物联网环境下负载均衡的低代价云存储数据副本分布
2012-07-31何典吴敏胡春华
何典 ,吴敏,胡春华
(1. 中南大学 信息科学与工程学院,湖南 长沙,410083;2. 湖南商学院 计算机与电子工程学院,湖南 长沙,410205)
物联网时刻在产生大量的数据,需要对这些数据进行采集、处理、存储、分析和应用等操作。物联网结点数目多,数据规模巨大,需要有一个分布式数据管理体系来管理和整合。传统的分布式数据库系统,局部故障和数据同步更新带来的开销影响系统性能,使得数据量和结点数目均受到限制[1],无法满足物联网环境下数据管理的要求。云存储是一种基于互联网的全局分布式资源存储和访问模型,能同时向大量的用户提供高传输率和高吞吐量的数据服务。云存储是云计算的重要基础和主要应用领域,能够管理大数据集,高效地在海量数据中存储、处理、分析和访问特定对象。现有的云存储数据管理技术包括 Google Bigtable[2],Yahoo PNUTS[3],Amazon Dynamo[4],Amazon S3和 Microsoft Live Mesh等。另外,数据的可靠性、可用性和经济性对数据的提供者和使用者至关重要。为保证这些特性,云存储系统为同一数据复制多个副本,副本的分布将直接影响到副本存储、查询和更新的开销。在一些云存储系统中[5-6],副本所在的存储服务器通过 Hash算法等随机选择,具有随机的分布位置。Amazon Dynamo[4]采用静态方法进行副本分布。由于没有考虑到副本备份的地理位置、开销和数据访问位置等问题,静态或随机的数据分布,均可能带来较高的访问代价[7]。物联网中有大量的移动设备。移动设备数据的存储和管理困难在于数据量的不断膨胀和移动设备本身的固有限制,例如存储空间限制、计算能力限制和无线连接的间歇性等。而且,物联网中各个结点的通信能力不同,较宽的带宽并不能在物联网的每一个部分都得到保证。因此,物联网中的数据访问需要有较低的访问代价。Bonvin等[8-9]提出一种有成本效益分析的、可伸缩的云存储副本复制策略。但物联网中的移动终端在不同结点间访问数据时,需要较快的响应速度,各个访问点的数据访问代价并不相同,临时根据访问代价进行副本复制和迁移的决策会损失较大的实时性能,难以满足要求。数据网格是有效的分布式数据存储系统,与副本管理有关的研究成果较多[10-11]。但云存储的应用范围和面向用户数目均比网格环境大。在数据网格算法中,多从网格结点或者网格系统的角度出发来考虑效益,例如通过效益函数,或者计算任务完成时间等[12-14]。物联网中应用程序的数据访问要求较高的移动性和实时性,无论是从应用程序数据访问代价的角度,还是从系统总的开销的角度来看,物联网中的用户层对存储层的访问代价均要着重考虑,即从用户的角度来考虑总体的访问开销。而且由于数据量急剧膨胀,同一数据的副本数目不能太多,过多的副本冗余将降低存储空间的使用效率并加重数据更新的负担,需要更高的数据一致性保证网络通信能力。当数据网格中提出的方法在存储结点数为 100个时,若副本数目超过 20个[15],则在云存储系统中无法实现。云存储系统为同一数据提供副本数目很少。例如,Google和Amazon提供的云存储服务的数据副本均为3个。因此,数据网格中的副本分布方法不能直接应用于云存储,特别是物联网环境中。
物联网各个结点的存储能力和网络状态不同,备份开销不同,所承担的副本存储任务也应不同。同时,数据副本被访问的情况也应作为确定副本分布方法的依据之一。如果副本能够按照某些条件进行分布,并适应数据访问的实际情况,数据访问代价将会减少。仅考虑访问代价来选择存储服务器,会造成集中选择低代价存储服务器来存储副本,出现各服务器负载不均衡的现象。本文作者提出在最少副本前提下,考虑访问代价和数据被访问情况的副本分布方法,并设计负载均衡机制,使云存储系统中应用程序的数据访问总代价较低,各云存储服务器的负载整体均衡。
1 云存储副本分布及访问代价
1.1 副本数目与类型
副本数目与类型是讨论副本分布方法的前提。
1.1.1 副本数目
为了容错,同一数据应至少保留3个副本。如果存在数据副本不一致,可通过投票机制,决出产生错误的副本。当然,副本数目也可以是任意大于2的奇数。但过多的副本会增加维持数据一致性的复杂性和开销。在云存储系统中,数据量太大,存储空间消耗过快,难以为同一数据保留过多的副本,典型的云存储系统提供3个副本。
1.1.2 副本类型
副本分为临时副本、永久副本和长期副本[16]:临时副本用来提高访问性能(位于存储服务器上),永久副本用来备份数据,长期副本用来对副本归档。假设副本总数为3,本文为同一数据定义2个临时副本和1个永久副本,这样既可以提高数据访问效率,又能够对数据进行备份。本文中,访问代价是指对临时副本的访问代价,副本位置是指存储2个临时副本的云存储服务器的位置。
1.2 访问代价描述
通过应用程序接口(API),应用程序在数据访问服务提供点访问云存储中的数据。云存储数据管理系统接到访问请求之后,将数据查询等访问结果返回给应用程序。整个数据访问可以看作一系列虚拟化的过程,访问细节对应用程序而言是透明的。整个系统的模型可用图1来表示。
图1中,云存储系统由分布在多个地点的存储服务器组成,服务器的集合记作 S,各存储服务器Sj∈S,j = 1,2,… ,n 。应用程序访问提供云存储接入服务的各服务提供点,这些提供点的集合记作 A,各服务提供点 ai∈A,i = 1,2,… ,m。将服务提供点对存储服务器的访问代价记录在矩阵C中,即:

图1 云存储数据访问模型Fig.1 Data access model in cloud storage
其中:Ci,j表示服务提供点ai对存储服务器Sj访问的代价(i=1,2,…, m;j=1,2,…,n)。具体的访问代价受通信开销、带宽分配、硬件配置、存储容量及利用率和查询负载等因素的影响,其计算见文献[8-9]。
2 低访问代价副本分布
在物联网中,考虑到带宽和可靠性等限制,应用程序访问数据应选择较小访问代价的存储服务器,以提高访问效率。而且,物联网中结点具有移动性,当应用程序在多个服务提供点访问数据副本时,应找出与这些服务提供点相对应的低代价存储服务器。
根据当前访问位置临时进行代价计算,决定副本存放位置和是否进行迁移的方法,难以满足物联网实时性的要求。低代价存储服务器的位置可通过分析数据访问的历史数据来确定,并根据情况变化适当进行修正,不必临时进行代价计算。
2.1 低代价副本分布方法
找到最低访问代价的2个存储服务器来布置数据r的副本,相当于在矩阵C中找出m个元素,这m个元素仅属于矩阵的某2列,并且元素之和最小。应用程序没有访问的服务提供点不参与计算。使用集合 V记录应用程序对服务提供点访问的情况:

其中:若vi=0,则表示应用程序未在服务提供点i访问过数据r;若vi=1,则表示应用程序在服务提供点i访问过数据 r。未访问过的结点不需要参与总代价计算。由于仅考虑整个拓扑结构的一部分,减少了计算的复杂度,计算结果与访问情况相符合。数据r最低代价计算公式为:

由式(3)计算得到最小访问代价fmin-cost,与之对应的i和j表示2个副本应分别存放在存储服务器Si和Sj上。
2.2 结合访问频率
应用程序在不同的数据访问服务提供点多次访问某一数据,将产生这段时间内对该数据的副本访问总代价。由于应用程序在不同的服务提供点访问该数据的次数并不相同,由式(3)选取的存储服务器,可能存在来自较低代价服务提供点的数据访问次数少,而较高代价服务提供点的数据访问次数多的情况,使得其总代价不一定最小。因此,结合访问频率来计算总的访问代价更为合理。
使用集合P记录应用程序对某数据r的访问频率,如式(4)所示:

其中:pi表示应用程序在服务提供点i对数据r访问的频率,即在该服务提供点访问该数据的次数占所有服务提供点对该数据访问总次数的比例。pi=0表示在服务提供点i未访问过该数据r。
将应用程序在服务提供点i访问某数据的次数记为ti,则pi计算方法为:

可以将集合P中的元素作为计算最小代价的加权值。修改式(3)进行数据r最低总代价计算和选择存储服务器:

2.3 考虑访问频率的合理性
由下例说明结合访问频率的副本分布的合理性和正确性。例如,有10个访问服务提供点,5个存储服务器,根据式(1),其访问代价矩阵C如下所示:

如果某数据的访问情况V={ 1, 1, 0, 1, 0, 0, 0, 0, 1,0},使用的访问代价矩阵相当于:

然后,找出具有代价之和最小的2列,如下面矩阵中的有下划线的数字所示。对于该数据,选择S2和S5为存储服务器具有最小的总访问代价,值为21。

若在某一段访问时间内,在这4个服务提供点访问数据的次数分别为60,100,10和30,则:P={0.3, 0.5, 0.05, 0.15}使用的访问代价矩阵C相当于:

根据代价矩阵 C和式(6)计算得出有最小的总代价的2列为S4和S5,各数据访问服务提供点对应的存储服务器如表中有下划线的数字显示。其访问总代价为990。如果不考虑访问频率,采用式(3)将选择S2和S5为存储服务器,产生代价1 410。可以看出,结合访问频率的总代价计算方法能够更准确反映实际的访问情况。
3 基于动态代价矩阵的负载均衡机制
仅考虑访问代价,每次均选取总代价最低的存储服务器来布置副本,使低代价存储服务器被选择的可能性大大增加,将造成各存储服务器负载不均衡。
当选中低代价存储服务器布置某个副本后,其剩余容量减少,负载增加,可认为其访问代价增加。若动态更新代价矩阵,使负载增加的存储服务器访问代价的值增加,那么,该服务器下一次被选中成为布置副本的服务器的可能性将减小,使整体的负载能够达到均衡。
3.1 访问代价矩阵的动态修正方法
由式(6)可知,根据副本被访问的情况,包括访问点的位置、访问次数、访问代价来决定2个副本的位置,使得副本将来被访问时有尽可能小的代价。当副本存放到存储服务器后,其负载增加。这时,可以适当提高该存储服务器对各访问点的访问代价。若副本存放在存储服务器k和l上,那么代价矩阵中的相应元素修改方法如下:

其中:i=k,l;l≤j≤m;α是一个代价增加参数。云存储中数据副本数目一般都很大,当存储服务器上增加副本时,α取略大于0的小数即可。
3.2 基于负载均衡机制的副本分布算法
引入负载均衡机制的副本分布算法(RDLBLC),每一个副本的分布位置可以由该算法来确定。作为补充,若某存储服务器的负载超过了目前平均负载的 β倍,即便其访问代价最小,也不选择该服务器作为当前副本分布的结点,这样可以保证当代价矩阵增加太慢时,负载的相对均衡。β根据存储服务器最大负载与平均负载的比例设定。
算法 1:引入负载均衡机制的副本分布算法(RDLBLC)
输入代价矩阵Cm×n和数据访问频率数组Pm
For i=1 to n
If Load(Si) < β×AvgLoad(S1to Sn) //最大负载调节
For j=i+1 to n
使用式(6)计算最小代价fmin-cost
设相应的Si和Sj为应选择的存储服务器
End For
End If
End For
输出Si,Sj//确定副本所在存储服务器Si和Sj
For k=1 to m //负载均衡机制
使用式(7)修正和更新代价矩阵的第i列和第j列
End For
End RDLBLC
3.3 副本位置重新分布问题
当代价矩阵发生变化后,决定副本位置所依据的代价也发生了变化。但是,每次副本分布均选择了低代价的存储服务器,而且增加了对应服务器的访问代价,更新了代价矩阵,使副本比较均匀地分布到各个服务器上。当大批量的副本被布置到云存储系统时,相对于初始状态,各个存储服务器访问代价的增长也是均衡的,即整个代价矩阵各个元素的值在同比增加。因此,副本仍分布在与访问情况相对应的低代价存储服务器上,整个系统的总访问代价仍然较小。
4 实验
在 Pentium(R) Dual-Core CPU 2.60GHZ,2.0G Memory,Windows7,Java1.6环境下,对包括一系列数据存储服务器和数据访问服务提供点的云存储系统进行了模拟。该模拟环境包括30个存储服务器和100个服务提供点。每1对存储服务器和服务提供点被赋予1个随机数,该数值为数据访问代价,记在代价矩阵C中。为了便于讨论,代价矩阵C各元素的初始值为[1, 100]之间的一个整数,表示在初始状态,最大代价至多是最小代价的100倍。在此基础上,模拟产生105个数据及其访问位置和频率。
将随机选择副本位置的方法记为RS,结合访问频率的最小代价选择方法记为MFS,负载均衡的低代价选择方法记为 LBS。经过 50次模拟实验,求出各次数据访问总代价的平均值。上述3种方法产生的总代价平均值比较如图2所示。
从图2可见,负载均衡方法产生的数据访问总代价略高于结合访问频率的选择方法,但相对于随机选择方法,减少了一半以上的数据访问开销。

图2 3种副本分布方法的系统访问总代价比较Fig.2 Total access costs of three replicates distribution methods
结合访问频率选择存储服务器虽然有最小的应用程序访问总代价,但负载不均衡。图3所示为按照结合访问频率的最小代价选择存储服务器后各个服务器的访问代价与其负载的对照图。
从图3可以看出,总代价较小的存储服务器其承担的副本存储任务较重。虽有一定的合理性,但负载分布过于不均衡。
根据上述分析和算法,令α=0.01,β=1.3,采用负载均衡机制后,各个存储服务器访问总代价与负载对比情况如图4所示。
将采用负载均衡机制时各个存储服务器的访问总代价与其负载的比值如图5所示。其中,纵坐标为各比值与这些比值的平均值比较后的分布结果。
从图4和5见:负载均衡方法使副本的分布比较平均,而且使副本的分布与存储服务器的访问代价结合较好。

图3 结合访问频率的最小代价方法各服务器总代价与负载Fig.3 Total access cost and load of selection method with minimum cost integrating access frequency
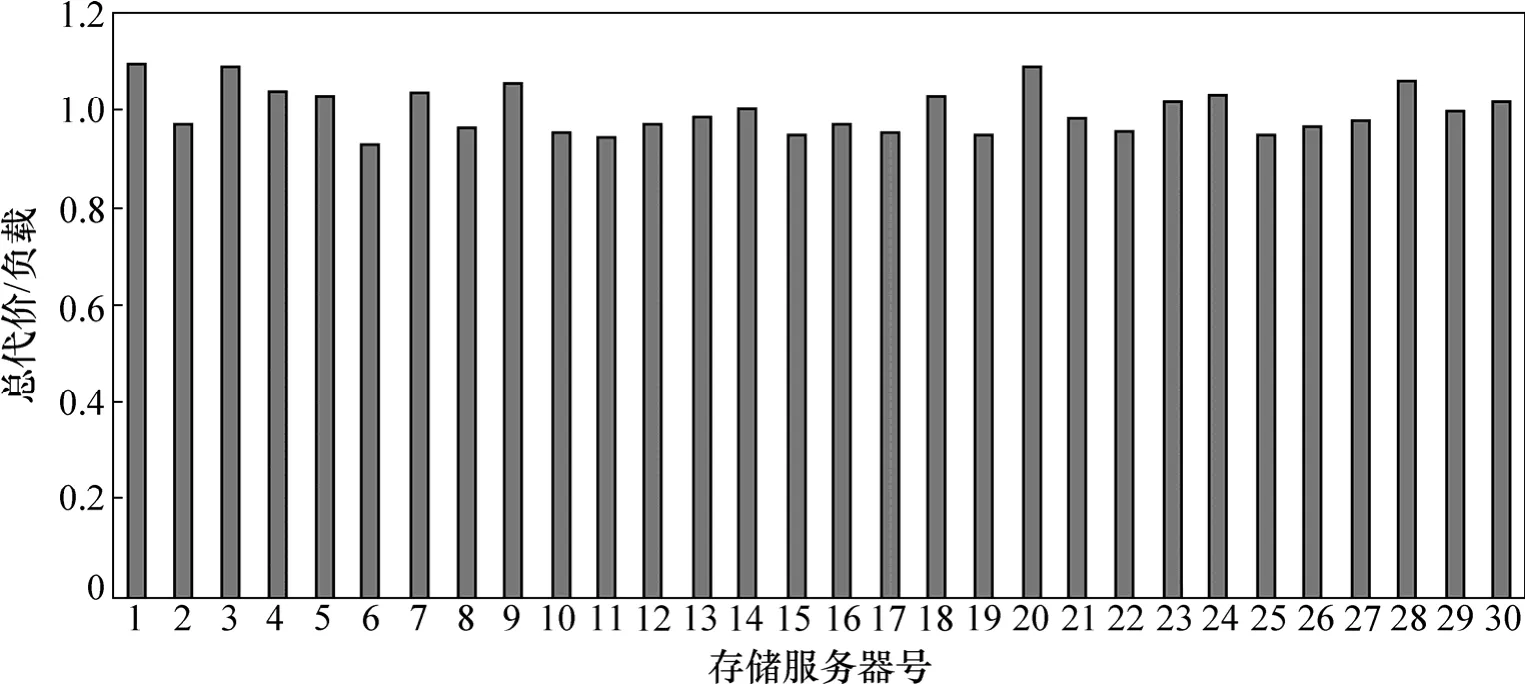
图5 各数据存储服务器的总代价/负载的比值分布Fig.5 Values of total access cost/load of data storage servers
5 结论
(1) 将访问位置、访问频率、访问代价结合在一起考虑,通过选取访问代价较小的存储服务器,减少云存储系统中应用程序进行数据访问的总代价,降低系统数据访问总开销。
(2) 充分考虑物联网中应用程序数据访问的移动性和实时性,使副本分布与用户访问情况相适应,具有较低的访问代价,提高用户数据访问效率。
(3) 采用基于动态代价矩阵的负载均衡机制,使副本能够均匀地分布到与访问情况相适应的低代价存储服务器上,避免仅考虑访问代价时副本分布较为集中的问题,达到平衡各存储服务器负载的效果,适应数据量增加后访问代价的变化。
(4) 使用最少副本数目,最大限度地减少保持数据一致性和更新的开销。
[1] Agrawal D, Abbadi A E, Antony S et al. Data management challenges in cloud computing infrastructures[C]//Proceedings of the 6th International Workshop on Databases in Networked Information Systems. Japan: Springer, 2010: 1-10.
[2] Chang F, Dean J, Ghemawat S, et al. Bigtable: a distributed storage system for structured data[J]. ACM Transactions on Computer Systems, 2006, 26(2): 205-218.
[3] Cooper B F, Ramakrishnan R, Srivastava U, et al. PNUTS:Yahoo!’s hosted data serving platform[J]. Proceedings of VLDB Endowment, 2008, 1(2): 1277-1288.
[4] DeCandia G, Hastorun D, Jampani M, et al. Dynamo: amazon’s highly available key-value store[C]// Proceedings of 21st ACM SIGOPS Symposium on Operating Systems Principles.Washington, USA: ACM, 2007: 205-220.
[5] Rowstron A, Druschel P. Storage management and caching in PAST a large-scale, persistent peer-to-peer storage utility[C]//Proceedings of ACM Symposium on Operating Systems Principles. Banff, Alberta, Canada: ACM, 2001: 188-201.
[6] Kubiatowicz J, Bindel D, Chen Y. Oceanstore: an architecture for global-scale persistent storage[J]. Special Interest Group on Programming Languages Notices, 2000, 35(11): 190-201.
[7] Abadi D J. Data management in the cloud: limitations and opportunities[J]. Bulletin of the IEEE Computer Society Technical Committee on Data Engineering, 2009, 32 (1): 3-12.
[8] Bonvin N, Papaioannou T G, Aberer K. Dynamic cost-efficient replication in data clouds[C]// Proceedings of the 1st Workshop on Automated Control for Datacenters and Clouds. Barcelona,Spain: ACM, 2009: 49-56.
[9] Bonvin N, Papaioannou T G, Aberer K. A self-organized,fault-tolerant and scalable replication scheme for cloud storage[C]// Proceedings of the 1st ACM Symposium on Cloud Computing. Indianapolis, Indiana, USA: ACM, 2010: 205-216.
[10] Chervenak A, Foster I, Kesselman C. The data grid: Towards an architecture for the distributed management and analysis of large scientific datasets[J]. Journal of Network and Computer Applications, 2000, 23(3): 187-200.
[11] Ranganathan K, Foster I. Identifying dynamic replication strategies for a high performance data grid[C]//Proceedings of the International Grid Computing Workshop. Berlin: Springer Verlag, 2001: 75-86.
[12] 游新冬, 陈学耀, 朱川, 等. 数据网格中基于效益函数的副本管理策略[J]. 东北大学学报: 自然科学版, 2007, 28(8):1122-1126.YOU Xin-dong, CHEN Xue-yao, ZHU Chuan, et al. Benefit function based replication strategies in data grids[J]. Journal of Northeastern University: Natural Science, 2007, 28(8):1122-1126.
[13] 易侃, 王汝传. 分布式任务调度与副本复制集成策略研究[J].通信学报, 2010, 31(9): 94-101.YI Kan, WANG Ru-chuan. Decentralized integration of task scheduling with replica placement strategy[J]. Journal of Communications, 2010, 31(9): 94-101.
[14] HU Zhi-gang, XIAO Peng. A novel resource co-allocation model with constraints to budget and deadline in computational grid[J].Journal of Central South University of Technology, 2009, 16(3):458-466.
[15] 付伟, 肖侬, 卢锡城. 个体 QoS 受限的数据网格副本管理与更新方法[J]. 计算机研究与发展, 2009, 46(8): 1408-1415.FU Wei, XIAO Nong, LU Xi-cheng. Replica placement and update mechanism for individual QoS-restricted requirement in data grids[J]. Journal of Computer Research and Development,2009, 46(8): 1408-1415.
[16] Grossman R L, Gu Y H, Sabala M, et al. Compute and storage clouds using wide area high performance networks[J]. Future Generation Computer Systems, 2009, 25(2): 179-183.
