分布式存储中数据分布策略的分析与研究
2012-09-25陈艳君
庞 慧 陈艳君
(1.河北建筑工程学院,河北张家口075000;2.北京交通大学计算机与信息技术学院,北京100000)
0 论文所要解决的问题
分布式存储系统,就是将数据分散存储在多台独立的设备上.传统的网络存储系统采用集中的存储服务器存放所有数据,存储服务器成为系统性能的瓶颈,也是可靠性和安全性的焦点,不能满足大规模存储应用的需要.分布式网络存储系统采用可扩展的系统结构,利用多台存储服务器分担存储负荷,利用位置服务器定位存储信息,它不但提高了系统的可靠性、可用性和存取效率,还易于扩展.
如何才能最大限度地提高分布式存储系统的容量、可靠性、安全性、数据分布、负载均衡性、可移植性,在数据存储领域中已成为一个急需解决的迫切问题.本课题主要研究合理的分布式存储管理系统的体系结构,分布式数据存储的数据流向与数据负载均衡和系统优化等各方面的关键技术.所得结论使得分布式存储系统更能适应网络存储数据的动态变化,可以更加合理地利用存储设备的磁盘资源.有效地调度系统资源,使服务器的负载趋于平衡,使存储设备的性能得到充分利用.
1 分布式存储中数据分布策略的分析
1.1 分布式存储架构模型:

整个存储架构可以分成三部分:存储客户端、元数据服务器集群以及存储资源池.其中客户端内嵌入用户或者存储应用系统内部,提供与元数据服务器以及存储资源池通信的应用接口,完成客户端与存储系统之间的数据交互功能.由于原型系统对于存储应用接口进行了封装,元数据服务器集群以及存储资源池的底层架构以及工作方式对抗上层客户端是完全透明的,这使得用户无需考虑底层复杂的结构特征,利用简单的接口轻松使用存储资源,开发数据服务应用.元数据服务器集群用来管理用户数据的元数据信息,并且管理数据的存放位置以及冗余策略.元数据服务器对用户提供文件IO,处理来自客户端的文件级操作,并保存关键的元数据信息.存储资源池由多个存储节点构成,主要采用对象存储技术和分布式的架构,完成客户数据的保存,并提供数据的容错,容灾功能.
海量的网络存储系统必须支持在底层存储池变动的情况下保持数据负载的均衡,数据寻址的高效.特别是随着数据量不断增加,网络存储系统面临着不断扩展的压力,对系统的可扩展性提出了要求.所以,为了满足这些技术需求,网络存储系统需要灵活高效的数据分布策略来确保性能.数据分配策略是在数据与存储地址之间建立起高效映射关系的方法,换言之,是将数据合理的分配到存储设备中,并最大限度地简化寻址过程,同时确保存储资源和网络资源的合理分配.
1.2 分布式缓存的问题
假设我们有一个网站,最近发现随着流量增加,服务器压力越来越大,之前直接读写数据库的方式不太合适了,于是我们想引入一种高性能的分布式内存对象缓存系统作为缓存机制.现在我们有两台机器可以作为服务器,如图2所示.

很显然,最简单的策略是将每一次缓存请求随机发送到一台服务器,但是这种策略可能会带来两个问题:一是同一份数据可能被存在不同的机器上而造成数据冗余,二是有可能某数据已经被缓存但是访问却没有命中,因为无法保证对相同key的所有访问都被发送到相同的服务器.因此,随机策略无论是时间效率还是空间效率都非常不好.
要解决上述问题只需做到如下一点:保证对相同key的访问会被发送到相同的服务器.很多方法可以实现这一点,最常用的方法是计算哈希.例如对于每次访问,可以按如下算法计算其哈希值:h=Hash(key)%2其中Hash是一个从字符串到正整数的哈希映射函数.这样,如果我们将服务器分别编号为0、1,那么就可以根据上式和key计算出服务器编号h,然后去访问.
这个方法虽然解决了上面提到的两个问题,但是存在一些其它的问题.如果将上述方法抽象,可以认为通过:h=Hash(key)%N这个算式计算每个key的请求应该被发送到哪台服务器,其中N为服务器的台数,并且服务器按照0–(N-1)编号.
这个算法的问题在于容错性和扩展性不好.所谓容错性是指当系统中某一个或几个服务器变得不可用时,整个系统是否可以正确高效运行;而扩展性是指当加入新的服务器后,整个系统是否可以正确高效运行.
现假设有一台服务器坏了,那么为了填补空缺,要将坏的服务器从编号列表中移除,后面的服务器按顺序前移一位并将其编号值减一,此时每个key就要按h=Hash(key)%(N-1)重新计算;同样,如果新增了一台服务器,虽然原有服务器编号不用改变,但是要按h=Hash(key)%(N+1)重新计算哈希值.因此系统中一旦有服务器变更,大量的key会被重定位到不同的服务器从而造成大量的缓存不命中.而这种情况在分布式系统中是非常糟糕的.
一个设计良好的分布式哈希方案应该具有良好的单调性,即服务节点的增减不会造成大量哈希重定位.
1.3 一种改进的哈希方案
如果将整个哈希值空间假想成一个虚拟的圆环,然后将各个服务器使用H进行一个哈希,具体可以选择服务器的IP或主机名作为关键字进行哈希,这样每台机器就能确定其在哈希环上的位置,这里假设将上文中两台服务器使用IP地址哈希后在环空间的位置如图3所示:

接下来使用如下算法定位数据访问到相应服务器:将数据key使用相同的函数H计算出哈希值h,通根据h确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器.
例如我们有a、b、c三个数据对象,经过哈希计算后,在环空间上的位置如图4所示:
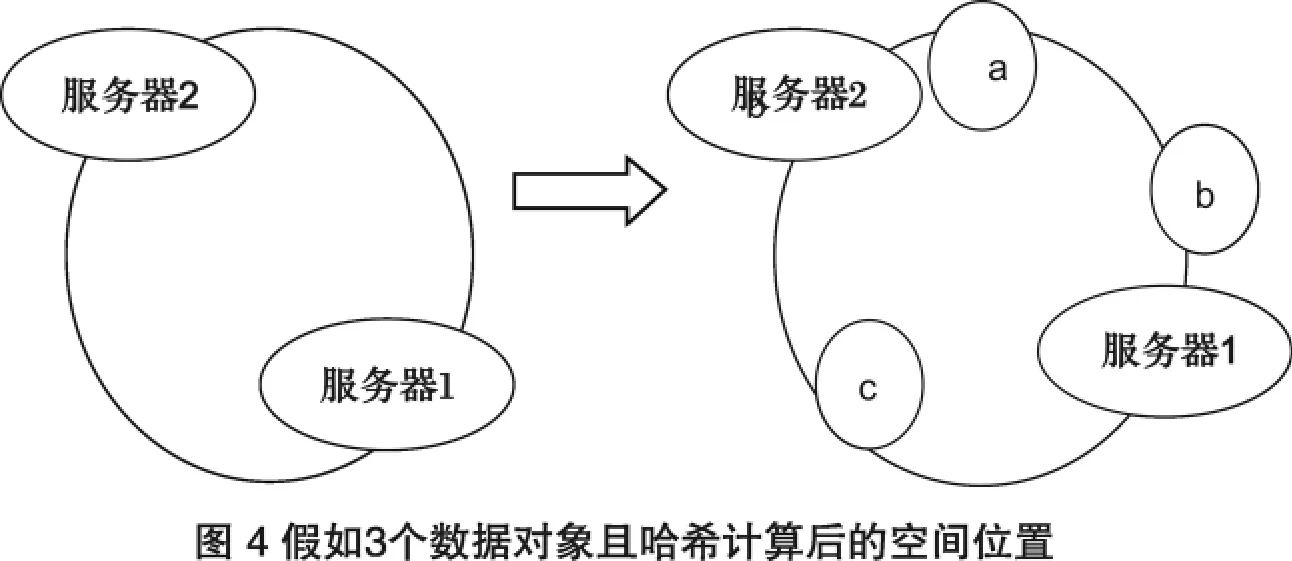
根据算法,数据a,b会被定为到服务器1上,c被定为到服务器2上.现假设服务器1坏了:
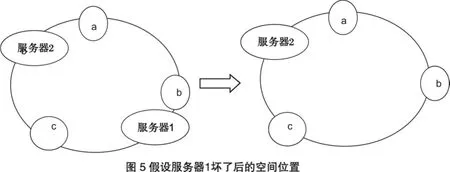
可以看到此时c不会受到影响,只有a,b节点被重定位到服务器2.一般的,在该算法中,如果一台服务器不可用,则受影响的数据仅仅是此服务器到其环空间中前一台服务器之间数据,其它不会受到影响.如果我们在系统中增加一台服务器3:

此时b,c不受影响,只有a需要重定位到新的服务器3.一般的,在一致性哈希算法中,如果增加一台服务器,则受影响的数据仅仅是新服务器到其环空间中前一台服务器之间数据,其它不会受到影响.

综上所述,该算法对于节点的增减都只需重定位环空间中的一小部分数据,具有较好的容错性和可扩展性.但是在服务器节点太少时,容易因为节点分部不均匀而造成数据倾斜问题.例如我们的系统中有两台服务器,其环分布如图7所示:
此时必然造成大量数据集中到服务器2上,而只有极少量会定位到服务器1上.为了解决这种数据倾斜问题,上述算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点.具体做法可以在服务器IP或主机名的后面增加编号来实现.例如上面的情况,我们决定为每台服务器计算三个虚拟节点,于是可以分别计算“服务器1.1”、“服务器1.2”、“服务器 1.3”、“服务器 2.1”、“服务器 2.2”、“服务器2.3”的哈希值,于是形成六个虚拟节点:

同时数据定位算法不变,只是多了一步虚拟节点到实际节点的映射,例如定位到“服务器1.1”、“服务器1.2”、“服务器1.3”三个虚拟节点的数据均定位到服务器1上.这样就解决了服务节点少时数据倾斜的问题.在实际应用中,通常将虚拟节点数设置为32甚至更大,因此即使很少的服务节点也能做到相对均匀的数据分布.
1.4 基于节点容量感知的负载均衡策略
在大多数的存储系统中,随着系统存储设备的更新升级,新加入的节点往往具有更高的带宽,更大的存储空间.而基本的一致性哈希算法所有节点默认为资源对等,地址分配的结果只是满足统计学意义上的均匀分配.所以基本算法的使用环境默认为由同构存储节点构成的存储池,无法再存储资源分配过程中体现存储节点之间的性能差异.
所以,针对该问题,本文在虚拟节点分配方法的基础上,提出了基于节点容量感知负载均衡策略,对分配方法进行优化,提高系统数据分布策略的灵活性,从而提高系统的整体性能.该优化方法的实现基于以下假设:存储对象的哈希值成均匀分布,并且各个存储地址段的存储开销呈均匀分布.优化的基本思想是对每个物理节点的资源进行估计量化,根据整个系统的节点资源情况,对物理节点分配的虚拟节点数进行调整,从而进一步优化物理节点间的负载均衡.对于每个物理节点分配调节因子w,该参数表示该物理节点的资源分配权值,可表示节点的容量或者带宽等,原型系统设计中采用的是对容量资源的量化权值.然后,统计每个物理节点的所分配地址空间的大小s.基于前提假设,s值可以表示该节点所分配存储开销;设P=s/w,作为物理节点资源利用率量化值.系统通过统计计算,获取P的均值,并设定门限值Pmax和Plow,当节点超过门限范围时,采用增加或减少虚拟节点的方法,均衡整个系统负载.图9为该策略具体的实现流程:
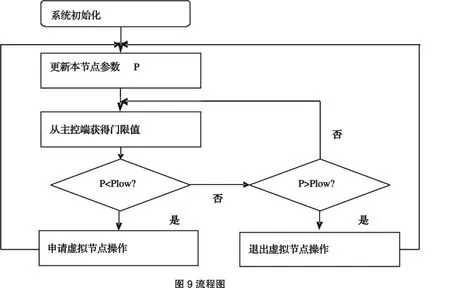
基于节点容量感知的分配策略采用分布式的方式完成,存储资源节点通过主控端获得相关门限值,并计算自身的相关参数,实时比较.当本节点的参数P值小于下限值Plow时,进行申请虚拟节点操作,请求信息被发送到控制端,调用函数完成操作;同理,当本节的参数P值大于上限值Phigh时,进行退出虚拟节点操作.此外,在主控端保存着节点的信息,很容易获得理论均值.门限值的设定采用如下公式:
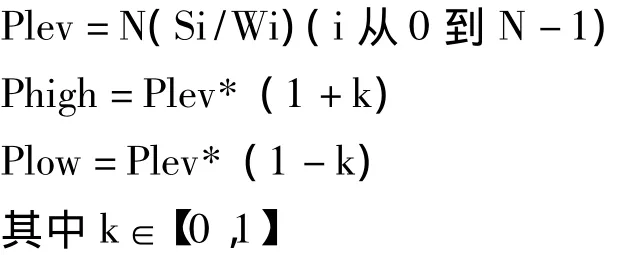
其中:Plev时P的均值;N为物理节点数;S为物理节点所有虚拟节点地址范围之和;W为存储资源标准化权值(例如采用50GB为单位,200GB的节点W值为4,100GB的节点W值为2.值得注意的是:当K过大时,会影响到负载平衡的效果;当K值过小时,会造成虚拟节点的频繁增减操作,甚至造成某些物理节点的虚拟节点数出现“颤动”(频繁来回增减虚拟节点),造成极大地系统开销.此外,K值的极限值与物理节点的个数有一定关系,当物理节点数越多时,k值可以设得越小.
以上便是基于接点容量感知分配策略的实现方法,在前提假设成立的情况下,该方法为系统存储资源的合理利用提供了更加灵活的机制,确保了系统存储资源的负载均衡.
2 结论
本文对分布式存储领域的技术展开了研究,介绍了一种分布式存储的基本架构.该策略以一致性哈希数据分布策略为基础,引入了虚拟化设计思路,采用虚拟节点的分配策略,并分析研究了一种基于节点容量感知的负载均衡方法,有效优化了系统的性能,提高了系统的可扩展性.但是上述负载均衡策略由于算法的缺陷带来过大的负载转移开销,如:由于需要实时比较,主控端必须不停的获取并计算理论均值,并调用函数进行比较,这就必将增加系统的负荷.
既然静态负载均衡策略具有简单易行的优点,动态负载均衡策略具有较好的时间和空间效率,而二者又都具有其弊端,故单独使用某个策略并不能满足所有网络系统的需求.因此我们可以试着动静结合,将这两种策略互相配合使用,或许可以达到更好的效果.下面是一个新的算法设想:
在没有节点加入或退出系统时,我们可以采用普通的静态负载分配算法,在静态负载分配算法中,利用特殊的ID生成算法可有效地为节点均衡分配负载;同时,当网络发生动荡时,即有节点加入或退出系统时,采用特殊的动态负载分配方法来对其进行调整,以最快的速度和最小的转移开销可保证系统负载重新均衡.设想中提出的策略虽有待改进和细化,但我相信在不久的将来必将出现与之相符的详细实用的算法.
[1](美)特尼博姆等著,辛春生等译.分布式系统原理与范型(第2版).清华大学出版社,2008,6
[2]肖迎元.分布式实时数据库技术.科技出版社,2009,6
[3]陆嘉恒.分布式系统及云计算概论.清华大学出版社,2011,5
[4]李明.认识 Linux的磁盘配额.http://blog.chinaunix.net/u3/93755/showart-187
[5]Andrew S.Tanenbaum著,陈向群,马洪兵译.现代操作系统.北京机械工业出版社,2009,7
[6]韦理,周悦芝,夏楠。用于网络存储系统的存储空间动态分配方法.计算机工程,2008(5)
[7]田颖.2003.分布式文件系统中的负载平衡技术研究[D]:[硕士学位论文]北京:中国科学院计算技术研究所
[8]杨德志,许鲁,张建刚.2008.蓝鲸分布式文件系统元数据服务[J].计算机工程:4~9
[9]肖培棕.2009.分布式文件系统元数据负载均衡技术研究与实现[D][硕士学位论文]合肥中国科学技术大学
[10]冯幼乐.2010.分布式文件系统元数据管理技术研究与实现[D]:[硕士学位论文].合肥:中国科学技术大学
