改进的Fisher准则及其在语音聚类中的应用
2013-04-23赵海涛李相莲
赵海涛,李相莲,李 阳
(1.海军驻南京924厂军事代表室,江苏 南京 211100;2.江苏自动化研究所,江苏 连云港 222061;3.海装上海局,上海 200051)
语音控制研究的目的是使机器根据人类说话的语句或命令做出相应的反应,在语音识别技术的基础上加入控制功能形成的语音操控系统在很多领域取得巨大的成功。语音识别技术是语音控制的主体,而在语音识别算法中,语音模板库建立的质量的好坏直接影响了语音识别准确率的高低,在军用语音操控系统或一些特殊行业中对语音识别的准确率要求极高,否则将可能以牺牲生命为代价。本文给出的基于修正后的Fisher准则的 LBG(Linde,Buzo,Gray)聚类算法,相比传统的Fisher准则,能更有效地优化聚类,从多人混合语音段中提取出单人的纯净语音,为无监督的说话人自适应提供更可靠的说话人模板库。
1 Fisher准则
Fisher准则是模式识别中的一种降维准则,是特征抽取的有效方法之一,其目的是寻找一个最佳投影向量,使投影后的样本可分离性好,即投影后样本的类间方差最大且类内方差最小,利用Fisher准则及改进后的准则能提取出具有更好鉴别能力的最优判别矢量[1-5],目前被广泛应用在图像分割[6-9]、人脸识别[10-12]、说话人识别[13]、聚类分析[14-15]等模式识别领域。
Fisher准则的主要思想是使类内距离尽可能小,类间距离尽可能大。根据Fisher比来确定最佳聚类数目,得到最佳聚类结果,Fisher比越大,表明类之间的区分度就越大。本文选用单个特征的Fisher比作为准则,对特征进行排序,选出那些鉴别性能较强的特征,从而达到降维的目的并得到较优的识别性能。
定义数据集中共有n个样本属于C个类w1,w2,…,wc,每一类分别包含 ni个样本分别表示样本x,第i类样本的均值,所有样本的均值在第k维上的取值[7]。单个特征的Fisher准则表示为
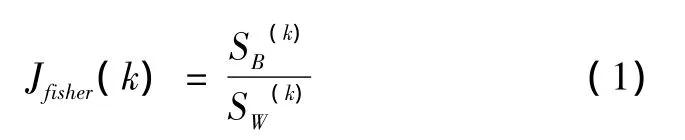

式(2)和式(3)分别为第k维特征的类间方差和类内方差的表达式[7]。
Jfisher称为特征的Fisher比或Fisher判据,某维特征在训练样本集上的Fisher比越大,说明该特征的类别区分度越好,即包含的鉴别信息越多,而噪声特征的Jfisher趋近于0,故Fsiher最大值对应了各聚类之间具有最大区分度时的最佳聚类数目。
在特征向量聚类过程中选用传统的Fisher准则,得到的Fisher值随着聚类数目的增加而增加,呈单调递增分布,这样并不能得到最佳聚类结果。针对这种情况,本文提出了修正后的Fisher准则,可以确定出最佳的聚类数目。
2 修正后的Fisher准则
与传统的Fisher准则不同,修正后的Fisher准则得到的最大Fisher值将对应于最佳聚类数目结果,而不是已设定的最大聚类数。修正后的Fisher准则[16]计算表达式为


3 优化聚类算法
聚类分析是多元统计分析的方法之一,也是非监督模式识别的一个重要分支。聚类方法将相似的数据点分为一类,而将不相似的数据点分为不同的类。LBG聚类算法由Yoseph Linde,Andres Buzo与Robert M.Gray三人共同提出 ,它是一种高效且直观的向量量化算法。其主要思想类似于分裂聚类算法,即将所有的样本初始化为一类,根据离质心距离最小化原则进行聚类,依次聚成两类,四类,八类,……,直到满足聚类停止条件为止。应用聚类算法实现特征向量的自动聚类,为使聚类停止,需要满足聚类停止条件,例如类别之间的相似度的最大值达到某个阈值或类别之间的差异性的最小值达到某个阈值,但是阈值的选取具有较大的随机性,尤其是最佳聚类数目的确定,目前没有较好的选定标准,因此聚类停止条件尤其是最终聚类数目设定的优劣,是决定最终聚类结果好坏的关键因素。
本文采用基于修正后的Fisher准则的非监督聚类LBG算法对混合语音段进行说话人分割与聚类,即聚类得出该语音段包含几个说话者,并分割出单人纯净的语音,即得出该段语音的说话者组成结构。该算法主要包括预处理、词单元分析和结构分析三个部分。算法的整体框架如图1所示。

图1 说话者组成结构分析算法结构框图
预处理阶段:输入语音流经过采样、量化、分帧和活动语音检测VAD(Voice Activity Detection)。本实验选取16kHz采样率和16bit量化位数,帧长为10ms。VAD要辨认出有效语音部分和非语音部分,说话者分割和处理需要对有效的部分进行处理和分析。
词单元分析:选取MFCCs(Mel Frequency Centrum Coefficients)特征量进行特征提取,选用非监督聚类LBG聚类算法,通过特征量的自动聚类得到词单元。特征向量之间的相似距离测度选用欧式距离。
结构分析:候选边缘分析算法类似于BIC算法,其根据是处于边界边缘两边的词单元分差异很大或者很小,然后用帧长为3s的LBG聚类算法得到更大的语音片段,采用基于阈值的短小片段合并算法进行结构边界调整,最后对得到的语音片段进行标注,得到输入混合语音段落的说话者组成结构。
其中,在结构分析部分的语音片段单元聚类中应用了修正后的Fisher准则,根据最大Fisher值来确定最佳聚类数目,对应说话者个数。
4 实验结果与分析
实验语音数据库包含50个语音段落,共由10个录音者在噪音系数较小,相对比较安静的实验室录制完成,每个语音段落由至少1个,最多10个录音人录制完成,存储为wav格式。
随机选取语音库中某个语音段进行语音片段聚类时,根据库中录音人数量设定最大聚类数目为10,传统的与修正后的Fisher值曲线对比图如图2所示。
在图2中,横轴代表聚类数目,最大值为10,纵轴代表不同的聚类数目对应的Fisher值。可以看出,在聚类过程中,选用传统的Fisher准则,得到的Fisher值随着聚类数目的增加而增加,确定出的最大Fisher值对应的聚类数目恒为最大聚类数目10,显然不符合结构分析结果;而应用修正后的Fisher准则后,聚类数目随Fisher值呈具有最大值的曲线分布,此时Fisher最大值对应的聚类数目8为最终聚类数目,其聚类对比结果如图3所示。
从图3可以看出,传统的Fisher准则最佳聚类数目为10,修正后Fisher准则最佳聚类数目为8,与被测试语音段的真实说话者数量相符,分别与图2中最大Fisher值确定的最佳聚类数目相对应,与前者相比,后者减少了聚类中多余碎片的产生,优化了聚类分析,更符合真实结果。
对实验语音数据库的50个语音段落进行结果统计分析,得出修正后的Fisher准则与传统的Fisher准则在确定最佳聚类数目的准确率及说话者组成结构分析对比结果如表1所示。
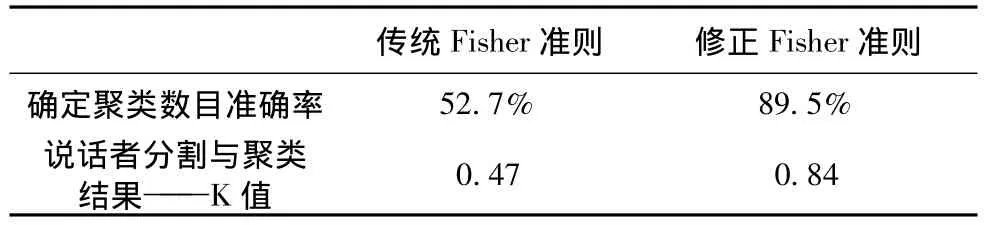
表1 Fisher准则修正前后结果对比

图3 传统与修正后Fisher准则聚类结果对比图
准确率由准确确定出最佳聚类数目的语音段落的总个数与语音库中语音段落总数(即50)的比值来表示。从表1可以看出,修正后的Fisher准则在确定最佳聚类数目时的准确率远远高于应用传统Fisher准则时的准确率,显著提高了聚类结果精度,从而使得说话者分割与聚类结果的准确率显著提高,此处用统计量K[16,18]作为评价标准来衡量语音段说话者分割与聚类结果,K值越大,说明结构分析结果与真实结果的匹配程度越高。由此可以看出,修正后的Fisher准则能有效的优化聚类分析,为无监督的说话人自适应说话人模板库的建立提供了可靠的基础。
5 结束语
在聚类分析过程中,本文应用传统的Fisher准则,Fisher值随着聚类数目的增加呈单调递增分布,而根据修正后的Fisher准则得到的Fisher最大值对应了最佳聚类数目,由此得出的最终聚类结果精度更高,从而优化了聚类。当然本文提出的基于修正后的LBG聚类算法在确定聚类数目准确率及说话人分割结果方面都有待改进与提升。应用本文算法对混合语音段进行说话人分割与聚类,根据得出的纯净单人语音进行码本提取,在基于特定人或特定某些人的语音操控系统中,为建立基于无监督的、说话人自适应的说话人模板库奠定了良好的基础。
[1]王飒,郑链.基于Fisher准则和特征聚类的特征选择[J].计算机应用,2007,27(11):2812-2813,2840.
[2]黄国宏,刘刚.一种改进的基于Fisher准则的线性特征提取方法[J].计算机仿真,2008,25(7):192-195.
[3]王郑群,等.基于Fisher准则的多特征融合[J].计算机工程,2002,28(3):41-42.
[4]Sa.W,et al,Feature Selection by Combining Fisher Criterion and Principal Feature Analysis[J].In Proc.International Conference on Machine Learning and Cybernetics(ICMLC 2007)Hong Kong,2007,2:1149-1154.
[5]郑宇杰,等.一种基于Fisher鉴别极小准则的特征提取方法[J].计算机研究与发展,2006,43(7):1201-1206.
[6]陈果.图像阈值分割的Fisher准则函数法[J].仪器仪表学报,2003,24(6):564-567,576.
[7]温淑焕,唐英干.基于Fisher准则的多阈值图像分割方法[J].激光与红外,2008,38(7):741-743.
[8]关新平,等.二维属性直方图的Fisher准则图像分割及快速递推算法[J].信息与控制,2009,38(6):659-664.
[9]童莹,邱晓晖.基于Fisher准则函数的二维阈值图像分割算法[J].电力系统通信,2004,25(9):36-39,47.
[10]郭娟,等.基于加权Fisher准则的线性鉴别分析及人脸识别[J].计算机应用,2006,26(5):1037-1039,1049.
[11]夏文彬.基于特征脸及Fisher脸的人脸识别方法[D].南京:南京邮电大学硕士学位论文,2008.
[12]陈佳佩,卢元元.基于核函数的逆Fisher人脸识别[J].计算机工程,2011,37(21):179-181.
[13]张芸.基于Fisher准则和数据融合的说话人识别方法研究[D].上海:上海大学硕士学位论文,2006.
[14]曹苏群,等.基于模糊Fisher准则的半模糊聚类算法[J].电子与信息学报,2008,30(9):2162-2165.
[15]支晓斌.基于模糊Fisher准则的自适应降维模糊聚类算法[J].电子与信息学报,2009,31(11):2653-2658.
[16]李相莲.基于音色单元分布的音乐结构分析[D].济南:山东大学硕士论文,2010.
[17]Y.Linde,A.Buzo,R.Gray.An Algorithm for Vector Quantizer Design[J].IEEE Transactions on Communications,vol.28,1980:84-94.
[18]H.Lukashevich.Towards Quantitative Measures of Evaluating Song Segmentation[C].Proc.9th International Conference on Music Information Retrieval(ISMIR'08),September,2008:375-380.
