基于语义模式与词汇情感倾向的舆情态势研究
2012-11-30王铁套王国营黄惠新
王铁套,王国营,陈 越,黄惠新
(解放军信息工程大学 电子技术学院,河南 郑州450004)
0 引 言
网络舆情表达快捷、信息多元、方式互动等特点使其成为社会舆情动态的实时晴雨表,对人们生活和社会稳定的影响越来越大。突发事件易成为舆论焦点,一旦被网络媒体或网民报道,短时间内便会引起众多网民关注,相关报道被重复转载、迅速传播,进而造成突发事件事态扩大,并可能引起新的突发事件,因此,国家和社会的相关管理者应该对网络舆情进行及时的掌控。
目前,一些学者已经对网络舆情态势的分析进行了研究,例如,谢海光[1]等从统计学的角度构建了互联网内容和舆情的热点、重点、焦点、敏点、频点、拐点、难点、疑点、粘点和散点等十个分析模式和判据;钱爱兵[2]等设计出主题关注度分析、热点分析、焦点分析、拐点分析、重点分析,对网络舆情态势的分析提供了一种思路。
本文针对网络舆情的文本信息,依据文本情感分析技术,从情感词汇和上下文语境的角度对网络舆情进行分析,判断网络舆情的发展态势。
1 文本情感倾向性分析
目前,基于语义的文本倾向性研究方法主要有两种:一种是通过现有词典构建情感倾向词典,基于建立的词典,运用分词等技术判断文档中包含的关键词与词典中情感词的语义相似度来决定此关键词的倾向性,把所有关键词的倾向性综合起来就可得到此文档的倾向性。例如,Hiroya[3]等采用计算待测词和一些具有明显倾向性的基准词之间的互信息来判断倾向性,即利用待测词与褒义词、贬义词的语义距离计算待测词汇的语义倾向性;Ku[4]等利用WordNet中的其他与词汇相关的信息来判断词汇的语义倾向性;徐琳宏[5]等采用HowNet作为基准词,并在实验中加入否定词和副词的处理,计算待测词与关联度确定语义倾向,从语义理解方面对电影评论进行了倾向性识别研究。
另一种是建立一个语义模式库,采用语义分析技术用于文本倾向性判断。例如,Wilson等[6]探讨如何结合上下文环境中判定词语倾向性,选用了大量的特征,对信息的倾向性判别提出一种比较全面的方法;吕滨[7]等设计了一种基于语义分析的信息过滤模型,该模型针对不良信息的特点,以自然语句为处理单元,采用主题词和语义分析的两级过滤工作模式,实验表明,一级过滤由于采用精确主题词匹配,准确率为100%,二级过滤的准确率达到80%以上,这样可以同时获得较高的处理效率和精度。
综上可知,文本情感倾向性分析技术已经具有一定的研究成果,但是许多方法只是片面地进行倾向性判定,不能较全面、准确地判定文本倾向性。针对突发事件网络舆情,本文把语义模式和词汇情感倾向性分析技术结合起来,对舆情话题评论进行文本情感倾向性分析,判定舆情话题评论的正负导向性。
2 结合情感词汇与语义模式的文本倾向性判断
基于语义模式的方法不具有通用性,针对每个话题要抽取的语义模式不一样,另外,无法实现自动抽取语义模式;基于情感词汇的方法具有通用性,对于所有的话题可以使用一样的情感词典,而且人工操作少,但是,基于情感词汇的方法由于没有考虑语义关系和上下文环境,并不能真正鉴别相关文本的情感倾向性。通过以上分析可以看出,单独使用一种方法都不能达到较好的判别效果。由此,结合两种方法的优点,将两者结合起来形成如下思路:首先,基于HowNet建立基准词词典、否定词词典、程度副词词典和语义模式库;其次,对句子进行中文分词和词性标注,提取特征词汇并依据HowNet相似度方法确定其倾向值,注意考虑否定词、程度副词对词汇倾向值的影响;第三,对句子进行语义模式匹配并确定句子权值,并结合前面计算的词汇倾向值来确定文档的倾向值;最后将文档的倾向值与设定的阈值进行比较来最终确定文档的情感倾向性。
2.1 词汇情感倾向值计算
词汇情感倾向值的计算一般基于情感词典,基于情感词典的计算思想[8]是首先选出具有代表性的k对基准词,而每对基准词包含一个褒义词和一个贬义词。若褒义基准词用key_p表示,贬义基准词用key_n表示,词汇w的情感倾向值用Orient(w)表示,则计算公式[9]为

Orient(w)的数值大小表示词汇w褒贬的强烈程度。其中,Sim(key,w)表示词汇w与基准词之间的语义相似度。
一个词汇可能具有多个义项,而一个义项又可能有多个义原,词汇相似度计算可转换为义项相似度计算,而义项相似度计算又可解析为若干义原的相似度计算[10]。两个义原之间的语义相似度定义如下

式中:p1、p2——两个义原,d——两个义原在层次体系中的路径距离,α——一个可调节的参数。
由义原之间的语义相似度可导出义项之间的语义相似度,其定义如下[11]

式中:Y1、Y2——两个义项,t1、t2——义项Y1和Y2中的属性个数,原字符串——义项定义中不同位置的属性的权重值。
由此推出两个词汇之间的语义相似度[12]为
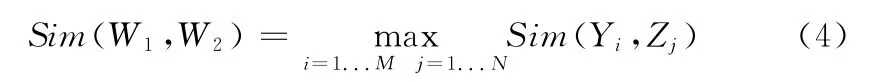
式中:W1、W2——两个词汇,词汇W1有M个义项Y1,Y2,...,YM,词汇W2有N个义项Z1,Z2,...,ZN。
考虑到否定词和程度副词对词汇情感倾向值的影响,除了构建基准词词典之外,还需要构建否定词词典和程度副词词典。作为实验,本文构建的词典中包含了汉语语言中常用的否定词和程度副词,这样可以较为全面的计算词汇的情感倾向值。构建的否定词词典是从HowNet中抽取的22个否定词,即:并非、不、不对、不再、不曾、不至于、从不、毫不、毫无、绝非、决非、没、没有、尚未、未、未必、未尝、未曾、永不、不大、不太、不很等。
如果情感词汇添加了否定前缀,其倾向值就会发生变化,有否定前缀修饰的词汇的倾向值的计算定义为

式中:m——否定词修饰的情感词汇,u——否定词出现的次数。
构建的程度副词词典根据每个程度副词的表达程度不同,为程度副词定义不同的强度值。本文抽取59个程度副词,将其划分为7个级别,分别赋予不同的强度,其値从1.5倍到0.8倍,具体设置如表1所示[13]。

表1 程度副词
如果情感词汇有程度副词修饰,其倾向值也发生变化,有程度副词修饰的词汇的倾向值的计算定义为

式中:n——程度副词修饰后的情感词汇,G(v)——程度副词v的强度值。
针对话题的评论 (专指文本),利用中国科学院计算技术研究所研制的中文分词系统ICTCLAS[14]进行中文分词和词性标注,查找评论中带有情感倾向的词汇,并依据情感词典记录其倾向值,判断评论中是否出现否定词和程度副词,计算词汇被修饰后的情感倾向值,最后,话题评论的情感强度为
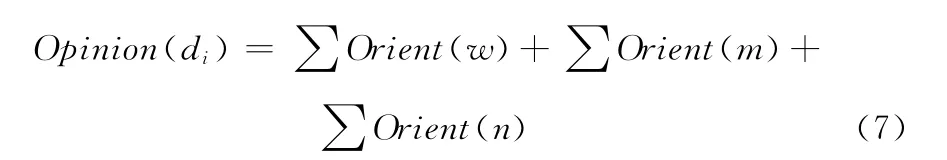
式中:Opinion(di)——话题的评论di的情感强度,w——包含评论中没有被否定词和程度副词修饰的情感词汇,m——被否定词修饰的情感词汇,n——被程度副词修饰的情感词汇。
2.2 语义模式分析
针对话题评论的情感倾向性分析,只用词汇的情感倾向性并不能真实全面反映评论所包含的情感,还需要依赖于一些语义模式。例如:“朝鲜击败韩国”和 “韩国击败朝鲜”,在向量空间模型中,其向量形式均为 (朝鲜,韩国,击败),两者的相似度为1,两个句子在任何情况下都是匹配的,而其实两个句子的意思却相反。要解决这个问题,则只有通过语义模式分析,识别文本和句子中各个特征项的角色和作用,进而比较全面地确定话题评论的情感倾向性。
基于语义模式的情感分析不仅仅是特征提取,而且要体现出语义关系。在情感倾向性分析时,也可以忽略一些要素,因为它们对情感倾向性的分析结果影响不大。依据动作的施加和承受,可以将句子分为4种语义模式[15]:
(1)主体 (Who)+行为 (What)+客体 (Whom)+权值 (Power),即主谓宾模式;
(2)主体 (Who)+行为 (What)+权值 (Power),即主谓模式;
(3)行为 (What)+客体 (Whom)+权值 (Power),即动宾模式;
(4)关键对象+权值 (Power),即关键对象模式。
在一些评论中,有些对象本身就反映了情感倾向,模式 (4)将具有明显倾向性的主体、行为或客体称为关键对象。例如:主体 “东突集团”、行为 “欺诈”本身就反映了强烈的情感倾向。
另外,对每个模式设置权值,表示褒义倾向的语义模式设置为正权值,表示贬义倾向的语义模式设置为负权值,例如:反对台独的模式权值可以分别设置为1~3,而支持台独的模式权值可以分别设置为-1~-3,这样的设置可以消除因引用反面信息而造成的误判,比如,褒义评论中可能引用一些贬义信息,出现这类评论的语义模式的权值可能会小于零,但是整个评论的大部分语义模式的权值大于零,则整个评论的权值就大于零,不会造成倾向性误判。
2.3 基于语义模式与词汇情感倾向的判定算法
综合以上两种分析,给出以下判定算法。
输入:语义模式集合S= {s1,s2,...},需要情感倾向判定的话题T= {d1,d2,...},其中,di是话题的各条评论,设定阈值θ。
输出:话题评论的情感倾向值R(T)。
话题评论倾向性判定步骤:
(1)为话题的每条评论di寻找与集合S中相匹配的语义模式,得到相应的权值Q= {q1,q2,...};
(2)对话题的每条评论di进行中文分词和词性标注,提取特征对象和特征词汇,依据以上基于词汇的情感倾向值计算得到该评论的情感倾向值Opinion(di);
(3)结合评论的语义模式的权值qi和其情感倾向值Opinion(di)得到该话题评论的最终情感倾向值

式中:ci——评论di的字数。
(4)将 (3)计算得到的最终情感倾向值与设定的阈值θ进行比较,判定话题评论的情感倾向性。
3 实验及结果
本文人工采集两个话题 (T1和T2)及其评论进行实验,分别采用基于语义模式的方法、基于词汇情感倾向性的方法与基于本文提出的综合性方法进行情感倾向性判断比较。话题T1是百度贴吧上对突发事件 “新疆7.5事件”的评论集,包含500条评论,其中300条正面的评论、150条负面的评论和50条中立的评论;话题T2是网易新闻论坛上有关突发事件 “刘翔奥运退赛”的评论集,包含230条积极的评论、220条消极的评论和50条中立的评论。
为了比较3种方法的性能,对测试的话题评论集计算其判断准确率。利用下面的公式计算其判断的准确率
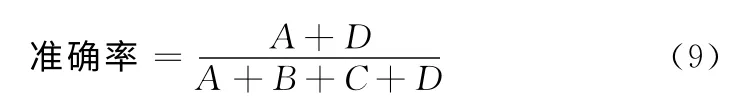
式中:A——被正确判断为正面的评论个数,B——被误判为正面的评论个数,C——被误判为负面的评论个数,D——被正确判断为负面的评论个数。
表2是针对不同的话题所进行的测试,其中,方法1、方法2、方法3分别代表 “基于语义模式的方法”、“基于情感倾向性的方法”和 “基于综合的方法”。

表2 3种方法的实验结果对比
实验表明,从判断的准确率来看,方法3较方法1和方法2的评论倾向的判断准确率高,这在一定程度上验证了方法3的有效性和实用性,即方法3综合两者的优点,使文本情感倾向判定的准确率达到了较理想的效果,比较全面地反映了话题评论的情感倾向性。
4 结束语
本文提出了一种将语义模式与计算词汇情感倾向性相结合的方法来判断文本的情感倾向性。该方法既考虑了词汇的情感倾向性,又能权衡语义模式对评论的情感倾向值的影响,能比较全面地分析突发事件网络舆情的态势。但是词典的构建与语义模式的建设需要人工参与的操作多,个人的主观性影响比较大,机器学习的工作不多,这些都需要改进,另外,由于网络语言表达的灵活性,现有技术还不能完全准确地判定句子的情感倾向性,需要进一步研究。
[1]XIE Haiguang,CHEN Zhongrun.Internet Information and the pattern of public opinion analysis in depth [J].Journal of China Youth College for Political Sciences,2006,25 (3):95-100(in Chinese).[谢海光,陈中润.互联网内容及舆情深度分析模式 [J].中国青年政治学报,2006,25 (3):95-100.]
[2]QIAN Xuebing.A model for analyzing public opinion under the Web and its implementation [J].New Technology of Library and Information Service,2008,24 (4):49-55 (in Chinese).[钱爱兵.基于主题的网络舆情分析模型及其实现 [J].现代图书情报技术,2008,24 (4):49-55.]
[3]Hiroya Takamura,Takashi Inui,Manabu Okumura.Extracting semantic orientations of words using spin model [C].Michigan,USA:Proceedings of the 43rd Annual Meeting on Association for Computational Linguistics,2005:133-140.
[4]KU Lun-Wei,LIANG Yu-Ting,CHEN Hsin-His.Opinion extraction,summarization and tracking in news and blog corpora[C].Proc of AAAI Spring Symposium on Computational Approaches to Analyzing Weblogs,2006:100-107.
[5]XU Linhong,LIN Hongfei,YANG Zhihao,et al.Text orientation identification based on semantic comprehension [J].Journal of Chinese Information Processing,2007,21 (1):96-100(in Chinese).[徐琳宏,林鸿飞,杨志豪,等.基于语义理解的文本倾向性识别机制 [J].中文信息学报,2007,21(1):96-100.]
[6]Theresa Wilson,Janyce Wiebe,Paul Hoffmann.Recognizing contextual polarity in phrase-level sentiment analysis [C].Vancouver:Proceedings of Human Language Technology Conference and Conference on Empirical Methods in Natural Language Processing,2005:347-354.
[7]LV Bin,LEI Guohua,YU Yanfei,et al.Reaserch on filtering system of harmful information on internet based on semantic analysis [J].Computer Applications and Software,2010,27 (2):283-285 (in Chinese).[吕滨,雷国华,于燕飞,等.基于语义分析的网络不良信息过滤系统研究 [J].计算机应用与软件,2010,27 (2):283-285.]
[8]WordNet[EB/OL].http://wordnet.princeton.edu/,2008.
[9]ZHU Yanlan,MIN Jin,ZHOU Yaqian,et al.Semantic orientation computing based on HowNet [J].Journal of Chinese Information Processing2006,20 (1):14-20 (in Chinese).[朱嫣岚,闵锦,周雅倩,等.基于HowNet的词汇语义倾向计算 [J].中文信息学报,2006,20 (1):14-20.]
[10]HowNet[EB/OL].http://www.keenage.com,2008.
[11]LI Dun,QIAO Baojun,CAO Yuanda,et al.Word orientation recognition based on semantic analysis [J].Pattern Recognition and Artificial Intelligence,2008,21 (4):482-487 (in Chinese).[李钝,乔保军,曹元大,等.基于语义分析的词汇倾向识别研究 [J].模式识别与人工智能,2008,21 (4):482-487.]
[12]JIANG Min,XIAO Shibin,WANG Hong wei,et al.An improved word similarity computing method based on HowNet[J].Journal of Chinese Information Processing,2010,22(1):5-7 (in Chinese).[江敏,肖诗斌,王弘蔚,等.一种改进的基于 《知网》的语义相似度计算 [J].中文信息学报,2010,22 (1):5-7.]
[13]WEN Bin,HE Tingting,LUO Le,et al.Text sentiment classification research based on semantic [J].Computer Science,2010,20 (1):261-264 (in Chinese).[闻彬,何婷婷,罗乐,等.基于语义理解的文本情感分类方法研究 [J].计算机科学,2010,20 (1):261-264.]
[14]ICTCLAS.ICTCLAS’s Home Page [EB/OL].http://ictclas.org/,2010.
[15]JIANG Baolin,LIU Yongdan,JIN Feng,et al.A tendentious text filtering system based on semantic analysis [J].Computer Applications and Software,2005,22 (1):10-11(in Chinese).[江宝林,刘永丹,金峰,等.一个基于语义分析的倾向性文档过滤系统 [J].计算机应用与软件,2005,22 (1):10-11.]
