面向对象的植被与建筑物重叠区域的点云分类方法
2012-09-07徐宏根王建超郑雄伟
徐宏根,王建超,郑雄伟,吴 芳,李 迁
(1.中国国土资源航空物探遥感中心,北京 100083;2.中国地质调查局武汉地质调查中心,武汉 430205)
面向对象的植被与建筑物重叠区域的点云分类方法
徐宏根1,2,王建超1,郑雄伟1,吴 芳1,李 迁1
(1.中国国土资源航空物探遥感中心,北京 100083;2.中国地质调查局武汉地质调查中心,武汉 430205)
在分析LiDAR点云数据分类现状的基础上,针对植被与建筑物重叠区域分类困难的问题,提出了一种基于面向对象的点云分类方法。首先采用三角网渐进内插的滤波方法将点云分为地面点和非地面点,并得到DTM;然后对高出DTM一定高度的非地面点建立三角网,删除较长的三角网的边(地物间的边),从而将非地面点云分割成多个对象;再利用各个对象内的三角网坡度信息熵大小判断该对象属于植被或建筑物;最后对于难以区分的对象(植被与建筑物重叠区)根据建筑物几何规则形状延伸扩充,从而提高植被和建筑物重叠区的点云分类准确率。实验结果表明,该方法能够很好地区分建筑物和植被点,分类准确率达到87%。
机载激光雷达;点云分类;植被;建筑物;面向对象
0 引言
机载激光雷达(light detection and ranging,LiDAR)是近年来广泛应用于快速获取精确地面三维数字信息的新型技术。目前,机载激光雷达技术已广泛应用于道路规划、数字城市建模、林业调查、电力选线巡线及自然灾害的灾前预测、灾情勘测、灾后重建等领域。在这些应用当中,首要任务是把点云数据进行分类。近些年已经提出了很多LiDAR数据的特征提取和数据过滤的算法,将激光点云进行分类,从而生成所需的数字产品。
Filin[1]将 LiDAR 数据作为单一数据源,对建筑物屋顶部分进行了分类研究;Vosselman[2]利用LiDAR数据所生成的地面模型和表面模型之差来提取建筑物;Höfle等[3]在LiDAR点云数据中利用基于对象的方法对冰川表面进行了分割和分类研究;Miliaresis[4]采用基于面向对象的方法从LiDAR点云数据提取建筑物点云数据;Lodha等[5]利用SVM方法进行LiDAR数据的分类。大多数分类算法是基于局部的相似性,如需要比较局部坡度差和高程差等,当树枝和建筑物顶部靠得很近时,则会造成建筑物与树木被错误地融合到一个类别中而难以区分,这种情形在城市地区尤为普遍。因此本文在基于面向对象分类后,对植被和建筑物重叠区域还进行了几何规则化并扩充,提高了建筑物点的识别率。
1 点云滤波
在LiDAR滤波时,需先建立区分地面点和非地面点的规则,该规则就是滤波算法的假设条件。主要的假设条件有两种:①地面点低于非地面点;②地面坡度变化在一定范围之内。滤波算法的关键问题是如何利用判别规则和假设条件建立数学模型,区分地面点和非地面点。根据滤波算法原理的差异,可分为3类:形态学方法[6-7]、基于内插的方法[8-10]和基于曲面拟合[11]的方法。形态学方法是以最低点为基础计算出粗略的模型,再利用该粗略模型定义一个高程缓冲区,在缓冲区内的点接受为地面点;基于曲面拟合方法是将地面看作连续且平缓变化的表面,可用带限制条件的参数曲面约束分类;基于内插的方法是线性最小二乘内插后激光脚点高程拟合残差不服从正态分布,高出地面的地物点高程拟合残差都为正值,且偏差较大。本文采用文献[10]中的三角网渐进内插的滤波方法区分地面点和非地面点。
2 研究方法与思路
2.1 基于面向对象的点云分类方法总体流程
点云滤波后得到地面点和非地面点。非地面点中包含建筑物、植被和小面积物体。先利用区域分割的方法,将地物进行分割,并排除小面积物体;再统计各个地物的坡度信息熵,利用建筑物表面平坦信息熵小的原理对建筑物和植被进行分割,若分割不成功,则采用基于几何特征约束的方法对植被和建筑物重叠区域进行分割,其流程如图1所示。

图1 点云分类流程Fig.1 Flow char of point cloud classification
1)将非地面点的高程减去地面点所构成的DTM,得到各非地面点的高度,将高度大于某设定阈值(如0.5m)的点建立三角网。
2)区域分割。在植被或建筑物区域,非地面点密度大于裸露地表区域的密度,因此在植被或建筑物区域的非地面点所建立的三角网比较密集,边长较短;而在裸露地面区域的非地面点所建立的三角网比较稀疏,边长较长。删除边长大于设定阈值的边后,三角网被分割成多个小三角网(每个小三角网为一个对象)。
3)统计各个对象的面积,若面积大于设定阈值,则该对象被判为植被或建筑物,转到下一步;否则,为小面积物体,本文对该类不识别;
4)利用建筑物表面平坦,其对应的坡度信息熵小的原理区分建筑物和植被;
5)若基于坡度信息熵方法无法区分建筑物和植被,则采用建筑物几何约束的方法对植被和建筑物重叠区的点云进行分类。
2.2 基于信息熵的植被和建筑物点云分类
采用基于坡度信息熵的方法分割建筑物和植被的流程如图2所示。
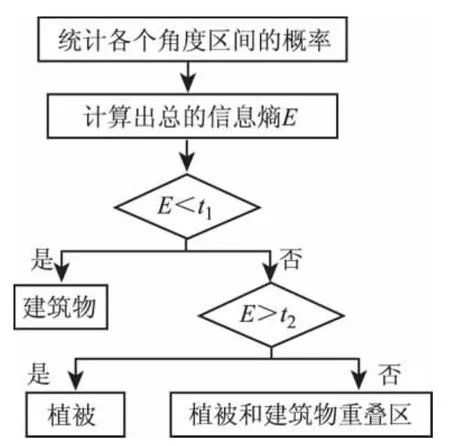
图2 建筑物和植被点云分类Fig.2 Point cloud classification of building and vegetation
与植被表面相比,建筑物表面比较平滑,即建筑物点所构成的三角网的各个法向量方向比较一致;而植被点所构成的三角网的各个法向量方向相差很大。因此,可按下面的步骤判断某个对象是植被还是建筑物:
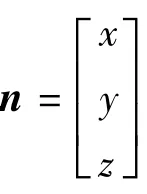

解算得出。求出法向量后,再根据相应公式求出该法向量与水平面所构成的倾斜角α。
2)统计倾斜角在各个角度区间的个数及其对应的概率,本文角度区间间隔设为10°,共9个角度区间。
首先,统计在各个角度区间的三角形个数,如图3所示。

图3 植被和建筑物的法向量角度统计直方图Fig.3 Histogram of vegetation and building on vector angle
然后,计算各角度区间三角形出现的概率p(xi),即
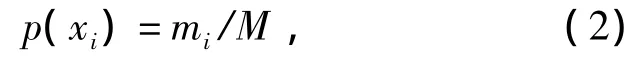
式中:mi表示第i个角度区间内的三角形个数;M表示总的三角形个数。
3)计算该对象的坡度角信息熵Entropy,即

式中n为角度区间个数。
4)从图3可以看出,若是建筑物,则该对象的三角形坡度方向主要聚集在个别角度区间内;而植被点,则分散在各个角度区间内。因此,可以根据坡度信息熵大小来区分植被和建筑物。若信息熵小于阈值t1,则该对象为建筑物;若信息熵大于阈值t2,则该对象为植被;否则为植被和建筑物重叠区,即

式中:E=Entropy(x)/M;0<t1<t2。根据多组实验数据测试,t1=0.01,t2=0.05能够取得较好的分类结果。如果是植被则根据其平均高度可分为低矮、中等和高大植被3种。
2.3 植被和建筑物重叠区分割方法
当某区域的E值在t1和t2之间时,其分类的正确率不高。这种情况主要出现在植被覆盖了部分建筑物。为了正确分离植被和建筑物,本文利用建筑物的几何约束特征对点云数据进行分类。
由于人工建筑物的几何表面存在严格的点、线、面的几何特征关系,如建筑物边缘一般由直线构成,而建筑物屋顶一般由平面构成;并且绝大部分人工建筑物的外形可以用棱柱体来描述,因为其一般具有比较规则的形状,其中一个突出的特点就是建筑物的外边缘线段常常是互相垂直或平行的,为此可对提取的建筑物边缘线进行规则化处理。因此本文基于这种假设,对植被遮挡的建筑物区域再次进行点云分类。其流程为:
首先,提取无植被遮挡的建筑物区域;然后,根据无植被遮挡的建筑物区域的点云提取概略的建筑物边缘;最后,将建筑物规则化,并重新分类;
2.3.1 提取无植被遮挡的建筑物区域
在无植被遮挡的建筑物区域具备2个特征:①回波次数大部分为1;②坡度角度大致相同。因此利用这2个特点可以快速提取无遮挡的建筑物区域。首先,将该对象区域的非地面点云数据进行规则格网组织;然后,统计各个格网内平均回波次数,并统计该区域内各三角形的坡度角信息熵;最后,逐个格网判断,若平均回波次数小于设定值(本文取1.1)并且坡度信息熵小于设定值(本文取0.01),则该区域为无遮挡的建筑物区域。
2.3.2 提取概略的建筑物边缘
采用张靖等[12]提出的基于等高线提取建筑物模型的方法提取建筑物的概略边缘。首先,通过对无植被遮挡的建筑物点云数据的三角网跟踪提取等高线;然后,利用等高线的长度、面积等形状参数来提取建筑物等高线;再通过拓扑分析,以及形状匹配的方法对等高线进行分簇,得到同一建筑物不同组成部分的等高线簇;最后,对各簇等高线进行模型参数优化,并按拓扑关系进行重组建筑物模型。
2.3.3 根据建筑物几何特征进行规则化和扩展
经2.3.2节提取的建筑物边缘是不规则的,如图4(a)所示,并且也不完整。因此需要对边缘进行规则化,并补充被植被遮挡的区域。

图4 建筑物规则化示意图Fig.4 Schematic diagram of regularizating building
由于大部分人工建筑物一般都是规则的多边形轮廓,即建筑物相邻两条边之间的夹角为90°,并且相对的两条线是平行的,因此可以根据该几何特征进行规则化并扩展。具体步骤如下:
首先,将边缘线分段,即相邻两边的夹角大于135°时,认为这两边属于同一线段;然后,将属于同一线段的边缘线重新拟合成一条直线;再根据相邻平行线一般是等长的情况,将建筑物边缘进行扩展,如图4(b)所示;最后,根据扩展后的边缘重新分类。若点离建筑物面的距离小于设定阈值,则认为该点为建筑物点,否则为植被点。
3 实验
3.1 实验数据
实验中所用的数据是2009年在敦煌市区采集的,选取其中一块进行实验,该数据按高程显示如图5所示。

图5 原始点云(按高程显示)Fig.5 Original point clounds(displayed on elevation)
3.2 点云滤波
采用渐进三角网加密方法对原始点云数据进行滤波,得到地面点(黄色点)和非地面点(白色点),结果如图6所示。

图6 点云滤波结果Fig.6 Point clouds after filtered
3.3 基于坡度信息熵的点云分类测试
滤波后,将非地面点云数据的高程减去地面点所构成的DTM,得到各个点的高度。对高度大于0.5 m的点云建立三角网。然后删除三角网中边长大于0.5 m的边,就会得到多个子三角网,对每个子三角网的坡度计算信息熵。图7(a)的点云所构成的三角网的坡度信息熵为0.114,而图7(b)的点云所构成的三角网的坡度信息熵为0.008。

图7 基于坡度信息熵的点云分类结果Fig.7 Classified result of point clouds based on slope information
3.4 重叠区分类
对于难于区分的重叠区域,经过几何规则化和扩展,并将点云重新分类,分类结果如图8所示。
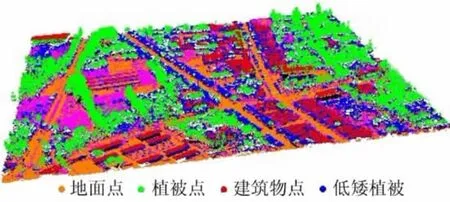
图8 重叠区分类结果Fig.8 Classification result of overlapping area
3.5 分类正确率
为了统计分类方法的正确率,将解译结果进行比较(表1)。

表1 分类正确率Tab.1 Classification accuracy (%)
表1中,方案1是采用文献[1]中的方法;方案2是采用本文的基于坡度信息熵的分类方法,处理重叠区前的准确率;方案3是采用本文方法,处理重叠区后的准确率。表中植被点误分率是指其他类被识别成植被的错误率,建筑物误分率是指其他类被识别成建筑物的错误率。
从表1中可以看出,本文方法在未处理重叠区时,与方案1相当;而在考虑建筑物几何规则约束的基础上对重叠区分类,建筑物点的正确率有所提高,植被点的误分率明显下降,并且总体识别率显著提高。
4 结论与展望
本文将非地面点按对象进行分组,利用建筑物点云比植被点云数据所建立的三角网的坡度更一致的原理,有效地区分了植被和建筑物;而在植被和建筑物重叠区域根据建筑物的几何形状拓展分类,解决了重叠区分类困难的问题,明显提高了重叠区的分类精度。
每种数据所包含的数据量都是有限的,要想靠独立的数据处理系统实现单数据源数据处理的自动化往往不太现实,因此融合多源数据进行点云滤波分类是今后点云数据处理的发展趋势,也是点云数据处理向高精度、高自动化程度发展的新方向。
[1]Filin S,Pfeifer N.Segmentation of Airborne Laser Scanning Data Using a Slope Adaptive Neighborhood[J].ISPRS Journal of Photogrammetry and Remote Sensing,2006,60(2):71-80.
[2]Vosselman G,Dijkman S.3D Building Model Reconstruction from Point Clouds and Ground Plans[J].International Aachives of Photogrammetry Remote Sensing and Spatial Information Sciences,2001,34(3/w4):37-44.
[3]Höfle B,Geist T,Rutzinger M,et al.Glacier Surface Segmentation Using Airborne Laser Scanning Point Cloud and Intensity Data[J].Remote Sensing and Spatial Information Sciences,2007(3/w52):195-200.
[4]Miliaresis G,Kokkas N.Segmentation and Object-based Classification for the Extraction of the Building Class from LiDAR DEMs[J].Computers & Geosciences,2007,33(8):1076-1087.
[5]Lodha S K,Kreps E J,Helmbold D P,et al.Aerial LiDAR Data Classification Using Support Vector Machines(SVM)[C]//Proceedings of the Conference on 3DPVT,2006,3(4):567-574.
[6]Chen Q,Gong P,Baldocchi D,et al.Filtering Airborne Laser Scanning Data with Morphological Methods[J].Photogrammetric Engineering and Remote Sensing,2007,73(2):175.
[7]Zhang K Q,Chen S C,Whitman D,et al.A Progressive Morphological Filter for Removing Nonground Measurements from Airborne LiDAR Data[J].IEEE Transactions on Geoscience and Remote Sensing,2003,41(4):872-882.
[8]Kraus K,Rieger W.Processing of Laser Scanning Data for Wooded Areas[J].Fritsch and Spiller,Editors,Photogrammetric Week,1999,99:221-231.
[9]Lee H S,Younan N H.DTM Eextraction of LiDAR Returns Via Adaptive Processing[J].IEEE Transactions on Geoscience and Remote Sensing,2003,41(9):2063-2069.
[10]Axelsson P.DEM Generation from Laser Scanner Data Using Adaptive TIN Models[J].International Archives of Photogrammetry and Remote Sensing,2000,33(B4/1;PART 4):110-117.
[11]Elmqvist M,Jungert E,Lantz F,et al.Terrain Modelling and Analysis Using Laser Scanner Data[J].IAPRS,2001,34(3/w4):219-224.
[12]张 靖,李乐林,江万寿.基于等高线簇分析的复杂建筑物模型重建方法[J].地球信息科学学报,2010,12(5):641-648.
Object-based Point Clouds Classification of the Vegetation and Building Overlapped Area
XU Hong-gen1,2,WANG Jian-chao1,ZHENG Xiong-wei1,WU Fang1,LI Qian1
(1.China Aero Geophysical Survey and Remote Sensing Center for Land and Resources,Beijing 100083,China;2.Wuhan Center of Geological Survey,Wuhan 430205,China)
This paper proposes an object-oriented point clouds classification method for solving the difficult classification problem for the overlapping between vegetation and buildings based on reviewing current status of LiDAR point clouds classification approaches.In the proposed method,the point clouds are firstly separated into ground points and non-ground points through adaptive TIN filter method,and the DTM is obtained.Second,a triangle network is constructed for non-ground points higher than DTM.The non-ground point clouds could be divided into multi-objects by removing longer edges(edge between ground and object).Then,the object is judged to decide whether it belongs to vegetation or building according to its information entropy of triangle network slope.Finally,for objects difficult to be distinguished from other objects,the overlapped area between vegetation and buildings is extended by geometric shape of buildings,so that the accuracy of point clouds classification of the overlapped area could be improved.The experiment results show good classification performance for buildings and vegetation,and the accuracy reaches 87%.
light detection and ranging(LiDAR);classification of point clouds;vegetation;building;objectbased
P 237.3
A
1001-070X(2012)02-0023-05
徐宏根(1979-),男,博士,主要研究LiDAR数据分析处理、卫星遥感数据处理、遥感地质应用等。E-mail:honggen_xu@163.com。
(责任编辑:邢 宇)
10.6046/gtzyyg.2012.02.05
2011-07-04;
2011-07-20
中国国土资源航空物探遥感中心对地观测技术工程实验室,航遥青年创新基金项目(编号:2010YFL14)资助。
