PCI Express技术在嵌入式MPSoC中的应用*
2013-03-23尹亚明刘秋丽陈书明
尹亚明,刘秋丽,陈书明
(1.国防科学技术大学计算机学院,湖南长沙410073;2.河南信息工程学校计算机科学系,河南郑州450003)
1 引言
当前,单处理器系统芯片SoC(System-on-Chip)已远不能满足日益复杂的嵌入式应用需求,而硅工艺技术的快速发展也为日趋复杂的IC设计提供了充分的土壤。多处理器系统芯片MPSoC(Multi-processor System-on-Chip)[1]的提出与研究获得了广泛关注,凭借其高性能、并行处理和灵活编程性等优点,MPSoC已经成为超大规模集成电路VLSI研究领域的前沿和热点。
PCI Express作为第三代高性能I/O互连技术[2],继承了第二代总线体系结构最有用的特点,并且采用了计算机体系结构中新的研究成果,能够实现两台设备之间通信的串行、点对点的互连,同时采用基于报文交换技术来互连大量的设备。当前,PCI Express的发送和接收数据的速率是2.5 Gb/s,具有很高的串行传输速率,适用于大量成块的数据传输任务,广泛应用于芯片设计当中。但是,PCI Express更多地是在通用计算机领域的应用与实现,鲜有嵌入式系统设计采用PCI Express技术。
本文综合考虑嵌入式MPSoC系统设计中的数据传输需求与PCI Express技术特点,采用基于IP的快速设计方法,将PCI Express互连技术应用于一款自行研制的嵌入式片上多处理器YHFT-QDSP(Quadruplex DSP)[3]系统中,缩短了设计周期并简化了设计过程,同时获得了良好的设计结果。
2 PCI Express技术特点与应用分析
2.1 PCI Express技术特点
传统的PCI总线协议存在可扩展性差、安全性与容错性差和系统I/O整体吞吐率低等缺陷,导致I/O互连技术及体系结构发生了重大变革,相继涌现出PCI Express、RapidIO、Hyper Transport以及InfiniBand等新型I/O互连技术[4],它们采用基于报文交换的点到点的互连替代共享总线结构,提供了高带宽、可扩展的I/O互连,克服了传统的共享I/O总线结构的种种弊端。
2001年正式发布的PCI Express的前身是Intel公司率先开发的第三代I/O总线技术3GIO,其目标之一是提供芯片间的局部互连总线,二是以较低开销提高现有PCI结构的性能。PCI Express采用基于报文交换的点对点串行传输技术为每个设备分配独立通道,所有设备均通过各自独立的通道发送和接收数据,设备之间无需共享资源。其串行链路采用LVDS接口电路和时钟数据恢复CDR(Clock Data Recovery)同步技术,利用8 b/10 b编码机制将时钟信号嵌入数据信号中,单线单向数据传输率可达2.5 Gb/s。除了高带宽以外,PCI Express还支持数据交换、信息封包优化、虚信道和频率带宽可变等技术,可通过2、4、8、12、16或32线多路技术线性地扩展I/O带宽。PCI Express基于Load Store结构、PCI寻址模式,沿用PCI-X分割事务、生产消费者排序规则等关键技术与思想;但是,与PCI和PCI-X总线不同的是,PCI Express可延伸到系统之外,可将外部设备直接与系统内部的PCI Express总线连接。跨平台兼容是PCI Express非常重要的特点之一,为广大用户提供了平滑的升级平台。PCI Express作为第三代I/O互连技术,无论是在速度、性能、功能,还是可扩展性和兼容性等各方面,与PCI和PCI-X总线相比都有了显著改进和提高,可为台式机、笔记本、服务器、通信平台、工作站和嵌入式系统提供统一标准的高性能I/O互连。
2.2 PCI Express技术应用分析
由于PCI Express是标准的计算机系统结构I/O互连技术规范,因此在国际上关于PCI Express技术的学术性研究并不多见。更多的是使用PCI Express技术的工程实现型研究或针对PCI Express协议中某个子问题的研究。
文献[5]中给出了基于Xilinx的Virtex-II Pro、Virtex-4和Virtex-5系列FPGA设备的PCI Express 1.0规范的设计实现。为了实现PCI Express 2.0规范,将原有设计从Virtex-5系列移植到Virtex-6系列上,解决了相关频率需求和板级设计问题。文献[6]详细分析了PCI Express物理层技术特点,针对串行接收端的数据时钟恢复技术进行研究,采用基于锁相环结构的数据时钟恢复技术设计了一款速率为2.5 Gb/s的高速物理层电路。国际上也有在片上多核系统中集成PCI Express技术的研究,如第四代UltraSPARC T3片上多核处理器[7]中集成了两路PCI Express 2.0规范的接口,实现了5.0 Gb/s的高速外部扩展功能。文献[8]中给出一款四核嵌入式原型系统芯片RP-1,其设计目标是满足高能效、高性能的嵌入式系统应用。RP-1的片上系统总线也集成了PCI Express扩展接口,作为系统外设扩展使用。此类多核系统虽集成了PCI Express技术,但其应用目的是为整个系统扩展外设所用,而本文的目标是将PCI Express的高速数据传输能力用于多核芯片的扩展连接,属于对该技术的一种创新型尝试。
3 YHFT-QDSP及其层次化互连结构
YHFT-QDSP是一款异构多核DSP超结点芯片,其主体由一个RISC内核和四个高效精简的DSP内核构成[9]。以QDSP超结点为中心,采用PCI Express技术实现的片间互连组件可以扩展为更大规模的众核系统。
QDSP超结点结构如图1所示,包括Leon3通用处理器及其AMBA总线上针对设计需求而保留的外部设备。Leon3在QDSP中负责整片SoC的启动、简单的任务派发和结果回收等工作,通过AH/MB(Master Bus)桥接模块和32位的MB总线实现与四个DSP内核的连接,其中MB总线挂接在每个DSP内核的EDMA外设总线上。DSP内核是QDSP系统的主体运算模块,四个DSP运算核同构,每个DSP内核包含独立的一级指令和数据Cache、一个二级Cache和独立地址空间的EMIF外部存储器模块。共享数据缓冲池模块SDP(Shared Data Pool)[10],为四个DSP内核共享,采用请求队列和信号灯共同实现各DSP内核对共享数据的一致性操作,完成片内DSP间的小数据量交换。全局通信模块QLink[11]挂接在每个DSP内核的EDMA外设总线上,负责实现全局片内及片间数据传输任务,其内部实现自行设计的QLink协议,具有发送和接收全双工数据通路。定制实现的8端口、16位数据宽度的crossbar交叉开关,其中四个端口与片内各DSP内核的QLink相连,另外四个端口则与QDSP的四个片间互连模块相连,实现全交叉灵活的数据交换。片间互连模块采用PCI Express协议实现片间高速数据传输,四个片间互连模块可实现多SoC的灵活结构扩展,同时通过交叉开关实现片间模块与片内模块的全交叉互连,能够自由灵活地实现多种通路的数据传输。
QDSP系统实现了层次化的互连结构,按照其应用目的与设计指标可分为三个层次:片内快速紧耦合共享缓冲池(FCC-SDP)、片内实时大粒度数据传输引擎(QLink)和片间高速互连模块(PCI Express)。
3.1 片内快速缓冲池
FCC-SDP是QDSP超结点内四个DSP内核的一种共享存储结构。FCC-SDP在存储层次上与一级Cache平行,如图1所示,可以被访存指令直接访问;采用多体并行结构,支持双体交叉访问模式和基于硬件信号灯的自动同步机制,支持多个DSP内核的并行访问与快速核间数据交换,两核之间交换单个数据只需四拍;采用八体并行SRAM存储器实现,容量为8 KB,具有四个DSP内核共享的全局地址,具有访问延迟小、存取速度快、同步开销低和编程使用灵活等特点。FCCSDP在QDSP的层次化互连结构中处于第一级,实现了DSP内核之间最紧密的一级互连,传输粒度最小但速度很快,适用于少量数据或某些标量的核间传递。
3.2 QLink片内通信机制
QLink片内通信机制的设计目标是实现QDSP超结点芯片中DSP核间的大粒度批量数据通信,并能够在多个DSP之间实现组播通信。QLink传输模块向内与DSP的DMA总线挂接,数据传输通路宽为32位;向外与交叉开关端口挂接,数据通路宽为16位。相对于片内快速缓冲池来说,QLink能更有效地完成大批量数据的核间通信,对于某些运算量比较大的应用,使用QLink进行DSP间数据传输能获得更好的效果。QLink通信过程采用基于报文交换的QLink协议完成,QLink协议是自主设计的一种可同时用于片内与片间数据传输的通信协议。QLink通信机制在QDSP的层次化互连结构中处于第二级,实现了QDSP片内DSP核间的数据通信。相对于第一级的片内快速缓冲池,其传输能力更强,适用于大粒度批量的数据传输,是一种典型的基于报文交换的数据传输网络。

Figure 1 Architecture of YHFT-QDSP图1 YHFT-QDSP系统结构
3.3 片间PCI Express高速互连模块
片间PCI Express高速互连模块处于QDSP层次化互连结构第三级,其设计目标是实现QDSP超结点芯片间的扩展连接,通过这种扩展可以构成更大规模的处理系统,从而完成某些大型特定应用。
图2给出一种典型的QDSP超结点扩展连接应用结构,其拓扑结构为二维Mesh。片间互连模块分为东、西、南、北四个扩展接口,分别挂接于片内交叉开关中的四个端口,实现片内DSP核到片外的数据交换网络。QDSP超结点之间通过PCI Express高速互连接口进行连接。系统中属于不同超结点的DSP核之间可以通过PCI Express高速互连网络实现数据通信。
4 PCI Express在QDSP中的应用
一个QDSP超结点含有四个片间互连模块,本文以其中任意一个为例来说明PCI Express互连技术是如何应用于QDSP嵌入式超结点中的。图3所示为QDSP超结点中片间互连模块的结构图,其中左侧为QDSP超结点结构简图,仅体现了四个内DSP核与四个片间PCI Express互连模块,这8个模块通过一个8×16位的交叉开关实现交叉互连,可以实现任意两个模块之间的数据传输。这里结合图2来说明片间数据传输的工作过程,一次批量数据传输是在两个DSP内核之间进行的,即数据发出者与数据接收者是系统中某两个QDSP超结点中的某两个DSP内核。含有数据发出者和接收者的QDSP分别为源结点和目的结点,其他在数据传输路径上经过的QDSP均为过路结点。对于一次数据传输过程,路径上经过的QDSP超结点内部仅完成了两个PCI Express片间模块之间的数据传输,只有源结点与目的结点内部才实现了DSP内核与PCI Express片间模块之间的数据交换。图3右侧所示虚线框内为PCI Express片间互连模块各子模块与接口,主体包括三部分:QLink-PCIE桥接模块QPB(QLink PCIE Bridge)[12]、PCIE IP核和PCIE全定制物理层模块(PCIE PHY)。
4.1 QLink-PCIE桥接模块
QLink-PCIE桥接模块负责完成QDSP超结点内部的QLink协议到片间数据传输的PCI Express协议之间的转换,桥接模块上、下接口分别与交叉开关和PCIE IP核接口相连接。图4为QLink-PCIE桥接模块结构图,其主体模块的实现按照发送(QDSP超结点片外方向)和接收(QDSP超结点片内流动方向)两个方向来完成,内部包括了数据的拆分与拼装、数据的接收缓冲与发送。另外,在QLink-PCIE桥内部实现了源路由与XY路由两种全局路由策略。因此,QLink-PCIE桥接模块既是一个协议转换器,同时也是一个全局互连路由器。

Figure 2 Super-node interconnection of QDSP图2 QDSP超结点扩展互连示意图

Figure 3 Inter-chip interconnection module of PCI express图3 PCI Express片间互连模块
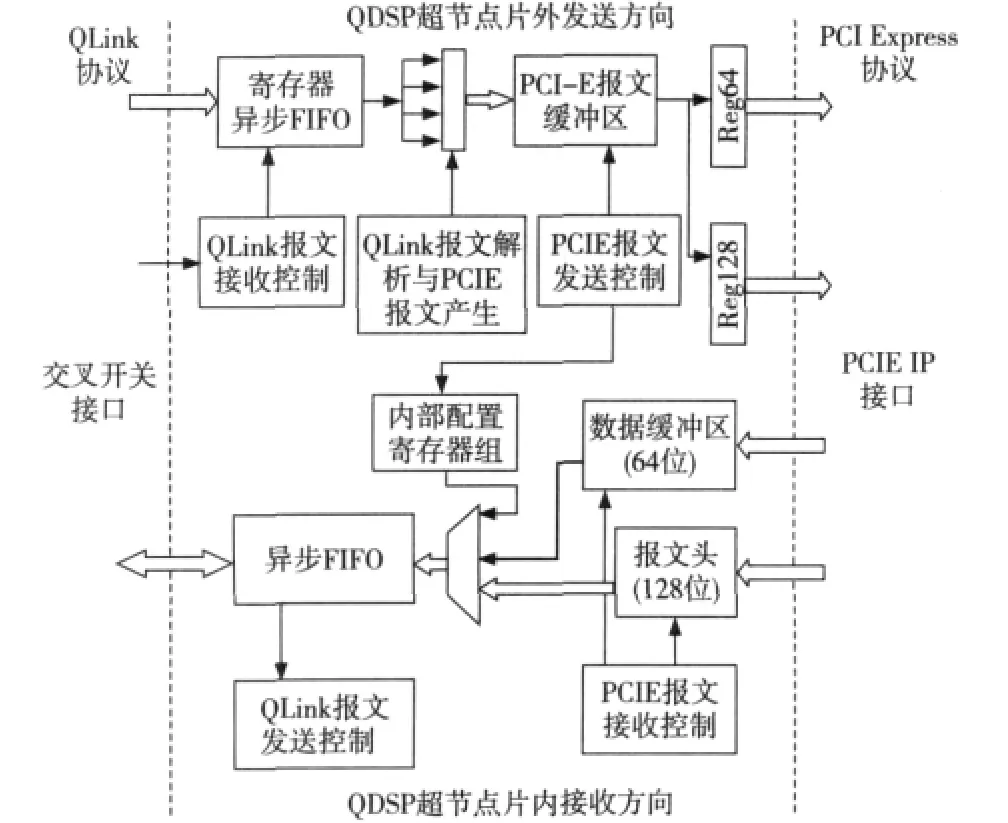
Figure 4 Structure diagram of QLink-PCIE图4 QLink-PCIE桥接模块结构图
4.2 PCI Express IP核
PCIE IP核为PCI Express标准协议的主体实现模块,采用Verilog描述语言完成,是一款第三方IP核,包括PCI Express协议的事务传输层、数据链路层和物理层的PCS子层三个部分。其用户层接口给出了明确定义的传输模式和接口信号,主要包括128位的PCIE协议报文头和64位数据信号线,还有一些其他的控制信号。物理层接口为与PCIE全定制物理模块的PCS子层接口协议,为250 MHz的10位数据信号。采用基于IP核的设计方法有效简化了设计复杂度和设计周期。
4.3 PCI Express全定制物理模块
全定制PCIE物理层模块,即PCIE PHY,是PCI Express协议电器物理层模块,包括高速串行-解串Ser Des(Serializer-Deserializer)电路的定制实现,接收端还包括从接收到的数据信号流中恢复出时钟信号的CDR模块。PCIE PHY还完成高速差分I/O,即LVDS接口的定制实现。
5 设计与实现
设计采用SMIC的0.13μm工艺单元库,QLink-PCIE桥模块单独综合面积为0.12 mm2,QLink-PCIE与PCIE IP共同综合总面积为0.65 mm2。
本文构建了如图2所示的RTL级SoC测试平台,但考虑测试复杂度和运行速度问题,将系统规模选定为四个QDSP超结点构成一个2×2的二维Mesh网络结构。其中互连模块均采用真实的RTL级代码实现,DSP的数据发送与接收采用模拟方法实现,通过文件读入写出方式对片间互连操作进行验证和性能统计分析。
片间互连通路性能统计数据如表1所示。从表1中可知,片间通路适合于连续大量数据的传输,从而能更好地掩盖通路的建立时间;同时,获得了约1.6 Gb/s的有效数据带宽,满足了系统片间数据传输的性能需求。对QPB模块的延迟信息进行统计发现,QPB内异步FIFO传输延迟为2~3拍PCI Express时钟(PCLK);发送方向异步FIFO输出到PCI Express接口报文请求产生延迟最短为16 PCLK,这是由于发送方向内部具有缓冲区存储转发导致的;接收方向由于使用虫孔路由其延迟为固定的4 PCLK。

Table 1 Performance of inter-chip route path表1 片间互连通路性能统计
我们在现有测试平台的基础上进行了改进,每个QDSP内加入一个真实DSP模块,生在其上运行32×32的FFT程序。目的是测试整个环境运行真实程序的能力,每个SoC内的一个DSP内核参与到运算当中,四个DSP内核共同完成FFT程序的运算并得到正确结果。
6 结束语
工艺技术不断发展,应用需求日益复杂,带来了单处理器片上系统时代向多处理器片上系统时代的转变。面对层出不穷的多核处理器芯片,如何能将现有技术更好地应用于片上系统是设计者和研究者都要进行思考的问题。PCI Express是一种成熟、高效的大规模高性能计算机互连技术,针对其技术特点和片上多处理器系统的设计需求,本文将其应用于一款自行研制的片上多DSP系统QDSP芯片中,取得了良好的设计结果,同时为片外设计技术向片上设计的移植给出了很好的思路。在未来的工作中将考虑尝试更多的技术融合,并将其应用于多处理器片上系统的设计中。
[1] Ahmed A J,Wayne W.Multiprocessor systems-on-chips[M].San Francisco:Morgan Kaufmann,2005.
[2] Budruk R,Anderson D,Shanlev T.PCI express system architecture[M].Boston:Addison Wesley,2003.
[3] Chen Shu-ming,Wan Jiang-hua,Lu Jian-zhuang,et al.YHFT-QDSP:High-performance heterogeneous multi-core DSP[J].Journal of Computer Sicence and Technology,2010,25(2):214-224.
[4] Li Qiong,Guo Yu-feng,Liu Guang-ming,et al.Research and development of I/O interconnection and architecture[J].Computer Engineering,2006,32(12):93-95.(in Chinese)
[5] Nambiar S O S,Abhyankar Y,Chandrababu S.Migrating FPGA based PCI express Gen1 design to Gen2[C]∥Proc of 2010 International Conference on Computer and Communication Technology,2010:617-620.
[6] Wang Kun,Xu Wen-qiang,Ma Zhuo.Design and implementation of the 2.5 Gbps high-speed ser Des for PCI-express[J].Computer Engineering &Science,2009,32(11):62-65.(in Chinese)
[7] Shin J L,Huang D,Petrick B,et al.A 40 nm 16-core 128-thread SPARC SoC processor[J].IEEE Journal of Solid-State Circuits,2011,46(1):131-144.
[8] Arakawa F.Multicore SoC for embedded systems[C]∥Proc of 2008 International SoC Design Conference,2008:I180-I183.
[9] Chen Shu-ming,Li Zhen-Tao,Wan Jiang-hua,et al.Research and development of high performance YHFT digital signal processor[J].Journal of Computer Research and Development,2006,43(6):993-1000.(in Chinese)
[10] Chen Shu-ming,Wang Dong,Chen Xiao-wen,et al.A small close-coupled fast shared data pool for multi-core DSPs[J].Chinese Journal of Computers,2008,31(10):1737-1744.(in Chinese)
[11] Guo Bao-dong,Liu Xiang-yuan,Xu Yi,et al.Research and implementation of Qlink——a communicaiton mechanism to heterogeneous multi-core DSP[C]∥Proc of NCCET,2007:1.(in Chinese)
[12] Yin Ya-ming,Chen Shu-ming.Design and implementation of a inter-chip bridge in a multi-core SoC[C]∥Proc of the 4th International Conference on Design &Technology of Integrated Systems in Nanoscal Era,2009:102-106.
附中文参考文献:
[4] 李琼,郭御风,刘光明,等.I/O互联技术及体系结构的研究与发展[J].计算机工程,2006,32(12):93-95.
[6] 王堃,许文强,马卓.PCI Express中2.5 Gbps高速Ser Des的设计与实现[J].计算机工程与科学,2009,31(11):62-65.
[9] 陈书明,李振涛,万江华,等.“银河飞腾”高性能数字信号处理器研究进展[J].计算机研究与发展,2006,43(6):993-1000.
[10] 陈书明,汪东,陈小文,等.一种面向多核DSP的小容量紧耦合快速共享数据池[J].计算机学报,2008,31(10):1737-1744.
[11] 郭保东,刘祥远,徐毅,等.一种异构多核DSP互连通信机制Qlink的研究与实现[C]//第十一届计算机工程与工艺全国年会,2007:1.
