倒谱分量减去该维倒谱的均值)。

图2 PNCC参数提取流程
与MFCC相比,PNCC参数有三点主要改进:Gammatone滤波器、强度幂函数映射以及基于中长时段功率谱规正化的噪声去除。分别说明如下。
3.1 Gammatone滤波器
人的听觉依赖于耳蜗对于声音信号的分析。声音激发出耳蜗内流体的压强波,压强波沿基底膜传播,不同频率的声音产生的驻波峰值出现在基底膜的不同位置上。低频峰值出现在基底膜的顶部附近,高频峰值出现在基底膜的基部附近。如果信号为多频率信号,则会在基底膜在不同位置上产生多个峰值。从这个意义上讲,耳蜗将复杂的信号分解成各种频率分量,是一个频谱分析仪。
研究中常采用一组并行的带通滤波器来模拟耳蜗基底膜的分频特性。每个滤波器的中心频率不同,带宽也不同。听觉研究领域有很多频带仿真模型,其中比较具有代表性且比较成功的是Gammatone模型,广泛应用于人工耳蜗。
Gammatone滤波器[8,15]是一个标准的耳蜗听觉滤波器,该滤波器组的冲激响应为[15]:
其中,a为滤波器增益。n为滤波器阶数,n=4时,Gammatone滤波器较好地模拟了基底膜的滤波特性。f为滤波器中心频率。φ为相位,相位对功率谱的影响可以忽略。b为滤波器带宽,采用人耳听觉临界频带(Critical Band,CB)[16]:
图3绘出了Gammatone滤波器组的频率响应。

图3 Gammatone滤波器频率响应[17]
PNCC用Gammatone滤波器替代MFCC的Mel三角滤波器,更精确地模拟人耳听觉,因此在语音识别中获得了更好的抗噪声性能[8]。
3.2 强度的幂函数映射[8]
众所周知,人耳对音强的感知是非线性的,MFCC 和PLP分别采用对数曲线和幂函数来模拟非线性这一特性。对数曲线的优势在于其在高音强段能很好地模拟人耳特性,但在低音强段(≪1),其在音强的细微差别上会带来很大的对数值差异,这与人耳听觉特性并不相符。另一方面,由于混入语音的噪声数值往往较小,而对数特性扩大了小信号的影响力,因而不利于减小噪声的影响。与其相比,幂函数映射则可以更好地模拟各个音强段的特性,有利于改善语音识别的噪声性能。因此,PNCC采用y=xa0的幂函数映射,本文取a0=1/15。
3.3 基于中长时段功率谱规正化的噪声去除[8]
中长时功率谱归正化噪声去除是PNCC获得抗噪声性能最重要的环节。去噪方法类似于Wiener滤波。核心目标是利用带噪语音谱和纯净语音谱构造滤波器,对语音谱实施规正化去噪。获得纯净语音谱的方法类似谱减法,在假定加性噪声与短时平稳语音信号相互独立的条件下,从带噪语音功率谱中减去噪声功率谱,从而得到较为纯净的语音频谱。PNCC主要的改进在于噪声功率的估计。算法不是从非语音段中估计噪声功率,而是采用功率谱时间算术平均值与几何平均值的比值(Ratio of arithmetic mean to geometric mean,AM-to-GM)衡量语音被污染的程度,进而估计背景噪声的幅度。
语音处理多采用长度为10ms到30ms的短时分析帧,更长的分析帧会破坏语音信号的短时平稳性。噪声分析则不然,由于噪声谱随时间变化比语音信号缓慢,噪声特性的分析和估计要求更长的分析帧——中长时分析帧。一般在进行语音去噪时,分析帧长的选取是个比较两难的问题,难以同时满足语音和噪声的不同要求。PNCC用中长时功率谱估计噪声,得到规正化噪声去除滤波器,再对短时语音谱滤波。兼顾了语音处理和噪声分析的不同需求。
3.3.1 中长时功率谱噪声估计
一般情况下,语音谱随时间变化大于噪声谱,语音应该比噪声具有更大的AM-to-GM比值。相应地,被噪声污染的语音应该比干净的语音具有更小的AM-to-GM比值。Chanwoo Kim用AM-to-GM估计语音信号受噪声干扰的程度。比值越高,相应频带受噪声干扰的程度越低。这是PNCC噪声估计的基本思想。
设P(i,j)为分析第j帧语音时,第i个Gammatone频带滤波器输出的短时功率谱值。用于噪声估计的中长时功率谱为短时谱的中长时间均值:
Kim的实验表明M=3时,误识率最低。若语音帧长为25.6ms,帧移为10ms,则中长时噪声分析窗为85.6ms。
设第i个频带背景噪声功率值为B(i),减去噪声后的中长语音功率谱为

(5)
式中第二项的作用是为了防止减噪语音功率谱为负值,Kim取d0=10-3。
定义第i个频带语音谱的算术平均值与几何平均值的比值的对数AM-to-GM为:
(6)
取对数得以变乘法为加法,减小了运算负担。相应的减噪语音谱的对数AM-to-GM比值定义略有不同,见式(7)。
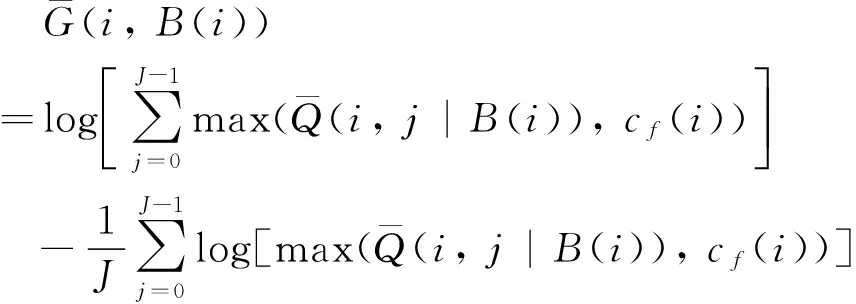
(7)
其中,
加入cf(i)可以使背景噪声功率的估计更为可靠。
3.3.2 语音功率谱规正化去噪
求得每个频带减噪后的语音谱估值之后,可以用它作为干净语音值,定义语音谱规正化去噪滤波器,见式(9)。
由此可得规正化去噪语音的短时功率谱为
式中规正滤波器取2N+1个频带均值平滑,本文取N=5。
3.4 PNCC发音评估
普通话测试语料为现场实时录音,噪声的影响较大。为了降低噪声影响,本文将PNCC引入发音评估。表4列出分别选取PNCC与MFCC作为特征参数的不同声学模型拆分方式下3状态HMM评估和识别性能的比较,其中XIF为扩展声韵母模型,IMF为声母介音+韵母模型,这两种模型将在后续进行详细介绍。
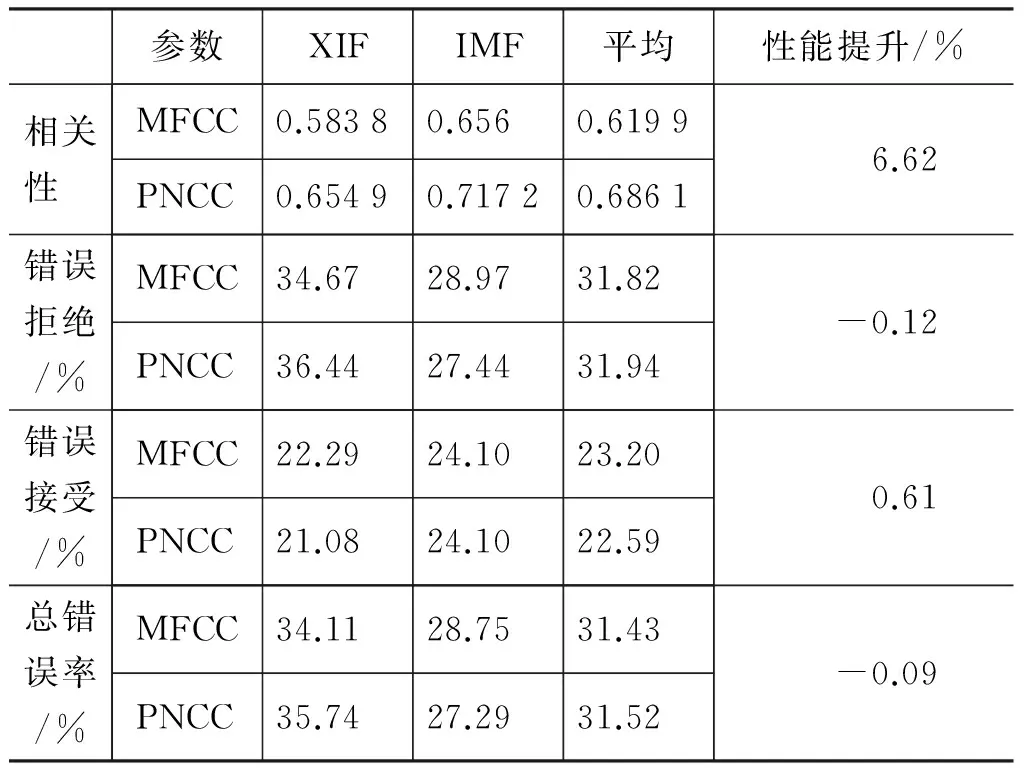
表4 PNCC发音评估与MFCC对照
可以看出,在本文选取的数据库上,PNCC语音识别性能与MFCC基本相同,而发音评估性能优于MFCC达6.6个百分点。PNCC在发音评估方面具有更为突出的优势。
实验使用HTK训练模型,其中,声学参数采用39维的PNCC,HMM模型状态数取3。概率分布采用混合高斯模型,其中,静音采用32个高斯混合,静音之外其他所有音素则采用16个高斯混合。{Gc l(i)}采用Kim的实验数据。如果能采用未受噪音污染的汉语语料重新计算,识别和评估性能还有进一步提高的空间。
4 发音评估与声学模型单元拆分的关系
汉语语音识别可以采用小到音素大到音节等不同尺度的声学模型。目前应用较为普遍的有郑方等人以声母+韵母为基础的扩展声韵母方案[18]。语音识别多在扩展声韵母基础上建立triphone模型。triphone模型考虑到声母与不同韵母拼接时的区别,以及韵母与不同声母拼接时的区别,因此对汉语语音的描述更为确切。代价是模型数量大,要求更多训练数据量。郑方等人研究汉语普通话triphone模型合并,给出了不同合并情况对识别性能的影响[19]。其中87i+45f方案模型数目最少,尽管识别率略有降低,但仍不失为一种选择。
基于识别的发音评估系统的性能依赖于语音识别器,识别性能的优劣直接影响评估性能的好坏,识别性能也是目前制约发音评估性能进一步提高的主要原因。另外,发音评估毕竟不是语音识别,语音识别解决发音“是什么”的问题,而发音评估则更多关注各个音素发音是否“到位”,以及“到位”在程度上的差别。尤其在普通话测试第一部分单音节词发音评估中,评估目的主要是音素的发音准确度。因而发音评估对识别器的要求和语音识别未必完全相同。
无论声母还是韵母,与不同音相拼时自身会发生相应的改变,音的边界由于受过渡段的影响而不同。因此以声母和韵母为声学模型的扩展声韵母方案中,声母或韵母的声学模型具有许多不同的变体,郑方等人正是以此作为出发点,从合并triphone的角度展开思路的。
为了避免不同单元相拼时带来的模型差异,本文发音评估采用声母介音+韵母方案拆分音节,从划分的角度考虑问题。将拆分点选在与声母紧邻元音的稳定段。例如:音节ba被表示为ba和a相拼,dian则表示为di和ian相拼。与郑方等人进行triphone合并实验中得到的三因子模型集合87i+45f相吻合。
为了探讨噪声环境PNCC发音评估对声学模型拆分的要求,本文比较了扩展声韵母(XIF)方案和声母介音[20]+韵母(IMF)monophone语音识别的发音评估方案的性能。
声母介音+韵母方案初始音素(initial)和结尾音素(final)列于表5。

表5 声母介音+韵母方案的初始音素与结束音素
其中,iz、izh分别代表zi、zhi的韵母。儿化音则根据发音规则进行了部分合并。其中ar是儿音“二”以及a、ai、an的儿化音;er是“儿”以及ei、en的儿化音;err是e的儿化音;ir是i和in的儿化音。
实验使用HTK训练模型,声学参数采用39维的PNCC。HMM模型状态数分别取2~6,概率分布采用混合高斯模型,静音采用32个高斯混合,静音之外其他所有音素采用16个高斯混合。发音评估与专家打分的相关性corr,错误拒绝FR和总错误率ER示于表6。

表6 扩展声韵母方案和声母介音+韵母方案比较
可以看到,声母介音+韵母方案无论是在识别性能或是打分性能方面均优于扩展声韵母方案。其中,错误拒绝率降低6%,总错误率降低5.6%。而发音评估相关性则提高了0.056。因此,本文选定声母介音+韵母方案作为最终拆分方案,并在此基础上进行后续模型状态数选取的研究。
5 发音评估与模型状态数的关系
5.1 模型状态数混合配置
以音素为单位建立声学模型的语音识别系统多采用3状态HMM。汉语情况较为复杂。在最常用的扩展声韵母方案当中,声母结构复杂度与韵母不同,各个不同声母或韵母相互间复杂度也各不相同。较为常见的状态数配置有单一固定状态(常取3~6个),声母3状态+韵母5状态等[18,21]。另外还有研究表明,根据不同声韵母复杂度配置不同状态数目,能够得到更好的识别性能[22]。
声母介音+韵母方案中,声母介音与韵母结构复杂度不同,各个声母介音或韵母之间复杂度也各不相同,可以推断采用不同状态数配置有可能得到较好的识别效果,进而得到更好的发音评估性能。根据语音特点本文以“为结构复杂的单元多分配状态,结构简单的单元少分配状态”的原则进行实验,结果表明,声母介音选取3状态,韵母选取5状态下评估的识别性能和打分性能均优于声母介音和韵母采用相同状态数下评估的结果;根据不同音素结构优化的混合状态数配置实验结果也好于多数相同状态数配置下的评估结果,见表7。
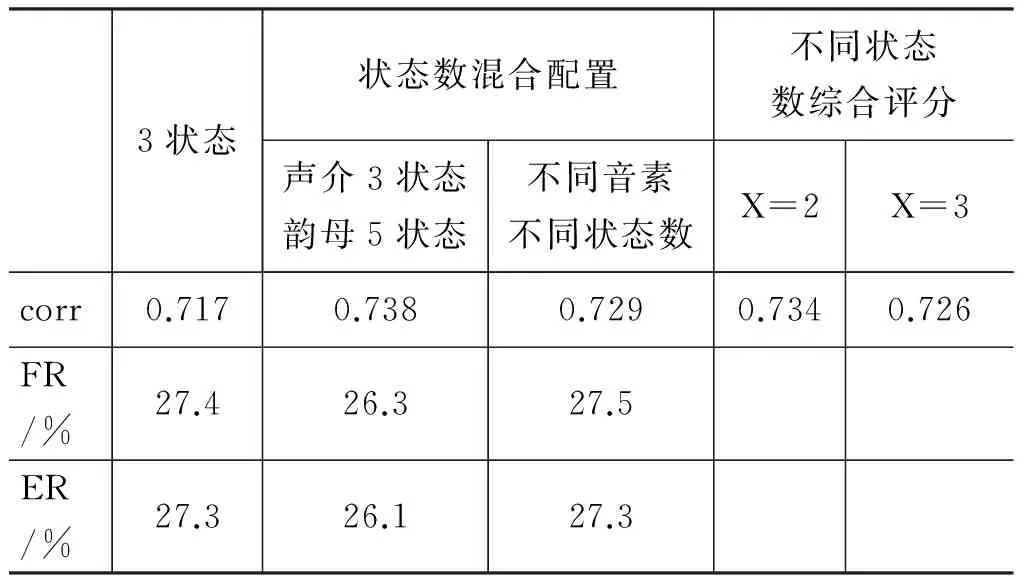
表7 混合状态配置和综合分数实验
5.2 不同配置综合评分
另外,由于各个模型单元的状态数配置相互影响,通过配置使每个单元都达到最佳识别性能是不可能的。某种配置下,一些模型识别率高,另一些模型识别率低。若将不同配置的识别结果综合起来,有可能达到更高的识别性能和评估性能。
为此本文进行了初步的发音评估实验,选取声母介音+韵母模型,使用音节(单字)作为模型单元进行测试评分。首先归纳出各个音节在2~6之中哪种状态数配置下识别率较高。在此基础上评估分两步进行。第一步,应用之前训练好的状态数为 2~6的5个声学模型库,依次识别待测语料,得到不同模型匹配的5套似然率;第二步,针对目标文本的语音标注(发音评估和语音学习都有目标文本),根据之前关于似然率高低的归纳结果,选用该音节识别效果较好的状态数配置下得到的似然率计算评估分数。结果好于固定状态数配置。见表7。
其中, X为限值,表示以3状态为基准,若某一状态配置的识别错误比基准配置少至少X个,则选取此状态评估的似然度计算评估分数,否则选取3状态配置下的评估分数。
可以看到,相比固定3状态模型,模型状态数混合配置在相关性上最高可提高0.021,而使用不同状态数综合评分方法最高也可提高近1.7个百分点。
6 结论
针对普通话发音评估性能的优化问题,本文从三方面对系统进行了改进。首先,针对受噪声环境影响较大的实录语料库,本文将抗噪性能较好的PNCC参数引入普通话发音评估。相比传统MFCC参数,其评估相关性提高了6.6%,表现出良好的性能;其次,本文就汉语普通话音节拆分方案的选取进行了深入研究,引入声母介音+韵母方案。在这种模型拆分下建立的评估系统在识别器和评分性能上较原有的扩展声韵母(XIF)模型都有长足改进。最后,本文对评估模型最佳状态数的选取进行了讨论,提出模型状态数混合和不同配置综合分数两种混合评分方法,在保持识别器性能的前提下,其相关性较固定3状态模型的结果分别提高了0.021和0.017。
[1] S M Witt. Use of Speech Recognition in Computer assisted Language Learning[D]. PhD Thesis, the University of Cambridge, Nov.1999.
[2] H Strik, K Truong, et al. Comparing different approaches for automatic pronunciation error detection[J]. Speech Communication, 2009, 51(10): 845-852.
[3] K Truong, A Neri, C Cucchiarini, et al. Automatic pronunciation error detection: an acoustic-phonetic approach[C]//Proceedings of the InSTIL/ICALL Symposium 2004. Venice, Italy: 2004: 135-138.
[4] A Neri, C Cucchiarini, W Strik. Automatic speech recognition for second language learning how and why it actually works[C]//Proceedings of the 15th International Congresses of Phonetic Sciences. Barcelona, Spanish: 2003: 1157-1160.
[5] 刘庆升,魏思,胡郁,等. 基于语言学知识的发音质量评价算法改进[J].中文信息学报,2007,21(4):92-96.
[6] 葛凤培,潘复平,董滨,等. 汉语发音质量评估的实验研究术[J].声学学报,2010, 35(2):261-266.
[7] 张峰,黄超,戴礼荣. 普通话发音错误自动检测技术[J].中文信息学报,2010, 24(2):110-115.
[8] Kim Chanwoo. Robust Speech Recognition Motivated by Auditory and Binaural Observations[D]. Department of Language Technologies Institute, Carnegie Mellon University, Ph D. thesis, July 2009.
[9] 郑静. 针对普通话水平测试的汉语自动发音评估[D]. 北京师范大学, 2008, 6: 30-31.
[10] H L Wang, J Q Han, T R Zheng. Quality evaluation and optimization of confusion network for LVCSR[J].中国科学院电子学报合集1994-2007.
[11] L Mangu, E Brill, A Stolcke. Finding consensus in speech recognition: word error minimization and other applications of confusion networks[J]. In Computer, Speech and Language, 2000,14(4): 373-400.
[12] J Xue, Y Zhao. Improved Confusion Network Algorithm and Shortest Path Search from Word Lattice[J]. ICASSP 2005, 2005: 853-856.
[13] J Zheng, C Huang, M Chu, et al. Generalized segment posterior probability for automatic Mandarin pronunciation evaluation[J]. ICASSP 2007, 2007: 201-204.
[14] 王璐,赵欣如,谢簪,等. 普通话测试信息分析[J]. 中文信息学报,2010,24(4):104-110.
[15] P D Patterson, K Robinson, J Holdsworth, et al. “Complex sounds and auditory images”[C].in Auditory and Perception. Oxford, UK: Y Cazals, L Demany, and K Horner, (Eds), Pergamon Press, 1992: 429-446.
[16] B C J Moore, B R Glasberg, “A revision of Zwicker’s loudness model”[J].Acustica—Acta. Acustica, 1996. 82: 335-345.
[17] M Slaney, “Auditory Toolbox Version 2” Interval Research Corporation Technical Report, 1998, no. 010, 1998.
[18] 李净,郑方,张继勇,等.汉语连续语音识别中上下文相关的声韵母建模[J]. 清华大学学报(自然科学版),2004, 44(1):61-64.
[19] J Li, F Zheng,W H Wu. Context-independent Chinese initial-final acoustic modeling[J]. ISCSLP’00, Oct. 13-15, 2000: 23-26, Beijing.
[20] 孙景涛. 介音在音节中的地位[J].语言科学,2006, 5(2):44-52.
[21] 魏思. 基于统计模式识别的发音错误检测研究[D].安徽:中国科学技术大学,2008.
[22] 何珏,刘加. 汉语连续语音中HMM模型状态数优化方法研究[J]. 中文信息学报,2006, 20(6):83-88.
