基于计算几何分类器的帕金森病语音障碍可视化诊断分析
2013-03-10洪文学任宏雷燕山大学信息科学与工程学院秦皇岛066004
张 涛 洪文学 任宏雷(燕山大学信息科学与工程学院,秦皇岛 066004)
2(燕山大学生物医学工程研究所,秦皇岛 066004)
引言
帕金森病是一种常见的中老年神经退行性疾病,具有发病率高且无法治愈的特点。目前最有效的办法就是早发现,以减少发病后期带来的损失。但由于现有的帕金森病早期诊断过程比较繁琐,造成漏诊率高达6 成。因此,寻找检测方便的各种帕金森病早期诊断的方法,成为了帕金森病研究的热点[1 -2]。
在各种帕金森病的早期诊断方法中,有一种基于语音障碍的帕金森病机器诊断方法,由于其具有测量方便、成本低廉的特点,受到了广泛的关注[3]。在现有的基于语音障碍的帕金森病分析中,研究主要集中在两个方面:特征选择与数据分类。
在特征选择的研究中,目前主要有穷举法[4]、粗糙集方法[5]和遗传算法[6]3 个方法。其中,穷举法可以获得相对较高的分类精度,但由于其计算复杂度较高而无法获得实际应用,同时其特征融合过程难以物理解释;利用粗糙集方法做特征选择,其结果为22 特征,实际上为全选过程;遗传算法通过模拟自然进化过程来搜索最优解,其本质属于随机类算法,难以得到稳定解。对于帕金森病这样一种需要进行病原解释的疾病,显然其诊断在知识发现领域是无能为力的。
在对帕金森病数据的分类研究中,Little 等人的研究小组采用核函数的支持向量机(SVM)对其进行分类[7],获得了较为理想的分类精度。Freddie Åström 利用并行神经网络进行帕金森病的预测[8],取得了和Little 近似的研究成果。以上方法虽然在分类精度上达到了较高水平,但在数据解释上,由于映射关系与帕金森病语音障碍物理意义的脱节,造成难以对该分类结果进行解释。同时,由于难以让使用者获得直观理解,因而分类过程的可解释性较差。
为了同时满足分类的高精度和结果的可解释性,笔者提出利用基于计算几何原理的多维筛分类器[9]对帕金森病的数据进行可视化诊断。作为典型的可视化分类器,多维筛分类器从数据的表示到分类界面的形成与数据的分类,做到了全程可视化,且数据与过程对应的物理意义明确,解释性强,不但有利于完成更高精度的数据分类,而且可以对分类结果进行解释。本研究利用多元图表示原理,对基于语音障碍的帕金森病数据进行可视化表示与分类,并比较不同参数下的分类结果及其分析。
1 测试数据集和方法
1.1 测试数据集
为了保证实验数据的客观性、可重现性与可对比性,所有实验数据均采用国际公开数据库完成。在国际公开数据库中,有关语音障碍的帕金森病的数据库只有两个,分别为Parkinson's Dataset(帕金森数据集,http://archive. ics. uci. edu/ml/ datasets/Parkinsons)和Parkinsons Telemonitoring Data Set(远程帕金森数据集,http://archive. ics. uci. edu/ml/datasets/Parkinsons +Telemonitoring)。
Parkinson's dataset 为牛津大学的帕金森病检测数据库(OPDD),于2007 年由牛津大学的Max A.Little 建立,共采集到31 人195 份语音样本,其中23人为确诊的帕金森病患者。被测试对象的年龄在46 ~85 岁之间,患病时间0 ~28 年不等每个对象都分6 次发元音[a],每次的时间为36 s。
在帕金森数据集的基础上,Max A. Little 于2009 年公布了远距离测量的帕金森病语音数据远程帕金森数据集Parkinsons Telemonitoring Data Set(PTDS)。在该测试中,选择了42 名早期帕金森患者,共收集到5 875个数据样本,每个样本记录26 个属性,因此该数据集具有测试意义。
帕金森数据集与远程帕金森数据集均为实测的语音障碍与帕金森病的关系。其中,帕金森数据集关注的是能否用语音特征完成患者是否患有帕金森病的诊断,而远程帕金森数据集则是通过语音特征来完成帕金森病的严重程度判断。从分类过程上看,二者的分类过程类似,且帕金森数据集表示更为简单。因此,在本文的描述中,如不做特殊声明,所有的数据表示与计算均采用帕金森数据集作为分析样本,仅在最终分类结果处加入远程帕金森数据集的分类结果,以降低表示过程的重复。
1.2 帕金森病的可视化分类过程
多维筛可视化分类器对帕金森病的可视化分类原理见文献[10]。图1 给出了帕金森数据集几个典型的子分类空间的数据分布。其中,(a)为最大最小基音频率的组合,可以看到,相同物理含义的特征组合虽然具有一定的分类效果,但混叠严重;(b)为Jitter 的百分比与绝度值组合,由于仅为比例变换,因此走势基本一致,数据不具备分类意义;(c)为DDA 和NHR 的组合,在大多数的区域中,两类数据基本完全混叠,其分类意义上效果甚至低于(a);(d)为D2 和DFA 的组合,虽然呈现严重的非线性分布,但分离程度较高。
由此分析可知,从数据分类的角度看,帕金森数据集不但数据空间分布混叠严重,而且类别分布筋混叠严重。这样的数据分布特点符合主动生长的非线性模糊分类特性,因此符合多维筛分类器特色。
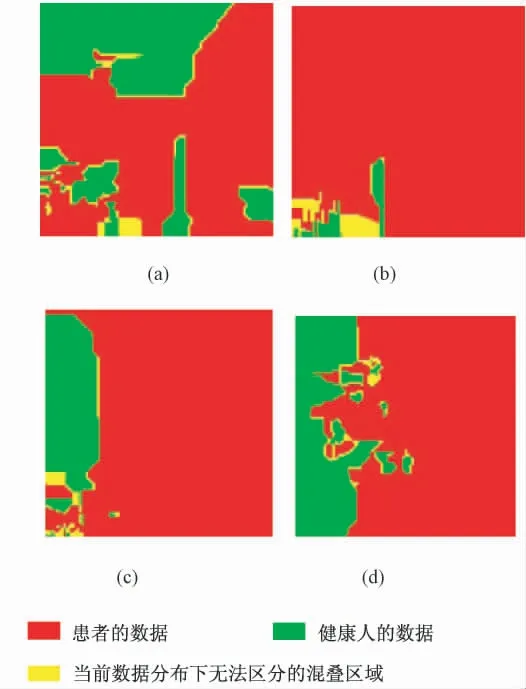
图1 帕金森数据的分类空间。(a)最大最小基音频率组合;(b)Jitter 的百分比与绝度值组合;(c)DDA 和NHR的组合;(d)D2 和DFA 的组合Fig.1 The classify spaces of OPDD. (a)Maximum and minimum vocal fundamental frequency;(b)Jitter(%)and Jitter(Abs);(c)DDA and NHR;(d)D2 and DFA
1.3 实验方法
在可视化模式识别中,为了保证方法的普适性,设置了众多可调参数。对于同一个数据,不同的表示方法、不同的量化阶、不同的非线性优化以及加权算法,都将导致最终分类精度的差别。下面将以帕金森数据集与远程帕金森数据集为测试对象,论述不同参数下多维筛分类器各阶段的表现与分类精度,进而验证帕金森病在可视化模式识别下的可行性。
在对帕金森数据集的测试中,选取全部特征作为备选特征,把空间量化分为水平量化与垂直量化进行,分别对应组成散点图的两个特征分量。量化级从5 级开始,以5 级为递进量,共递进20 级,即最高量化级为100。因此,对每个特征进行20 次不同等级的量化,并将这些量化后的特征分别进行组合。对于远程帕金森数据集,采用横纵量化阶相等的方案进行测试。
在特征选择分析中,通过对不同特征组成的分类空间的可视化分析,确定分类意义明显的分类空间,进而对所用特征进行分析,以此发现可视化模式识别选用的特征向量与帕金森病临床诊断之间的关联。同时,可获得分类性能的直观认识,利用LDA、QDA、kNN、parzen 窗、SVM 等经典分类器作为对比测试方法。为保证测试结果的客观性,参考分类器均采用PRTools 中的软件包完成。
2 实验结果与讨论
2.1 不同的量化级下分类精度对比
对同一个数据,采用不同的量化级可获得不同的数据量化精度。一般来说,量化级越多,量化后的图形与原始图形越接近。但在模式识别中,适当地降低量化等级,不但可以有效地降低运算复杂度,同时可以消除部分由于测量不精确而形成的孤立点对分类精度的影响。因此,在不同的量化级下,分类器将表现不同的分类精度。下面的测试关注量化级对分类精度的影响。
利用文中1.3 节所述的方法,对帕金森数据集进行测试。为了直观地观察不同量化级对分类精度的影响,采用形成等高区域表示图,其结果如图2所示。
由图2 可知,量化阶对诊断精度的影响大约为5%。当量化级过小时,分类精度较低;而随着量化级数的升高,分类精度也相应提高;但当超过某一精度时,精度反而下降。对于帕金森病数据,当横纵量化阶均为65 时,可达到当前条件下的最高分类精度91.28%这和Little 等的实验结果相当。但从整体趋势上看,图形的对称性较为明显,因此其影响趋势具有横纵量化阶趋同的结构——当类空间横纵方向量化阶相等时,对于分类性能的影响具有典型意义。基于此,对于远程帕金森数据集,采用横纵量化阶相等的方案进行测试,其结果如表1 所示。由此可以看到,与帕金森数据集相同,远程帕金森数据集的分类精度也受到量化等级的影响。

图2 量化阶对帕金森数据集精度的影响Fig.2 The relationship between quantization levels and precision in OPDD
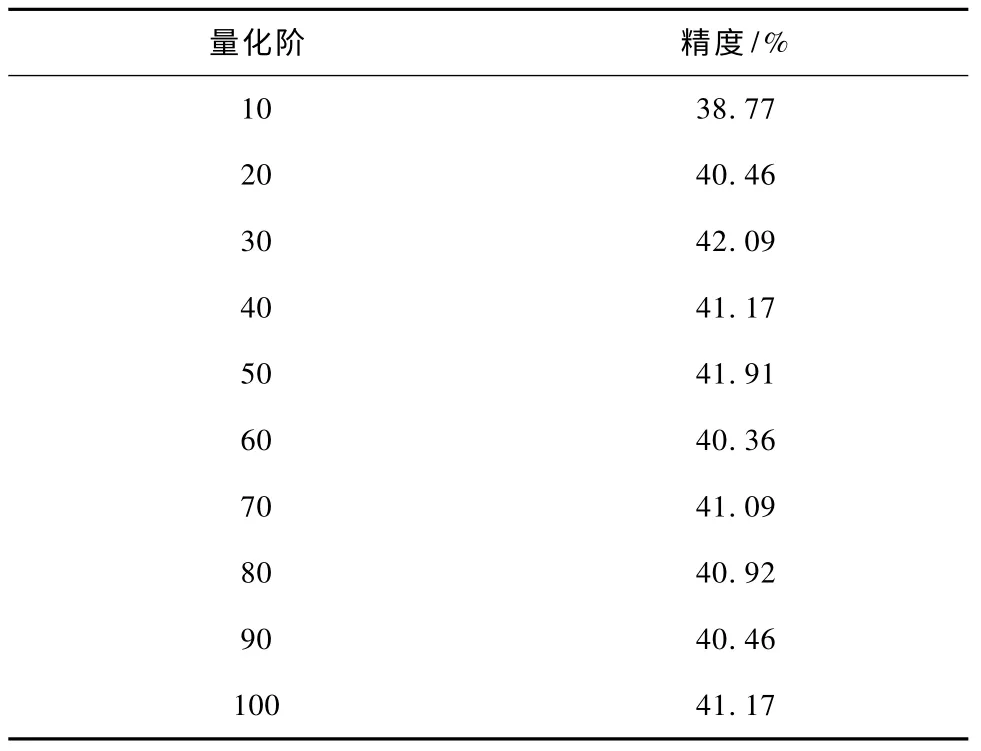
表1 量化阶对远程帕金森数据集精度的影响Tab.1 The relationship between quantization levels and precision in PTDS
2.2 特征选择分析
对于帕金森数据,利用散点图表示下的多维筛分类器进行分类,共形成231 个特征空间。在相同条件下,不同的子分类器空间下分类的精度将有所不同。图3 表示两个不同特征组合下形成的分类空间。其中,(a)可以对健康与患病两类情况分别进行表示,仅有少部分为模糊区域;(b)中的大部分区域表示患病类别,而确定的健康类别占有面积很少,甚至低于模糊区域面积。因此,从应用角度看,(a)适合于进行分类,而(b)对于分析患者的患病严重程度可能更为合适。
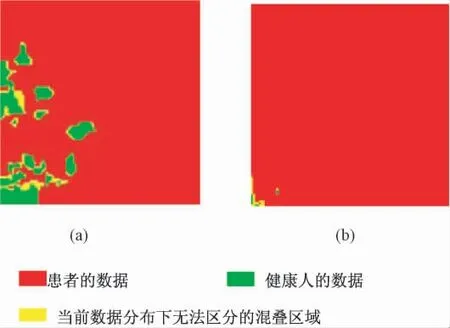
图3 不同特征组合下的子分类器类空间。(a)PPE 与DFA 组合空间;(b)APQ3 与APQ5 组合空间Fig.3 The sub classifier spaces combined by different features. (a)PPE and DFA;(b)APQ3 and APQ5
对子分类器信息的分析过程,实质是对特征进行筛选的过程。综合分析帕金森数据集和远程帕金森数据集,具有分类意义明确的前3 个特征分别为HNR、PPE 和DFA。其中,HNR 为语音信号的谐波信噪比,与发音颤抖、发音气息较重相关;PPE 为基音频率变化的非线性测量,反映了发音过程中的频率域变化;DFA 则从非线性动力学角度,对语音特征进行了噪声度量。三者均与发音的噪声部分相关,而这种噪声大多是由于发声时气流经过声带而产生。正常人在发声时,可以对该噪声进行抑制。由以上分析可以初步判断:在帕金森病的早期,由于运动机能受损,患者无法控制发声过程中的噪声,因此产生发音气息较重、音节颤抖等现象,而这些现象也正是基于语音障碍的帕金森病的临床典型症
状[11]。
2.3 与其他分类器比较
在与其他分类器分类精度的对比实验中,各分类器对帕金森数据集和远程帕金森数据集的分类精度如表2 所示。
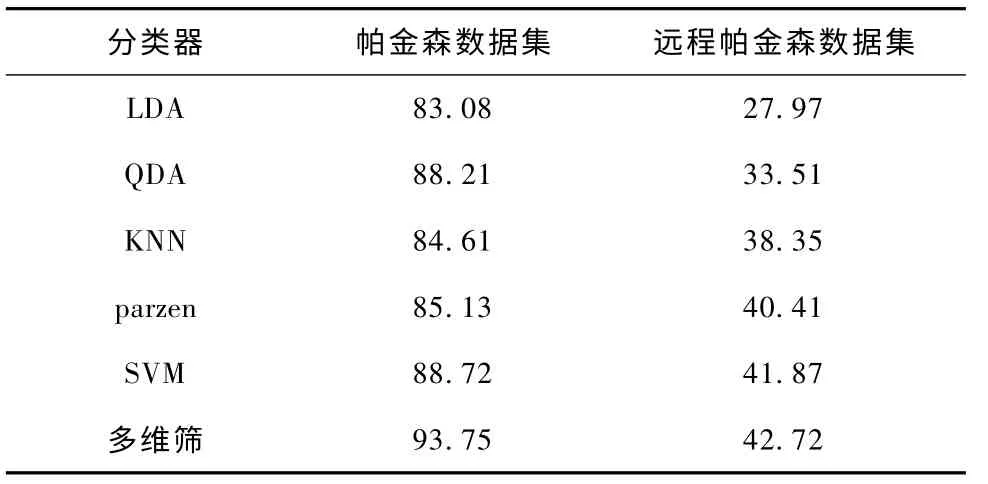
表2 不同分类器分类精度对比 %Tab.2 The comparison of precision (%)from different classifiers
由表2 可知,对于帕金森病这样的高维复杂数据,很难获得较高的分类精度。其中,以LDA 为代表的线性分类器由于其分类界面的线性约束,因此获得的分类精度最低;而对于以非线性为代表的QDA 分类器,在分类结果中精度较高,说明其模型与帕金森病数据分布模型基本符合,即帕金森病数据为典型的非线性分布数据;kNN 分类器基于测量的思想,寻求待分类样本与训练样本的最大相似性,但由于数据类别混叠严重,因此其分类效果一般;Parzen 窗分类器则是利用了空间窗口分析,仅考虑了窗口大小对分类结果的影响,可认为是多维筛的子集;SVM 作为统计学习理论和核方法的典型代表,其分类效果在传统分类器中可以达到最优,但仍低于多维筛方法5.03%。
该结果也充分说明,帕金森数据必须通过向高维的映射才可以做到更好的分类;而多维筛分类器在集成了SVM 的高维映射特性的同时,也具有非线性模糊分类器的典型特征。与经典分类器相比,多维筛分类器模型与帕金森病数据的模型更为吻合,因此获得了更高的分类精度。
3 结论
笔者分别对帕金森数据集与远程帕金森数据集两个国际公开的帕金森病语音障碍数据集进行了不同条件下的实验测试。首先,针对不同特征组合下的数据分布进行了可视化分析,验证了“并非所有特征组合都适合分类”的结论。其次,对不同量化阶下的数据精度进行了对比,发现的精度差别与类空间分布相关,且该相关可通过对类空间分布的直观观察获得,验证了可视化在分类过程中的作用,进而完成了特征选择过程并进行了特征分析。最后,通过与经典分类器的对比,验证了可视化模式识别在帕金森病可视化诊断中的优势。
通过实验,证明了基于语音障碍的帕金森病可视化诊断的可行性与功能特色,为可视化模式识别在疾病诊断中的进一步应用奠定了基础。
[1] Cho Chienwen,Chao Wenhung,Lin Shenghuang,et al. A vision-based analysis system for gait recognition in patients with Parkinson's disease [J]. Expert Systems with Applications,2009,36:7033 -7039.
[2] Dominique G,Pierre B,Christian L,et al. Auditory temporal processing in Parkinson's disease[J]. Neuropsychologia,2008,46:2326 -2335.
[3] 张涛,洪文学,常凤香,等. 基于元音分类度的帕金森病语音特征分析[J]. 中国生物医学工程学报,2011,30(3):476-480.
[4] Max AL,Patrick EM,Eric JH,et al. Suitability of dysphonia measurements for telemonitoring of Parkinson's disease [J].IEEE Transactions on Biomedical Engineering,2009,56(4):1015 -1022.
[5] Revett K, Gorunescu F, Salem AB. Feature selection in Parkinson's disease:a rough sets approach [C] //Barbara K,Waldemar P,eds. International Multiconference on Computer Science and Information Technology. Mragowo:IEEE Digital Library,2009:425 -428.
[6] Guo Peifang,Prabir B,Nawwaf K. Advances in detecting Parkinson's disease [J]. Lecture Notes in Computer Science,2010,6165:306 -314.
[7] Max AL,Patrick EM,Stephen JR,et al. Exploiting nonlinear recurrence and fractal scaling properties for voice disorder detection[J]. Biomed Eng Online,2007,6:23.
[8] Freddie A,Rasit K. A parallel neural network approach to prediction of Parkinson's disease [J]. Expert Systems with Applications,2011,38:12470 -12474.
[9] 张涛,洪文学. 基于计算几何的非线性可视化分类器设计[J]. 电子学报,2011,39(1):53 -58.
[10] 张涛,洪文学,李铭婷,等. 基于多维筛分类器的可视化帕金森病诊断. 燕山大学学报[J],2010,34(2):180 -184.
[11] 赵国华. 帕金森病的中西医结合治疗[M]. 北京:人民卫生出版社,2010:32 -50.
