基于单向增长链表的关联规则挖掘算法研究
2012-11-08亳州职业技术学院信息工程系安徽亳州236800
董 辉 (亳州职业技术学院信息工程系,安徽 亳州 236800)
基于单向增长链表的关联规则挖掘算法研究
董 辉 (亳州职业技术学院信息工程系,安徽 亳州 236800)
分析研究关联规则挖掘经典算法Apriori和FP-Growth算法,发现其不足之处在于构建和遍历各自数据结构的时间长、内存消耗巨大,降低了算法在时间和空间方面的效率。针对2种算法的缺陷,提出了LK-Growth算法,该算法不再构建FP-Tree,而是构建单向线性链表组结构,能有效地缩短发现频繁模式的时间和节省内存空间开支。研究结果表明,LK-Growth算法的实用性强且挖掘效率更高。
数据挖掘;关联规则;线性增长链表;LK-Growth算法
关联规则挖掘是数据挖掘众多知识类型中一种典型代表,也是数据挖掘中最活跃的研究领域之一,其首要任务就是发现频繁项目集。长期以来,人们对关联规则频繁项目集的挖掘主要采用Apriori算法和FP-Growth算法或者它们的有关改进算法。但是,无论是Apriori算法还是FP-Growth算法,都要多次扫描事务数据库,I/O负载大,导致算法的时间开销增大;在空间需求上,Apriori算法要产生大量的候选频繁项目集、FP-Growth算法构造结构复杂的FP-Tree树,对内存开销要求都很高[1]。针对上述情况,笔者提出基于单项线性链表的关联规则挖掘优化算法,该算法构建多个单向链表结构做成链表组,通过该结构的遍历发现所有的频繁模式,在挖掘效率上比Apriori和FP-Growth算法都要高。
1 优化算法设计
1.1优化算法的思路
从对关联规则挖掘的2种经典算法的分析可知,要想提高挖掘效率,可从2方面考虑[2]:第1方面是优化重构算法操作对象的数据结构;第2方面是在不改变操作对象的数据结构情况下,改变对其执行方式,提高操作速度,发现频繁项集。笔者从第1方面着手,构建单向链表组数据结构,提出优化的LK-Growth算法,挖掘出所有的频繁模式,从而提高挖掘效率。
1.2算法设计
LK-Growth算法设计过程为输入:事务数据库D,最小支持度阀值 min_sup;输出:频繁模式完全集。具体实现步骤如下[3-4]:①首次扫描事务数据库D生成1-频繁项集和各项支持度计数值,把支持度计数满足最小支持度阀值的各项及支持度计数按支持度计数降序存至项头表HT(Header Table)中;②第2次扫描数据库D,对第1个事务 扫描,保留出现在HT表的频繁项,各项节点按支持度计数降序排列,存入到名为SingleLink单链表内;③构造以项头表中节点为头节点的单链表组,伪代码如下:
Procedure HTL_List
(1)For (i=2;i≥j;i++) //j是SingleLink链表中的节点数
(2)Do begin
(3) For (m=i;m≥2;m--)
(4)Do begin
(5)Insert_link(SL,Mj-1); //Mj为SingleLink
//链表第j个节点,SL为HT表中以Mj为头节点的单向链表
(6)End
(7)End
在构造单链表过程中调用Insert_link( )函数作用是把节点插入到LT单链表中,其伪代码如下:
Function insert_link(LT,λ)
(1)If( LT中存在 ) Then
(2)λ.Sup_count=λ. Sup_count +1; //λ节点支持度计数加1
(3)Else
(4)IF (按HT表的排序,LT中存在δ节点排在λ前) Then
(5)λ节点链接在δ之后,λ.Sup_count=λ. Sup_count +1;
(6)Else
(7)节点链接到LT的尾端,λ.Sup_count=λ.Sup_count +1;
④依照上述步骤依次扫描数据库D的每个事务,每次扫描要重构SingleLink单链表,再按步骤②、③对余下的频繁项作类似处理,直到全部事务扫描完止,把各事务的所有数据项都插入到相应的以项头表中节点为头节点的单链表内。至此,可以得到以HT表中各节点为头指针的各单链表组成的相邻的链表组,通过遍历该邻接链表组,即可发现满足最小支持度阀值的所有频繁模式。
2 应用案例
2.1构建事务数据库
设事务数据库D(见图1),设最小支持度计数为3。根据最小支持度计数为3,对事务数据库D的数据项进行排序,结果如图2所示。
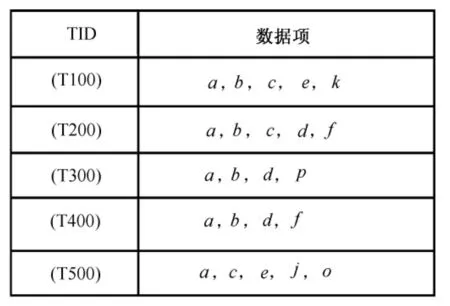
图1 事务数据库D
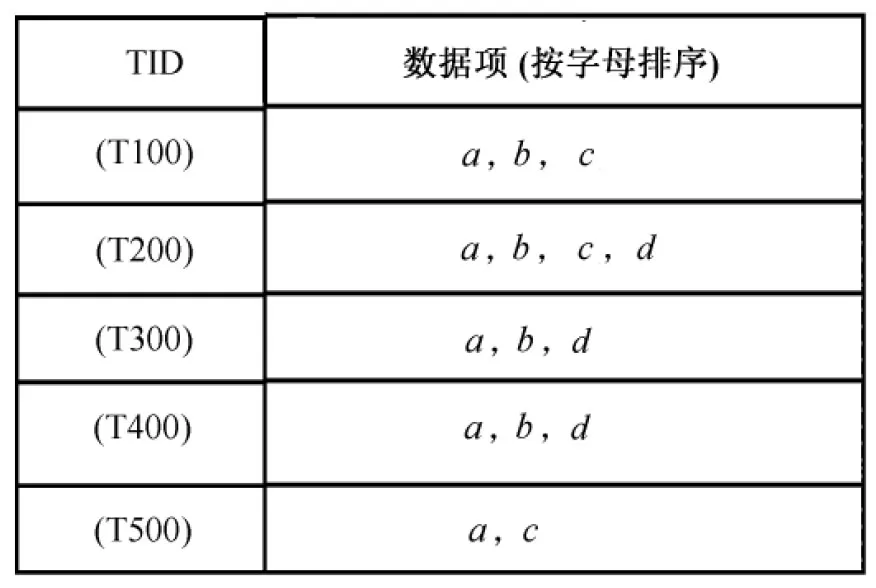
图2 处理后的事务数据库D
2.2LK-Growth算法应用
首次扫描事务数据库D,得到1-频繁项集:L={(a:5),(b:4),(c:3),(d:3) }(支持度计数相同者按字典排序,e、f、j、k、o、p、s的支持度计数为1小于2,故舍去),并把1-频繁项集按支持度计数降序存入项头表HT中。

图3 第1个事务的SingleLink链表
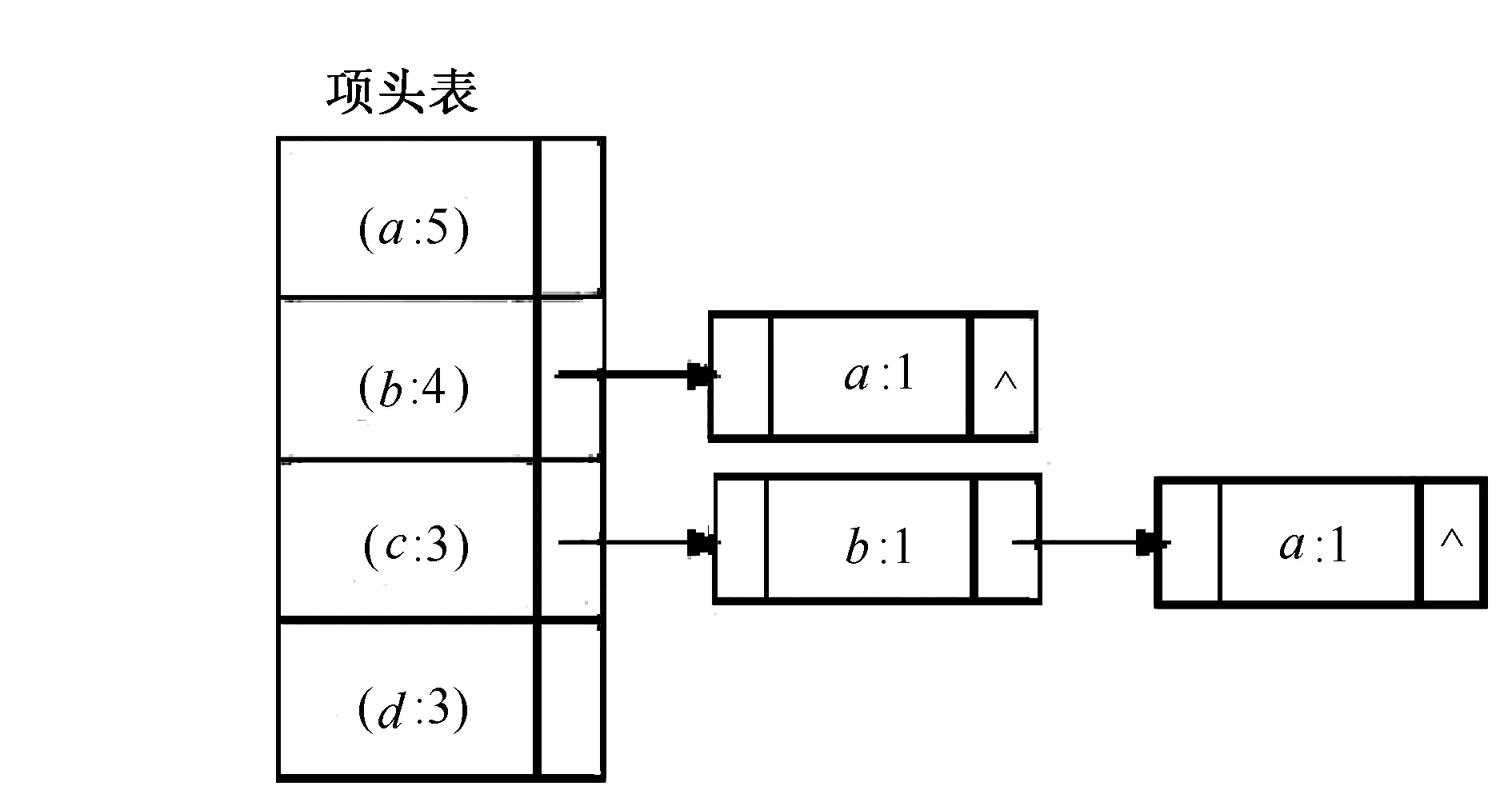
图4 节点单链表结构
第2次扫描事务数据库D,对T100事务的扫描只保留HT中出现的频繁项,且按支持度计数降序排列得到:a、b、c,依次存入SingleLink单链表中,此时SingleLink链表节点个数j=3,其第2的节点为b,把b的父节点(即a)插入到HT表中以b为头节点的单向链表中,计数值置为1。同理,对余下节点进行上述操作,对T100事务扫描操作结束后,SingleLink单链表如图3所示,各节点单链表结构如图4所示。
按照上述操作,对余下事务进行扫描操作,每次重构SingleLink链表,并把每个节点信息按如下规则插入到相应的单链表位置上:若链表内无该节点,则创建之,并计数值置1;若链表内存在该节点,无需再创建,计数值加1即可。按照上述方法,直至全部事务扫描完毕,最后生成以项头表HT中各节点为头结点的多个单链表构成的链表组,结果如图5所示。
遍历图5,在满足支持度计数大于3的条件下,以项头表HT中各节点为基本结点,分别对各单链表中各节点组合,可得频繁模式集(见图6)。
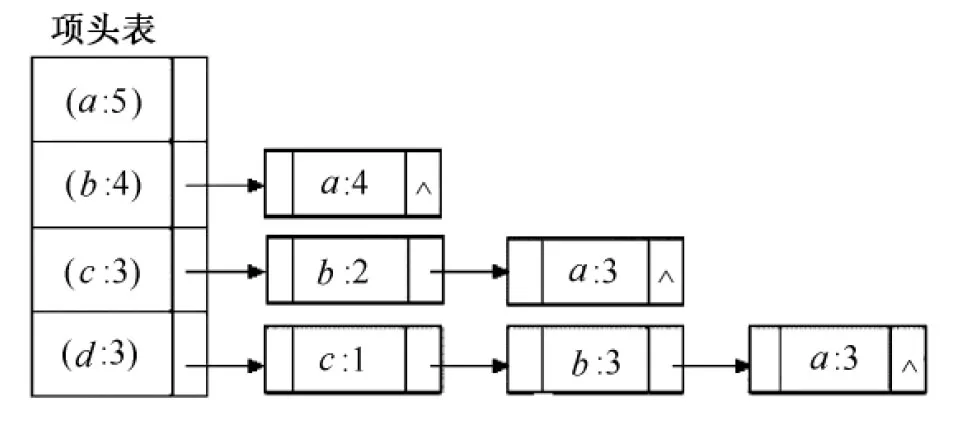
图5 各事务所有节点构成的链表组

图6 满足最小支持度阀值的所有频繁模式
2.3算法性能试验分析
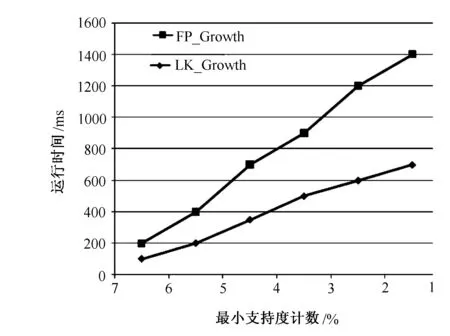
图7 算法运行对比图
通过试验对FP_Growth算法和LK_Growth算法的性能进行分析比较。试验测试环境如下:Intel Core i3 CPU;4G内存;320G SATA硬盘;Win7 OS;C#编程环境。试验中采用的数据库为中国生物谷中药方剂数据库,数据库事务量(即方剂数)为84449,测试结果如图7所示。
由图7可知,在相同支持度计数的情况下,要处理的事务量是相同的,但是LK_Growth算法所花费的时间明显要小于FP_Growth算法所耗费的时间,LK_Growth算法的效率要高于FP_Growth算法的效率,且随着支持度计数的减小和事务量的增大,LK_Growth效率优势越明显,总体效率比FP_Growth要高50%以上。
3 结 语
分析了关联规则中的Apriori和FP_Growth算法,针对其不足,提出了LK_Growth优化算法。由于在优化算法中无需生成频繁模式基和条件模式树,而是把事务的所有节点数据项直接存入到以HT表中各节点为头指针的相邻的单链表组中,因此减小了空间消耗,避免了内存压力,同时也仅需扫描事务数据库2次,且这种存储结构本身就直接蕴涵了全部频繁项目集,通过遍历操作,可以很容易地挖掘出所有的频繁项模式,挖掘效率有了显著的提高。试验结果表明,改进后的算法速度快,而且挖掘的数据库事务量越大,其优越性越能得以体现,从而为关联规则挖掘提供了新途径。
[1]朱 明.数据挖掘[M].合肥:中国科学技术大学出版社,2008.
[2]杨云,罗艳霞.FP-Growth 算法的改进[J].陕西科技大学学报,2010,31 (7):1506-1508.
[3]石杰.大规模数据库关联规则挖掘算法研究[D].济南:山东师范大学,2003.
[4]潘福铮.数据挖掘中的关联规则[J].湖北大学学报(自然科学版),2002,24(4):25-29.
[编辑] 李启栋
10.3969/j.issn.1673-1409.2012.01.035
TP391.1
A
1673-1409(2012)01-N110-03
