一种基于Rough集的案例推理模型的构建
2012-07-05龚锦红凌仕勇
龚锦红,凌仕勇
(华东交通大学1.电子与电气工程学院;2.现代教育技术中心,江西南昌330013)
案例推理(case-based reasoning,CBR)技术是近年来人工智能领域中兴起的一项新兴的推理技术[1],其通过检索历史案例,充分利用以前的经验,推理得到新问题的解决方案。一个典型的案例推理过程的基本步骤包括4个主要过程:案例检索、案例重用、案例修正和案例保存。通常,案例的恰当表示、合理组织、获取的有效性以及案例检索的有效性及快速性关系到问题求解的效率和质量。
Rough集理论[2]由波兰数学家Pawlak在1982年提出,以处理含糊和不精确性问题。Rough集理论在处理含糊信息方面,具有不需要外界信息和先验知识的独特优点,能够依赖于统计知识提炼规则,有效地解决实践中遇到的不精确性属性难题,在对问题的计算分析方面具有客观性。因而,应用Rough集理论对案例推理系统具有积极的作用。
1 基于Rough集理论的案例推理模型
在解决问题时,可借助于该类问题的历史经验进行推理得出该问题的解决方法。在案例推理系统中,对某个问题的表述及解决方法通常用一个或多个案例来表达,这些案例按一定的结构和模式组织在案例库中。当某类新问题出现时,此推理系统依据相关的事实和索引,在案例库中检索得到相似的案例,并对其求解策略进行分析,重用,得到此问题的求解;最后,将此问题及相应的求解模式和策略作为一个新的案例追加到系统的案例库中,供日后所需。案例库是存储过去案例的空间,随着时间的推移,案例库中存储的案例不断增加,会存在失败的案例及冗余的案例,使得案例推理系统的推理质量和效率大大降低。应用Rough理论可以对案例库进行有效的知识约简,在优化案例库的同时,提高案例推理的效率和质量,积极地解决案例推理系统所面临的难题[3]。
1.1 案例的表示
在Rough集理论中,案例库是以一个二维表格的决策系统形式来表示的,即S=(U,A,V)。其中,U定义为非空有限集,即案例全域;A代表案例的条件属性,是案例的描述特征属性集,A=﹛f1,f2,…,fn﹜,f1f2…fn为不同的案例特征属性;V代表案例的决策属性,即解特征属性集,V=﹛fS1,fS2,…,fSn﹜,其中fS1fS2…fSm为不同的案例解特征属性。在决策表中,行代表研究的案例对象,列代表其属性,行代表案例库中的某个案例。
1.2 案例库的预处理
应用Rough集理论在案例推理系统中时,为了优化案例库,并处理不完备数据及不精确知识表达的问题,在案例检索前须采用Rough Set对案例库进行初步处理,如对初始数据的补全、离散化处理以及对案例知识进行约简等等[4]。
1.2.1 数据补全
形式上描述为:案例库中定义的S=(U,A,V),进行补全后的数据集={x∈U|∀a∈A,a(x)≠T},T为缺失数据,集合A为全集U中的属性集合。
数据补全简单的有均值补全和模式补全,均值补全是,若其属性数据是数值类型的,则取属性均值为补全后的数据。若其属性数据是字符类型的,则取出现概率次数最多的属性值作为补全后的数据。
1.2.2 数据离散化
采用Rough集对案例和案例库进行处理时,要求案例库中的属性值必须用离散数据进行表示。但是,实际中数据多数是连续的,因此,必须首先离散化处理连续的数据,然后再进行相关分析[5]。对联系数据进行离散化应满足:①信息处理复杂度应尽可能小,即离散后属性维数尽量小,也就是属性值种类尽量少;②信息熵丢失少,即离散后的属性值信息丢失应尽量少。
1.2.3 知识约简
知识约简是Rough集理论的核心内容之一,就是在保持知识库的分类和决策能力不变的条件下,删除一些无关或多于的信息。设C表示数据的集合,ω(C)是C的权重集,D是最后得到的约简集,算法描述如下:
①设D=φ。②设b是有最大åw(C)的属性,ω(C)表示集合D的没有放入的,集合C的权重集总和。③将b加入到D中。④从S中移除包含b的属性集。⑤若S=φ,得到最终的最小约简,返回集合D,否则转到②继续执行。
例如,对于对象C={{fish,cat,dog},{cat,man},{man,dog},{cat,fish}},令ω=1。首先设定D=φ,因为cat是集合C中最经常发生的属性,把cat加入到D中且需从集合C中移除含cat的项,这样C={{man,dog}};继续上面发现dog是接下来的集合中最经常发生的属性,将dog加至集合D中且移除含dog的项,最后,C=φ,得到集合D={cat,dog}。
1.3 案例库的构建
案例库构建是对案例进行处理的中心,首先利用类DTImporter从基础数据库中导入初始数据;然后利用GetMethod(SCALER)对数据进行预处理和离散化处理;接下来采用Johnson约简方法,即GetMethod(JOHNSONREDUCER)对数据进行约简;最终产生系统的推理规则。最后写入数据库或内存中,供以后的浏览案例库,维护(增,删,改)案例库及测试使用。
案例库构建的代码片段如下[6]:
Method*method;
//数据导入,决策表方法(DECISIONTABLE)
DTImporter dtIm;
method=&dtIm;
SetStruc(Creator::Create(DECISIONTABLE));
GetStruc().Apply(*method);
//数据离散化(SCALER)
method=GetMethod(SCALER);
GetStruc().Apply(*method);
//知识约简(JOHNSONREDUCER)
method=GetMethod(JOHNSONREDUCER);
method->SetParam(“DISCERNIBILITY=Object;SEED=1111”);
GetStruc().Apply(*method);
//规则产生(RULEGENERATOR)
method=GetMethod(RULEGENERATOR);
GetStruc().Apply(*method);
1.4 案例检索
应用Rough集进行案例检索的基本过程为:对某个新问题,根据模型找出案例属性的索引,求取属性集合中等价类属性集合的交集,通过检索找出相似的案例;若没有从案例库中找到相似的案例,则重新选择较合适的案例索引进行检索。案例的Rough集检索算法流程大致如图1所示[7]。
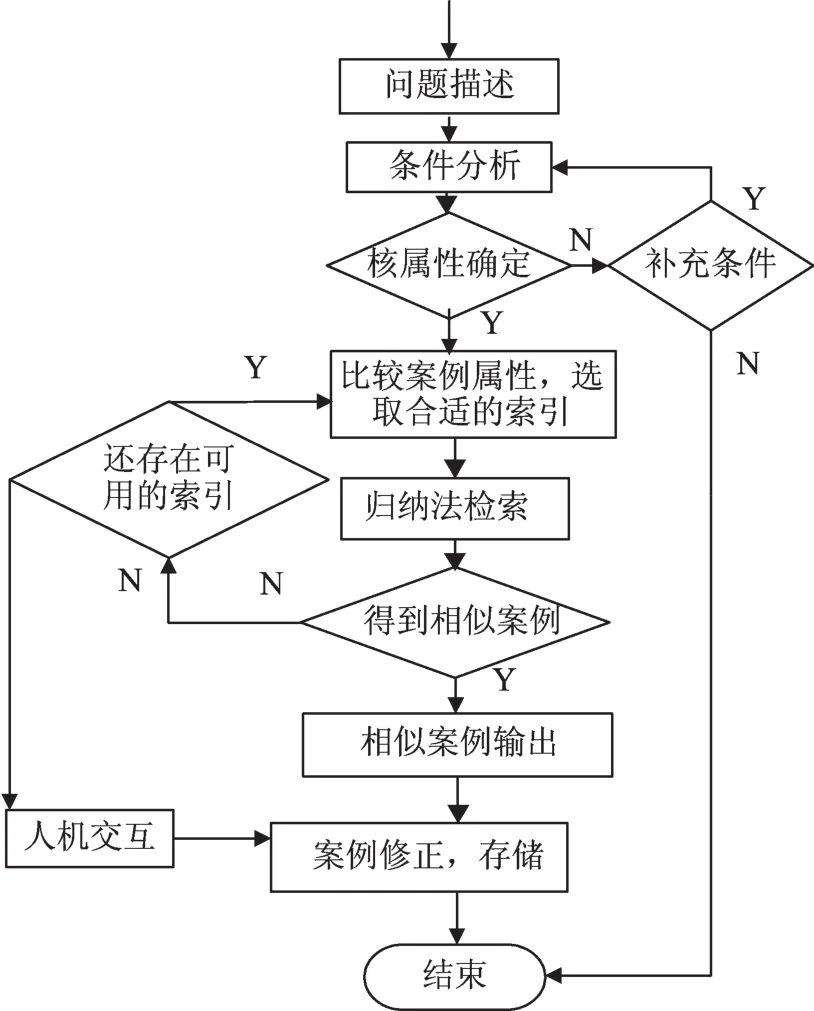
图1 案例推理系统的Rough集检索算法流程图Fig.1 Rough set retrieval algorithm flow chart of case reasoning system
2 系统应用示例
现以文献[8]中稀土萃取分离生产过程的料液处理量,产品纯度等指标的优化控制为例,将Rough集推理与案例推理相结合,对稀土萃取分离过程中的萃取剂、料液和洗涤液的流量值通过构造案例,将稀土萃取分离过程的优化设定控制问题转变为对案例模型的分析,案例库的构建,案例的检索,重构,复用及对案例库的增删改过程,从而确定实际过程的动态模型。
将现场采集到的30组数据作为测试集如表1所示,针对该推理系统进行精确性和可行性的测试。
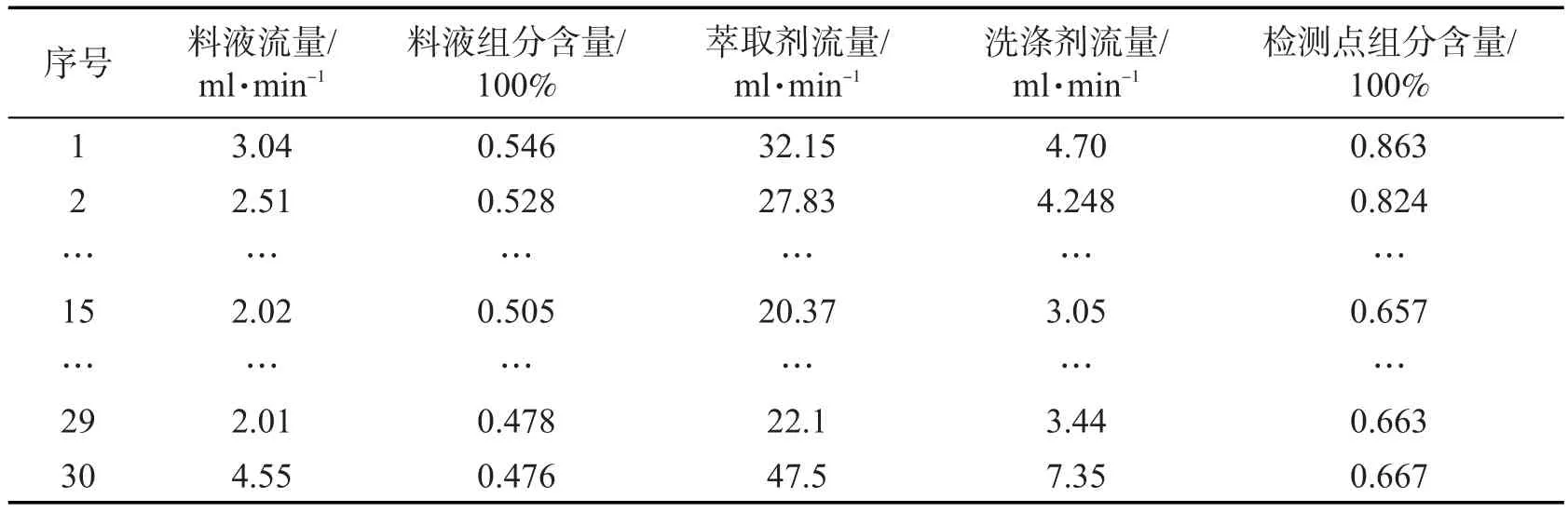
表1 测试集数据Tab.1 Testing set data
输入为单个测试集的案例工况描述特征,输出为实际解特征和基于Rough集的归纳法检索方法得到的解特征如图2所示。
案例检索结果与实际采样数据比较,可发现,经案例检索后导出的特征数值与实际值非常接近,各项误差小于2%。
对整个测试集的30组数据分别采用基于欧拉距离的近邻检索法和基于Rough集的归纳法,两种检索结果和实际值绘制成对比图。以检测点组分含量测试对比结果为例绘制测试对比图如图3所示。
采用近邻法和归纳法分别得到这两种检索方法的解结构特征和实际值解特征的误差对比图。此处以检测点组分含量测试误差为例绘制对比图如图4所示。

图2 单元测试归纳法检索结果Fig.2 Retrieval results of unit testing result induction

图3 检测点组分含量测试对比图Fig.3 Testing contrast of component content on check point
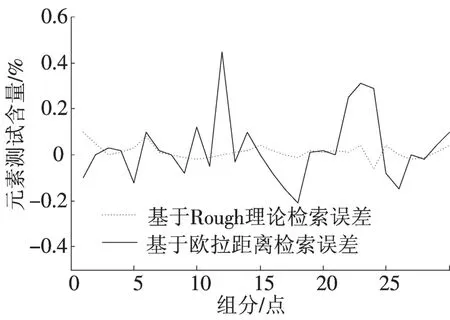
图4 检测点组分含量测试误差对比图Fig.4 Testing error contrast of component content on check point
从图中可以看出,两种检索结果和实际值之间具有一定的误差:Rough集推理模型与实际值的误差范围比较小,基本围绕0%这个中心点上下浮动,最多10%;而基于欧拉距离的模型与实际值的误差范围较大并且极不平均,曲线呈不规则的形状有些误差达到了50%。从对比的结果可以看出这种案例推理模型相对于基于欧拉距离的模型更接近于实际工程数值,在案例推理过程中具有很强的可行性和精确性。
3 结论
结合Rough集对案例知识进行推理,在对案例进行分析形成案例模型,构造Rough集的属性集合,进而形成Rough集案例模型,根据不同问题采用不同方案进行快速检索,能有效地解决实际工况中的不完备和不确定性问题。实验证明,该推理模型构建方法对解决实际问题是客观可行的。
[1]WATSON I,MARIR F.Case-based reasoning:Areview[J].The Knowledge Engineering Review,1994,9(4):335-381.
[2]PAWLAK Z.Rough sets[J].International Journal of Computer and Information Seience,1982(11):341-356.
[3]HOANG XUAN HUAN.Case-based reasoning with rough features[J].Knowledge-Based System.2003(4):321-327.
[4]DUNTSCH I,GEDIGA G.Statistical evaluation of rough set dependency analysis[J].International Journal of Human Computer Study,1997,46(5):589-604.
[5]LINGRAS P.Application of rough pattern,Rough set in datamining and knowledge discovery[J].Series Softcomputing,Physical Velag(Springer),1998(2):369-384.
[6]龚锦红.基于案例推理的稀土萃取分离过程优化设定控制方法研究[D].南昌:华东交通大学,2007:221-222.
[7]龚锦红,杨辉,衷路生.稀土萃取分离过程中的Rough集案例推理方法[J].第二十九届中国控制会议(No 29,CCC’10),2010(7):1701-1706.
[8]杨辉,柴天佑.稀土萃取分离过程的优化设定控制[J].控制与决策,2005,20(4):398-407.
