Gaussian mixture model clustering with completed likelihood minimum message length criterion
2013-01-08ZengHongLuWeiSongAiguo
Zeng HongLu WeiSong Aiguo
(1 School of Instrument Science and Engineering, Southeast University, Nanjing 210096, China)(2 College of Engineering, Nanjing Agricultural University, Nanjing 210031, China)
The Gaussian mixture model (GMM) is commonly used as a basis for cluster analysis[1-2]. In general, the GMM-based clustering involves two problems. One is the estimation of parameters for the mixture models. The other is the model order selection for determining the number of components. The expectation-maximization (EM) algorithm is often used to estimate the parameters of the mixture model which fits the observed data. Popular model selection criteria in the literature include the Bayesian information criterion (BIC), Akaike’s information criterion (AIC), the integrated likelihood criterion (ILC), etc.
However, most previous studies generally assume the Gaussian components for the observed data in the mixture model. If the true model is not in the family of the assumed ones, the BIC criterion tends to overestimate the correct model size regardless of the separation of the components. In the meantime, because the EM algorithm is a local method, it is prone to falling into poor local optima in such a case, leading to meaningless estimation. In order to approximate such a distribution more accurately, the feature weighted GMM, which explicitly takes the non-Gaussian distribution into account, is adopted in Refs.[3-8]. Nevertheless, the approaches in Refs.[3-8] assume that the data features are independent, which is often not the case for real applications. Based on the minimum message length (MML) criterion, Ref.[9] proposed an improved EM algorithm that can effectively avoid poor local optima. But we find that it still tends to select much more Gaussian components than necessary for fitting the data with uniform distribution, giving obscure evidence for the clustering structure of data.
We propose a novel method to address the model selection and parameter estimation problems in the GMM-based clustering method when the true data distribution is against the assumed one. In particular, we derive an improved model selection criterion for mixture models with an explicit objective of clustering. Furthermore, with the proposed criterion as the cost function, an improved EM algorithm is developed for estimating parameters. Ultimately, the proposed method is not only able to rectify the over-fitting tendency of some representative model selection criteria, but also able to avoid poor local optima of the EM algorithm.
1 Completed Likelihood of the Gaussian Mixture Model
Suppose that aD-dimensional sample follows aK-component mixture distribution, then the probability density function ofycan be written as
(1)
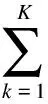
(2)
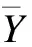
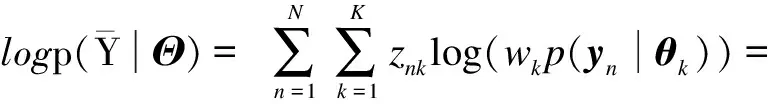
logp(Y|Θ)+logp(Z|Y,Θ)=

(3)
wherepnkis the conditional probability ofynbelonging to thek-th component and can be computed as
(4)
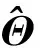
(5)
where
(6)
2 Clustering with Completed Likelihood Minimum Message Length(CL-MML) Criterion
2.1 Completed likelihood minimum message length cri-terion

(7)
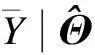
(8)

(9)

2.2 Estimation of GMM parameters
For the GMM, each component follows the Gaussian distribution, i.e.,p(y|θk)=G(y|μk,Σk), whereμkandΣkare the mean and the covariance matrix of thek-th Gaussian components. For a fixed model orderK, we estimate the GMM parametersΘby an improved EM algorithm, with CL-MML in Eq.(9) as the cost function. The proposed EM algorithm alternatively applies the following two steps in thet-th iteration until convergence:
E-step: Compute the conditional expectation:
(10)
M-step: Update the parameters of the GMM by
(11)
(12)
(13)
3 Experiments
We present experimental results to illustrate the effectiveness of CL-MML for GMM-based clustering (denoted as GMM+CL-MML), compared to that of BIC (denoted as GMM+BIC), MML (denoted as GMM+MML), as well as the method utilizing the feature-weighted GMM and the integrated likelihood criterion (FWGMM+ILC) for clustering[3].
3.1 Synthetic data
We consider a synthetic 2D data set where data from each cluster follow the uniform random distribution:
ur(y1,y2)=

wherer={r1,r2,r3,r4} are the parameters of the distribution. 1000 data points are generated using a 5-component uniform mixture model. Its parameters are as follows:
w1=0.1,w2=w4=w5=0.2,w3=0.3
r1={-1.89, 4.07, 4.89, 7.94}
r2={1.11, 5.11, 2.47, 3.53}
r3={5.17, 6.53, 2.77, 5.77}
r4={4.31, 6.49, 6.29, 6.71}
r5={5.58, 8.42,-0.77, 2.23}
The Gaussian components are adopted to fit such a uniform mixture data set, for which the true distribution models are very different from the assumed ones. The models with the number of componentsKvarying from 1 toKmax, a number that is considered to be safely larger than the true number (i.e., 5), are evaluated.Kmaxis set to be 30 in this case. We evaluate these methods by the accuracy in estimating the model order and structure. Tab.1 illustrates the number of times that each order is selected over 50 trials. Fig.1 shows typical clustering results by these four methods.
It can be observed that for such a data set, the GMM+BIC approach not only fails to yield a good estimation of model order (see Tab.1), but also leads to a meaningless mixture model by the standard EM (see Fig.1(a)). Although the MML criterion generates a GMM which fits the data well, it suffers from severe over-fitting as shown in Fig.1(b) and Tab.1. Since the features are assumed to be independent in FWGMM, it also tends to select more components in order to approximate the distribution of data accurately (see Fig.1(c) and Tab.1).

Tab.1 Number of times for selected model orders over 50trials on synthetic data
In contrast, due to the introduction of an extra penalty to the MML criterion, the proposed CL-MML criterion-based GMM clustering favors much fewer but more “powerful” components which successfully detect the clusters. The clustering result in a typical successful trial of CL-MML is shown in Fig.1(d).

Fig.1 Typical clustering results of different methods on the synthetic data.(a) GMM+BIC;(b) GMM+MML;(c) FWGMM+ILC;(d) GMM+CL-MML
3.2 Real data
We also measure performance on four real-world data sets from the UCI repository. The number of classes, the number of samples and the dimensionality of each data set are summarized in Tab.2. For each data set, we randomly split the data 50 times into training and test sets. Training sets are created from 50% of the overall data points. We do not use any label in the training stage.Kmaxis still set to be 30. After model learning, we label each component by majority vote using the class labels provided for the test data, and we measure the test set classification accuracy as the matching degree between such obtained labels and the original true labels. The means and the standard deviations of the classification accuracy, as well as the number of components for each data set, over 50 trials are summarized in Tab.2. The best results are marked in bold.

Tab.2 Comparison of different clustering approaches on real data sets
Several trends are apparent. First, the numbers of components determined by the proposed method are generally less than those by the compared counterparts. This may be due to the reason that the distribution of a real data set often does not strictly follow the Gaussian mixture model, and most GMM-based clustering approaches tend to generate more components than necessary in order to better fit the data. However, it is found that the CL-MML can rectify the over-fitting tendency of the compared methods under such circumstances. This can be explained by the reason that it takes the separation among components into account. Secondly, the proposed method yields the most accurate results among all the approaches on these four data sets. This justifies that the proposed approach can estimate the GMM parameters more properly than the compared ones.
4 Conclusion
In this paper, by taking the capability of the candidate GMM to provide a relevant partition to the data into account, an improved GMM-based clustering approach is developed for the difficult scenario where the true distribution of data is against the assumed GMM. The experimental results show that the proposed method is not only able to rectify the over-fitting tendency of the compared methods for performing the model selection, but also able to obtain higher clustering accuracy compared to the existing methods.
[1]Zeng H, Cheung Y M. Feature selection and kernel learning for local learning based clustering [J].IEEETransactionsonPatternAnalysisandMachineIntelligence, 2011,33(8):1532-1547.
[2]Jain A K. Data clustering: 50 years beyondK-means [J].PatternRecognitionLetters, 2010,31(8):651-666.
[3]Bouguila N, Almakadmeh K, Boutemedjet S. A finite mixture model for simultaneous high-dimensional clustering, localized feature selection and outlier rejection [J].ExpertSystemswithApplications, 2012,39(7): 6641-6656.
[4]Law M H C, Figueiredo M A T, Jain A K. Simultaneous feature selection and clustering using mixture models [J].IEEETransactionsonPatternAnalysisandMachineIntelligence, 2004,26(9):1154-1166.
[5]Markley S C, Miller D J. Joint parsimonious modeling and model order selection for multivariate Gaussian mixtures [J].IEEEJournalofSelectedTopicsinSignalProcessing, 2010,4(3):548-559.
[6]Li Y, Dong M, Hua J. Localized feature selection for clustering [J].PatternRecognitionLetters, 2008,29(1):10-18.
[7]Allili M S, Ziou D, Bouguila N, et al. Image and video segmentation by combining unsupervised generalized Gaussian mixture modeling and feature selection [J].IEEETransactionsonCircuitsandSystemsforVideoTechnology, 2010,20(10):1373-1377.
[8]Fan W, Bouguila N, Ziou D, Unsupervised hybrid feature extraction selection for high-dimensional non-Gaussian data clustering with variational inference [J].IEEETransactionsonKnowledgeandDataEngineering,2012, in press.
[9]Figueiredo M A F, Jain A K. Unsupervised learning of finite mixture models [J].IEEETransactionsonPatternAnalysisandMachineIntelligence, 2002,24(3): 381-396.
[10]Wallace C S, Dowe D L. MML clustering of multi-state, Poisson, von Mises circular and Gaussian distributions [J].StatisticsandComputing, 2000,10(1): 73-83.
杂志排行

Journal of Southeast University(English Edition)的其它文章
- Uplink capacity analysis of single-user SA-MIMO system
- A broad-band sub-harmonic mixer for W-band applications
- Feature combination via importance-inhibition analysis
- Transmission cable fault detector based on waveform reconstruction
- Force measurement between mica surfaces in electrolyte solutions
- Flexural behaviors of double-reinforced ECC beams