基于本体的Web服务分类的实现
2012-08-16陆雄斌郭朝珍
陆雄斌,郭朝珍
(福州大学数学与计算机科学学院,福建福州350108)
Web服务(Web Service)是基于XML和HTTPS的一种服务,其通信协议主要基于SOAP,服务的描述通过WSDL,通过UDDI来发现和获得服务的元数据.传统的SOA有其局限性[1],单靠WSDL描述其服务信息,不能存储语义级别的服务信息,极大地限制了服务发现的效率.由于WSDL只对Web服务的技术和语法进行描述,因此在服务检索的时候,只能通过关键词进行查找.
本文从WSDL出发,介绍网络本体语言OWL的特点,利用OWL的结构存储服务信息.再根据目前对服务检索效率的要求,提出了服务分类的想法,对众多不同的服务在一定规则下进行分类,使具有相同功能的服务被归为一类,把不同的服务用本体区分开.
1 Web服务分类算法的设计
1.1 本体概念
本体(Ontology)的概念最初起源于哲学领域,经过多年的演进,人们对“本体”这一概念的重新理解和定位,本体的理论与方法早已被信息领域采用,用于知识的组织、表示、共享和重用.
OWL(Web Ontology Language)是W3C开发的一种网络本体语言,用于对本体进行语义描述.它拥有比RDF和RDF Schema更强的表达能力,是基于XML扩展的语言.
本体语言是用于对领域知识的显示的形式化描述,具有良定义语法[2]:高效率的推理支持、形式语义、充分的表达能力和表达的方便性.
OWL本体的结构如下:
1)OWL头部:OWL文档通常称为OWL本体或RDF文档.一个OWL本体的根元素是一个rdf:RDF元素,用来指定一系列命名空间.
一个OWL本体开始于一个owl:Ontology元素中,包括了注释、版本及其他本体的导入等.
2)OWL类元素:OWL类的定义使用了owl:Class元素,它是rdfs:Class的子类.
3)OWL属性元素:(1)对象属性,将对象相互关联.(2)数据类型属性,将对象与数据类型值相关联.
因此,引入本体论的思想,并采用OWL DL这种基于XML的信息呈现方式,能更好地表现领域知识,作为推理的事实基础.并且采用基于XML的方式表达知识,可以方便知识的共享[3].
1.2 分类思想
算法的基本思想,就是在本体中构建一个根节点类,在根节点之下建立m个分类节点(m根据具体分类数而定),每一个分类节点下有若干个服务,这些服务之间具有较高的相似度,它们被归为一类.
现在,我们所拥有的,即是已经发布到服务器上的众多Web服务的服务URL,即WSDL文档所在的地址.要对Web服务进行分类,首先就必须提取服务的特征.
服务的特征有:服务名(Service Name),输入列表(Input List),输出类型(Output Type),以及服务描述(Service Description)等.这些特征在WSDL中都有相应的描述,因此首先要对服务的WSDL进行解析,提取服务特征,分类系统将利用OWLSAPI进行这一处理.
1.3 方法的选取
常见的分类方法有:决策树、贝叶斯、人工神经网络、k-近邻、支持向量机、基于关联规则的分类和集成学习等,这些方法都是建立在有训练集的前提下,而Web服务分类研究的是在没有训练集的前提下,根据一定的规则将相似的服务聚合以达到分类的效果.这种无指导的学习方法称为聚类方法,常见的聚类方法有:K-means算法、PAM算法(也称k-中心点算法)、层次聚类算法、AGNES算法、密度聚类方法和DBSCAN算法等.
由于分类思想是Web服务迭代比较相似度来聚合相似的服务,因此适合用划分聚类法.其中最典型的是K-均值算法(K-means)和K-中心点(K-modoid)方法.
由于K-中心点方法在迭代前需给定簇的个数K,而Web服务在分类前不知道具体的分类数,而是在迭代比较中产生新的分类或加入已有的分类,因此引入了聚合度阈值,根据聚合度同阈值的比较决定是否产生新的分类.
1.4 相似度计算方法
本文计算字符串相似度是基于编辑距离的,在编辑距离的基础上加以改进之后,再计算字符串相似度的.
编辑距离[4],又称Levenshtein距离(也叫做Edit Distance),是指2个字串之间,由一个转成另一个所需的最少编辑操作次数.许可的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符.
例如将kitten一字转成sitting:
(1)sitten(k→s),
(2)sittin(e→i),
(3)sitting(→g),
则字符串“kitten”和“sitting”的编辑距离为3.
设2个字符串分别为 S1和 S2,编辑距离为d(S1,S2),字符串长度分别为L1和L2,则字符串S1和字符串S2的相似度:
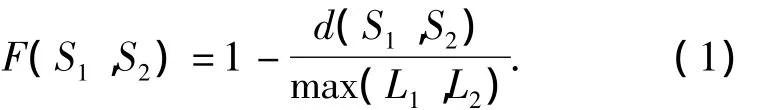
根据式(1)字符串“kitten”和“sitting”的相似度Sim 等于 0.571.
一个 Web服务的特征为:服务名称(Service Name),输入列表(Input List),输出类型(Output Type)和服务描述(Service Description),设对应的相似度为 Simn,Simi,Simo和 Simd.则服务 WSi和 WSj的聚合度其中,α、β、γ和θ分别表示服务名称相似度、输入列表相似度、输出类型相似度和服务描述相似度的权重(本文默认 α =0.3,β =0.6,γ =0.1,θ=0.1,α +β + γ =1.0,θ是辅助权重).
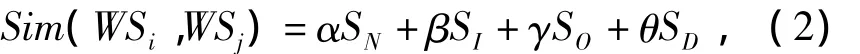
该方案对于计算服务之间的相似度是有效的,因为编辑距离是基于计算2个字符串的差异值,而相似度计算与差异值有关,差异值越小相似度越大.相似度的公式实际上表示2个字符串间匹配字符所占的平均比例,这用来描述2个字符串的相似度是合适的.因此,利用这种计算相似度的方法可计算服务的相似度.又由于服务是由服务名称、输入列表、输出类型和服务描述等组成,就需要对各组成部分进行加权计算.
1.5 服务名称相似度计算
服务名称是Web服务的一大特征,具有相似功能的Web服务通常服务名称相似,由于服务名称属于字符串,因此服务名称相似度的计算直接调用式(1).
设服务WSi和WSj的服务名称分别为Ni和Nj,则服务名称相似度:
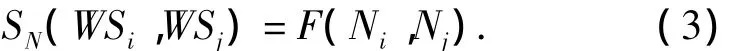
1.6 输入列表相似度计算
输入列表包含一组输入参数(也可以不包含),输入参数由输入参数类型和输入参数名称组成,设输入参数类型名为T,输入参数名称为M,则二元组(T,M)构成一个参数.设服务WSi和WSj的输入列表分别为INi和INj.
INi={(T1i,M1i),(T2i,M2i),…,(Tpi,Mpi)},INj={(T1j,M1j),(T2j,M2j),…,(Tqj,Mqj)},其中p和q分别代表WSi和WSj输入参数的个数.将INi和INj进行笛卡尔积,得到配对集:
D(INi,INj)={〈(T1i,M1i),(T1j,M1j)〉,〈(T1i,M1i),(T2j,M2j)〉,…,〈(Tpi,Mpi),(Tqj,Mqj)〉}.
对于配对集的每一个元素,按类型名(T)与类型名(T)计算相似度,参数名称(M)与参数名称(M)计算相似度,然后加权求和得出元素的相似度,最后将配对集中所有元素的相似度累加,得出2个输入列表的累加相似度:

其中,υ和ν分别表示输入参数的类型和名称的权重(本文默认 υ =0.35,ν =0.65,υ + ν=1.0);F(Mki,Mlj)的计算参见式(1);G(Tki,Tlj)为类型名相似度计算公式,由于类型名比较特殊,例如float和double这2个类型名,按式(1)计算得到相似度为0,但从常识来看,单精度浮点型和双精度浮点型在参数中没有太大的区别,因此必须为给定的类型名对预设一个相似度,也就是经验值.本文设置的类型名预设值表见表1.
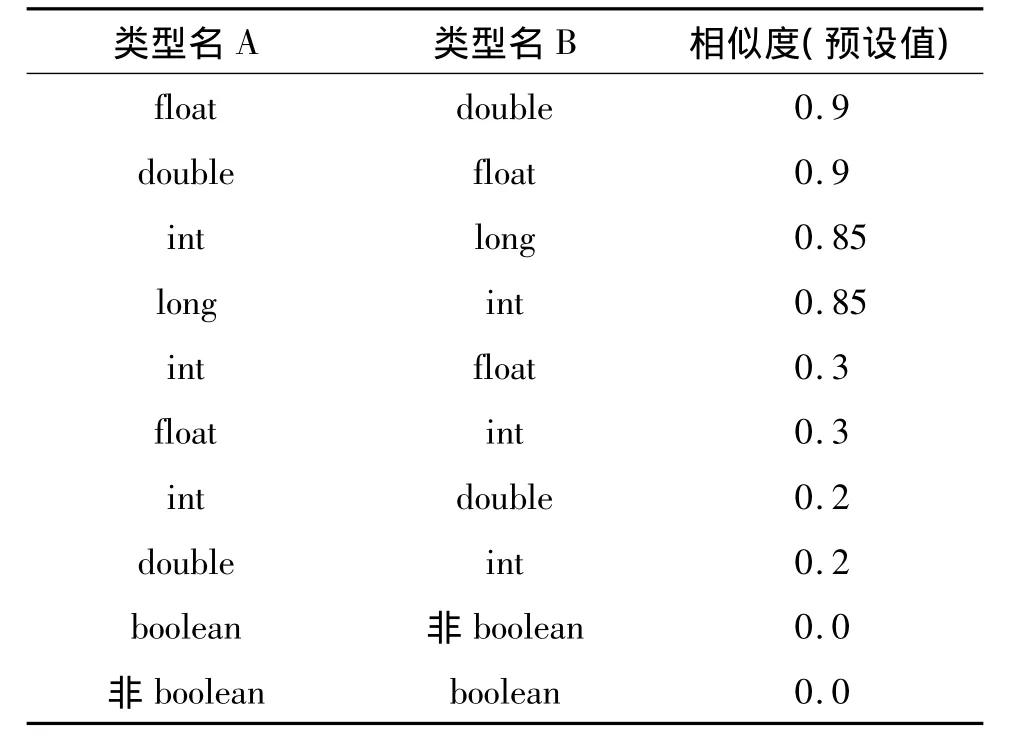
表1 类型名预设值表Table 1 Table of preset value of type name
因此,G(Ti,Tj)结合表1和式(1)得出:

Web服务输入列表的相似度等于它们输入列表的累加相似度与自身输入列表累加相似度最大值之比:

1.7 输出类型相似度计算
Web服务都有输出类型(当无返回值时,输出类型名为null),计算输出类型相似度只要应用式(5)即可.设服务WSi和WSj的输出类型名分别为Oi和Oj,则输出类型相似度为
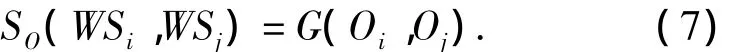
1.8 服务描述相似度计算
服务描述是描述服务功能和服务信息的一串字符串,不像服务名称、输入列表和输出参数是必须事先定义好,服务发布者根据需要定义服务描述或不添加服务描述.因此,计算服务聚合度时,仅将服务描述相似度作为辅助值来计算.本文对服务描述相似度的计算只用了简单的字符串相似度公式,设服务WSi和WSj的服务描述分别为Di和Dj,则服务描述相似度为

2 实验结果及分析
Web服务分类系统和Web服务调用客户端运行的计算机配置如下:
·操作系统:Windows XP(SP3);
· CPU:AMD Athlon(tm)64 X2 Dual 2.41 GHz;
·内存:1 GB.
系统包含2组测试任务:一组固定10个分类数,服务数分别是 10、20、30、50、100;另一组固定 60个服务数,分类数分别是 6、7、8、9、10.每组测试 6次,然后取平均值.
测试结果采用执行时间、平均簇内聚合度、平均簇间聚合度作为本系统的性能指标,执行时间指系统的分类时间,即完成分类所需的毫秒数,平均簇内聚合度和平均簇间聚合度指分类的质量.
2.1 实验效果
本文测试使用的数据以手工发布的100个服务为基础,分为固定分类组和固定服务组,由此分析分类数和服务数对于分类时间的决定作用,测试结果见表2、表3.
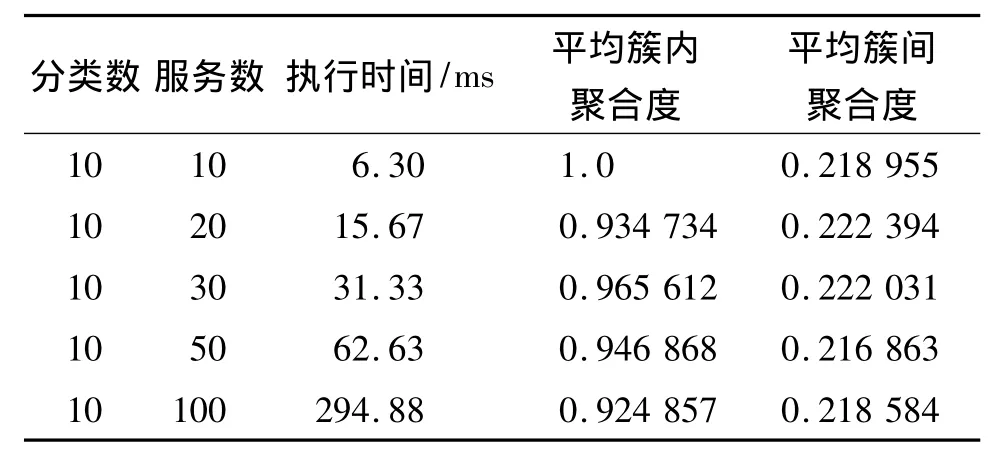
表2 固定分类组Table 2 Group of fixed classification
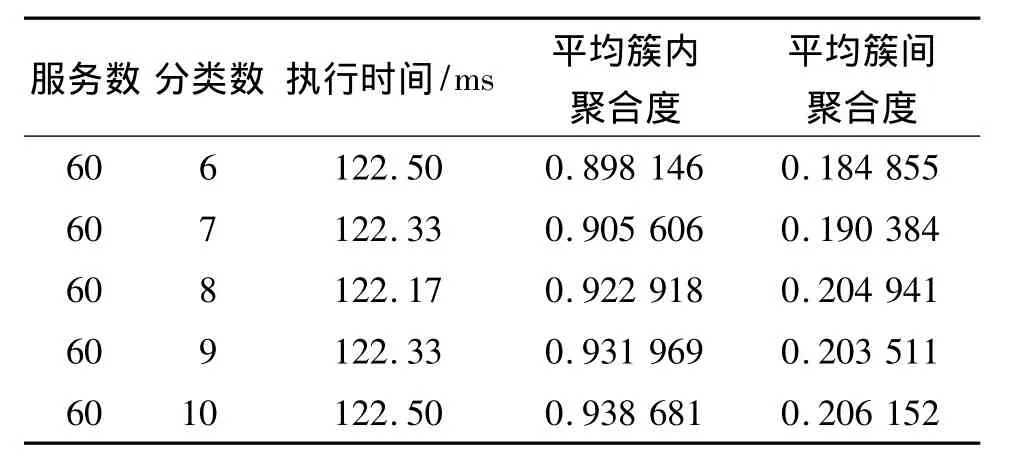
表3 固定服务组Table 3 Group of fixed service
2.2 结果统计分析
从表2和表3的结果,发现服务数n对执行时间影响较大,分类数c影响不大.分类数固定组的平均簇内聚合度和平均簇间聚合度上下波动,而服务数固定组的平均簇内聚合度随着分类数c的增加而上升,平均簇间聚合度有微小的上升趋势,这说明分类数越多,相同类别服务的相似度越高.由于迭代时,每个服务先与每个分类的中心服务比较,再与该分类的所有服务比较,因此Web服务分类的时间复杂度为O(n(c+n/c)).
如图1,当服务数n增加时,分类时间呈抛物线的趋势增加.

图1 时间随服务数变化图(分类数=10)Figure 1 Diagram of time-varying caused by the amount of service
如图2,当分类数变化时,分类时间呈双曲线的趋势变化.
3 结语
本文研究了Web服务的分类问题,采用聚类方法中的K-中心点的思想,结合了聚合度阈值对Web服务进行迭代聚类.利用本体的结构存储分类模型,动态生成分类结果,即服务本体文件.服务请求者读取本体的分类模型,利用相似度比较的查找规则检索服务,为服务请求者提供了一个更快更准确发现服务的方法.

图2 时间随分类数变化图(服务数=60)Figure 2 Diagram of time-varying caused by the amount of classification
该系统提供了服务信息的可视化界面,功能区块划分清晰,另外支持用户自定义系统参数值,以满足不同的分类需求.
[1]曹刚,余凡,程慧平.基于语义Web服务的系统集成研究[J].现代商贸工业,2009(1):357-358.
[2]ANTONIOU Grigoris,HARMELEN Frank van.语义网基础教程[M].陈小平,译.北京.机械工业出版社,2008.
[3]朱创录.OWL DL的知识表示与推理研究[J].甘肃科技,2010(4):42-44.
[4]LEVENSHTEIN V L.Binary codes capable of correcting deletions,insertions and reversals[J].Doklady Akadem iiNauk SSSR,1966,163(4):707-710.
