森林蓄积量调查数据空间化的方法研究
2013-01-05廖顺宝许立民
廖顺宝,许立民
(1.河南大学 环境与规划学院,河南 开封 475004;2.中国科学院 地理科学与资源研究所,北京 100101)
森林蓄积量调查数据空间化的方法研究
廖顺宝1,2,许立民1
(1.河南大学 环境与规划学院,河南 开封 475004;2.中国科学院 地理科学与资源研究所,北京 100101)
森林是陆地生态系统的重要组成部分,蓄积量是森林资源调查的基本指标之一。传统的森林蓄积量调查数据一般以行政单元为记录进行表示,因此,难以在更细尺度上反映蓄积量的空间分布及其变化。以20世纪80年代全国森林资源清查数据为例,在国家和省区两个尺度分别分析森林蓄积量与不同土地利用类型面积和不同土地覆被类型面积之间的关系。结果显示:不论在国家尺度还是省区尺度,森林蓄积量与土地覆被类型的相关性(国家尺度R2=0.568 2;省区尺度R2=0.851 1)均优于其与土地利用类型的相关性(国家尺度R2=0.528 3;省区尺度R2=0.775 4),而且分省区模型优于全国整体模型;在此基础上,基于蓄积量与不同森林类型面积之间的线性回归模型,利用回归计算结果与残差修正相结合的方法,计算得到全国 1 km×1 km分辨率的森林蓄积量空间化产品,该产品既反映了公里网格尺度上蓄积量的空间变化,又可以利用该产品统计全国及省区、市县的森林蓄积总量;根据本研究的空间化结果进一步计算得到,20世纪80年代全国森林蓄积总量为1.348 6×1010m3。
森林;蓄积量;调查数据;数据空间化
森林是地球上最大的有机碳的贮库,是控制陆地生物圈能量传输的重要组成部分。陆地上,森林面积约占地球非冰表面的40%,而森林生物量却占整个陆地生态系统生物量的90%左右,其土壤碳储量约占全球土壤碳储量的73%[1-2]。森林生物量不仅是森林固碳能力的重要标志,也是评估森林碳收支的重要参数,对全球碳循环起着重要作用[3]。因此,森林生物量的定量测算是生态学及相关领域的重要研究问题,在全球气候变化背景下开展森林生物量的数量、时空分布和动态变化研究具有重要的理论意义及实践价值[4]。
森林生物量是指单位面积森林内生物群落的现存量,常用t/hm2表示,它包括林木的生物量(根、茎、叶、花、果、种子和凋落物等的总重量)和林下植被层的生物量。另一个反映森林资源的丰富程度、衡量森林生态环境优劣的重要指标是林木蓄积量,它是指一定森林面积上存在着的林木树干部分的总材积。蓄积量是反映一个国家或地区森林资源总规模和水平的基本指标之一。而且,森林生物量与林木蓄积量在一定的条件下可以通过模型进行转换[5],换而言之,当知道一个地区的林木蓄积量时,就可以推算出该地区的森林生物量。
关于森林蓄积量的估算,目前主要有两种途径。一是以遥感信息源为主,辅之以其他相关数据进行蓄积量的估算。例如,基于ALOS PALSAR和森林资源二类清查固定样地数据,利用非线性回归方法建立蓄积量与所对应的 PALSAR像元后向散射系数之间的关系[6];利用Landsat TM数据和人工神经网络方法研究中红外波段与森林蓄积量之间的负相关关系[7];以TM可提取因子(不同波段比值或线性组合)及样地林分立地条件因子为可选变量,通过逐步回归构建马尾松林分蓄积量估测模型[8];蓄积量与平均冠幅、海拔、坡位、坡向、QuickBird Band1-4以及NDGI(归一化绿度指数)、GI(绿度指数) 等因子之间的回归拟合[9];利用CBERS-02B 影像为数据源, 同时提取海拔、 坡度、坡向等GIS因子,运用偏最小二乘法建立森林蓄积量估测模型[10];以郁闭度、阴坡、阳坡、TM1、TM2、TM3、TM5、TM7、NDVI、TM(4-3)、TM4/3 为输入变量,建立蓄积量估测的神经网络模型[11];以 CBERS/CCD 影像和同步实测样地数据为基础,构建基于 NDVI、RVI及NDVI和RVI组合的人工速生林地蓄积量回归估测模型[12],等等。利用遥感信息进行森林蓄积量的估算主要在林场或小区域尺度上开展工作,目前尚未见到利用遥感信息在大范围内进行森林蓄积量估算的文献。
第二种途径是以微观地理因子以及森林本身的参数为变量,构建蓄积量与这些变量之间的相关关系,从而进行蓄积量的测算。例如,以林分断面积和平均树高为自变量,以林分蓄积量为因变量,构建杉木、马尾松和阔叶树等不同树种的蓄积量模型[13];利用林木采伐伐区设计资料及蓄积表,以海拔、年龄、郁闭度、坡向、坡度、坡位、林分起源等因子为解释变量进行多元线性回归,建立马尾松、 黄山松、 杉木纯林等的蓄积量数学模型[14];桤木人工林蓄积量与密度、平均高度之间的非线性相关关系模型[15];通过建立杉木人工林广义干曲线模型模拟不同立地、 不同密度、不同年龄杉木人工林单株材积和林分蓄积量[16],等等。通过这类途径进行蓄积量的估算也主要在林场甚至是样地尺度上开展,一般比利用遥感信息进行蓄积量估算的区域范围更小,因此仍然是局地性质的研究。
当前,进行生物量空间分布估算的研究,特别是在较大范围(如省区、全国)的研究还不多见。2004年,朴世龙等[17]利用中国草地资源清查资料,并结合同期的遥感影像,建立了基于修正的归一化植被指数( NDVI )的我国草地植被生物量估测模型,并利用该模型研究了我国草地植被生物量及其空间分布;2011年,彭守璋等[18]根据祁连山地区野外调查资料、青海云杉林相图和气象资料,在GIS技术的支持下估算了祁连山地区青海云杉林的生物量和碳储量及其空间分布;2012年,刘双娜等[19]以中国第六次国家森林资源清查资料为基础,同时结合1∶100万植被分布图及同期基于MODIS反演的NPP空间分布,定量估算了1 km分辨率下全国森林生物量的空间分布。而进行大范围森林蓄积量空间分布的研究,尚未见到相关研究。
本文基于全国县级森林资源调查数据和同时期的土地利用/土地覆被数据,根据属性数据空间化的思路和方法,将基于县级行政单元的森林蓄积量调查数据重新分布到规则格网上,以实现森林蓄积量调查数据的空间化。空间化结果是进行全国森林生态系统以及森林资源研究与评价的基础数据产品。所谓属性数据空间化,是指将地学矢量目标(点、多边形)中的属性要素向同要素栅格目标转化的过程。通过属性数据空间化,一方面可以增加属性要素在空间分布上的信息量,尽可能地反映该要素在空间上的实际分布状况;另一方面,又可以改变数据的存储格式,即从不规则的矢量结构(点、多边形)转变成规则网格,以便进行跨学科的综合分析[20]。从定义可以看出,属性数据空间化不是简单的矢量数据栅格化。
最近10年以来,属性数据空间化已经成为地理学、生态学、环境科学、社会科学中的研究热点,其主要内容包括自然要素的空间化和社会经济要素的空间化,如气象观测要素的空间化[21-25]、人口统计数据空间化[26-29]、国民经济各行业产值数据的空间化[30]等。
1 数据资料
本研究使用的数据资料主要包括森林蓄积量调查数据、土地利用/土地覆被数据和全国县级行政区划数据等三部分,具体情况说明如下:
(1)全国各省、自治区、直辖市分县森林蓄积量调查数据(1980 s):来源于各省区森林资源清查,包括除香港、澳门和台湾以外的全国31个省级行政单元的数据,各省区调查的时间不尽相同,但基本上都集中在20世纪80年代,核心数据指标是县级行政单元的活立木总蓄积量。
(2)全国公里网格土地利用/土地覆被数据:分别来源于中国科学院资源环境科学数据中心和国家科技基础条件平台——地球系统科学数据共享网。这两种数据分别利用与蓄积量调查数据时间基本一致的全国1∶10万土地利用数据和全国1∶25万土地覆被数据加工形成。需要说明的是,该公里网格数据产品不是将某一栅格单元全部表示成某一种特定的土地利用/土地覆被类型,而是详细记录每个栅格单元中不同土地利用/土地覆被类型占整个栅格单元面积的比例,因此特别适合用作属性数据空间化的参数。该产品是目前我国在国家尺度上精度最高的土地利用/土地覆被数据产品,已经在国家土地资源调查、水文、生态研究中被广泛应用。
全国1∶10万土地利用数据将全国土地利用类型分为耕地、林地、草地、水域、工矿居民用地和未利用土地等6个一级类25个二级类,其中,林地又分为有林地、灌木林、疏林地、其他林地等4个二级类型;全国1∶25万土地覆被数据将全国土地覆被类型分为森林、草地、农田、聚落、湿地水体、荒漠等6个一级类25个二级类,其中,森林又分为常绿针叶林、常绿阔叶林、落叶针叶林、落叶阔叶林、针阔混交林和灌丛等6个二级类型。不论是土地利用数据还是土地覆被数据,本研究只用其中与森林蓄积量有关的数据,即仅分别使用土地利用中的“林地”数据和土地覆被中的“森林”数据。因为森林蓄积量仅与它们相关。
(3)全国县级行政区划数据:即与森林蓄积量调查数据和土地利用/土地覆被数据时间接近的全国县级行政区划数据,包括县级行政区划图(边界)、行政区名称和行政区划代码。
2 数据预处理
数据预处理的目的是为数据分析与建模进行数据准备,主要包括以下三项内容:
(1)统计各市县不同林地类型/森林类型的面积。首先,在地理信息系统软件ArcGIS中将全国县级行政区划的多边形矢量数据转换为栅格数据,用县级行政区划代码作为栅格单元的属性值;其次,用县级行政区划栅格数据对不同林地类型/森林类型的栅格图层进行区域统计,得到每个区域(市县单元)内不同林地类型/森林类型的面积,即得到一个包括市县名称、市县代码、不同林地类型面积(有林地、灌木林、疏林地、其他林地)、不同森林类型面积(常绿针叶林、常绿阔叶林、落叶针叶林、落叶阔叶林、针阔混交林、灌丛)等信息的二维属性表。
(2)对各市县森林蓄积量调查数据与林地/森林面积数据进行匹配。根据市县名称和市县代码一致的原则,将各市县的森林蓄积量调查数据匹配到上一步形成的二维表中。由于全国县级行政区划的变动(县改市、县改区、市县合并与拆分等),有些名称一致或代码一致的市县并不表示同一个区域,因此需要甄别每个市县的确切含义。
首先根据名称和代码同时一致的原则进行匹配;其次根据名称一致(这种情况只包括县,不含变为市的县)的原则匹配;第三,删除名称、代码均不一致的记录,特别是县级市升格为地级市,原来的县级市成为新的地级市的市辖区的情况。需要说明的是,这种删除对后续的数据分析没有影响,因为各市县的数据主要用于分析和建模,因此不需要全部市县的数据。事实上,通过匹配和删除不匹配的数据后,全国仍然保留了2 175条记录。
(3)生成省级行政区划栅格数据。对全国县级行政区划栅格数据进行类型归并,生成全国省级行政区划栅格数据,用省级行政区划代码作为栅格单元的属性值。在利用分区模型计算蓄积量时,该栅格数据将作为模型选择的控制参数。
3 数据分析与建模
3.1 数据总体分析
森林蓄积量是一定森林面积上存在的林木树干部分的总材积,因此,有森林或林地的地方才会有森林蓄积量(也称林木蓄积量)。森林描述的是地表土地覆被状况,林地描述的是地表土地利用状况,它们均与森林蓄积量有关。
以全国各市县森林蓄积量为因变量,不同森林类型(常绿针叶林、常绿阔叶林、落叶针叶林、落叶阔叶林、针阔混交林、灌丛)面积或不同林地类型(有林地、灌木林、疏林地、其他林地)面积为自变量,分别进行多元线性回归分析,令常数项为0,得到的线性回归方程分别为:

式中:y 表示森林蓄积量,104m3;c1、c2、c3、c4、c5、c6分别表示不同森林类型的面积,km2;u1、u2、u3、u4分别表示不同林地类型的面积,km2。
图1、图2分别表示根据方程(1)和方程(2)预测的森林蓄积量与实际调查的蓄积量之间的相关关系。从图1、图2可以看出,蓄积量不论是与土地覆被中的不同森林类型面积还是与土地利用中不同林地类型的面积,均已达到统计上的显著相关。尽管如此,利用这2个方程来预测各市县的蓄积量仍然存在比较大的问题,因为它们的平均相对误差分别到达86.29%和86.07%。平均相对误差的计算公式为:

式(3)中:e表示平均相对误差(无量纲);abs()表示求绝对值;n表示参与回归分析的样本(市县)个数;a0i表示第i个样本(市县)的实际调查蓄积量,104m3;a1i表示通过回归方程预测的第i个市县的蓄积量,104m3;a0表示所有n个市县调查蓄积量的总和,104m3。
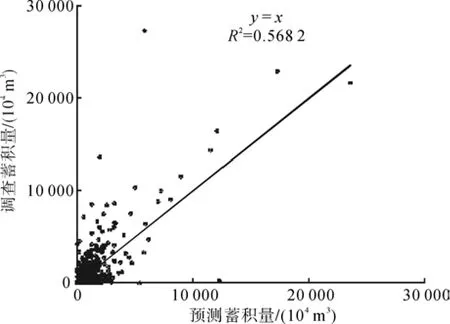
图1 根据不同森林类型面积预测的蓄积量与实际调查蓄积量之间的相关关系(全国统一模型)Fig.1 Relationship between actual and predicted total accumulation of live timber by area of different forest types (unified national model)
从图1和图2也可以明显的看出,分析样本主要集中在蓄积量比较低的区域,而且这个区域的散点图非常发散。因此,在全国范围内构建一个统一的蓄积量模型是不科学的,在实际应用中也是不准确的。分区建模是解决这一问题的有效手段。
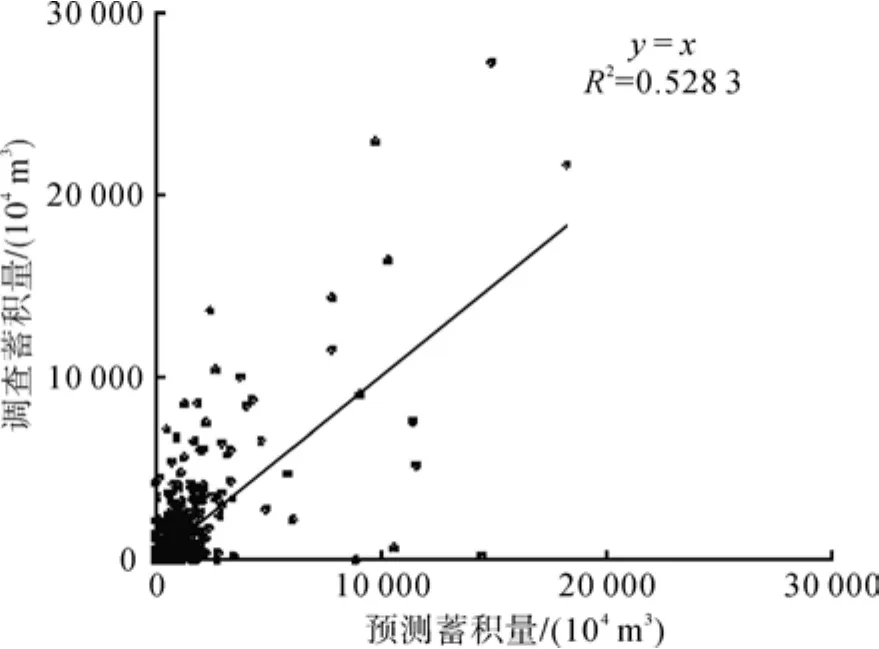
图2 根据不同林地类型面积预测的蓄积量与实际调查蓄积量之间的相关关系(全国统一模型)Fig.2 The relationship between actual and predicted total accumulation of live timber by area of different forest-land types (unified national model)
3.2 分区建模
由于地形、地貌、土壤以及水热等自然条件的差异,在不同区域,森林蓄积量与各种土地覆被/土地利用类型面积之间的关系也不尽相同。本研究使用的蓄积量数据以行政区划为记录单元,因此,分区建模也以省级行政区划界线作为分区的界线。用对全国数据进行总体分析一样的方法对各省区的数据进行分析,结果列于表1。从表1不难看出,按省分区以后,不论是基于森林类型(土地覆被)还是基于林地类型(土地利用)的回归方程,相关系数和样本的平均相对误差都有明显的改进。平均相对误差已经从86.29%和86.07%分别下降到46.82%和50.07%,全国各市县预测蓄积量与实际调查蓄积量的相关系数(R2)从0.568 2和0.528 3分别上升到0.851 1和0.775 4(见图3、图4),且绝大部分省区的相关系数明显提高。与图1和图2相比较,图3和图4明显地反映出了这种改进。
根据上述分析可以得到这样的结论,不同森林类型(土地覆被)、不同林地类型(土地利用)的面积分布情况均能较好地反映一个区域的森林蓄积量。但从相关系数、平均相对误差(见表1)以及模型预测蓄积量与调查蓄积量之间的分布情况(见图3、图4)看,根据森林类型建立的蓄积量估算模型比根据林地类型建立的蓄积量估算模型的总体效果要好。因此,本文中利用前者进行蓄积量调查数据的空间化。

表1 各省区森林蓄积量与土地利用/土地覆被的相关性及平均相对误差Table 1 Correlation coefficients and average relative errors between total accumulation of live timber and landuse or landcover by province
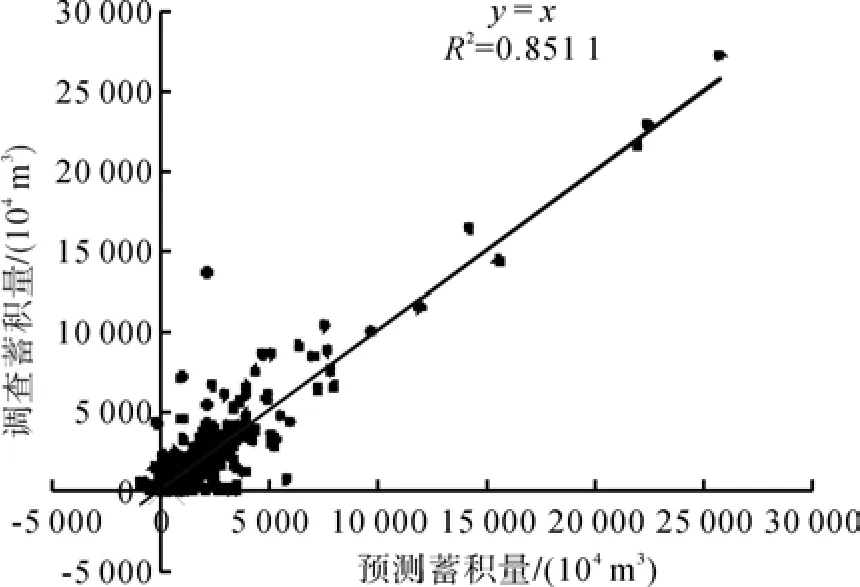
图3 根据不同森林类型面积预测的蓄积量与调查蓄积量之间的相关关系(分区模型)Fig.3 Relationship between actual and predicted total accumulation of live timber by area of different forest types ( provincial models)
4 蓄积量调查数据空间化
全国森林蓄积量调查数据的空间化由模型计算和残差修正两步完成。
4.1 模型计算
(1)土地覆被参数提取。全国1∶25万土地覆被数据分为6个一级类25个二级类,因此,基于1∶25万土地覆被数据生成的全国公里网格产品由25个栅格图层组成,每个栅格图层表示一种二级土地覆被类型,栅格单元的属性值表示该二级土地覆被类型面积占整个栅格单元面积的比例。因此,理论上讲,对于同一个地表栅格单元,可能会同时包括这25个土地覆被二级类型,如果将25个栅格图层求算术和,则每个栅格单元的属性值之和为100%。

图4 根据不同林地类型面积预测的蓄积量与调查蓄积量之间的相关关系(分区模型)Fig.4 Relationship between actual and predicted total accumulation of live timber by area of different timberland types ( provincial models)
森林蓄积量只可能分布在有森林的地方,不可能分布在非森林的土地覆被类型中。因此,在进行蓄积量计算时,只需从25个图层中选择属于森林类型的6个二级森林类型(即常绿针叶林、常绿阔叶林、落叶针叶林、落叶阔叶林、针阔混交林和灌丛)作为输入参数,而不必使用全部25个数据层。
(2)蓄积量计算。在地理信息系统软件ArcGIS中,以6个二级森林类型图层数据作为输入参数,以省级行政区划栅格数据作为模型选择的控制参数,利用3.2节所建立的分区模型逐个栅格计算森林蓄积量。结果如图5所示。

图5 根据分区模型计算的全国森林蓄积量分布Fig.5 Distribution of total accumulation of live timber in China by provincial models
4.2 残差修正
根据图3不难发现,几乎所有通过计算得到的蓄积量与实际调查的蓄积量都不相等(即不在1∶1线上,这在统计上也是很正常的),它们之间存在残差。虽然各分区模型在总体上较好地反映了全国森林蓄积量与各森林类型面积之间的关系,但如果直接用这些模型的计算结果作为最终的空间化结果,则可能与实际情况有较大的出入,有些栅格上的值甚至为负数(见图5)。因此,必须对模型的计算结果进行修正。
修正的基本思路是将模型计算结果与残差求和。因为在统计上,回归方程的预测值与残差相加正好等于样本的实际观测值。不过,这里存在三个问题:(1)模型计算是逐个栅格进行的,理论上,模型计算得到的每个栅格的值都是不一样的。而残差针对的是每个县级行政单元(因为模型是基于县级行政单元构建),虽然可以把每个县级行政单元的残差平均分配到该县级行政单元的每一个栅格单元上,但这种平均分配的依据并不充分,因为不能把残差分配到没有森林分布的栅格单元上。(2)如果将残差平均分配到县级行政单元的每个栅格单元上,在相邻县级行政单元的边界,残差可能会出现阶梯状突变;(3)在数据预处理阶段,因行政区名称或代码不匹配去掉了一些行政单元,这些行政单元未能作为样本参与建模,因此不存在残差。
解决上述问题的方法是将残差仅仅分配到有森林类型分布的栅格单元上,且以森林占栅格单元面积的比例为权重进行分配。具体处理方法是:
(1)统计各市县各森林总面积(Ai);
(2)用各市县残差除以该市县森林类型总面积(Ai),得到该市县单位森林面积的残差(Ri);
(3)以Ri为栅格化的属性代码,对县级行政区划多边形数据进行栅格化,形成以市县为单元的残差系数栅格图(GridRi)。因台湾、香港、澳门无调查数据,残差修正系数均设为0,即不进行残差修正。
(4)对各二级森林类型栅格图求算术和,得到每个栅格单元上不同森林类型的总面积(GridF);
(5)用GridRi乘以GridF,得到所有有森林分布的栅格单元上的残差(无森林分布的栅格单元上的残差为0),结果如图6所示。
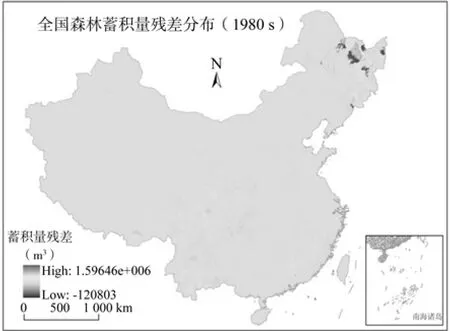
图6 全国森林蓄积量残差分布Fig.6 Distribution of residuals of total accumulation of live timber in China
将分区模型的计算结果(见图5)与处理后的残差(见图6)求和,并将蓄积量为负数的栅格的值设为0。另外,根据相关资料,全国单位森林蓄积量的最高值不高于3.813×105m3/km2,因此,将计算结果大于3.813×105m3/km2的栅格单元值设为3.813×105m3/km2,得到最终的空间化结果(见图7)。
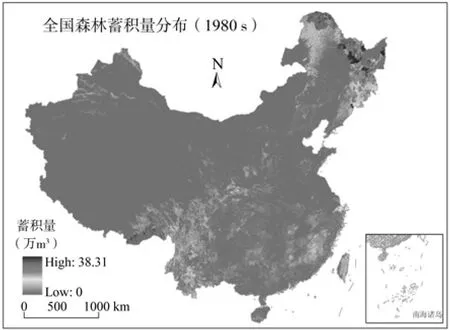
图7 全国公里网格森林蓄积量分布Fig.7 Distribution of total accumulation of live timber in China at resolution of 1 km by 1 km
4.3 空间化过程与结果分析
(1)尽管在空间化过程中进行了残差修正,但仍有少量栅格单元的蓄积量为负值,同时,少量栅格单元的空间化结果明显偏高,这些都是模型计算不可避免的。进一步分析表明,这些栅格单元的数量并不多,蓄积量为负值的栅格面积仅占全国总面积的5.90%,蓄积量大于3.813×105m3/km2的栅格面积仅占全国总面积的0.025%,因此,对这些栅格单元值的重新设定对最终结果的影响并不大。
(2)根据最终的空间化结果(见图7)统计分析得到,20世纪80年代,全国森林资源的总蓄积量为1.348 6×1010m3。图7既反映了全国森林蓄积量总量,又反映了蓄积量在1 km×1 km尺度上的空间分布状况。而一般的森林资源蓄积量调查数据则不能反映这些细节,这正是森林资源蓄积量调查数据空间化的目的和优势所在。
5 小 结
本研究采用分省区建模的方法进行全国森林蓄积量调查数据的空间化,从计算结果与实际调查数据之间的相关系数以及平均相对误差看,效果明显地要比全国使用同一个模型进行空间化好。但同时也存在一个问题,那就是部分省区接壤处(如内蒙与黑龙江)出现了一个比较明显的界线,造成这种结果的原因是这两个省区的调查数据口径存在差异。虽然用全国统一模型不存在这个问题,且整体性比较好,但具体到每个省区却又存在比较大的误差。因此,相比之下,对全国森林蓄积量数据进行空间化,省区模型仍然优于全国统一模型。
虽然本研究使用的森林蓄积量调查数据的时间是20世纪80年代,当然,所使用土地覆被数据也是同时期的。但作为一种空间化方法研究,数据的时间并无明显影响。下一步将收集较新的数据对本研究使用的方法进行进一步改进、完善和应用。
[1] Warring R H, Running S W. Forest ecosystem: analysis at multiple scales[J]. San Diego: Academic Press, 1998: 286-320.
[2] 杨洪晓, 吴 波, 张金屯, 等. 森林生态系统的固碳功能和碳储量研究进展[J]. 北京师范大学学报: 自然科学版, 2005,41(2): 172- 177.
[3] Brown S, Sathaye J, Canell M, et a1. Mitigation of carbon emission to the atmosphere by forest management[J].Commonwealth Forestry Rev.,1996,75: 80-91.
[4] 王晓宁,徐天蜀,李 毅. 利用ALOS PALSAR双极化数据估测山区森林蓄积量模型[J]. 浙江农林大学学报, 2012, 29(5):667-670.
[5] 王仲锋,冯仲科. 森林蓄积量与生物量转换的CVD模型研究[J]. 北华大学学报:自然科学版,2006,7 (3):265-268.
[6] 杨永恬,李增元,陈尔学,等. 基于ALOS PALSAR数据的森林蓄积量估测技术研究[J]. 林业资源管理, 2010,(1):113-117.
[7] 刘志华,常 禹,陈宏伟. 基于遥感、地理信息系统和人工神经网络的呼中林区森林蓄积量估测[J]. 应用生态学报,2008,19(9): 1891-1896.
[8] 余坤勇,林 芳,刘 健,等. 基于RS的闽江流域马尾松林分蓄积量估测模型研究[J]. 福建林业科技, 2006, 33(1):16-19.
[9] 许炜敏,孙开铭,陈友飞, 等. 杉木林蓄积量估测的因子选择研究[J]. 亚热带资源与环境学报,2012, 7(2):76-83.
[10] 洪奕丰, 林 辉, 严恩萍, 等. 基于偏最小二乘法的平南县森林蓄积量估测模型研究[J]. 中南林业科技大学学报, 2011,31(7): 80-85.
[11] 涂云燕,彭道黎. 基于神经网络的森林蓄积量估测[J]. 中南林业科技大学学报,2012, 32(3): 49-52.
[12] 王 磊, 张新华, 宋乃平,等. 基于遥感技术的人工速生林蓄积量估测[J]. 林业资源管理, 2007 ,(12): 84-88.
[13] 曾伟生,方宝新. 福建省林分蓄积量模型的建立[J].华东森林经理,2007,21(3):24-25.
[14] 龚道怀. 闽东北鹫峰山针叶林蓄积量模型的研究[J]. 湖南林业科技,2009,36(4):13-15.
[15] 文仕知,朱光玉,王忠诚,等. 湘西桤木人工林蓄积量模型及适宜经营密度研究[J].中国农学通报,2012,28(1):92-97.
[16] 佟金权. 广义干曲线模型在杉木人工林蓄积量测定中的应用[J]. 中南林业科技大学学报, 2007,27(1): 93-98.
[17] 朴世龙,方精云,贺金生,等. 中国草地植被生物量及其空间分布格局[J].植物生态学报,2004, 28 ( 4) :491-498.
[18] 彭守璋,赵传燕,郑祥霖,等. 祁连山青海云杉林生物量和碳储量空间分布特征[J]. 应用生态学报,2011,22(7):1689-1694.
[19] 刘双娜,周 涛,舒 阳,等.基于遥感降尺度估算中国森林生物量的空间分布[J].生态学报, 2012, 32(8):2320-2330.
[20] 廖顺宝,张 赛.属性数据空间化误差评价指标体系研究[J].地球信息科学学报, 2009,11(2):176-182.
[21] 廖顺宝,李泽辉.基于GIS的定位观测数据空间化[J].地理科学进展,2003,22(1):87-93.
[22] 廖顺宝,李泽辉,游松财.气温数据栅格化的方法及其比较[J]. 资源科学,2003,25(6):83-88.
[23] 于贵瑞,何洪林,刘新安, 等. 中国陆地生态信息空间化技术研究——气象/气候信息的空间化技术途径[J]. 自然资源学报, 2004, 19(4):537-544.
[24] 何洪林, 于贵瑞, 刘新安, 等. 中国陆地生态信息空间化技术研究——太阳辐射要素[J]. 自然资源学报,2004, 19(5):679-687.
[25] 刘新安,于贵瑞,范辽生, 等. 中国陆地生态信息空间化技术研究——温度、 降水等气候要素[J]. 自然资源学报, 2004,19(6): 818-825.
[26] 廖顺宝,孙九林.基于GIS的青藏高原人口统计数据空间化[J]. 地理学报,2003,58(1):25-33.
[27] 廖顺宝,李泽辉.基于人口分布与土地利用关系的人口数据空间化研究——以西藏自治区为例[J].自然资源学报, 2003,18(6)659-665.
[28] 廖一兰, 王劲峰, 孟 斌,等.人口统计数据空间化的一种方法[J]. 地理学报, 2007,62(10):1110-1119.
[29] 闫庆武,卞正富,王 红.利用泰森多边形和格网平滑的人口密度空间化研究——以徐州市为例[J]. 武汉大学学报:信息科学版, 2011, 36(8):987-990.
[30] 刘红辉, 江 东, 杨小唤,等. 基于遥感的全国GDP 1 km格网的空间化表达[J]. 地球信息科学, 2005, 7(2): 120-123.
Methodology for spatialization of timber volume data from forest inventory
LIAO Shun-bao1,2, XU Li-min1
(1.College of Environment and Planning, Henan University, Kaifeng 475004, Henan, China; 2. Institute of Geographic Sciences and Natural Resources Research, Chinese Academy of Sciences, Beijing 100101, China)
∶ Forest is a very important part of land ecosystem. Timber volume is one of basic indicators for forest inventory. The timber volume data usually are expressed in attribute tables with administrative divisions as record units, so it is difficult to reflect spatial dynamic of the timber volume in a detail scale. In this study, 1980s’ forest inventory data of China were used to analyze the relationship between timber volume and area of various kinds of forest (by landcover) or timberland (by landuse) in national and provincial levels respectively. The results from regression analysis demonstrated that the timber volume had closer relationships with landcover (R2= 0.568 2 at national scale and 0.851 1 at provincial scale) than with landuse (R2= 0.528 3 at national scale and 0.775 7 at provincial scale) either at national scale or provincial scale, and provincial models were better that national models. Based on the analysis results, the linear regression models between timber volume and area of different forest categories at provincial level were used to calculate the national timber volume product of China at a resolution of 1km by 1 km. And the result from the models computation was rectified with residuals which came from regression analysis at a scale of 1 km by 1 km. The rectified product, which is final product, can not only reflect spatial dynamic of the timber volume at a scale of 1 km by 1 km, but also be used to count total timber volume in light of administrative divisions at national, provincial or county levels. Based on the product there were about 13.486 billion cubic meters of timber volume in China in 1980s.
∶ forest; timber volume; inventory data; spatialization of forest data
S758.5+1;S771.8
A
1673-923X(2013)11-0001-07
2013-01-28
中国科学院战略性先导科技专项 (XDA05050000);环保公益性行业科研专项(201209030)
廖顺宝(1966-),男,四川德阳人,教授,博士,博士生导师,主要从事遥感与GIS在资源环境中的应用研究;E-mail:liaosb@igsnrr.ac.cn
[本文编校:谢荣秀]
