网络论坛搜索引擎的设计
2012-12-31唐勇桑丽丽
电脑知识与技术 2012年8期
摘要:网络论坛作为一种信息交流的平台蕴含着大量由用户发表的主题信息,目前互联网上出现了越来越多的具有较高信息聚合度的网络论坛,它们分散在互联网的各个角落,形成了新的“信息孤岛”。用户往往需要访问多个网络论坛来获取这些分散的信息。因此,有必要整合这些“信息孤岛”中的信息,为用户提供一个统一的访问接口来获取网络论坛中的信息。该文首先通过设计一种多个论坛爬虫程序来获取多个网络论坛中的帖子,并将这些不同格式的帖子转换成统一格式的XML文件,最后使用Lucene构建了面向多个论坛的搜索引擎,从而满足了用户对多论坛信息获取的需求。
关键词:网络论坛;搜索引擎;设计
中图分类号:TP315文献标识码:A文章编号:1009-3044(2012)08-1968-05
1网络论坛分析
为了整合多个论坛中的信息就需要对多个论坛的信息进行分析并抽象出共同的特征。目前,绝大数论坛都是由板块和帖子构成,即若干主题相关的帖子聚合形成板块,若干板块聚合构成论坛。每个论坛中的帖子地址和板块地址都具有相同的URL地址格式。帖子的URL地址显示了该帖子的内容;而板块的URL地址显示的是帖子标题列表,由于一个板块具有多个帖子,所以往往要划分为多个页面来显示,所以这里的板块URL地址是第一页,通过翻页地址可以链接到该板块的下一页。以“采购经理人论坛”网站为例,帖子的URL地址格式如下:http://bbs.purchasingbbs.com/forum.php?mod=viewthread&tid={articleId}&extra=page%3D{nextPage? Id}。其中{articleId}是帖子的数字编号,{nextPageId}是翻页地址的数字编号,即当前板块的页面编号。板块的URL地址的格式如下:http://bbs.purchasingbbs.com/forum.php?mod=forumdisplay&fid={boardId}。其中{boardId}是板块的数字编号。板块翻页URL地址的格式如下:
http://bbs.purchasingbbs.com/forum.php?mod=forumdisplay&fid={boardId}&page={nextPageId},这里的{boardId}是板块的数字编号而,{nextPageId}是板块的页面编号。
因此,本文认为一个论坛可以通过论坛名称、论坛首页地址、板块地址格式、帖子地址格式、板块翻页地址格式等来描述,从论坛首页地址出发可以找出所有与板块地址格式相匹配的板块地址,再从板块地址出发就可以找到所有与帖子地址格式相匹配的帖子地址,最后由帖子地址即可以得到帖子所包含的信息。
2论坛爬虫设计
2.1论坛爬虫分析
论坛爬虫的主要任务是从某个论坛的首页地址出发下载该论坛的所有帖子。它涉及到的三个实体类分别为:论坛实体、板块实体和帖子实体,与之对应的JavaBean对象分别为:SiteBean、BoardBean、ArticleBean,具体分析如下:
SiteBean是对论坛基本信息的封装,其属性包括论坛名称(SiteName)、论坛地址(SiteUrl)、板块地址格式(boardUrl)、帖子地址格式(articleUrl)、翻页地址格式(nextPageUrl)。在数据库中使用SiteInfo数据表来存放SiteBean实体类。
BoardBean是对板块信息的封装,其属性包含了板块编号(boardId)、板块名称(boardTitle)、板块地址(boardUrl)、帖子列表(arti? cleList)、论坛地址(SiteUrl)。这里的articleList是一个数据类型为LinkedList
ArticleBean是对帖子信息的封装,其属性包括帖子地址(articleUrl)、帖子标题(articleTitle)、帖子编号(articleId)、发表时间(post? Date)、保存时间(saveDate)、帖子标识(visitedFlag)、所属板块(boardUrl)、所属论坛(SiteUrl)。其中visitedFlag字段表示帖子的处理状态,当visitedFlag=0时表示当前的帖子是新帖子但还未被保存;当visitedFlag==1是表示帖子已经被保存但是还没有被转化为XML文档;当visitedFlag==2时表示该帖子已经加入到索引中处理完毕;当visitedFlag==-1时,表示该帖子的处理失败。在数据库中使用ArticleInfo数据表来存放ArticleBean实体类。
论坛爬虫还用到两个非常重要的工具类DownLoader类和HtmlPage类。其中DownLoader类借助于HttpClient4.0提供的Http协议访问功能,接收一个URL地址作为输入参数,下载该URL地址所对应的网页文件,并将该网页内容封装成HtmlPage类。HtmlPage类则借助于HtmlParser2.0提供的HTML文件解析功能,从HTML文件中提取出所需要的内容。HtmlPage类的extractBoardUrl方法以SiteBean对象的boardUrl属性作为板块地址格式,从论坛首页中提取出论坛的板块地址放入BoardBean对象的articleList属性中。
2.2抓取板块地址
一般而言,论坛的所有板块地址都包含在论坛的首页中,论坛爬虫通过读取论坛首页并匹配板块URL地址格式,可以获取该论坛的板块地址列表。抓取论坛板块地址的过程如图1所示。
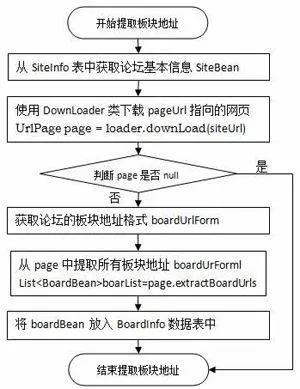
图1抓取论坛板块地址
2.3抓取新帖地址
通过读取每个板块的首页地址并匹配帖子URL地址格式及翻页URL地址格式可以获取该板块的所有帖子地址列表。抓取帖子的具体过程如图2所示。在抓取帖子的过程中,为了提高程序运行的效率,在发现新帖后先将新帖的地址保存到ArticleInfo数据表中,并将visitedFlag设置为0,等待下载程序的进一步处理。
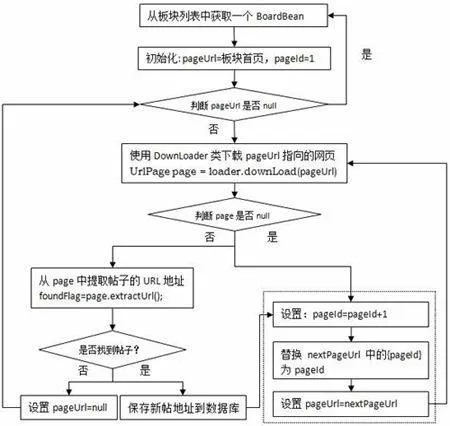
图2抓取论坛中的帖子
2.4下载贴子
下载程序的功能是将网络论坛中的帖子以html文件的格式保存在本地文件系统中,首先从ArticleInfo数据表中读取所有visit? edFlag==0的记录,并封装成ArticleBean实体类;再使用DownLoader类下载ArticleBean所对应的网页并保存到本地文件系统中;最后将当前记录的visitedFlag字段更新为1,同时更新saveDate为当前日期。
如何存储下载的帖子是关键点。一个论坛的帖子总数可以达几十万之多,而文件系统中一个的目录只能存储一定数量的文件,所以将所有帖子都存放在同一个目录中是不可行的。本文采用了论坛域名、板块编号、处理日期三个级目录结构,将帖子的存储路径设置为:
论坛地址\\板块编号\\处理日期\\帖子编号.html
以下是“采购经理人论坛”中某个帖子的保存路径,从保存路径中可以分析出该帖子属于10号板块,于2011年12月2日被保存。
bbs.purchasingbbs.com.html\\board10\\board10_20111202\\article120.html
2.5提取内容
提取程序的功能是将帖子的保存形式从html格式转化为xml格式。不同论坛中的帖子格式不尽相同,但是都包括如下信息:帖子的标题、帖子的地址、帖子的发表时间、帖子的内容、帖子所属的论坛。帖子在保存为html文件后将被提取程序转换为xml文件,xml文件的结构如下所示。
仍以“采购经理人论坛”中那个帖子为例,其对应的xml文件保存路径如下所示:
bbs.purchasingbbs.com.html\\board10\\board10_20111202\\article120.xml
可以看出xml文件的存储也采用了论坛域名、板块编号、处理日期三级目录结构。
提取程序首先从数据库中读取所有visitedFlag=1的记录并将这些记录都封装成ArticleBean实体类,再根据ArticleBean中的boardId字段、saveDate字段构成帖子的html文件存储路径和xml文件存储路径,最后从html文件中提取相关信息到xml文件中。
检测html文件的页面编码是提取程序的关键点。检测页面编码的程序采用三种中文编码:“gbk”、“gb2312”、“utf8”分别来解析html页面,如果某种编码解析出的html节点全部有效,则该编码就是页面编码;如果这种策略失败,则采用utf8编码去解析html页面,并查找页面中是否存在charset属性,并提取出charset属性的值作为当前页面编码。由于同一论坛的所有帖子的页面编码都相同,为了避免每次提取内容时都检测页面编码,应该将首次检测出的页面编码保存到SiteInfo数据表中,具体的计算流程见图3所示。
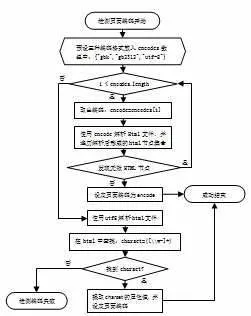
图3检测html页面的编码
检测出页面编码后就可以借助HtmlParser2.0来解析出帖子的有效内容、发表时间等信息。帖子的有效内容都包含在一个具有id属性的html标签中,以“采购经理人论坛”为例,帖子的有效内容包含在id值为postmessage_[d]+的html元素中。预先将内容标识contentFlag存放在SiteInfo数据表中,在读取论坛基本信息的时候该contentFlag被封装到SiteBean实体类中。提取有效内容的具体过程如图4所示。在提取过程中将发现的有效内容放入到StringBuffer缓冲区中,最后采用Dom4J开源包将StringBuffer的内容写入到xml文件中。
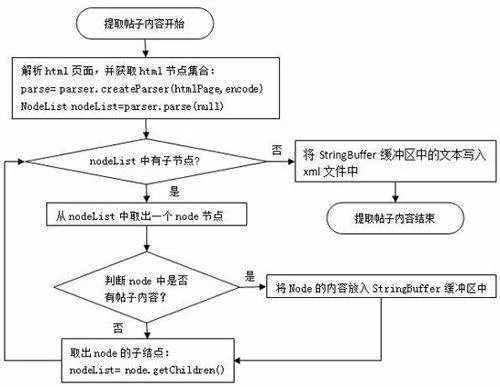
图4提取帖子内容
3搜索引擎设计
前面的爬虫程序从多个网络论坛中将所有板块的帖子下载到本地文件系统,并转化为统一的xml文件。为论坛搜索引擎的开发提供了数据源。这里的搜索引擎设计分为两大步骤,即索引文件的制作和搜索功能的开发。
3.1索引文件
爬虫程序生成的xml文件不能直接提供给搜索引擎使用,必须采用“倒排文档”技术生成索引文件。Lucene是一款开源的搜索引擎开发框架,它提供了制作索引的API接口。由于Lucene自带的分词包对中文的支持效果不是很好,本文采用了开源的paoding分词器,先将paoding分词器封装成符合Lucene要求的分词器,然后再使用这种分词器创建Lucene索引。在建立索引之前,设置索引的合并因子为50,设置文档在内存中的数目为100,这可以提高建立索引的效率。具体代码如下:
Analyzer analyzer = new PaodingAnalyzer();
indexer = new IndexWriter(indexP
