R语言在数据预处理中的开发应用
2012-10-08肖颖为
肖颖为,葛 铭
(杭州电子科技大学信息与控制研究所,浙江杭州310018)
0 引言
目前数据的主要研究方向集中在挖掘技术和算法领域,但现实中的数据错综复杂,对数据的业务理解因人而异,数据源不统一,系统故障,操作不规范等等原因数据将不可避免的存在缺失数据、冗余数据、不一致数据等情况,这些“脏数据”将极大影响整个数据挖掘的建模过程导致错误的模型[1]。大量实践证明,在数据挖掘系统中,数据前期的理解和预处理阶段要花费60%左右的时间,要得到一个准确的模型,高质量的数据是必不可少的,所以在建模前期如何提取数据元信息,如何与专家和业务人员沟通来理解分析数据是非常重要的。而统计方法是强有力的诊断分析工具,能以此来促进挖掘模型中的参数估计、变量的假设检验和其他此类方法的发展[2],为此,本文提出引入目前在统计学领域发展最快的R语言工具来辅助对数据的理解和预处理,参考业内公认的商业数据挖掘模型CRISP-MD,搭建了一个简单的分析流程,并使用某家电信公司的客户数据进行测试分析,并取得了良好的分析效果。
1 R语言特征
R是一种为统计计算和图形显示而设计的语言环境,是贝尔实验室的Rick Becker,John Chambers和Allan Wilks开发的S语言的一种实现。其主要特点是具备一系列连贯而又完整的数据分析中间工具,拥有一整套数组和矩阵操作运算符能有效地处理保存数据,其图形统计功能可以对数据直接进行分析和显示,加上R是一种面向对象的可编程语言,和其它编程语言、数据库之间有很好的接口[3]。R还是免费开源软件,并且有强大的社区资源,提供了非常丰富的程序包,有很多专家、贡献者提供学习指导、前沿领域的探讨。
现有的ELT工具能够提供一般化的预处理功能,但灵活性不足,而独自开发ELT工具又要面临开发时间长,费用过高的问题,引入R来分析数据并且实现数据预处理可以灵活地定制需要的数据来实现挖掘,R有强大函数拓展包和图像展示功能,可以方便快捷地提供数据信息并且进行数据处理,这个过程提供了良好的互动环境使得业务人员和专家的参与,为之后的模型设计和选择提供了良好的支持。目前R在统计学领域和数字分析领域是增长最快的工具,在国外被广泛应用,在国内尚处于发展期,按如此趋势未来R的应用面将越来越广。
2 数据理解和数据准备功能设计
本文提出的一个思路是将数据预处理的一系列方法流程化,通过数据输入,数据反馈输出来进行互动式的数据理解和数据准备,这可以为真正需要进行的数据的预处理提供决策支持。流程图如图1所示:
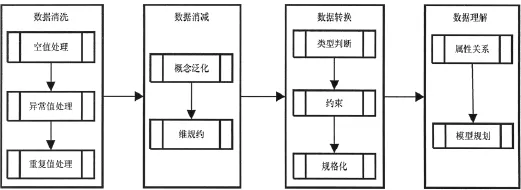
图1 数据预处理流程图
2.1 数据清洗
空值处理,统计每个属性空值的个数和占总样本数的百分比,统计每个缺失样本的缺失属性个数并且按大到小排列,一般来说若属性空值个数占整体样本数的比例比较大时可以考虑删除此属性,而各属性空值过多的样本也可以考虑删除。
检测重复值,主要针对离散型变量,统计每个离散因子的出现次数并画出整体的直方图,统计因子占整体样本数的百分比。
检测异常值,对于离散变量来说异常值可能是出现次数比较小或者特别大的一些因子这需要根据具体业务来判断。对于单一连续变量用K均值的聚类算法自动识别可能的异常值,K均值算法实现如下:
首先从n个数据中任意选择k个作为初始聚类中心;对于剩下的其他数据,根据它们与聚类中心的距离(相似度),分别将其分配到距离最近的聚类中心所代表的聚类中;然后重新计算每个新聚类的聚类中心(所有该类的均值);不断重复这个过程直到标准测度函数开始收敛为止。一般会采用均方差作为标准的测度函数,具体定义如下[4]:

式中,E为所有数据对象的均方差之和,p为代表对象空间的一点,mi为聚类ci的均值。
2.2 数据消减
泛化处理,所谓泛化处理就是用更抽象的概念来取代低层次或数据层的数据对象,如年龄属性,可以映射到更高层次概念,如:青年、中年、老年。为这里需要设计一个映射,能把低层次的数据对象映射到高层次的概念上来。
维规约,即为属性消减,对于相关性过高或者提供信息量过少的属性可以考虑消除,这样可以提高数据挖掘算法的效率,节约时间,提高准确率。因此除了引入统计学中的相关性检验外还加入基于熵的离散化方法来对属性进行维规约分析如[5]:

式中,A1和A2为A的一个划分且分别满足条件:A1<T与A2>T。熵函数可以根据所给集中的不同类别数据行分布情况计算获得。如给定m个不同类别,A1的熵就是:

式中,pi为Ai中类别i的出现概率。该值可以通过A中类别i的行数除以A1中数据行的总数而得到。Ent(A2)的值也可以类似方法计算获得。
2.3 数据转换
类型判断,一般来说数据可以分成间隔、二值、符号、顺序、比例5种类型来进行分析处理,间隔数值属性就是基本呈直线比例的连续测量值。典型的间隔数值有:重量、高度和温度等。一个二值变量仅取0或1值,其中0代表(变量所表示的)状态不存在,而1则代表相应的状态存在。符号变量是二值变量的一个推广。符号变量可以对两个以上的状态进行描述。例如:颜色变量就是一个符号变量,它可以表示五种状态,即红、绿、篮、粉红和黄色。一个离散顺序变量与一个符号变量相似,不同的是(对应N个状态的)的N个顺序值是具有按照一定顺序含义的。一个比例数值变量就在非线性尺度上所获得的正测量值。对属性类型有个正确的判断将极大方便数据挖掘算法的选取[6]。
约束,对数据处理来说,需要引入业务理解的内容,能够通过业务人员和专家对数据进行取舍,为此,对于每个属性引入限制条件对数据进行约束达到符合现实的目的。
规格化,规格化将一个属性取值范围设在一个特定范围之内,以消除数值型属性因可能存在的大小不一的情况而造成结果偏差。
2.4 数据理解
属性关系,对于没有缺失值的离散变量进行做交叉表进行Pearson χ2检验分析在置信度为0.05的情况下判断属性之间是否存在相关性,而对于没有缺失值连续变量做相关系数矩阵分析相关性。
分布特征,对于离散变量来说统计因子个数和统计量并做直方图可以快速发现出现次数最多的点及可能存在的异常因子,而对于连续变量求其平均值,中位数,众数,方差,标准差,变异系数,峰度系数,偏度系数等变量信息。
通过R对每个数据项(变量)实现上述基本分析,对于每个数据项都建立一个元数据列表综合上述功能的所有统计信息,从其数据特征到与其他变量可能存在的相关性等信息都可以通过这个列表查看,同时配上可视化图来理解数据项。
3 对于电信业客户数据的分析
主要抽取了电信数据的2张表组成探索型数据集:
账户表。存放所有客户的基本信息,包括13个数据项,其中与分析主题有关的有8个数据项:客户ID,城市,省份,邮编,激活时间,账户收支,出生时间,信用等级;
账单表。记录客户每月账单情况,包括5个数据项:客户ID,账单日期,通话费,增值业务费,互联网使用费,总费用;
数据经过处理后,可以得到一系列数据项的元数据属性。其中在账户表中的账户收支中,一共822个数据。在数据清洗阶段,通过编写的空值统计函数得到此数据项有6个空白值,但占总数量的0.007,可以考虑删除。
用R语言开发的异常值处理模块,可发现可能存在的异常值,主要通过聚类分析方法处理每个变量;在重复值方面,账户为零出现的次数最多有715次,其他重复值出现次数较少,结合具体业务来说并无特别发现。
在数据消减方面,将出生时间进行数据清洗后,转化为青年,中年,老年3个等级来进行分析,而通过信息熵分析发现城市、省份、邮编对信用等级影响很小可以考虑规约到特征变量省份中来。数据消减流程全用R语言代码编写的函数实现,相比于Excel和数据库处理数据清洗流程,R实现的速度更快更灵活,可复用性也强。
在数据转换中,根据实际业务情况,可以判断分析出属性的类型,设定相关约束,排除些超过约束的样本,对连续数据的属性进行规格化处理以便为之后数据挖掘算法服务。
在数据理解阶段,通过前面一系列的处理,通过R语言编写的程序包可以十分便捷的观察样本与样本间的关系,变量与变量间的关系,可能存在的分布特征。
4 结束语
R工具的优点在于灵活性,可以快速地根据具体情况来增加功能,对于数据挖掘来说是个强大的数据分析工具,本文利用R开发了前期数据理解和准备阶段的辅助分析工具,整合一套自动的系统流程工具能够提供给业务人员和专家对数据进行分析,并且可以根据具体需求调整,增减功能使建模过程更加准确可靠,在之后的开发中可以根据实际需求引入更多的统计学方法来支持挖掘任务,如PCA分析、因子分析等,可以拓展的空间非常大。
[1]David Olson,Yong Shi.吕巍译.商业数据挖掘导论[M].北京:机械工业出版社,2007:41-42.
[2]刘莉,徐玉生,马志新.数据挖掘中数据预处理技术综述[J].甘肃科学学报,2003,15(1):117-18.
[3]陈希.基于R语言数据挖掘的社交网络客户细分研究[D].北京:北京邮电大学,2011:34-40.
[4]J.MacQueen.Some methods for classification analysis of multivariate observations[M].Los Angeles:University of California Press,1997:281 -289.
[5]W.Buntine.Learning classification trees.In Artificial Intelligence Frontiers in Statistics[M].London:Chapman&Hall,1993:182-190.
[6]Richard Roiger,Michael Geatz.数据挖掘教程[M].北京:清华大学出版社,2003:1 -8.
