基于HowNet的词语相关度计算模型*
2012-08-15曾淑琴吴扬扬
曾淑琴,吴扬扬
(华侨大学 计算机科学与技术学院,福建 厦门361021)
语义相关度的研究是自然语义处理NLP(Natural Language Processing)的基础,广泛用于语义消歧、信息检索、文本分类、文本聚类等领域。本文将其作为数据空间[1]研究课题的基础性内容来研究,旨在从内容上发现数据空间中的数据源之间的关联。
关于语义相关度的研究在国外较多,目前的方法一般分为两类[2]:一种是统计方法,另一种是基于语义词典方法。Jiang和Conrath利用Wordnet图的上位关系,通过合并概念c1和c2的信息内容以及最小的共同类属者,综合基于边以及结点的技术,再用语料库统计作为辅助因素进行矫正[2];Banerjee和 Pedersen在 Wordnet的英文语境下,将单词的解释中重叠的单词数量的平方,及含有上下文等关系类型的词语的单词重叠的数量的平方之和,共同作为最后词语相关度的值[2]。
国内在语义相关方面的研究还较欠缺,且大多数选择英文环境,主要基于HowNet、词林、维基百科等知识库[3-5]。参考文献[3]根据知网中的特征文件下位义原和上位义原拥有的属性以及纵向语义联系和实例信息计算词语的相关度。参考文献[4]通过挖掘直接或间接的关系而提出的新的语义相关度计算模型,适用于类似知网的知识体系。总结基于语义词典度量语义相关度所考虑的因素,即最短路径长度、局部网络密度、结点在层次中的深度、连接的类型、概念结点的信息含量以及概念的释义,将上述6个因素归为三大类:结构特点、信息量和概念释义。
本文在综合了参考文献[3]中所提到的基本义原相似度和关联度以及其他相关研究的基础上定义了一个词语相关度算法模型,实现计算同种词性、不同词性词语之间的相关度。
1 知网
中国人民大学的董振东教授等人编写的《知网》以汉语和英语的词语所代表的概念为描述对象,包含丰富词汇,反映概念的共性和个性,是以揭示概念与概念之间以及概念所具有的属性之间的关系为基本内容的常识知识库。
知网中的语义通过义原描述,共有1 618个义原被分成 10大类,每一类都是由一个树结构来存储,而不同类之间的义原构成一个网状结构,它们通过解释义原关联起来。知网中的词语关系类型[6]如表1所示。
2 语义相关度模型
2.1 语义相关概念
定义1语义相似度是指两个词在不同的上下文中可以互相替换使用而不改变文本的句法语义结构的程度[7]。
定义2词语关联度是指词语在概念解释上所存在的语义关系的程度。
定义3词语相关度是指词语间含有表1中的关系类型或存在词语隐含传递等相互关联的特性,即两个词语相互关联的程度从侧面反映了两个词语在同一个语境中共现的可能性,其影响因素有词语的相似性以及关联性等。
鉴于目前国内还没有对相关度判断的标准和类似的专门人工判断的词集,本实验中对相关度的判断主要从两个方面来界定:一是依据上文的定义;二是通过对比参考文献[3]中相关度的实验结果,改进其中一些明显不合理的实验结果来确认本方法的改进性。
2.2 建立词语语义相关度模型
通过对知网结构的分析,根据如下几个因素计算语义相关度:
(1)词语的相似度
知网中的词语通过一个记录来表示,其中有一项语义表达式DEF对该词语进行描述,语义表达式由概念和义原组成。知网中义原有3个类别,另有一些关系符号对概念的语义进行描述的义原,因此,可以将义原分为基本义原、其他义原、关系义原以及关系符号义原。词语的相似度可以通过这4种义原类型求得。
采用下列方法计算两个词语之间的相似度:将两个词语的语义表达式中的义原抽取出来,计算对应义原类型的相似度。如果某一义原类型的对应项为空,则将任何义原 (或具体词)与空值的相似度定义为一个比较小的常数;如果某一义原类型包含多个义原,则将各个义原的相似度加权平均作为该类型义原的相似度[7]。
第一基本义原即主要特征义原,两个词语的这一部分的相似度采用式(1)计算:

[7]中提到的第一基本义原直接用path的倒数计算,不够逼近相关度的实际曲线。本文的思想来源于BP神经网络的S型函数,该函数所划分的区域是一个非线性的超平面组成的区域,是比较柔和、光滑的任意界面,因而它的分类比线性划分精确、合理,且容错性较好,取值范围在[0,1]之间,其图像更加逼近相关度的实际曲线,故而将其作为第一基本义原的表达式。
其他义原即语义表达式中除第一基本义原以外的所有其他义原(或具体词),其值是一个特征结构:sim2(p1,p2)[6]。
关系义原即对应于所有关系义原描述式,其值是一个特征结构,记为:sim3(p1,p2)。

表1 知网中的关系类型
关系符号义原即对应于关系符号描述式,其值是一个特征结构,记为:sim4(p1,p2)。
于是,两个概念(义项)语义表达式的整体相似度为[6]:
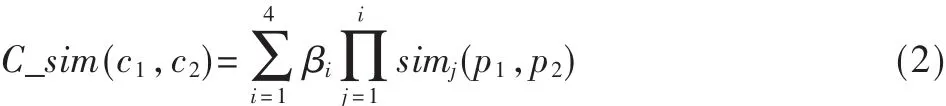
其中 β1+β2+β3+β4=1,βi的值依次递减, 反映了这 4 类义原对整体的相似度所起到的作用是依次递减的。
词语的相似度:sim(w1,w2)=maxC_sim(ci,cj)
(2)词语的关联度计算
知网的每类义原都用一个树结构来存储,形成上下文的层次结构,而每个义原和不在同一个义原树中的义原彼此也可能存在关系,这样就表现出义原之间的横向联系,也就是关联关系,从而使整个义原体系形成一个网状结构。
本文通过对HowNet层次网络结构的分析,找到义原和解释义原之间的重叠部分,从而获取词语关联度的计算模型。
①义原之间的关联度
义原p1和p2的关联度可以表示为:
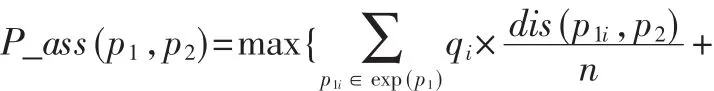

其中 qi、qj是常数,p1i表示 p1的第 i个解释义原,p2j表示p2第 j个解释义原,dis(p1i,p2)是分别求 p2与 p1的解释义原的基本义原的相似度之和,dis(p1,p2j)是分别求p1与p2的解释义原的基本义原的相似度之和,n和m分别是p1和p2解释义原的个数。
②义原之间的相关度
义原的相关度由义原的相似度及其关联度共同决定,表示为:

其中,s1与s2为动态分配权值,其和为1。
③义项(概念)之间的关联度
每个词语可能有几个义项,而义项是通过义原来描述的,故而义项的关联度要从义原的相关度上来计算,而词语的关联度则是从义项的关联度上来计算。

式中,pi、pj分别是 c1、c2中的解释义原。 其中 i≤size(c1),j≤size(c2)。
④词语之间的关联度
每个词语可能有几个义项,故而可以将词语之间的关联度表示为:
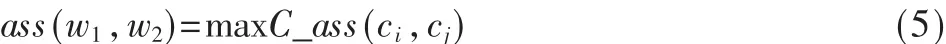
式中,ci,cj分别表示 w1的第 i个概念和 w2的第 j个概念。
(3)实例因素
实例因素模型即义项的实例单词的集合,实例因素对相关度的影响[3]:
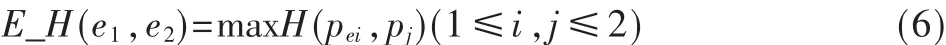
其中,pei为第i个义项的实例单词集合的任意一个词的义项,用pi的实例中词的义项与pj计算相似度,取最大值。
(4)词语的相关度计算
词语的相关度就是将语义相似度与相关度结合起来,同时考虑实例因素,共同构成词语的相关度:
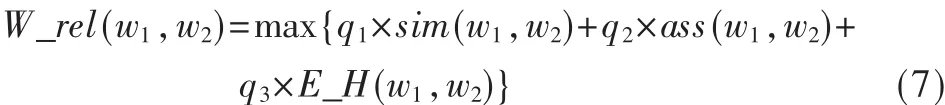
式中 q1+q2+q3=1,若式(7)的第 3项值为 0,这时应把q3的值按比例分配给 q1、q2。
2.3 实验结果与讨论
本实验的数据来源于知网的数据文件,实验中所设置的计算相似度的参数与参考文献[3]和参考文献[7]中是一致的,所以存在可比性。此外,其他一些参数是随程序自动调整使得结果达到最佳效果。
关于第一义原的改进,通过与参考文献[7]的实验进行对比,结果如表2所示。
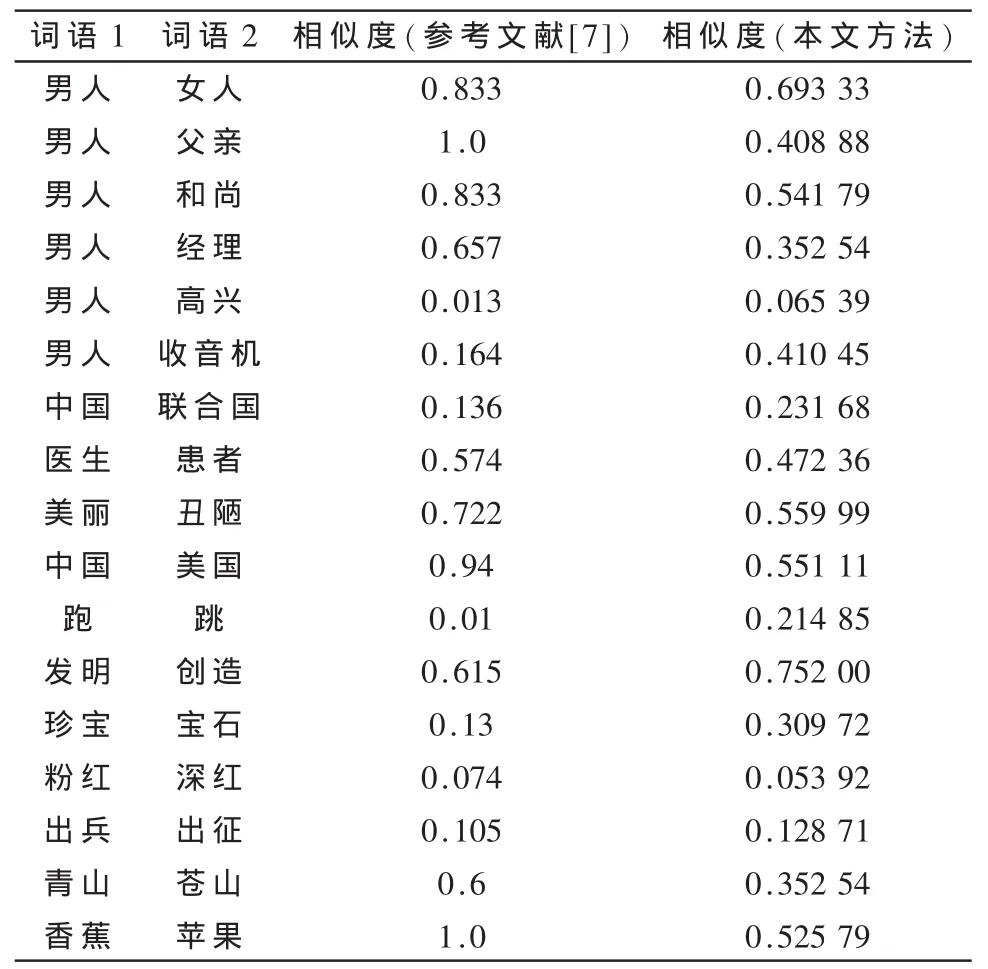
表2 词语相似度实验结果
从表 2可知,“中国”和“美国”在参考文献[7]中的相似度特别高。主要是它用其距离的倒数作为其第一义原,会出现分类不明确的情况,本文采用的S型激活函数所划分的区域,分类比线性划分精确合理,所计算值也更合理。“男人”和“父亲”的相似度为 1,“香蕉”和“苹果”也为1,显然太过粗糙,这种划分分类的方法确实存在着许多缺陷,且算出的值在客观事实之外,本文通过修改第一义原的定义和计算,所得出的相似度分别为0.408 88和0.525 797,相比而言更合理。
上述实验都是同种词性的相似度,而相似只是相关的一个方面,故而进行下面实验,进一步量化同种词性和不同词性之间的相关度,通过对比参考文献[3]的结果进行说明。结果如表3所示。

表3 词语相关度计算的实验结果
由表3可以看出,用参考文献[7]所述方法算出的相似度比较粗糙,例如面包和报纸的相似度比面包和苹果的相似度还要高,这显然不太合理,在义原树中,仅仅考虑语义距离,确实“面包”和“报纸”的距离更近,分析发现,这是因为没有考虑义原关联度原因导致的,而本文计算出来的结果对比参考文献[7]和参考文献[3],结果更合理些。
在参考文献[3]的结果中,“面包”和“巧克力”的相关度为1,这显然与事实不符,通常认为相关度为1是完全相关,趋于同一个事物,虽然这两个词语同属于“食品”范畴,关联度方面确实很大,可是相似度方面却相差甚远,因此其相关度值不可能为1。此外,对事物的看法倾向于一个动宾方式,“削”和“皮”与“削”和“刀”,后者的搭配中表明用“刀”进行“削”,但是也存在用别的东西来“削”,而“削皮”这个搭配在人的直观认知中应该更加相关,故而“削”和“皮”的相关度应该更甚于“削”和“刀”,在本文方法中前者为0.096 533,后者为0.058 880,也符合习惯使用上对相关度的主观判断。另外经分析可以看出,本文方法计算出来的数值都会偏小一些,且不会出现极端值问题,比较平稳,从整体上改进了参考文献[3]中的实验结果。
实验所存在的不足是结果对比不够明显,只是改进了偏差比较大的结果,其原因有两方面,一是对于相关度的度量确实是一个比较主观的做法,且目前没有基于统计的相关度的判断标准,因此很难从微观上细小地区分方法的优劣;其次,知网本身有待进一步完善和补充外,通过义原的相似度(相对稀疏的层次结构)来反映大量词语之间的相似度 (相对密集)的方法本身是否存在一定的上限还需要进一步深入研究,且许多词语的编撰的定义项存在着一些不完整的方面。
本实验通过自适应的参数来进行调整,没有固定权值,考虑到的是动词间、名词间以及名词之间和动词间,其所侧重的因素不同,如名词之间的相关度计算,相似度占的比重更大,而在动词和名词间,相似度比重应该较小,关联度应占更大的比重,这样才更加合理,因此,自动调整好各参数,偏向各自比较侧重的因素,以便获得更好的效果。
词语的语义相关度研究在国内并不多,本文以知网为知识库,在参考文献[3]的基础上改进算法模型,以此提出的相关度模型所得出的结果比较符合人类主观上对相关度的认识。
今后的工作主要是将此词语相关度模型应用到数据空间中数据源内容关联性的发现机制中去,提出一个基于语义模式匹配的相关性匹配策略,以本文中的词语相关度模型为依托,从而发现数据空间内部的各种数据源的联系性。
参考文献
[1]李玉坤,孟小峰,张相於.数据空间技术研究[J].软件学报,2008,19(8):2018-2031.
[2]Hua Yu,Jiang Hong,Zhu Yifeng,et al.Smart Store:a new metadata organization paradigm with metadata semanticawareness for next-generation file systems[C].University of Nebraska-Liclon,Computer Science and Engineering,2008.
[3]许云,樊孝忠,张锋.基于知网的语义相关度计算[J].北京理工大学学报,2005,25(5):411-414.
[4]王红玲,吕强,徐瑞.一种基于知网的中文语义相关度计算模型[C].苏州:第三届全国信息检索与内容安全学术会议,2007.
[5]李峰,李芳.中文词语语义相似度计算—基于知网2000[J].中文信息学报,2007,21(3):101-107.
[6]李素建.基于语义计算的语句相关度研究[J].计算机工程与应用,2002,38(7):75-76.
[7]刘群,李素健.基于《知网》的词汇语义相似度计算[C].台北:第三届汉语词汇语义学研讨会,2002.
