问答系统中问句间语义相似度研究
2012-11-10汪材印宿州学院机械与电子工程学院安徽宿州234000
汪材印 (宿州学院机械与电子工程学院, 安徽 宿州 234000)
崔 琳 (宿州学院信息工程学院, 安徽 宿州 234000)
问答系统中问句间语义相似度研究
汪材印 (宿州学院机械与电子工程学院, 安徽 宿州 234000)
崔 琳 (宿州学院信息工程学院, 安徽 宿州 234000)
问答系统是信息检索系统的一种高级形式,它能够用准确、简洁的自然语言回答用户用自然语言提出的问题。如何计算问句之间的语义相似度是问答系统面临的主要难题。提出一种新的计算问句间语义相似度的方法,即综合考虑问句之间的显式关联和隐式关联2个方面,将链接预测模型与查询似然语言模型相结合计算问句之间的语义相似度。试验表明,采用该方法可提高问句语义匹配的准确率。
问答系统;语义相似度;链接预测;语言模型;随机游走模型
随着因特网的迅猛发展和Web2.0技术的日益成熟,问答系统(Question Answering System,QAS)逐渐成为一种新的信息检索技术。问答系统是指能够用准确、简洁的自然语言回答用户用自然语言提出的问题[1]。由于问答系统返回的是精确的答案,而不是一大堆相关的文档,因而问答系统比搜索引擎更快捷、高效,是未来搜索引擎发展的方向。
依据系统所处理问题范围的不同,问答系统可以分为开放领域问答系统和受限领域问答系统,前者不限输入问题的范围,可以解决关于任何主题的问题,后者只针对某一个特定领域(例如交通等领域)的问题。依据产生答案的方法不同,问答系统又可以分为自动问答系统和用户交互式问答系统,自动问答系统主要基于构建的知识库系统自动进行回答,用户交互式问答系统则通过让广大用户参与到问答当中,使用户能够共同协作,达到相互帮助的目的[2]。
句子相似度的计算是问答系统的核心所在,其计算方法的精确性和实时性关系到整个系统的精确性和效率,随着国内外学者的深入研究,目前的问句相似度计算有基于词形词序匹配的方法、基于语义计算的方法、基于编辑距离的方法等[3],但答案抽取的准确率不高。为此,笔者提出一个新的计算问句相似度的思路,即将链接预测思想与传统的问句相似度计算模型相结合,综合考虑问句之间的显式关联程度和隐式关联程度2个方面,从而更加准确地计算问句之间的的语义相似度。
1 问句之间的关联方式
问答系统面临的最大困难是2个问句使用不同的词汇表达相同或者相近的意思,在此情况下,使用向量空间模型或语言模型等以词形匹配为基础的模型来计算问句之间的相似度,很难达到满意效果。经研究发现,问句之间有2种关联方式:显式关联和隐式关联。显式关联是问句之间存在相同的单词,隐式关联是问句间用不同的单词表达相同或者相近的含义。传统的相似度计算模型只关注了问句之间的显式联系,但对问句之间的隐式关联无法进行有效评估。对此,可以将问句集合表示为网络,网络中的各个节点即为问句集合中的问句,节点之间的边即为问句之间的显式联系,则网络中2个节点之间存在未知链接的可能性,就代表了这2个节点所对应问句之间的隐式关联程度(见图1)。由图1可知,问句Q与问句Q1,Q2,…,Qn之间有边相连,证明问句Q与问句Q1,Q2,…,Qn之间存在显式关联;问句Q′与问句Q1,Q2,…,Qn之间有边相连,证明问句Q′与问句Q1,Q2,…,Qn也存在显式关联。那么,Q与Q′所代表的节点之间存在未知的边的概率,就代表了Q与Q′之间隐式关联程度(如图1中虚线所示)。
2 结合语言模型和链接预测思想的问句相似度计算
2.1查询似然语言模型

图1 问句Q与Q′之间的隐式关联图
信息检索模型是信息检索的核心,信息检索模型包括布尔模型、向量空间模型和语言模型等[4]。语言模型主要是通过统计学和概率论对自然语言建模,其中查询似然语言模型是该模型中最具代表性的一种类型,其计算方法如下[5]。
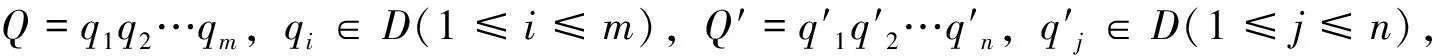

(1)
式中,P(qi|Q′)表示单词qi在问句Q′中的出现概率;P(w|Q)表示单词w在问句Q中出现的概率;c(w,Q)表示单词w在问句Q中出现的次数。
2.2链接预测模型
网络中的链接预测是指如何通过已知的网络节点以及网络结构等信息来预测网络中2个不相连的节点之间产生链接的可能性。Jaccard系数模型和随机游走模型是常用的2种链接预测模型,其中随机游走模型是基于边的链接预测模型的代表,采用随机游走模型计算问句之间的隐式关联程度,相关内容如下[6]。
在该模型中,从某一节点出发,移动到其任一邻接点的过程即为随机游走的过程。将节点x和节点y之间的隐式关联程度定义为从x出发随机游走到达y的平均步数:
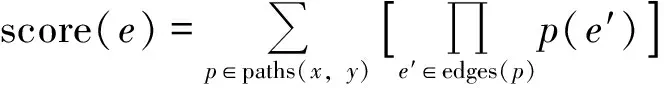
(2)
式中,score(e)表示节点x和节点y之间存在未知链接e的评分,也可以理解为节点x和节点y所代表的问句之间的隐式关联程度;paths(x,y)表示从节点x到节点y的所有路径的集合;edges(p)表示路径p中包含的所有边的集合;p(e′)表示在随机游走过程中选择边e′的概率。
p(e′)取值的基本思想是:当边e′权重越大,则p(e′)取值越大,而当边e′的起始节点的邻接边集合的权重之和越大,则p(e′)取值越小,其计算公式如下:
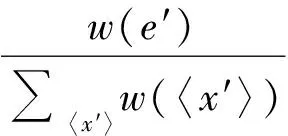
(3)
式中,w(e′)表示边e′的权重;x′表示边e′的起始节点;〈x′〉表示节点x′的邻接边的集合。
2.3基于归一化处理策略的问句相似度计算模型
传统的问句相似度计算只考虑问句之间的显式关联,一般都忽略了问句之间的隐式关联。针对上述情况,综合考虑问句之间的显式关联和隐式关联2个方面,利用查询似然语言模型计算问句之间的显式相似度和随机游走模型计算问句之间的隐式相似度来精确抽取答案。计算问句之间的语义相似度的步骤如下:
1)将问答系统中的所有问句表示为1个无向图G=(V,E);其中,V是无向图中顶点的集合,E是无向图中边的集合,V表示问答系统中的所有问句,E表示2个节点所对应问句存在显式关联,2个问句之间的显式相似度值(使用查询似然语言模型计算)就是边的权重。
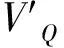
3)利用随机游走模型计算顶点VQ与图中各个顶点之间存在未知链接的概率,即问句之间的隐式相似度,将问答系统中各个问句按照与用户提问Q的隐式相似度由高到低进行排序。
4)对用户提问Q与问答系统中任一问句Q′之间的显式相似度和隐式相似度做归一化处理,计算两者之间最终的语义相似度。由于语言模型和随机游走模型计算结果的量级不统一,通过上述步骤所得出的问句之间的显式相似度和隐式相似度的量级也不统一,无法直接进行运算。因此,要对问句之间的显式相似度和隐式相似度做归一化处理,解决量级不统一的问题。
即对用户提问Q,有:
(4)
并且:
(5)
式中,SimLM、SimLP分别表示用户提问Q与问答系统G中的问句Q′之间的显式和隐式相似度。
即对用户提问Q,其与图G所对应的问答系统中全部问句的相似度的和为1。在此基础上,计算用户提问Q和Q′之间最终的语义相似度:
Score(Q,Q′)=λSimLM(Q,Q′)+(1-λ)SimLP(Q,Q′)
(6)
式中,λ∈(0,1),以调和问句之间的显式相似度和隐式相似度对问句之间语义相似度的影响。
5)在图G所对应的问答系统中,查找与Q具有最高语义相似度的问句输出。
3 试验分析
由于现在国内没有通用的问答系统,笔者通过网络爬虫程序从新浪爱问(http://iask.sina.com.cn)上抓取了部分问句,新浪爱问按照主题对问题进行分类,为了避免试验结果过于依赖特定领域,抓取的问句来自4个主题,即教育、健康医学、运动爱好和社会文化,共收集了这4个主题的3126条问句, 构建问句集合Set_Question,从问句集合Set_Question中无放回的随机抽取100个问句,构建测试集合Set_Test。试验数据集合如表1所示。
对于测试集合Set_Test中的每个问句Q,计算问句集合Set_ Question中各个问句与Q的相似度,并将与Q相似度最高的5个问句作为检索结果返回。有3位测试人员对每个返回的问句进行评分,如果实验人员认为某问句与用户提问Q语义相似,则为其计分为1,否则为0。如果一个问句的得分大于等于2,则该问句标注为与用户提问“相似”,否则将其标注为“不相似”。首先,只考虑问句间的显式关联时,得出一种问句标注结果;其次,使用笔者提出的基于归一化处理策略的问句相似度方法进行问句标注时又得出另一种标注结果,2种方法下问句标注结果的对比如表2所示。对于教育领域的25个测试问句,测试人员从由801个问句构成的问句集合中,计算与这25个测试问句语义相似的问句,如果只考虑问句间的显式关联,那么在801个问句集合中,有42个问句与25个测试问句语义相似;如果使用笔者提出的基于归一化处理策略的问句相似度方法计算,那么在801个问句集合中,就有59个问句与25个测试问句语义相似。显然,使用笔者提出的方法计算问句间语义相似度时,能更好地度量问句之间的语义相似度,因为该方法既考虑了问句间的显式关联,又考虑了问句间的隐式关联。

表1 试验数据集合

表2 问句标注结果
4 结 语
提出了基于归一化处理策略的问句相似度计算方法,利用查询似然语言模型计算问句之间的显式相似度,利用链接预测模型中的随机游走模型计算问句之间的隐式相似度,并将问句之间的显式相似度和隐式相似度做归一化处理,得出问句之间最终的语义相似度。下一步的研究工作是把笔者提出的基于归一化处理策略的问句相似度计算方法与几种常用的语义相似度计算方法进行对比,以进一步验证该方法的有效性。
[1]郑实福,刘挺,秦兵,等.自动问答综述[J].中文信息学报,2002,16(6): 46-52.
[2]宋万鹏. 短文本相似度计算在用户交互式问答系统中的应用[D].合肥:中国科学技术大学,2010.
[3]李月雷,师瑞峰.汉语语句语义相似度的计算方法[J].计算机科学, 2008,35(4):3-4.
[4]秦喜艳,陆伟,姜捷璞.信息检索中的相关性判断和系统评价述评[J].图书情报知识,2009(4):89-94.
[5]Ponte J M,Croft W B.A Language Modeling Approach to Information Retrieval[A]. Proceedings of the 21st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval [C],1998:275-281.
[6]David L N,Jon K.The Link-Prediction Problem for Social Networks[J].Journal of American Society for Information Science and Technology,2007,58(7):1019-1031.
[编辑] 李启栋
10.3969/j.issn.1673-1409(N).2012.04.036
TP391
A
1673-1409(2012)04-N103-03
2012-02-10
安徽省高等学校优秀青年人才基金项目(2010SQRL192);安徽省高校自然科学研究一般项目(KJ2011B173)。
汪材印 (1977-),男,2001年大学毕业,硕士,讲师,现主要从事问答系统和语义Web方面的教学与研究工作。
