基于索引路径的深度网页数据抽取改良
2012-09-30乐丁惕
乐丁惕
(闽江学院 计算机科学系,福建 福州350108)
随着Internet和通信技术的快速发展和广泛普及,Web页面数量急剧增加,已成为人们获取信息的主要渠道之一.目前,主流的搜索引擎基本上只收集了Internet上的静态页面(Surface Web),而这些静态页面只是其中小部分信息,其余大部分信息存放于Web中的在线数据库,对传统的搜索引擎是不可见的,这部分信息称为深度网页(Deep Web)[1].
Deep Web信息集成系统是为了有效利用海量的Deep Web信息而提出的解决方案,Web数据抽取是Deep Web信息集成系统的关键,是指通过技术手段将Web页面上的数据抽取出来,保存为XML文档或关系模式[2].对DEIP(Data Extraction based on Index Path)算法进行了改进,首先将Deep Web查询结果页面规范化为XML格式,然后在遍历XML文档的过程中确定待抽取数据路径集合,最后根据该集合完成数据抽取.
1 数据规范化
Web数据抽取是指将Web作为信息源,把分布在其上的用户感兴趣的查询结果抽取出来[3].然而,由于Web文档普遍是由半结构化标记语言HTML组成的,其语法规则比较宽松,且网站往往会在网页中加入大量的修饰性属性.因此返回的网页文件无法直接用于数据抽取,需要进行预处理:
1)补全未配对的tag;
2)滤掉修饰性属性.
以上过程称之为数据规范化,获取更易于数据抽取的XML文件.
2 DEIP算法
不同的网站,其页面布局风格往往有极大的差异,有效数据的存储位置也大不相同.但对于同一个网站而言,输入关键词后其返回的不同页面中,有效数据的存储位置是相同的.换句话说,对于同一个网站返回的动态页面,其主要数据是存放在同一个tag中.只要找到这个tag在网页中的“位置”,就能对该网站的所有动态网页自动地进行数据抽取[4].
DEIP算法的具体过程及说明如下:
输入:由HTML网页文件转换成的XML在内存形成的DOM树.
输出:所有记录的索引路径.
步骤1 深度优先遍历DOM树,为每一个Text结点建立索引路径;
步骤2 确定候选数据区.
假设输入N个关键词Key1,Key2,…,KeyN,将它们逐个与步骤2中的每一个Text结点的内容进行匹配,筛选出所有包含这N个关键词的索引路径,假设一共找到了K(K≥N)条,分别计作:IPath[1],IPath[2],…,IPath[K][5].
此处存在2种情况,一种是只找到K=N条索引路径,即符合所有关键词的记录各有1条,这K条索引路径处于DOM树中同一个数据记录子树中;另一种是找到了K>N条索引路径,即符合所有关键词的记录数不止1条,一般情况下,这K条索引路径处在不同的数据记录子树中,具体如下:
1)K=N 时,确定 IPath[1],IPath[2],…,IPath[K]的最大公共前缀结点 Nj,计算 Nj的兄弟结点的个数countsibling(Nj),如果countsibling(Nj)<Crecord(指网站返回的一个页面中的记录数),继续向上找其父结点Nj.parent,直至 countsibling(Nj.parent)> Crecord.结点 Nj或 Nj.parent就是主数据区所在子树的根节点.
2)K=N 时,确定 IPath[1],IPath[2],…,IPath[K]的最大公共前缀结点 Nj.结点 Nj就是主数据区所在子树的根结点.
步骤3 确定最佳数据区.
在确定候选数据区后,考虑到数据区子树中可能会包含噪声数据,会影响到数据抽取的准确率,所以需要再次匹配关键词去掉噪声数据,确定最佳数据区.本步骤也有2种处理方式:
1)当K=N时,判断Nj或者Nj.parent和它们的兄弟子树是否包含关键词,如果包含,将其子树下的所有文本抽取出来,并将这些子树的根结点的索引路径存储下来,否则直接丢弃.
2)当K>N时,判断Nj的各个孩子结点Nj.children子树是否包含关键词,如果包含关键词,将其子树下的所有文本抽取出来,并将这样的孩子结点Nj.children的索引路径存储下来,否则直接丢弃[6].
3 DEIP算法举例
如图1所示,图中Table,TR,TD结点表示元素结点,D+数字节点表示Text节点.

图1 XML文档片段的DOM树
图中部分标记对应的XML片段如下:

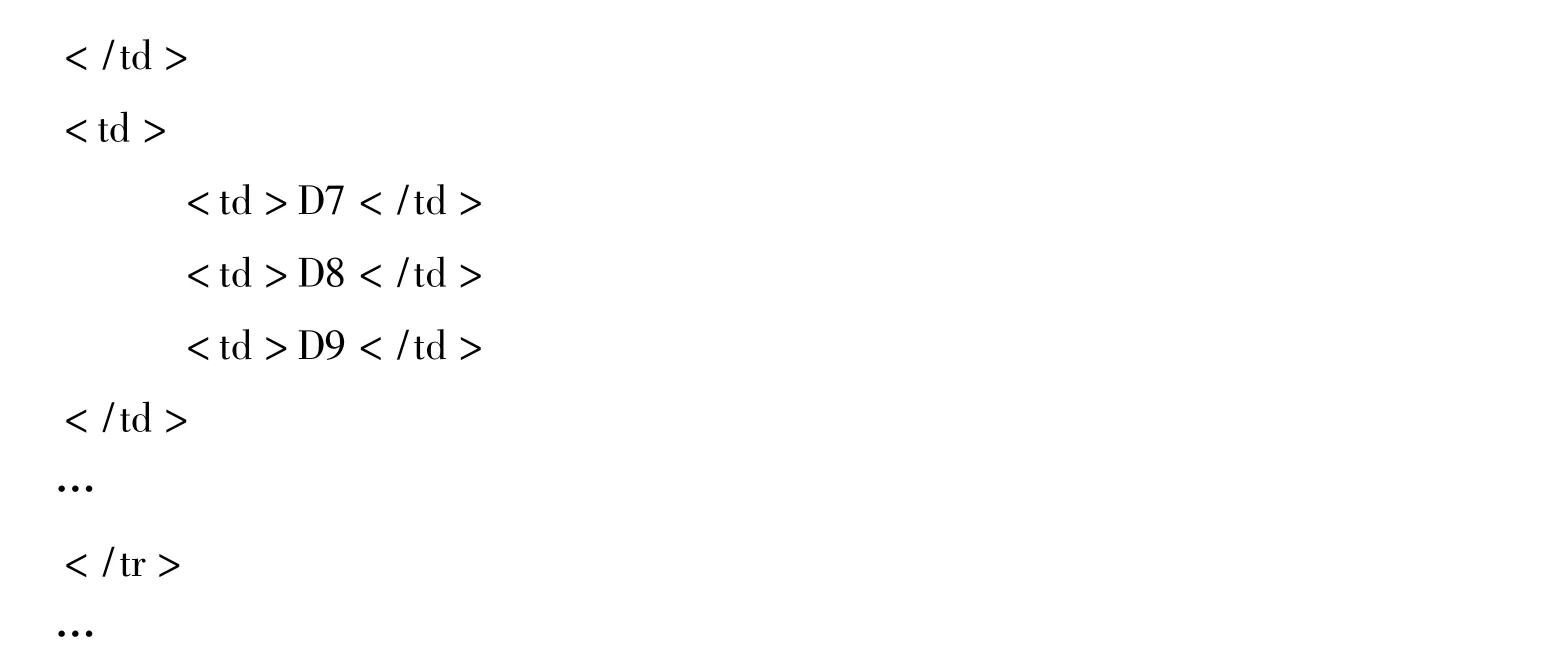
设共有2个关键词Key1,Key2,结果页面中的数据记录数Crecord=10.此处仅说明K>N时的情况:
假设包含 Key1 的有 D1,D3,D4,D7,D10,包含 Key2 的有 D2,D5,D8,D11.
步骤1 获得9条索引路径,分别为:

存放于索引路径数组L中.

步骤2 此时K>N,故直接求取9条索引路径的最长公共前缀maxPrefix,得到

则maxPrefix即为候选数据区根结点的索引路径.
步骤3 对候选数据区进行除噪处理.
判断table的各个孩子子树是否包含Key1或Key2,若包含,则记录下该子树根结点的索引路径,否则直接丢弃.得到

这3条索引路径即为网站的包装器Wrapper.
4 DEIP算法的不足及改进
仅从HTML代码的角度考虑,算法的执行结果覆盖了所有关键词存在的区域.然而,在现实世界中,能够与关键词匹配的数据未必就是有效数据.用户上网查询信息时,是通过输入1个或多个关键词来描述某领域的一类事物的.这些关键词相互关联,输入的关键词越多,对该事物的描述就越细.因此,在反馈给用户的结果网页中,关键词也应以组合的形式存在.
定义1 记录Record 即返回页面中的一组数据.这组数据在网页中相邻或相近存放,且应包含用户输入的所有关键词至少各一次.记录是描述用户想要获取的信息的最小单位,可由其包含的各个关键词在DOM树中的深度及各个关键词之间的相对位置关系组成.
特别地,在网页中往往存在一些无用的零散数据,包含了部分的关键词.而多个零散数据组合在一起,便形成了一条伪记录.
定义2 有效数据 即用户在返回的网页中希望看到的数据信息.记录中的数据,即为有效数据.而一些分散在网页中的数据,即使能够匹配部分的关键词,也不一定是有效数据.
定义3 主数据区 有别于前文中数据区.若一网页文件中仅存在1个数据区,或有1个数据区的记录数比其他数据区都要多,则称之为主数据区.主既表示该数据区拥有网页中最丰富的有效数据,也表示这是用户本次查询的主要结果.
以百度搜索为例,其返回的网页中数据主要分布在2个数据区中,如图2中所示.
若用户输入Keyword,其期望看到的是DataArea1中的数据,而不是DataArea2中的数据.

图2 百度搜索数据区
DEIP算法在纷繁冗杂的网页文件中找到了稳定存在的数据区,从而实现了对特定网站的一次生成,自动抽取,这是一个简洁而极富创意的算法.然而,该算法中不存在记录这一定义,更准确地说,所有能够匹配关键词的信息都是有效数据.由于算法的执行是基于DOM树进行的,无法识别无用的零散数据,使得实际上找到的数据区根结点在DOM树中的层次比实际层次小得多,因而包含了大量冗余信息.
分析DEIP算法中的步骤1可以发现,笔者指定要求深度优先遍历是有原因的.根据上述定义可知,记录和伪记录的区别在于其包含的N个关键词在网页中的分布情况,记录中各个数据均相邻或相近存放,作为数据的整体被<Div></Div>或<Table> </Table>包围(即记录中的Text节点均在同一子树中),而伪记录中的数据则无规律地分散在整个网页中.深度优先遍历使得处于同一数据区的记录在数组中相邻存放,同一条记录中的Text节点索引路径也在数组中相邻存放,可以将网页中的数据集散情况体现到Text节点索引路径数组中.由于去掉了所有不匹配关键词的Text结点,记录定义中的有效数据相邻或相近存放在数组中可简单地认为是相邻存放,因而可以通过遍历索引路径数组来区分记录和伪记录.为便于比较,改进算法仍然采用DEIP算法中的示例XML代码,具体如下:
对索引路径数组L进行遍历.
由于D1匹配Key1,D2匹配Key2,且二者相邻存放,说明此时已找到了一条记录.将该记录中各关键词的相对位置保存起来,此处为

Deep是求取结点在DOM树中深度的函数.Key1Pos,Key2Pos和relativePos就组成了当前数据区中记录的模版.
D3匹配关键词Key1,说明此时可能进入了另一条记录中,也可能D3只是无用的零散数据.继续向前,D4同样匹配Key1,表达了2个信息:
1)D3是无用的零散数据;
2)已离开当前记录模版能表示的范围.
忽略D3,继续向前遍历.D5匹配关键词Key2,说明又找到了一条记录.同样记下当前记录模版,
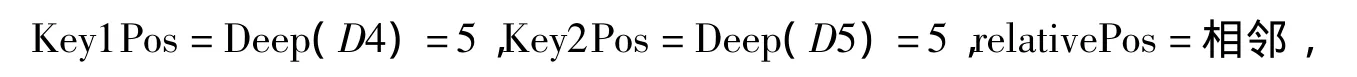
D7匹配 Key1,D8 匹配 Key2,且
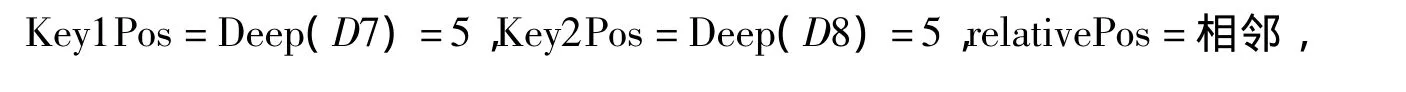
同样地,D10匹配Key1,D11匹配Key2,

3条记录均可由同一记录模板描述,因此这3条记录处于同一数据区中.
综上所述,共得到2个记录模板,即得到了2个数据区,DataArea1:D1,D2;DataArea2:D4,D5,D7,D8,D10,D11.
由于DataArea2中的“记录”数多于DataArea1,故其为主数据区,其索引路径为其中所有索引路径的最长公共前缀,
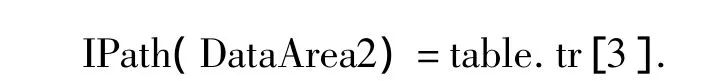
在步骤3中,对主数据区进行除噪操作,得
相比DEIP算法,获得的包装器更加精确,且仅包含有效数据.
5 小结
将用户角度的需求与具体的网页文件结构相结合,通过对有效数据记录的形式化定义,构建出由小整体到大整体、逐步获取网页中数据的模式,在此基础上给出了DEIP的改进算法.本文提出的数据抽取机制不仅解决了原算法对网页的高冗余,更使得抽取出的数据按记录存放,各归其位,为之后的语义标注等工作提供了极大的方便.
[1]GHANEM ,M T AREF W G .Databases deepen the Web[J].IEEE Computer,2004,73(1):116 -117.
[2]马安香,张斌,高克宁.基于结果模式的Deep Web数据抽取[J].计算机研究与发展,2009,46(2):22-23.
[3]单菁,王习特,刘桐.支持Deep Web数据库集成的图书搜索系统[J].计算机研究与发展,2011,48(Z2):33-34.
[4]魏永刚,袁方.Deep Web数据抽取及语义标注研究[D].保定:河北大学,2010.
[5]YUAN L,LI Z H,CHEN S L.Ontology-Based annotation for Deep Web data[J].Journal of Software,2008,19(2):237 -245.
[6]SAHUGUET A,AZAVANT,F.Building intelligent Web applications using lightweight wrappers[J].Data and Knowledge Engineering,2010,36(3):283 -316.
