剖宫产手术预防性使用抗菌药的数据挖掘
2012-11-06杨樟卫陈盛新陈长虹何宇涛南京军区杭州疗养院药械科浙江杭州0007第二军医大学长海医院药学部上海00第二军医大学药学院药事管理学教研室上海00第二军医大学长海医院信息科上海00
傅 翔,杨樟卫,陈盛新,陈长虹,何宇涛 (. 南京军区杭州疗养院药械科,浙江 杭州 0007;. 第二军医大学长海医院药学部,上海 00;.第二军医大学药学院药事管理学教研室,上海 00; . 第二军医大学长海医院信息科,上海 00)
傅 翔(1972-),男,博士.E-mail:fqj2000@hotmail.com.
剖宫产手术预防性使用抗菌药的数据挖掘
傅 翔1,杨樟卫2,陈盛新3,陈长虹4,何宇涛4
(1. 南京军区杭州疗养院药械科,浙江 杭州 310007;2. 第二军医大学长海医院药学部,上海 200433;3.第二军医大学药学院药事管理学教研室,上海 200433; 4. 第二军医大学长海医院信息科,上海 200433)
目的建立、比较和评价剖宫产手术抗菌药物预防使用的分类模型,为针对性干预打下基础。方法应用数据挖掘软件PASW® Modeler 13,建立分类模型,获得对抗菌药物预防性使用影响较大的变量(临床因素)。结果由787例行“子宫下段剖腹产术”的病例数据获得的分类模型中,以贝叶斯网络,logistic回归和CHAID 3个模型总体较佳; 21个变量指标中,“失血量”是对该医院剖宫产手术抗菌药物预防性应用影响程度最大的因素。结论数据挖掘技术,可以快速地建立反映剖宫产手术抗菌药物预防性使用的分类模型,为药物利用调查提供了新的分析方法。
数据挖掘;抗菌药物; 剖宫产
剖宫产是当前产科学中一种常见而重要的手术,近年来,国内剖宫产率出现迅猛增高的势头。剖宫产手术属于Ⅱ类(清洁-污染)切口手术,一般需预防性使用抗菌药物。
近年来,有关剖宫产围术期抗菌药物使用调查或干预的文献时有报道,这些研究通过了解剖宫产围手术期抗菌药物的应用现状[1~4],反映剖宫产抗菌药物预防性使用中存在的问题。由于临床环境和临床实践的复杂多变性,病人的药物治疗受多种因素影响,仅仅通过对药物品种、使用频率、用药时间、药品费用数据的调查,如忽视其他临床信息,得出的结论可能比较片面,干预也将缺乏针对性。
数据挖掘(data mining,DM)又称数据库中的知识发现,是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的、事先不知道的、但又潜在有用的信息和知识的过程[5]。分类是数据挖掘的常用模式之一,是指把数据样本映射到一个事先定义的类中的学习过程,由一组输入的描述属性值和相应的类标组成。
本研究利用某三甲医院HIS中剖宫产病人的用药数据,结合病情、诊断、手术等可能影响抗菌药物使用的临床数据,对剖宫产抗菌药物预防性使用情况进行分析,基于数据挖掘中的分类技术, 利用数据挖掘软件SPSS® Modeler,建立分类模型,挖掘影响抗菌药物使用模式的变量因素,为针对性地加强围手术期抗菌药使用的决策和干预提供依据。
1 数据来源
在某三甲医院2009年出院病人中,获取进行“子宫下段剖腹产术”的全部807例病例,排除在住院期间还接受其他手术的病例20例,余下787例为本次研究的对象。采集787例剖宫产手术病人的基本信息和诊断、手术、医嘱等数据,归纳为3类(常规、诊查、手术)21种因素,作为分类预测变量。
2 研究方法
2.1数据预处理 对原始数据中预测变量(描述属性)进行数据转换。每个描述属性(分类预测变量)指标数量化。对数字连续型变量,如“年龄”和“孕周”参考产科妊娠评分指标[6]进行离散化。
2.2目标变量(类标属性)分类标号确定 以抗菌药物预防使用作为分类挖掘的目标变量(类标号属性)。根据《剖宫产手术围手术期预防用抗菌药物管理实施细则(征求意见稿》,总结剖宫产手术预防性使用抗菌药物的品种和方法见表1。
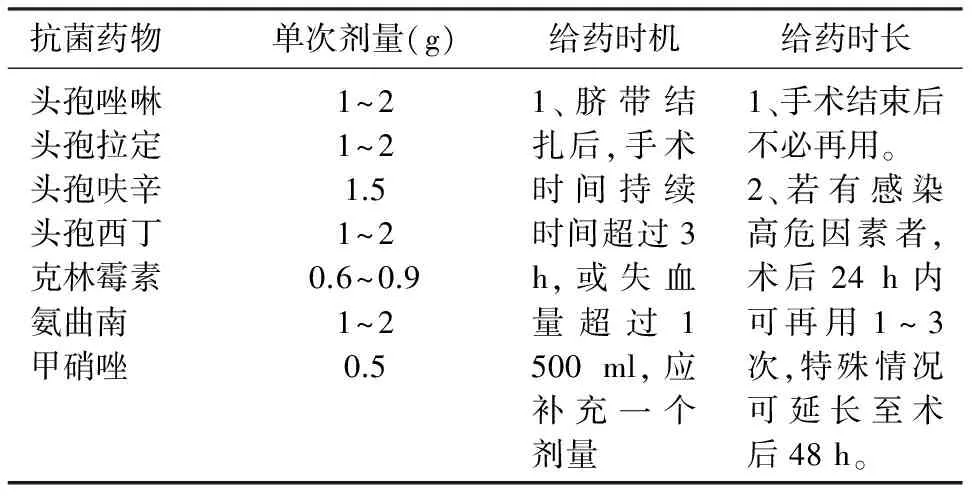
表1 剖宫产手术常用预防性抗菌药物和静脉给药方法
由于“剂量”、“给药途径”及“给药时机”上各病例间基本一致,因此主要从“选用品种”及“给药时长”角度进行比较和判别。 “选用品种”或“给药时长”两项均“符合标准”,则定义该病例抗菌药物预防性使用整体“符合标准”;“选用品种”或“给药时长”两项任一项不符合,则定义该病例抗菌药物预防性整体“不符合标准”,分别赋值“0”和“1”。
2.3预测变量的初步筛选 使用特征选择算法来缩小预测变量的选择范围,识别分析中重要的字段。通过将注意力迅速集中到最重要的字段上,可以降低所需的计算量,最终获得更简单、精确和易于解释的模型。
2.4训练样本和测试样本的确定 采用K-折交叉验证(K>2)的原理,将样本集随机分成3个样本数基本相同且互不重叠的子集。依次取1个子集为测试集,其余2个子集合并为训练集合,获得3组训练测试数据。每种模型都采用这3组数据进行训练和测试。
2.5分类模型建立与评价 采用决策树模型(C&RT、CHAID、QUEST,C5.0算法)、神经网络、贝叶斯网络和Logistic模型建立分类模型,观察各预测变量的相对重要性。
2.5.1准确性评价 准确性是指挖掘模型与所提供数据中的属性的相关联程度,即采用这个算法所获的模式(知识)对样本进行判别分类结果的正确性,常用准确度(accuracy)或曲线下面积(AUC)衡量。
2.5.2有用性评价 有用性反映了模型是否提供有用信息的各种指标,体现了对业务的优化能力,可用提升指数(lift)衡量。
2.5.3可靠性评价 可靠性指当提供不同的测试数据时,挖掘模型表现出稳定预测结果的能力,即对训练样本进行判别的准确率与对测试样本进行判别准确率的一致性。定义可靠因子R(reliability)[7]。

R越接近1,表示算法所获模式的可靠度高。由于很难推测未知样本的概率分布,所以实际计算中采用r近似于R:

3 研究结果
3.1数据预处理结果 787例行“子宫下段剖腹产术”的病例在围手术期间全部使用抗菌药物,对照前文所述的抗菌药物合理使用的标准,符合标准的700人(88.95%),不符合标准的87人(11.05%)。经预处理的预测变量及目标变量汇总见表2。
3.2特征筛选结果 经运行Modeler中的特征筛选节点。“serious_cond”等6个字段因单个类别过大被筛除; “charge_type”等5个字段因重要性偏低而被筛选,保留剩余的“重要”的“blood_lossed”等10个字段作为下一步建模的预测变量。
3.3分类模型评价
3.3.1模型准确性比较结果 总体来看,各模型在训练中的准确率差别不大,平均都在91%以上,贝叶斯网络、神经网络和Logistic回归的平均准确率超过92%;但在测试过程中,各模型表现的准确率有所差别,最低的为贝叶斯网络, 其次神经网络模型的测试准确率也低于90%,最高的为CHAID,为91.61%。

表2 变量指标与赋值

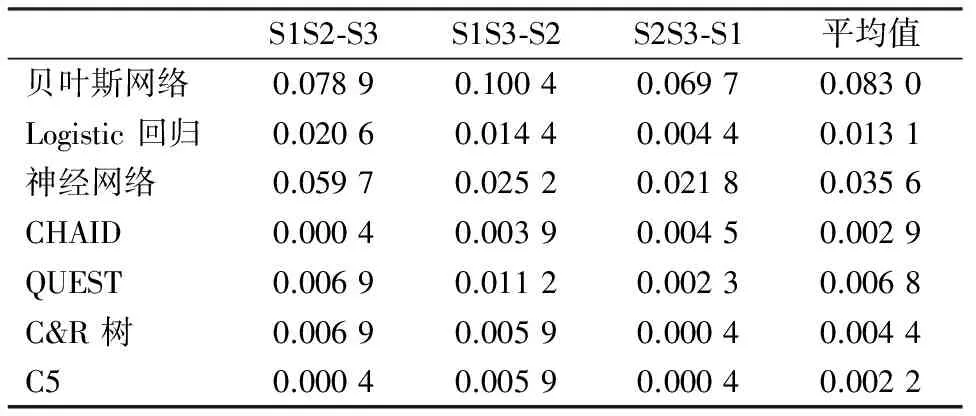
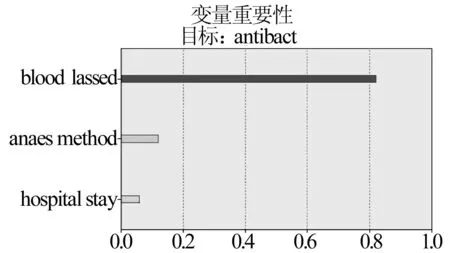
变量代码变量标识值标识变量值2000<4blood_lossed失血量(ml)≤2001200 表3 各模型训练与测试样本分类平均准确率汇总比较 从各模型的ROC曲线下面积来看(表4),贝叶斯网络,Logistic回归,神经网络平均在0.80以上,CHAID平均为0.79,接近0.80。 表4 各模型ROC曲线下面积 3.3.2模型可用性比较结果 由表5可见,贝叶斯网络,神经网络, Logistic回归提升指数较高,分别为5.92,5.50,5.03。 表5 各模型提升指数 3.3.3模型可靠性比较结果 由表6和表7可知,7种模型的可靠因子都在0.92以上;决策树的4种模型可靠因子与1最为接近,均在0.99和1之间;其次是Logistic回归,为0.989 8;神经网络为0.964 4;贝叶斯网络最低,为0.921 1。 表6 各模型可靠因子 表7 各模型的︱r-1︱ 综合准确性、可用性和可靠性,从中选择并使用贝叶斯网络,logistic回归和CHAID3个模型。 3.3.4变量重要性选择结果 变量重要性图表显示预测变量的相对重要性,并且考虑到预测变量的交互性和相关性。在本研究中,变量重要性表示变量对剖宫产围手术期抗菌药物使用情况影响的程度。 贝叶斯网络、logistic回归和CHAID模型的变量重要性如图1~图3所示。贝叶斯网络模型所选择的10个变量字段中,除了“attending_doctor”(主治医师)和“anaesthesia_method”(麻醉方式)变量重要性较低,其余变量重要性差别不大,因此模型的说服力不够强。 图1 贝叶斯网络模型变量重要性 Logistic回归建模采用前进法,得出模型的变量重要性见图2,,共有3个变量,以“blood_lossed”(失血量)重要性最高,其次为“attending_doctor”和“anaesthesia_method”,其余变量重要性较低。最终Logistic模型中包含了“blood_lossed(失血量)”和“anaesthesia_method”两个变量, “blood_lossed”的影响更明显。结合发生比可知,失血量在200和400 ml,其发生比为失血量200 ml以下的3.678倍,即失血量多更容易引起抗菌药物的使用超出标准。 图2 Logistic回归模型变量重要性 CHAID只选择了3个变量(图3),其重要性由高到低分别为,“blood_lossed”、“anaesthesia_method”和“hospital_stay”。 由CHAID生成的决策树结构见图4,由于研究更为关心的是抗菌药物使用“不符合标准的”,表明当手术失血量大于2(大于400 ml),有 85%可能引起围手术期抗菌药物预防性使用超过规定范围。综合3种模型分析,“blood_lossed”是剖宫产手术抗菌药物预防性应用影响程度最大的因素。 图3 CHAID模型变量重要性 图4 CHAID模型生成的决策树 以上结果可以提示,利用数据挖掘中的“分类”技术,可以快速地建立具有一定准确性、可用性和可靠性的,反映剖宫产手术抗菌药物预防性使用的分类模型,从中区分出可能出现“不符合标准”使用抗菌药物的病例。建立的模型提示:在没有进一步人为教育或干预措施下,在样本医院剖宫产手术中,失血量较多的患者更有可能在预防性使用抗菌药物时,在用药品种或者用药时间上,超出正常合理用药的需求。如果有下一步的针对剖宫产手术抗菌药物使用的教育或干预计划,对于失血量较多的病人应重点关注。 4.1住院病人的药物使用情况与其他临床数据密不可分,即使意识到这点,由于临床数据的复杂性、数据来源的多样性以及分析方法的缺乏,目前国内在结合具体病例诊断、手术等临床数据的前提下开展药物利用分析或研究的报道仍罕见。本研究是利用数据挖掘技术,针对住院病人的用药数据进行分析利用的探索性研究。是对医疗机构住院病人相关药物利用信息分析方法尝试与创新,为药物利用研究的深入开展提供新的思路,有助于从当前海量的医疗数据中获取有用的知识。 4.2当前,对抗菌药物使用的分析,已经从最初的使用品种、金额、限定日剂量等以“药物”为中心的总体性指标向以“病人”为中心的合理性研究转变。由于病情的复杂性以及医疗环境的特殊性,对药物的使用作出是否合理的评价应该全面而且慎重,并且需要足够的专业知识。因此,本研究在设定抗菌药物预防性使用的分类时,没有直接对合理性作出结论,而代之以“符合”或“不符合”标准来进行分类。 4.3本研究建立的模型发现“失血量”因素是影响该医院剖宫产围手术期抗菌药物使用的重要因素,提示可能由于失血较多,影响了病人的生理病理情况或医生对病情的判断,使医生倾向于超标准地使用抗菌药物。不同的模型还表明其他因素,如麻醉方式、住院时间、主治医生等对抗菌药物的使用有影响。这些“发现的知识”需要利用专业知识进一步筛选,评价和解释。通过分类模型建立以及变量重要性的获得,便于对抗菌药物使用容易出现“不符合标准”的病例进行重点监测和及时干预。 4.4数据挖掘进程需要不断的循环和深入。本研究数据来源于1家医院1年的病例,得出的结论也较为粗浅。为了增强模型的说服力,有必要采用多个样本医院的数据加以综合。此外,仅通过“失血量”和“麻醉方式”来预测分类也是不全面的,还应考虑其他因素,使模型更加完善。 [1] 王敬花.剖宫产围术期抗菌药物的使用干预与分析[J]. 中国医院用药评价与分析,2010,10(8):688. [2] 张 奕,李润萍,孟繁星.我院剖宫产手术预防感染应用抗菌药物的合理性分析[J]. 实用药物与临床,2010,13(3):218. [3] 姜 涛.785例产妇抗菌药物应用的合理性分析[J].中国医院药学杂志,2010,30(10):884. [4] 孟现民,丁天然,张 莉,等.HBsAg阳性孕产妇剖宫产术抗菌药物预防用药调查与分析[J].中国药物应用与监测,2010,7(1):29. [5] 傅 翔,陈盛新,杨樟卫.数据挖掘在合理用药信息分析中的应用[J].药学实践杂志,2009,27(6):411. [6] 李小毛,段 涛,杨慧霞主编.剖宫产热点问题解读[M]. 北京:人民军医出版社,2008. [7] 叶晨洲,杨 杰,耿道颖.应用数据挖掘技术从大脑胶质瘤病例中获取诊断知识[J].生物医学工程学杂志,2002,19(3):426. Dataminingofantibioticprophylacticuseforcesareansectionpatients FU Xiang1, YANG Zhang-wei2, CHEN Sheng-xin3, CHEN Chang-hong4, HE Yu-tao4 ObjectiveTo establish, compare and evaluate the classification models of antibiotic prophylactic use for cesarean section patients for the targeted intervention in future.MethodPASW® Modeler 13 was applied to establish classification models and to get the influential variables (clinical factors) in antibiotic prophylactic use.ResultWith the data of 787 cases, the classification models were established, in which, Bayesian networks, logistic regression and CHAID were better. In 21 clinical factors,bloodlosswas the most influential variable.ConclusionThe data mining technique was able to quickly create models reflecting the use of prophylactic antibiotics use for cesarean section, which would provide a new analysis tool for drug use survey. data mining;antibiotics;cesarean section R95 A 1006-0111(2012)02-0109-06 10.3969/j.issn.1006-0111.2012.02.009 2011-10-08 [修回日期]2011-12-29






4 讨论
(1. Department of Pharmacy and Medical Appliances, Hangzhou Sanatorium of Nanjing Military Region, Hangzhou 310000, China; 2. Department of Pharmacy, Changhai Hospital, Shanghai 200433, China; 3. Department of Pharmacy Administration, School of Pharmacy, SMMU, Shanghai 200433, China;4. Department of Information, Changhai Hospital, Shanghai 200433,China)
