用于高速入侵检测的工业物联网协议驱动
2012-07-26白瑞林陈大峰
季 杰 白瑞林 陈大峰
(江南大学轻工过程先进控制教育部重点实验室1,江苏 无锡 214122;江南大学智能控制研究所2,江苏 无锡 214122)
0 引言
由于传统工业控制系统的计算资源(包括CPU和存储器)有限,在设计时只考虑到效率与实时相关的特性,未将控制系统网络安全作为一个主要的指标进行考虑[1-2]。网络入侵检测系统(network intrusion detection system,NIDS)作为网络安全检测的重要工具,对网络设备的安全管理意义重大。
目前,网络入侵检测的研究主要集中在OSI网络架构的第7层(L7,应用层)。OSI采用字符串和正则表达式作为L7内容的特征描述和检测方法[3-4],吞吐率高达16 Gbit/s,但系统整体的吞吐率不到1 Gbit/s,这说明TCP/IP协议栈已经严重制约了系统的整体性能。使用优化TCP/IP协议栈的方法[5],可以使吞吐率提高到2.7~9.5 Gbit/s;而由于其并没有充分利用现有PC的硬件特性来充分优化协议栈,因此吞吐率还有提高的可能性。
本文在工业物联网协议栈的基础上,实现了一种运行在多核通用计算机平台上的高速并行工业物联网协议栈。该协议栈满足了高速入侵检测的需求。
1 工业物联网协议栈
工业物联网是指在传统工业网络的基础上,融合互联网、WSN和现场总线网络等异构网络,将具有环境感知能力的各类终端、云计算模式、移动通信和实时通信等不断融入到各个工业环节的网络。
工业物联网协议栈框架如表1所示。
在工业物联网协议栈的感知层中,基站利用网络拓扑发现协议从配置服务器获取网络地址配置池,感知设备利用网络拓扑发现协议从基站获得网络地址。在获得网路配置之后,数据采集子层负责采集PLC设备所获取的环境数据,令牌网和实时以太网负责工业总线的实时数据传输问题。对于网络层,应着重解决其异构网络间的数据融合传输。网关协议结合泛在计算模式,着重解决网络传输和计算的负担问题;用户协议是解决访问资源权限和访问资源负担的协议。应用层支持多协议,包括传统的互联网协议和自定义工业总线协议。
2 协议栈驱动和优化
2.1 协议栈驱动的分析
鉴于Windows系统中已经实现了TCP/IP协议栈,在实现工业物联网络协议栈驱动时,可直接调用Windows的TCP/IP协议栈方式实现以太网的部分功能。物联网协议栈的内部模块调用关系如图1所示。

图1 驱动调用关系示意图Fig.1 Relationship of driver calling
图1 中,TCP/IP.sys和 ndis.sys驱动是 Windows自带的驱动;ApplicationLayer.sys、NetWorkLayer.sys 和SenseLayer.sys分别为应用层驱动、网络层驱动和感知层驱动。
利用内核定时器对内核调用进行时间测量,再运用计数器对内核调用进行计数,可分析得出协议栈的瓶颈所在。
CPI是函数所执行的指令总数与函数执行这些指令所消耗时间的比值,CPI的值越大,意味着函数执行效率越低。函数执行效率测量如表2所示。

表2 函数执行效率测量Tab.2 Measurement of the function execution efficiency
由CPI数值可以分析出系统的资源消耗。协议栈处于内核空间,协议栈在内存拷贝函数RtlCopyMemory(Windows的运行函数)、哈希计算函数KeHashCalc和搜索数据流函数find_stream_data上所耗费的时间占用了总时间的44.1%,尤其是哈希计算,所花费的时间占整个协议栈处理时间的16.8%。
函数KeHashCalc利用源网络地址、远程网络地址和端口号计算出哈希值。函数采用的计算方法是查表和取模(mod)运算。虽然查表极大地简化了计算量,但却是一种利用空间换时间的办法。
函数find_stream_data利用计算所得的哈希值来查询数据流表,数据流表包含了218个条目,每个条目均指向一个动态分配的数据流结构。因此,该函数也相当耗费时间。
函数RtlCopyMemory是微软提供的一个内核API,用于在内核空间拷贝内存。如从网卡中读取的网络流量,网卡驱动会使用直接内存访问(direct memory access,DMA)将流量数据写入内核空间,用户空间的程序调用系统调用内核空间拷贝数据。优化内核空间和用户空间之间的内存拷贝,可以极大地提高协议栈的处理速度。
2.2 协议栈优化
根据上述分析结果,协议栈的优化可以分为内存操作优化、计算优化和并行处理3个方面。
2.2.1 内存操作优化
数据之间的依赖关系可能会导致大量的访问延迟。例如,处理器初始化内存读取立即数的请求,而这个立即数被下一条指令使用,此时处理器必须挂起,直到立即数从内存中返回。
为了减小内存访问延迟、提高处理器效率,处理器可以发起连续几个读请求,并分别使用返回的数据。此时,即使处理器处于延迟状态,仍然可以保持在运行状态,从而提高了性能。
分散-聚合直接内存访问(scatter-gather DMA,SGDMA)[6]使用链表描述物理不连续的存储器。SGDMA首先把链表首地址发送给DMA Master,DMA Master在传输完一块连续地址的内存数据后,再根据链表传输下一块连续地址的内存数据,最后进行一次中断,通知CPU传输结束。这为DMA提供了传输时间,尤其适合网卡与操作系统之间的数据传输。
2.2.2 计算效率优化
在工业物联网协议栈中,报文校验码的长度为32位。由于报文的校验码包含在报文头部,因此在发送大量报文时,累计的报文校验码运算量非常大。为了提高计算效率,结合X86架构的特性,使用汇编实现校验码算法。各个校验码计算操作之间没有相关性,4个32位数可以组成一个128位数,然后利用单指令多数据流(single instruction multiple data,SIMD)指令扩展指令集(streaming SIMD extensions,SSE)计算校验码。相比较使用32位指令,使用SSE指令[7-8]可将计算速度提高4倍。使用SSE指令的哈希算法如图2所示。
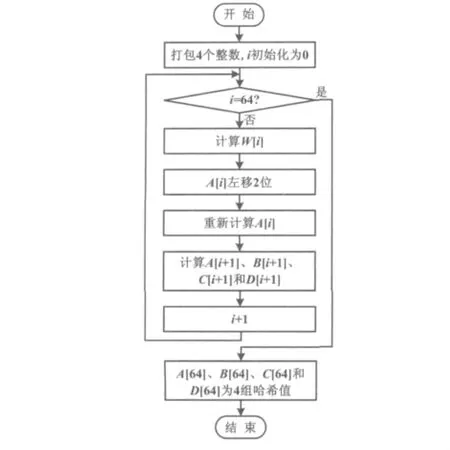
图2 哈希算法Fig.2 Hash algorithm
在哈希算法的预处理阶段,首先将4个整数打包成一个128位数,放入XMM0寄存器。W数组存放左移计算的临时结果,W[i]的值依赖于 W[i-3]、W[i-7]、W[i-11]和 W[i-15]相互异或的结果;A、B、C、D数组适用于存放每组哈希计算的临时结果。循环结束,A[64]、B[64]、C[64]和 D[64]就是保存的哈希计算结果。这样就可以一次计算4个哈希值。
2.2.3 并行处理
为了进一步提高协议栈的处理能力,可以在多核CPU上实现并行线程[9],但将单进程的协议栈改成多进程协议栈,将不可避免地遇到共享资源访问的问题。因此,本文提出一种多核CPU下的多进程划分方式。协议栈线程分配如图3所示。
Intel的E5200有2个CPU核,由于网关进程的运算负载相对较重,而且网关进程是与TCP/IP进程有关联的唯一进程,因此将网关进程与TCP/IP进程分别运行在2个处理核心上。
为了实现动态的负载均衡、减少进程间的通信开销,网关进程的负载会随着网络数据流量的变化而变化,因此需要创建多个处理线程,以达到负载均衡。网关进程创建的子线程之间通过共享缓存传递数据,减少了实际传输的数据量。
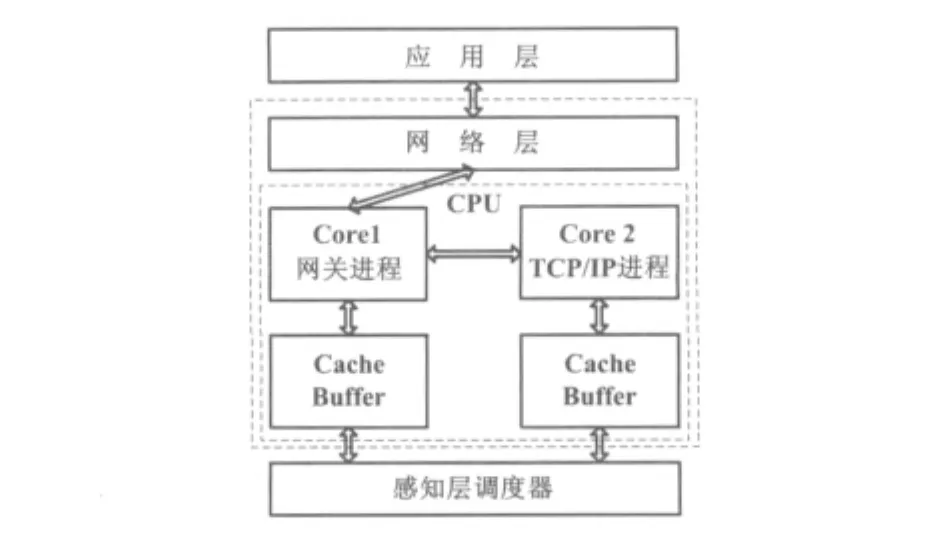
图3 协议栈线程分配Fig.3 Thread allocation of the protocol stack
3 测试
评估系统带有3 GB内存和1个Intel E5200处理器。CPU有2个运行在2.5 GHz的处理核心,这2个核心共享2 MB Cache,操作系统是Windows XP。为了测试协议栈的有效吞吐率,本文采用Darpa-1和Darpa-2[10]作为入侵检测的数据集,具体如表3所示。
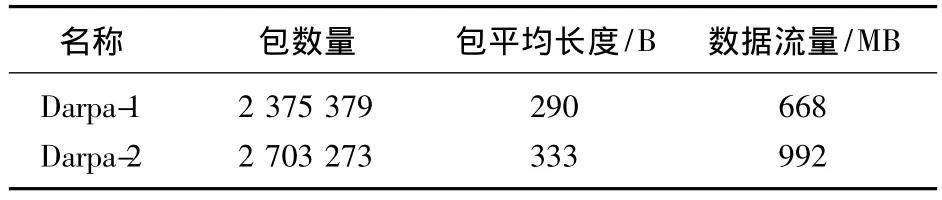
表3 数据集Tab.3 Data set
首先使用表3中的数据集Darpa-1和Darpa-2测试优化前的协议栈,依次为协议栈添加内存优化、SSE指令计算和多进程功能;再对CPU进行多线程压力测试。优化前,Darpa-1的吞吐率与Darpa-2的吞吐率略高,大约为1.2 Gbit/s。采用内存优化方法之后,两者的吞吐率分别达到1.7 Gbit/s和1.8 Gbit/s;进一步采用SSE指令加速计算的优化方法后,两者的吞吐率分别达到3.1 Gbit/s和3.5 Gbit/s;最后采用双进程的优化方案,两者的吞吐率可分别达到4.9 Gbit/s和5.6 Gbit/s。优化后的协议栈对每一个流量的吞吐率都在原始系统的4倍以上。
操作系统调度的最小单位是线程。线程压力测试结果如图4所示。由图4可知,网关进程创建线程数量达到一定值之后,协议栈的吞吐率反而下降,这是因为线程之间的切换会带来额外的开销。对于大量的数据流量,并不能通过创建无限多的线程来提高协议栈的吞吐率,这样做将使收益小于开销,导致吞吐率下降。由于优化的主要目标是提高工业物联网协议栈的吞吐率,因此选择一个最大线程数是非常有必要的。由图4可知,当线程数量为4时,吞吐率最高。此外,整个数据集的数据包平均长度越大,其吞吐率也越大。这是因为每发送或者接收一个数据包都会带来校验码计算、查找等操作的系统开销。

图4 线程压力测试Fig.4 Stress tests of the threads
利用特定资源协议栈函数进行优化之后,协议栈在内存操作、哈希计算和查找操作的耗费时间明显下降,达到了预期目标。函数优化前后耗时比如表4所示。
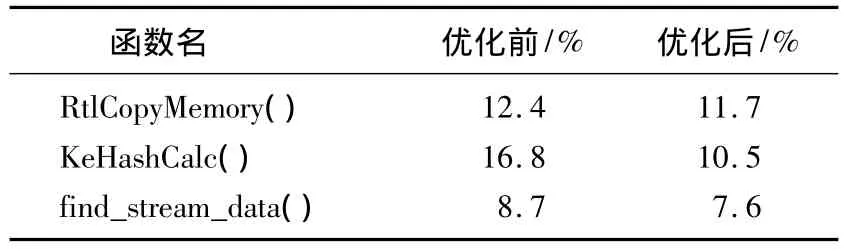
表4 函数优化前后耗时比Tab.4 Time-consumption of the function before and after optimization
4 结束语
工业物联网的数据流量越来越大,对高速入侵检测是一个严峻的挑战。本文提出了适用于工业物联网的协议栈优化方案。在PC机现有资源的情况下,该方案利用内存DMA解决了数据的高速流量问题,并利用CPU并行指令解决了协议栈的计算负载问题。测试表明,在工业物联网络架构上,优化后的协议栈完全能够满足工业物联网络高速入侵检测的需求。
[1]干开峰.嵌入式EPA安全网关开发——安全功能模块的设计与实现[D].重庆:重庆邮电大学,2007.
[2]杨云,宓佳,党宏社.嵌入式入侵检测系统的设计与实现[J].计算机工程与设计,2011,20(1):21 -23.
[3]Vasiliadis G,Polychronakis M,Antonatos S,et al.Regular expression matching on graphics hardware for intrusion detection[C]//Proceedings of the 12th International Symposium on Recent Advances in Intrusion Detection.Saint-Malo,France:Springer Verlag,2009:265 -283.
[4]徐乾,鄂跃鹏,葛敬国,等.深度包检测中一种高效的正则表达式压缩算法[J].软件学报,2009,20(8):2214 -2226.
[5]Xia Gao,Liuy Bin.Accelerating network applications on X86 - 64 platforms[C]//Proceedings of IEEE Symposium on Computers and Communications.Ricci on e,Italy:IEEE Computer and Communications Societies,2010:906 -912.
[6]陈卓,杨爱良,王骥,等.基于PLB总线的多通道SGDMA设计[J].航空电子技术,2009,40(1):12 -15.
[7]陈虎,欧彦麟,陈海波,等.面向多核处理器平台的并行Hash JOIN算法设计与实现[J].计算机研究与发展,2010,47(z1):171-175.
[8]张顺利,张定华,李明君,等.基于SIMD技术的锥束ART算法快速并行图像重建[J].仪器仪表学报,2010,31(3):630 -634.
[9]杨春阳,段勃勃,袁淮,等.多核平台上基于可声明并行性的程序优化框架[J].东北大学学报:自然科学版,2011,32(1):22 -26.
[10]MIT Lincoln Laboratory.MIT DARPA intrusion detection data sets[Z/OL].[2010 - 09 - 25].http://www.ll.mit.edu/mission/communications/ist/corpora/ideval/data/index.html.
