指令集仿真器自动生成技术及其优化
2013-01-18孔黎刘静
孔黎,刘静
(西北工业大学 陕西 西安 710072)
ISS(指令集仿真器)可以让开发人员在硬件完成之前就能对系统的正确性进行验证,同时也能使应用开发人员对应用设计的正确性以及效果做出评估。
虽然ISS在芯片以及应用开发中有着不可代替的作用,但传统的手动编写的方法不仅需要花费大量的物力人力,效率低下,而且其正确性无法得到很好的保证。嵌入式芯片的更新换代越来越快,为了以更快地速度、更低的代价开发出可靠的ISS,自动生成技术就成为了必然选择[1]。
1 ISS自动生成技术概述
现行的自动生成技术有2种,即构件组装法和模板构造法。这2种方法都有自身的优势与不足,但相对于原先的手动开发无论从效率还是正确率上都有了很大的提升。
构件组装法是指将ISS的不同部件手工编写完成后,放入构件库,利用面向对象技术,在开发新产品的时候,将库中的构件组合连接起来,这样的方法其实并不是真正意义上的自动生成技术,而是一种半自动技术。在对于一些变化不大的部分,使用这种方法是很有效的,但是不同公司的不同版本的芯片之间的体系结构以及指令集都有很大的差距,因此并不是所有的部分都能复用。
模板构造法是通过一些接口语言,对指令集的特征进行描述,从而自动生成所需要的ISS。这类接口语言有LISA,nML等。这种方法是通过屏蔽平台差异的接口语言描述所需仿真平台的指令集体系结构(ISA),再经过自动生成工具产生仿真器部件。这种方法的效率很高,但灵活性不好。
在实际的研制过程中,都采用构件与模板构造相结合的方法。对于变动不大的部分,采用构件组合的方式,而对于变化非常大的部分则采用自动生成技术来实现部件的设计。
一般的解释型ISS[2]是由几个固定的模块组成的,取指,译码,路由,执行,其运行流程如图1所示。取指模块的作用是读取PC值,到相应的位置获取指令字,并将指令字传给译码模块;译码模块的作用是将指令字翻译成指令序号以及并获取操作数;路由模块的作用是根据译码的结构将操作数传给正确的执行函数;执行则是最后的完成指令功能的C函数。其中的译码模块以及执行模块是最为繁琐,最易出错的部分,ISS开发的大部分工作量都集中在这两个模块上。所以自动生成主要就是这两部分。

图1 仿真器执行流程Fig.1 Flow of the simulator
2 译码模块的自动生成策略
译码的过程实质上是识别指令字的过程。这一部件是相对独立的,它的输入是指令字,而输出则是指令标志(序号)以及操作数。任意一条指令都是由操作数以及操作码组成的,操作码的作用是唯一的确定某一条指令;而操作数则是包含在指令字中,表示指令操作对象的值,操作数一般包含源操作数和目标操作数。
DSP芯片一般采用的都是RISC指令集,其指令字的长度是固定的,这就为译码的工作带来了很大的便利。我们把指令字在屏蔽掉操作数之后的结果称为特征码,指令字与掩码进行按位与运算可以得到特征码。
译码的过程实际上是一个搜索匹配过程,在把指令字与掩码进行按位与运算后得到的数与指令特征码进行匹配确定指令字所代表的指令。一般的DSP芯片的指令集系统设计时会将所有的指令分为几大类,而每一类的指令操作码的位置是相同的,这样这一类指令在译码是所需要的掩码也就是一样的。以Tricore为例,Tricore的指令集中将790条指令分为25大类,而一共使用的掩码个数为18个。
在设计译码模块的时候,将特征码、掩码信息以及操作数位置的信息脱离出来,用配置文件表示,这样译码器就可以针对不同平台进行复用。在实现的过程中,抽象出一个opcoder类,其中包含了对配置文件进行分析的函数以及执行译码操作的函数,opcoder类的定义如下:

为了实现对指令字中操作数位置的描述,定义了一个操作数掩码:

而在配置文件中,指令的操作数掩码如下:
11110022223333334444555500000000
32位数字表示Tricore的指令字长为32位,其中为1的位表示第一个操作数,4个1表示第一个操作数占据了31~28位,2表示第二个操作数占据的位数。在配置文件读取的过程中,操作数掩码是以string形式读入,通过opcoder:init()函数填入operand_maskcode_struct结构体中。
opcoder类定义了针对指令掩码的vector存储掩码列表,对指令进行编号,将指令编号与指令特征码作为一个对存储在map中。在初始化的过程中,译码器从配置文件中获取相关信息并将这些信息分类存放在容器中,而在译码的时候则从掩码表中逐个进行按位与运算,进行匹配,直到找到为止。
这样的设计使译码模块具有很好的灵活性,可以进行复用。但由于强调了通用性,造成其译码效率较低。在实际的应用中,对于指令集仿真器,最受到关注的就是它的效率问题。实际上,效率低下是指令集仿真器一直以来的通病,这是显而易见的,对于一条机器指令需要用一个C函数进行仿真,C语言没一条语句都对应几条甚至几十条x86汇编语句。一般来说,指令集中一条语句对应1 000条左右的x86指令。
3 仿真函数库的自动生成策略
仿真函数库的作用是用高级语言(C/C++)描述指令集中的没一条指令。一般来说一个C函数代表一个DSP指令。
仿真函数的编写是整个仿真器中工作量最大的一部分,而且其中的重复工作很多,而且极易出错,后期的测试也会花费大量的时间来验证这一部分的正确性。因此,对这一部分的自动化生成有强烈的需求。由于指令集结构(ISA)差异巨大,因此无法使用构件组合法。在一般的开发中,每一款DSP都要重新为其手动编写仿真函数库。在本仿真器的设计中,使用了模板法自动生成函数库,选取nML语言作为描述指令的接口语言[3]。
nML的语法是一个上下文无关的语法,通常一个上下文无关的语法可以用一个四元组来表示,G=(N,T,P,S),其中N表示非终止符,T表示终止符,P表示生成规则,S表示起始符[4]。
nML语言对ISA的描述是由各种规则组成的,而在nML中有2种生成准则:
1)OR-rules列出了一个指令部分的所有可选项。
2)AND-rules描述了指令各部分的组成。
使用nML语言自动生成需要对DSP的数据类型、主存、寄存器、指令进行描述[5]。
指令集仿真器自动生成器主要由两部分组成,即前端和后端。前端是以nML描述语言描述的模板作为输入,因此,其任务就是识别nML语言的规则,将用户描述的各种指令以及定义的寄存器等信息收集起来,并存储到相应的数据结构之中。这一部分由两个过程组成,即词法分析和语法分析。词法分析的主要任务是识别nML文件中的各个单词,并将这些单词转换成内部记号(tokens)表示;语法分析的主要任务是识别nML语言的语法结构,如“与”规则,“或”规则,以及寄存器定义等等,并将这些信息全部记录到预先设计好的各种表格中,这是一个信息收集的过程。信息收集完毕后,我们将这些信息保存到文件中,以便后端使用。
后端的主要工作首先是从中间文件中读取数据,将前端收集到的各种信息还原,然后就是对这些信息进行处理,主要包括:①“或”规则的去除;②将“与”规则根据其action属性转换成相应的指令解释程序,并生成唯一的指令名;③根据每条指令的image属性来构造译码表;④初始化代码的生成。最后,将处理好的信息按照C语言的格式输出到外部文件中。
这里之所以使用前端和后端两部分来构成自动生成器,就是为了达到松散偶合的目的,即前后端的工作都相对独立,这样自动生成器的可移植性就会更好[6]。
4 ISS的优化
自动生成ISS的有点十分明显,减少工作量,提高了正确性,但是缺点也是十分突出的,那就是无法根据不同DSP的ISA特性来对仿真器进行优化。
通过实验可以发现,ISS工作时,主要的时间开销是在译码上,实验结构表明译码的时间大约是执行时间的3.7倍,因此优化主要是在译码模块进行的。
4.1 搜索算法的优化
首先,在译码的过程中,显然时间主要花在搜索匹配上。最简单的设计就是用顺序搜索的算法,逐一与掩码进行按位与运算,为了提高效率,使用hash表的方法。DSP芯片的指令中都包含操作码(op),这些操作码代表了这条指令的意义,同一类型的指令往往其op1是相同的,所以,我们选取op1作为哈希函数的Key值,哈希函数即为H(Key)=Key。Tricore中一共有790条指令,op1的长度为8位,因此哈希表的入口有256个,理论上平均搜索长度为3左右。在实际中,指令的op1并不是在0-255上均匀分布的,所以平均搜索长度会高于3,经过统计之后发现,平均搜索长度约为5左右。
在自动生成过程中,添加一个配置项,该配置项为指令的op1(或者op)的起始位和结束位,在Tricore中这两个数字为0和7。在获得op1的位置后,译码模块会根据其位置以及长度建立相应的hash表。
根据这种方法,声明哈希表中项的结构:

在class opcoder中加入项:
int init_hash();//初始化哈希表的函数
unsigned int op_mask;//获取指令op1所需要的掩码
unsigned int hash_entry_num//哈希表入口的数量,通过op1的长度来确定
vector
通过测试,可以发现哈希表的搜索速度相对于顺序执行提高了3倍左右,两者的测试比较如图2所示。其中横轴是指令的数量,纵轴是运行这些指令所需的时间,单位是秒。
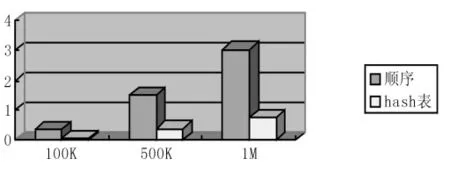
图2 搜索效率比较Fig.2 Compare of the searching
4.2 动态预译码策略
所谓预译码[6],就是在指令执行之前对整个可执行文件中的指令进行预译码,并把译码结果代替原来内存位置中装载的指令。在程序的执行过程中,大部分时间都是花在循环上,而在循环中,所执行的指令是相同的,因此如果反复地对相同的指令进行译码就会造成大量资源的浪费。经过预译码的处理之后,ISS执行的时间大大缩短。但有的大型程序有很多分支路径,而在实际的运行中,执行路径很短,这样预译码也会造成大量的浪费。为了解决这个问题,可以采取动态的指令缓存的方法。即在执行的过程中查找缓存中是否有结果,如果没有则进行译码,有就直接执行。使用动态预译码效率与原始效率对比如图3所示,横轴表示循环次数,纵轴是时间,单位是秒。

图3 预译码效率比较Fig.3 Predecoding efficiency comparison
在自动生成译码模块的过程中,在class opcoder中添加指令缓存项,改写译码函数。用一个与可执行文件中指令段的大小相同的数组来表示指令缓存,译码结果存储在结构体中,而缓存中只记录这些结构体的地址。
5 结 论
通过结合构件法与模板构造法,能够快速而高效地生成一款DSP芯片的指令集仿真器,通过对其译码模块的优化,能够大大提高ISS的性能,从而达到实际的使用要求。
[1]王小红.指令集仿真器快速生成环境的研究与实现[D].北京:北京航空航天大学,2001.
[2]俞甲子,石凡,潘爱民,等.程序员的自我修养[M].北京:电子工业出版社,2009.
[3]Nohl A.A universal technique for fast and flexible instructionset architecture simulation[M].DAC,2002.
[4]陶峰峰,付宇卓.DSP指令集仿真器的设与实现[J].计算机仿真,2005,22(9):225-228.TAO Feng-feng,FU Yu-zhuo.Design and implementation of DSP instruction simulator[J].Computer Simulation,2005,22(9):225-228.
[5]Freericks M.The nML machine description formalism[M].Berlin Tech.Rep.TU Berlin, Fachbereich Informatik,1991.
[6]刘竞楠.基于nML的指令集仿真器自动生成技术初步研究[D].北京:华北电力大学,2008.
