基于千兆网卡的PF_RING功能的分析与设计
2012-09-17刘宝辰
刘宝辰
0 引言
随着计算机网络带宽的迅速发展,对网络流量分析提出了新的挑战。在高速网络环境中,设计流量分析系统的关键是如何高效捕获网络数据包,即能否快速、完整地捕获到所需要的数据包,是准确分析网络数据的基础。在硬件方面,研究人员同硬件生产厂家试图通过专用硬件实现流量监测和分析。当前市场上有很多千兆以太网报文处理网卡,如Endace公司生产的DAG网卡、Liberouter 及SCAMPI 项目开发的 COMBO网卡等。但基于硬件的捕包设备价格比较昂贵,且系统缺乏一定的灵活性,难以适应当今瞬息万变的网络发展现状与具体的流量分析需求。然而使用普通PC机,基于软件进行协议处理的 TCP/IP 协议,使 CPU承担了很大负载并且无法实现多线程或多进程数据包并行处理。在高速网络中,传统的数据包捕获处理模型,已经成为整个系统的性能瓶颈,这是因为传统处理流程需要经过网络设备到系统内存空间,系统内存空间到用户应用程序空间这两次拷贝,同时用户还需要向系统发出系统调用,这需要耗费大量的系统资源。
如何用普通PC搭建廉价灵活的高速数据包捕获接口?为了解决此的问题,也不断涌现出一批优秀软件,Libpcap、Libpcap-mmap、Tcpdump、PF_RING 等。作者在分析比较后,设计修改了BCM5709C的网卡驱动使其支持PF_RING,实现了一种基于 BROADCOM 千兆网卡和 PF_RING的高速包捕获接口。实验证明,使用这种接口可以大大提高数据包的捕获速度,降低系统开销,降低硬件成本,为网络数据后续处理打下良好的基础。
1 常用数据包捕获方法介绍
1.1 Libpcap 方法
Libpcap(Packet Capture Library),即包捕获函数库,是一个应用程序级的API接口,在Linux/Unix和Windows 环境下都有着广泛的应用。通过它提供的 C程序接口,可以方便捕获网络数据包,大部分网络安全监测软件都是在它的基础上开发的,如snort,tcpdump等。并且它还支持Linux系统下的BPF(BerkeleyPacket Filter)信息过滤机制。
1.1.1 Libpcap数据包捕获机制分析
Libpcap的工作机制: 网卡默认工作在缺省模式下,这种模式下只能收到目的主机是本机的数据包,因此首先要将网卡的工作模式切换到混杂模式。为了不影响数据包的正常传输,libpcap的设计者将通过网卡的数据包拷贝出来,额外进行处理。首先与过滤规则进行匹配,不符合规则的丢弃,符合的才交给内核缓冲器,传递给用户层缓冲器,等待用户程序进行相应处理。虽然采用 BPF机制进行了过滤,在一定程度上降低了系统的开销,但libpcap是基于系统内核协议枝的捕包机制,数据包在从网卡FIFO 到用户空间的传递过程中,仍存在多次拷贝以及高频率的中断响应。Libpcap的工作流程,如图1所示:
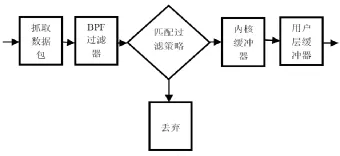
图1 Libpcap工作流程图
1.1.2 Libpcap-mmap数据包捕获机制分析
Libpcap-mmap 是对Libpcap 的一个改进版本,两种机制捕获下来的数据包格式和结构都是相同的。不同点主要是以下两个方面。
a) 缓冲器的改进
Libpcap 中使用存储缓冲器和保持缓冲器共同来完成数据包从网卡到用户层的传递,而 libpcap-mmap设计了一个循环缓冲器来代替这两个缓冲器,并且允许用户程序和内核程序对循环缓冲器中不同区域的数据进行访问和读写。
Libpcap 中的两个缓冲器大小是固定的,一旦出现一个缓冲器装满数据而另一个是空的情况,两个缓冲器还需要进行调换,这会增大系统开销以及丢包率。而libpcap-mmap 使用的循环缓冲器大小是可变的,可以根据不同情况进行不同的配置,这样就在一定程度上提高了捕包的性能。
b) 数据包传递流程的改进
Libpcap 机制下数据包从网卡 FIFO 通过网卡驱动经DMA 的方式,拷贝到内核级的内存中,再拷贝到用户级的内存中,才可以供用户程序访问。这样既占用了系统资源,又降低了捕包性能。而libpcap-mmap通过采用mmap技术,建立内核和用户层的映射,完成数据包从内核到用户层的传递,减少了一次内存拷贝,优势显而易见。
1.1.3 Libpcap 数据包捕获机制分析的结论
Libpcap 虽然是一个成熟的函数库,并且已经为众多网络安全软件的开发提供了支持,但是在它的捕包机制下网络数据包存在多次的拷贝,缓冲器也会在一定情况下出现调换操作,严重影响了数据包的捕获性能,尤其在高负载的网络条件下,显然已经不能满足监测网络安全的需要。根据文献[1]的实验表明,在数据包大小为64字节,流速为337Mbps 时,丢包率达到94.6%。即使是它的改进型libpcap-mmap ,仍然存在内存拷贝和频繁的上下文切换。在libpcap-mmap 机制运行的情况下,当网络报文长度为64 字节,流速为90Mbps 时,报文捕获率也仅为14.9%,同时CPU占用率也接近100%。由此可见,要解决传统捕包机制下遇到的问题,就必须设计并实现一种高速的占用系统资源小的新型捕包机制。
1.2 PF_RING方法
PF_RING是一个高速包捕获库,它能使一个商用PC变成高效廉价的网络测量设备。适合抓包流量分析操作等需求。
数据包在发送和接收过程中,会发生多次内存拷贝以及频繁的中断处理操作,这将消耗大部分的CPU时间。因此,要想提高数据包捕获平台的效率,需要在以下两个方面加以优化和改进:a)减少内存拷贝的次数,节省CPU开销;b)改进中断方式,减少不必要的CPU中断周期。Deri发明了一种 PF_RING机制[1],是一个第三方的内核数据包捕获接口,类似于零拷贝技术。PF_RING的基本原理是将网卡接收到的网络数据包存储在一个环状缓存 (RING)中,应用层程序可直接从环状缓存中读取数据包。
1.2.1 基于PF_RING+NAPI模式
NAPI(new application program interface)是一种中断机制和轮询机制的混合体,是Linux上采用的一种提高网络处理效率的技术。它的核心概念是不采用中断的方式读取数据包,取而代之的是首先采用中断唤醒数据接收的服务程序,然后采用轮询(POLL)的方法来轮询数据(类似于底半bottom-half处理模式)。
当第一批数据包中的第一个数据包到达时,会以中断的方式通知系统,在硬件中断中,系统将该设备注册到一个设备轮询队列中后关闭中断,同时激活一个软中断,采用POLL方式轮询队列中注册的网络设备,从中读取数据包。采用NAPI技术可减少中断触发的时间,改善短长度数据包接收的效率。PF_RING+NAPI模式的结构,如图2所示:
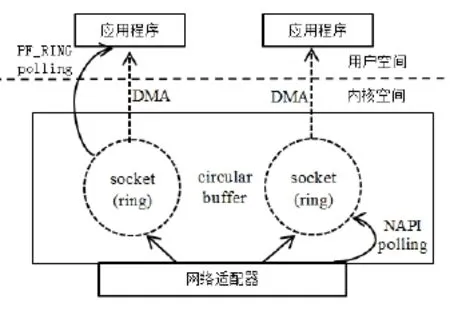
图2 PF_RING+NAPI模式结构图
1.2.2 基于PF_RING+TNAPI模式
随着多核平台的出现,先前的方法在内核网络层并没有利用多核的这个硬件优势,Luca设计了一个新的感知多核包捕获内核模块 TNAPI(threaded new application program interface)。TNAPI是NAPI的一种改进,它分发数据包流量到各内核来提高扩展性,另外它同步的轮询数据包从每个RX队列得到。PF_RING+TNAPI模式的结构,如图3所示:
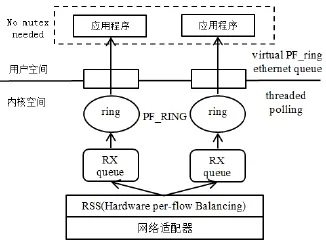
图3 PF_RING+TNAPI模式结构图
1.2.3 基于PF_RING+DNA 模式
DNA(direct NIC access)是一种映射NIC内核和寄存器到用户空间的机制,它是复制数据包从 NIC(网卡)到DMA 缓存环中使用NIC NPU(network process unit)网络处理单元)而不是使用NAPI。另外DNA开启网卡适配器使用pfring_open_dna()函数,这样使得CPU有一个更好的性能。但是使用PF_RING+DNA有一个缺点:就是一次只允许一个应用程序访问DMA缓存,也就是说多个用户层程序同时访问需要相互协调才能正确地分发数据包,而PF_RING技术可以对到来的数据包同时响应不同的应用请求。PF_RING+DNA模式的结构,如图4所示:
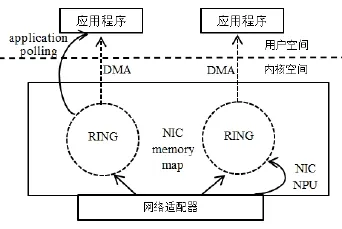
图4 PF_RING+DNA模式结构图
1.2.4 PF_RING机制分析结论
由上可以看出PF_RING为了不断提升性能,使用了多种内核技术。此外它可以选择数据包是否需要经过协议栈再转到用户空间,如果使用修改过的网卡驱动,可以直接由PF_RING传数据到用户空间,而不经过内核协议栈,这在抓原始数据包时提供了非常好的性能。按照PF_RING文档[2]在Linux平台之上,其效率至少高于libpcap 50%-60%,甚至是一倍。更好的是,PF_RING提供了一个修改版本的libpcap,使之建立在PF_RING接口之上。这样,原来使用libpcap的程序就可以自然过渡了。
2 方法实现
2.1 PF_RING数据接收流程
PF_RING提供了 3种数据接受模式,是由加载PF_RING内核模块时的参数transparent_mode指定。模块内部区分不同模式走不同的数据接收路径。
2.1.1 标准的Linux接收路径
当transparent_mode指定为0时,数据通过网卡接收,在发送到Linux内核网络协议栈,最后通过注册在内核里的prot_hook函数进入PF_RING里。这种模式不需要驱动知道任何PF_RING的信息,PF_RING可以部署在任意的硬件平台上,兼容性很好。但是数据经由内核处理,数据会做多次复制再转发到PF_RING,性能不理想,如图5所示:
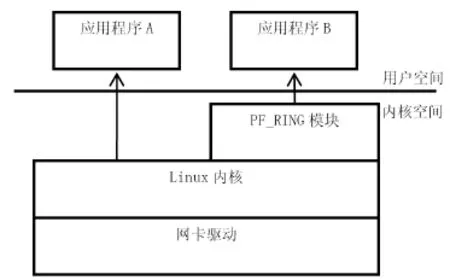
图5 PF_RING数据接收模式1
2.1.2 标准Linux接收路径和PF_RING接收路径
当transparent_mode指定为1时,数据通过网卡接收,在网卡驱动里分别发送数据到 Linux内核协议栈和PF_RING内核模块。这需要修改网卡驱动模块,使网卡在接收数据后分别转发。这种模式比第一种丢包率稍有下降,但是还是要被内核处理一次数据,CPU占用率没降低,性能稍有提高,如图6所示:
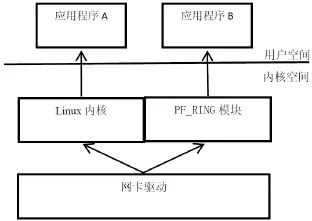
图6 PF_RING数据接收模式2
2.1.3 PF_RING接收路径
当transparent_mode指定为2时,数据通过网卡接收,在网卡驱动里把数据只发给PF_RING内核模块。这需要修改网卡驱动模块,在此模式时不需要把数据递交到上层协议栈。这种模式数据包只在PF_RING里处理,不经过内核,降低了CPU占用率,普通流量测试没有丢包现象,性能达到预期要求。如图7所示:
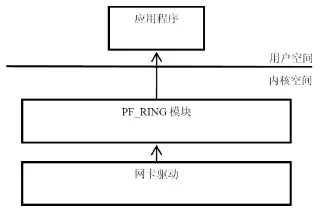
图7 PF_RING数据接收模式3
2.2 网卡驱动数据处理流程
本文使用BROADCOM千兆网卡BCM5709C,最新的驱动为bnx2-2.0.23b。当有数据到达网卡时,触发硬中断调用中断处理函数bnx2_msi_1shot,中断处理函数做完必要操作后,抛出一个软中断NET_RX_SOFTIRQ。硬中断处理完成后,软中断会被处理用于数据接收,这时会调用由网卡初始化时注册的处理函数 bnx2_poll_msix,此函数会调用bnx2_rx_int处理数据接收,并由bnx2_rx_int通过内核函数netif_receive_skb把数据转交到上层协议栈[3]。
2.3 增加PF_RING支持
修改bnx2-2.0.23/bnx2.c文件由上文分析可以知道只有在所有netif_receive_skb前加入判断,检查transparent_mode的值是什么,如果是0:按原流程处理;1:先转发到PF_RING再按原流程处理;2:只转发到 PF_RING,不再调用netif_receive_skb。如图8所示:
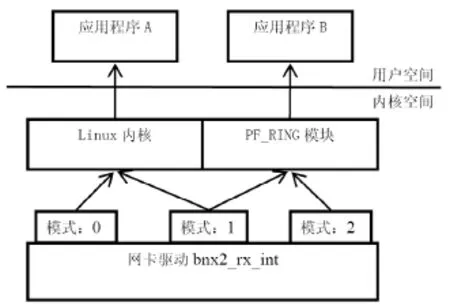
图8 增加P_RING支持
3 实验结果
本文使用的系统配置,两台主机DELL R610(2颗Intel Xeon E5500,2G内存,4-portBCM5709C网卡支持PCI-Express),操作系统 Linux(ubuntu10.4),软件使用PF_RING4.6.0,修改的驱动版本netxtreme2-6.2.23。实验测试时,一台为数据发送机,一台为数据抓包机,在64字节和256字节做测试均发送1500000000个数据包,实验结果,如表1所示:
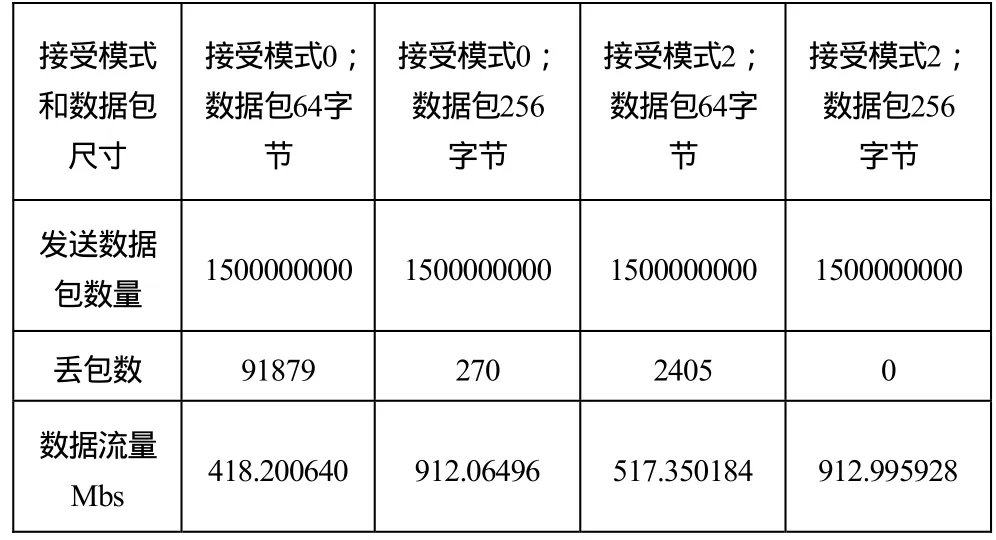
表1 实验测试结果
在接受模式为0时64字节小包丢包严重,在接受模式为2时丢包率下降很多。接受模式为2,模拟一般网络情况数据包为256时没有任何丢包。
4 结束语
如何实现高速链路流量捕获分析,是目前人们非常关注的问题。基于成本和性能的考虑,本文实现了一种在BroadCom千兆网卡上,支持PF_RING的网络抓包方案。随着多核计算机的普及应用,如何充分利用技术进步所提供的硬件资源,在多核条件下,实现更加高效的捕包方案,是一个十分值得研究的问题。这在目前市场竞争激烈的环境下将有重要意义。
[1]Luca Deri. Improving passive packet capture: beyond device polling. [C/OL]2004-10. http://luca.ntop.org/Ring.pdf
[2]Luca Deri, High-Speed Passive Packet Capture and Filtering [M/OL]2008-7 http://luca.ntop.org/AIMS2008_Tutorial.pdf
[3]Jonathan Corbet, Greg Kroah-Hartman, Alessandro Rubini,《Linux Device Drivers, 3rd Edition》[M]O'Reilly 2005-2
