基于特征噪声加权的特征权重算法改进*
2012-08-20杨天奇赵小厦
赵 航 ,杨天奇 ,赵小厦
(1.暨南大学 信息科学技术学院,广东 广州 510632;2.华南师范大学 计算机学院,广东 广州 510631)
随着信息技术的发展,信息极度膨胀,人们迫切希望找到一种信息自动处理技术。文本分类作为信息处理的技术之一,由于其能对信息进行分类,使得获取信息更加容易,因而得到广泛应用。在文本分类的算法中,空间向量法中的TF-IDF算法由于其以词频TF和逆文档频数IDF的乘积作为向量坐标系的值,具有简单、直观、处理速度快的优点,得到广泛应用。但在理论和实际应用中有很大局限性,以至于其精度在各种文本分类中一直是较低的[1]。
本文针对噪声特征对TF-IDF算法逆文档频率(IDF)影响进行分析,提出了一种IDF加权方法,调整对IDF产生影响的特征噪声权重,有效减少了算法对噪声的影响,提高了TF-IDF算法的精度和健壮性。虽然已有很多研究者对TF-IDF算法做了改进,从特征选择上减少噪声特征的选择,但特征噪声在分类中出现是不可避免的。
1 向量空间算法的分析
向量空间算法的基本思想是用词袋法表示文本,将文本看做特征空间的一个向量,用两个向量之间的夹角来衡量两个文本之间的相似度。用TF-IDF值表示向量空间的一个特征值权重。
词语权重计算唯一的准则就是要最大限度地区分不同的文档。所以针对词语权重的计算,主要考虑3个因素[2]:
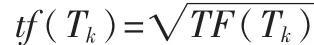
(2)词语的倒排文档频率 idf(inverse document frequency):该词语在文档中分布情况的量化,常用计算方法[3]为 idf(Tk)=log2(N/nk+L)。 其中 N 为文档集合中的文档数目;nk为出现过特征Tk的文档数目;L根据实验来确定。
(3)归一化因子(normalization factor):对各分量进行标准化。
根据上述3个因素,可以得出:TF与IDF的联合公式如下(其中i表示类别号):
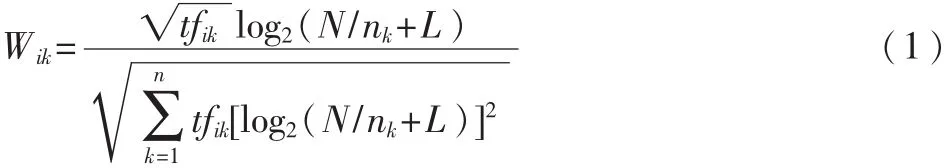
式(1)的提出基于这样一种假设[2]:对区别文档最有意义的词语应该是在文档中出现频率足够高,但在整个文档中出现频率足够少的词语。所以向量空间模型的基础是词语的出现频率和出现的文档频率[2],但同时一个文档中的特征在不管出现的频率多少与文档频率的计算无关,文档频率的计算只与该特征在文档中出现与否有关。而特征噪声在文档中出现一般是以较小的频率出现。当一个特征以特征噪声的形式在大量文档中出现时(该特征本不应该在这些文档中出现),文档频率计算出的值伴随特征噪声出现文档数目的不同变化很大。由于没有考虑特征受噪声影响的程度,只是单纯的以特征是否在文档中出现为依据计算文档频率,文档频率就不能够很好地在分类时起作用。
TF-IDF算法的IDF函数本质是一种抑制噪声的加权[3]。IDF函数认为文档频数少的单词就重要,而文档频数多的单词就无用,这样也使IDF值容易受噪声的影响。文档中的用词本身带有很大的随意性,用与不用某个词都行。大量的文档本身就不规范,并含有很多不规范的用词,导致降低了IDF值对单词权重的区分。
2 特征权重算法的改进
针对传统算法没有考虑噪声影响,对特征特点进行分析提出了改进算法。
2.1 文档特征分析
该文选择了搜狗实验室—搜狐新闻数据900篇文档进行特征分析,选出一篇文档 Di,首先对Di进行分词预处理,进行特征提取,特征降维。统计Di出现词频为t(t=1,2,3,…,10)的特征个数占该 Di所有特征数 Din的比例ri,且对所有文档取平均值;然后进行特征降维前后文档的对比。
经统计得出,在降维前出现词频为1的特征所占比例约80%;词频为1和2的特征共占约90%。通过降维后词频为1的特征所占比例有所降低,但仍然超过50%,词频为1和2的特征共超过60%。由此可见特征词频为1、2占特征总数的绝大部分,虽然可以通过各种算法降低特征数,但降维后特征词频为1、2的仍然占特征总数的绝大部分。如果特征词频为1、2的特征属于噪声特征,这些特征在文档中出现与否也许不会影响所在文档的分类,但由于训练库的文档数非常多,这样可能会造成文档频率DF出现较大波动,使得IDF值出现大的波动,扰乱TF-IDF算法的准确性。
2.2 改进方法
可以这样认为:当特征词频TF较小时(例如TF=1),并不能有效地代表此特征在文档中的重要性,有很大几率是作者偶然性使用该特征;当特征词TF较大时,很多次偶然使用同一特征词的几率不大,很可能是该文档不得不使用该特征。由于文档作者用词具有很大的随意性,可以很随意用其他特征词代替,从而很容易使TF较小的特征词频的TF=0,这一变化对IDF产生影响,如果词频TF在很多文档中出现频数很低,IDF值就更容易受文档作者用词的影响从而扰乱TF-ID特征值的计算,使TF-IDF特征值偏离代表分类权重的意义。
从上述分析可以得到文档中大部分特征的词频为1或2,因此,如何降低噪声特征影响对TF-IDF算法精度计算至关重要。
本文降低特征噪声对IDF值计算影响的方法主要是通过对统计文档频数进行加权。原算法文档频数计算值是统计特征在文档集中出现的文档数,而改进的算法是统计特征在文档集中出现的加权文档数。使噪声特征降低对IDF值的影响,从而降低IDF的波动,提高TFIDF算法的精度和稳定性。
使用 WIDF(加权反文档频率)代替 IDF,WIDF的计算公式如下

其中,L的取值通过实验来确定。N表示文档集总数文档数,TDi表示Tk在第i个文档中是否出现(出现为1,不出现为0),wi表示Tk在文档i出现的权重(通过实验确定容易受噪声影响的设为较小权重,否则为较大权重)。
实验在确定式(2)中的 wi值时,对 Tk出现 1和 2的词频进行处理,因为1和2的词频低,且在图1中可以看出占用比例很大的更容易受噪声影响。当Tk在文档中出现频率为1时,wi通过实验最终确定为0.5;频率为2时,通过实验最终确定为0.9;频率大于2的词频通过实验确定的wi非常接近1,所以出现频率大于2时wi取为 1。
3 实验与分析
3.1 实验数据
实验所有语料来源于搜狗实验室—搜狐新闻数据(SogouC.reduced.20061127)选取财经、IT、健康、体育、旅游、教育、招聘、文化、军事 9个大类,总共 4 500篇文档、其中1 800篇作为训练集(每个类 200篇),余下的 2 700篇(每个类300篇)文档作为测试集。
3.2 评价指标
实验采用分类精度来评估权重算法在不同类上的分类性能。分类精度的定义如下:

3.3 实验分析
k 近邻(k Nearest Neighbor,k-NN)分类算法基于类比学习的非参数分类算法,在文本分类领域获得广泛应用,对于未知分布和非正态分布可以获得较高分类准确率。实验采用式(4)进行相似度计算,用式(5)进行类别判定[4]:
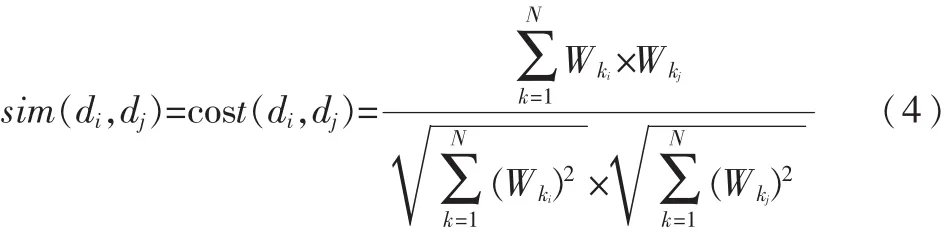
其中,Wki为特征词tk在文档di中的权重。
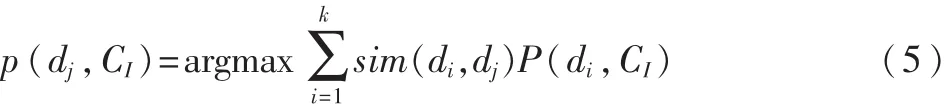
其中,k 为制定的最相似文本数量;P(di,CI)在 di属于 CI时取值为1,否则为0。分类判定时将待分类文本dj的类别归为sim(di,dj)P(di,CI)最大时的类 CI。
经过分词、去停用词、特征选择,表 1和表 2为TFIDF与TF-WIDF两种特征算法在k-NN分类器上的实验结果,试验中取 k为50~75中间的值,特征数为3 000。在确定式(2)权重时,本实验只对出现词频为 1或 2的特征进行加权,词频为1的权重设为0.5,词频为2的权重设为0.9(即在计算特征文档频率时:当此特征在文档Di中出现频率为1次时,在Di中的文档频率为0.5;当此特征在文档Di中出现频率为2次时,在Di中的文档频率为0.9。其他保持不变)。
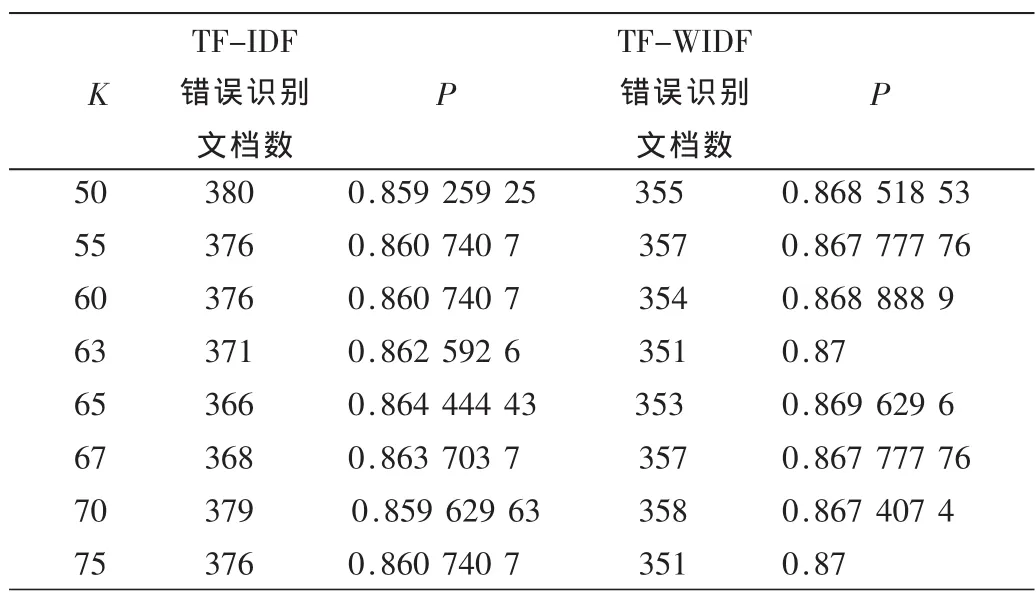
表1 文档错误识别统计表(测试文档数2 700)
从表(1)可以看出在对2 700篇文档进行分类时,当K从 50~75变化时:TF-IDF算法错误识别文档数在366~380范围变化,波动范围为14;TF-WIDF算法错误识别文档数在351~357范围变化,波动范围为6;由此得出当选不同k值时TF-WIDF算法比TF-IDF算法更加稳定。
从表(2)中可以看出TF-WIDF权重算法结合k-NN分类器在各类别上的精确度P除了在健康、财经有少许下降外大部分都有不同程度的提高,在所有类总体正确率提高 0.004~0.008。可以得出 TF-WIDF算法比 TFIDF算法更加精确,与本文使用已经适当优化了传统TF-IDF算法有关,使其总体分类正确率高达0.864 4,在如此高的正确率下再提高任何一点都是非常困难的,而本文正是在如此高的正确率基础上仍然使其提高0.004~0.008,足可以证明本文的改进是有效的。从而说明TF-WIDF能有效地减少由于文档作者用词不规范、用词随意性造成文档特征噪声对TF-IDF算法的影响。尽管改进后的权重算法取得了一定效果,但文本分类问题设计文本表示、相似的计算、算法决策等多个方面改进权重算法并未使分类效果得到明显提高[4]。

表2 各类正确率统计表
通过加权减少了噪声特征对文本分类系统精度的影响。本文研究了传统的TF-IDF加权算法,在已适当优化算法基础之上提出噪声加权算法。实验证明,在传统算法基础上改进的加权算法及其他一些算法基础上的改进,都可有更好的表现。
[1]陆玉昌,鲁明羽.向量空间法中单词权重函数的分析和构造[J].计算机研究与发展,2002,39(10):1205-1210.
[2]鲁松,李晓黎.文档中词语权重计算方法的改进[J].中文信息学报,2000,14(6):8-20.
[3]李凯齐,刁兴春.基于信息增益的文本特征权重改进算法[J].计算机工程,2011,37(1):16-21.
[4]台德艺,王俊.文本分类特征权重改进算法[J].计算机工程,2010,36(9):187-202.
