共振峰动态特征在法庭话者鉴别中的应用研究
2012-06-15张翠玲苏
张翠玲苏 斌
(1 中国刑警学院 辽宁 沈阳 110035;2 扬州市公安局开发区分局 江苏 扬州 225009)
共振峰动态特征在法庭话者鉴别中的应用研究
张翠玲1苏 斌2
(1 中国刑警学院 辽宁 沈阳 110035;2 扬州市公安局开发区分局 江苏 扬州 225009)
采用似然率方法对汉语两个复合元音的共振峰动态特征进行了量化分析和话者区分测试研究。对20位女性发音人正常状态下的两次发音进行比较研究,以/ai/和/iao/两个元音为代表,测量每位发音人两个元音的前三个共振峰的起点、中点和终点的频率值进行统计分析。采用似然率方法进行话者区分测试,进而对元音共振峰的动态性及其在话者鉴别中的作用进行了综合评价。
共振峰 话者鉴别 似然率 动态性
1 引言
元音和浊辅音的共振峰形态、走向和频率特征反映了发音人语音特异性,是进行话者区分最重要的依据。因此,国内外的法庭语音学家一直都很重视共振峰参数信息的提取。
在进行共振峰测量时,传统的做法都是测量某一元音段的共振峰频率均值。但是,这些平均后的测量结果不足以充分反映发音人特有的共振峰动态轨迹信息。因此,如何有效提取语音共振峰的动态信息对于话者鉴别来说是极为重要的。
长久以来,法庭话者鉴别技术一直停留在人工的形态比较和简单的数值比较上。然而,由于语音具有较大的变异性,同一发音人自身的几次发音也会有差异,这就决定了只是简单地依靠相似性比较而得出同一认定或否定排除的结论未免缺乏准确性和可靠性。国内外的统计学家早就意识到了这一问题,因而提出在法庭证据价值的评价上应引入概率估计。DNA在这方面已经做出了很好的范例,似然率方法在DNA证据上的分析和评判上已经获得成功。
按照1993年美国高院规定的Daubert准则,法庭证据的检验方法必须经过测试而且错误率已知。顺应这一要求,近十年来,法庭语音学家效仿DNA分析技术,开始将似然率评价体系引入法庭语音的比较,目前已经取得了很好的效果。就法庭语音比较而言,需要确定检材(通常是罪犯的语音)和样本(通常是嫌疑人的语音)的相似性或差异性究竟是来源于同一话者还是来源于不同话者,对于类似的不确定事件,使用概率估计是最好的解决方法。
似然率方法不仅要考虑检材和样本的相似和差异情况,还要参考检材和样本的特征在背景人群中的概率分布情况,最后计算出这些特征来源于同一个人的概率是来源于不同人的概率的多少倍。在话者鉴别技术中,似然率就是语音检材和样本来源于同一话者的假设为真的证据概率与二者来源于不同话者假设为真的证据概率的比值。其计算公式如(1)所示:
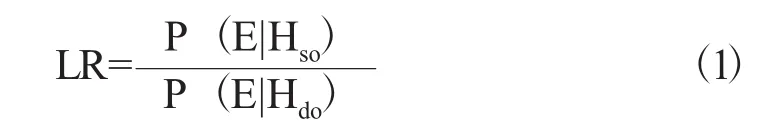
其中,LR(Likelihood Ratio)代表似然率,p代表概率,Hso为同源假设(起诉假设),Hdo为非同源假设(辩护假设),E为法庭语音比较的证据。似然率实际上是相似程度 (Similarity)和典型程度(Typicality)的比率。LR值大于1表明支持起诉假设(检材与样本同源);小于1表明支持辩护假设(检材与样本非同源);等于1表明支持起诉假设和支持辩护假设的程度是相等的,也可以理解为既不支持起诉假设也不支持辩护假设,因此没有价值。在实际语音案件中,如果得到的似然率LR值为1000,即同源假设条件下获得检材和样本之间差异(或相似)的概率与非同源假设条件下获得检材和样本之间差异(或相似)的概率比值为1000,那么,它的含义就是:不管在引入该语音证据之前你的信心如何,现在你应该1000倍地相信检材语音和样本语音来源于同一个人。
2 实验材料和方法
2.1 语料录制
本文以二合元音/ai/和三合元音/iao/为代表,各选取20个词组作为发音文本。发音采用朗读语体进行,形式为:“哀,哀怨的哀;要,要挟的要”等,字调均为阴平。发音人是中国刑警学院的20位女学生,年龄在21~24岁之间,普通话比较标准,没有明显的方言特征或言语障碍。实验室条件录音,采用Cooledit2.0软件进行麦克直录,采样率16KHz。录音分两次进行,时间间隔为一周。
2.2 测量方法
采用Praat语音分析软件对每位发音人两次发音的语音样本进行声学分析,采用人工手动测量的方法测量/ai/和/iao/两个元音的前四个共振峰在三点(起点、中点、终点)的频率值(见图1)。每个发音人/ai/和/iao/测量的音节数均为20。
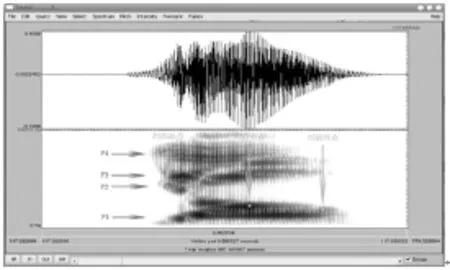
图1 /iao/的共振峰测量方法
2.3 统计分析
将所有20个发音人两次发音的/ai/和/iao/的三点共振峰数据进行比较分析。考虑到实际案件条件下语音检材多为电话录音,受传输带宽所限,通常只有前三个共振峰可以利用。因此我们仅对两个元音的前三个共振峰进行了同一话者的语音对和不同话者语音对的似然率比较分析。
似然率的计算采用Aitken和Lucy等人提出的多变量核密度似然率(Multivariate Kernel Density LR,MVLR)计算公式。该公式分为分子和分母两部分:分子用来评价检材和样本的相似性(也可以理解为差异性),分母用来评价二者的特征相对于背景参考人群的典型性。
3 结果和分析
3.1 /ai/的话者区分能力测试
3.1.1 三点比较分析
使用似然率作为功能函数对大量同一话者和不同话者的语音对进行测试时,同一话者语音对的LR值应大于1,而不同话者语音对的LR值应小于1。LR值的大小表明数据本身内在的区分能力。话者区分测试的结果一般用可靠性函数图谱来表示(以下简称Tippett图)。它表示的是对同一话者语音对和不同话者语音对的log10LR值的累积分布。其中,横坐标是以10为底的LR的对数值。向右递增的曲线为同一话者测试,表示Log10LR值大于或等于对应横坐标Log10LR值时同一话者比较所占的比例;向左递增的曲线为不同话者测试,表示Log10LR值小于或等于对应横坐标Log10LR值的不同话者比较所占的比例。
理想的情况是:如果两个语音样本来自同一话者,则LR应远远大于1,即Log10LR>>0;如果两个语音样本来自不同话者,则LR值应远远小于1,Log10LR<<0;Log10LR等于0,表明来自同一话者或不同话者的程度相等,因此无意义。验证性实验中,由于每个语音对的归属是已知的,因此根据Tippett图中同一话者和不同话者测试曲线的分布可以评测系统进行话者区分的有效性,包括计算方法和参数的有效性。
为了比较三个时间点的共振峰频率值的话者区分差异情况,我们分别对三点的频率值进行了测试分析。图2、3和4分别给出了利用/ai/的起点、中点和终点进行话者区分测试的Tippett图。
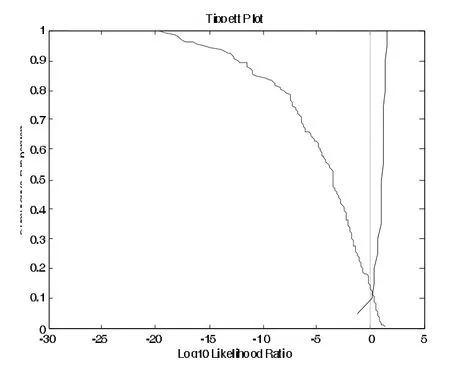
图2 /ai/的F1~F3起点频率值似然率计算的Tippett图
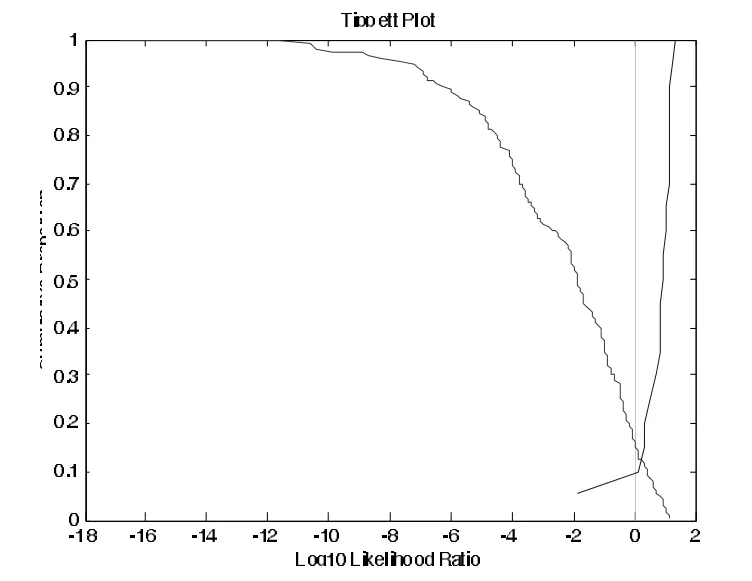
图3 /ai/的F1~F3中点频率值似然率计算的Tippett图
三个Tippett图中,向右倾斜的曲线表示的是同一话者的测试,向左倾斜的曲线表示的是不同话者的测试。结果表明:利用/ai/的前三个共振峰的起点频率值进行测试的等误率(两条曲线交点对应的值)为12%(见图2),错误排除(将同一话者对误判为不同话者对)的概率为15%,错误认定(将不同话者对误判为同一话者对)的概率9.1%。利用/ai/的前三个共振峰的中点频率值进行测试的等误率也是12%(见图3),错误排除的概率为17%,错误认定的概率为10.2%。利用/ai/的前三个共振峰的终点频率值进行测试的等误率为9.2%(见图4),错误排除的概率为9.5%,错误认定的概率为9.2%。
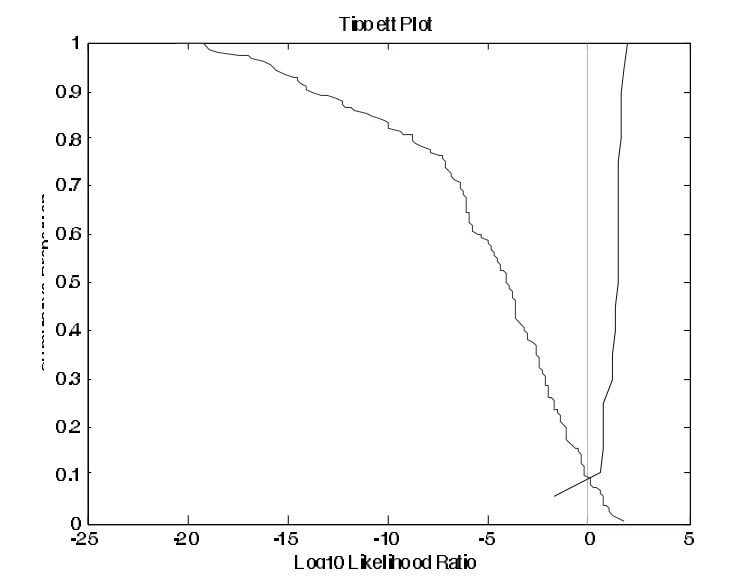
图4 /ai/的F1~F3终点频率值似然率计算的Tippett图
综合/ai/的前三个共振峰三点分别测试的结果来看,仅提取一点的共振峰频率值的区分效果大体相似,终点值的区分效果略好于起点值和中点值。这一点从/ai/的宽带语图中也可以得到解释,即该元音从起点到中点的变化相对较小,动态性不明显;而从中点到终点的变化较大,动态性很强。由此可见,动态性越强,话者区分的效果越好。
3.1.2 三点综合分析
为了检验/ai/的前三个共振峰三个时间点频率值的综合效果,我们又进行了三点频率值的综合分析,即每个话者元音起点、中点和终点的前三个共振峰的频率值共9个参数值合并统计,结果见图5。
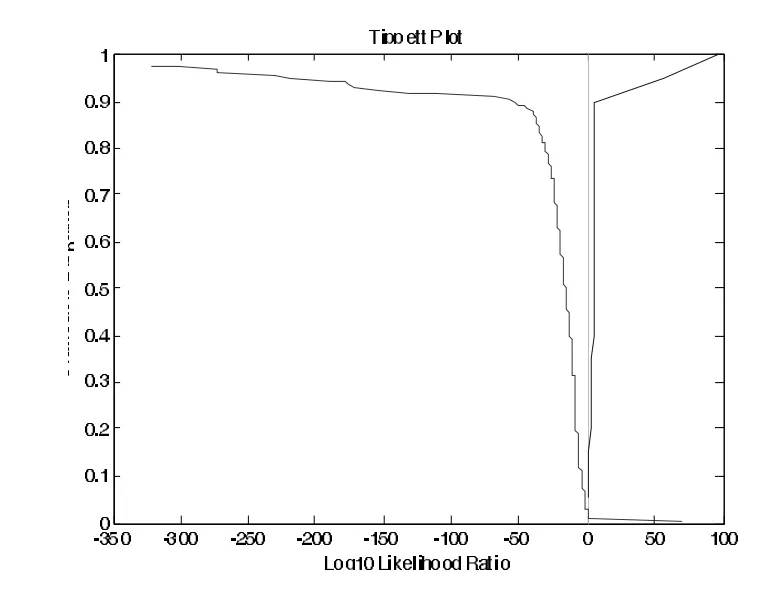
图5 /ai/的F1~F3三点频率值似然率计算的Tippett图
由图5可知,同一话者的测试曲线和不同话者的测试曲线已经完全分开,没有交点,即等误率为0。这意味着利用/ai/的9个共振峰数据已经将同一话者对和不同话者对全部区分开来。另外,从不同话者的测试曲线可以看出,将不同话者对误判为同一话者对的概率为1%,即错误认定的概率为1%;从同一话者的测试曲线可以看出,将同一话者对误判为不同话者对的概率为0,即错误排除的概率为0。由此可见,对于/ai/而言,前三个共振峰的起点、中点和终点的频率值已经足以进行话者的有效区分,区分效果非常理想。
与三点分别统计的结果比较而言,将/ai/的前三个共振峰频率的起点值、中点值和终点值合并分析时,话者区分的效果明显提高,等误率及同源/非同源区分的错误率都明显降低。这表明动态特征的数据越多,话者区分的效果越好。多点测量的数据分析结果明显好于任何一点测量的数据或者平均频率值。先前对于单元音的话者区分能力进行测试的研究结果表明了很有限的话者区分能力,利用单个元音(/i/、/ü/、/a/、/e/)的共振峰频率的平均值统计的话者区分的等误率基本上都在20%以上。这足以说明元音共振峰的动态轨迹特征在话者鉴别中的重要价值。因此,可以推断:采用共振峰动态轨迹追踪技术将提取更多的动态信息,话者区分的效果将会更好。
3.2 /iao/的话者区分能力测试
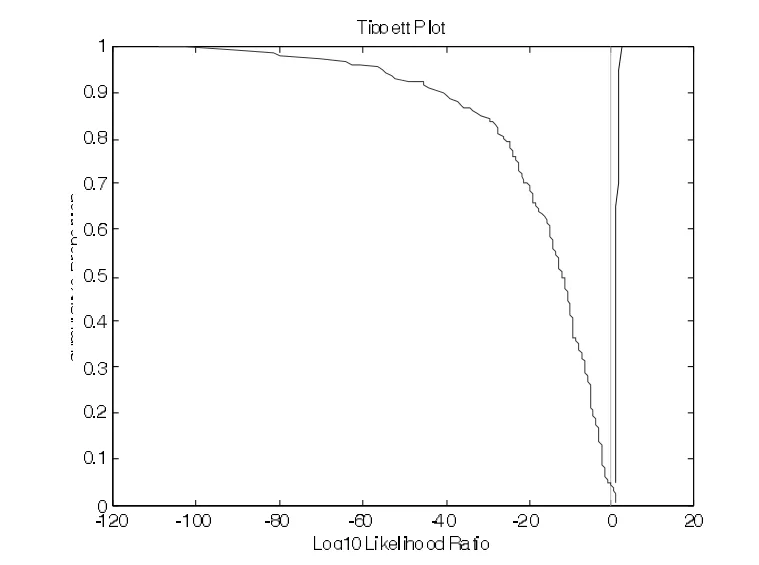
图6 /iao/的F1~F3起点频率值似然率计算的Tippett图
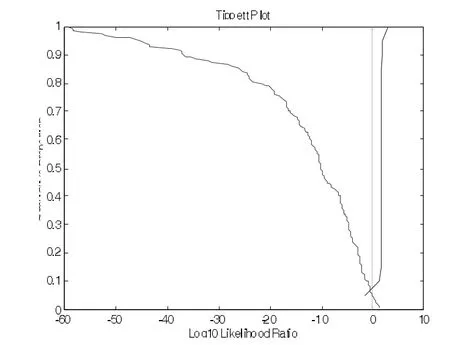
图7 /iao/的F1~F3中点频率值似然率计算的Tippett图
采用与3.1中同样的分析方法对/iao/的前三个共振峰频率的起点值、中点值和终点值进行测试分析。结果见图6-9,其中,图6-8是分别利用/iao/的前三个共振峰的起点、中点和终点频率值计算得到的Tippett图。
测试结果表明:利用/iao/的前三个共振峰的起点频率值进行话者区分的等误率为0,错误排除率为4.5%,错误认定率0。利用/iao/的前三个共振峰的中点频率值进行话者区分的等误率为6.2%,错误排除率为5%,错误认定率为7.5%。利用/iao/的前三个共振峰的终点频率值进行测试的等误率为5.5%,错误排除率为5.4%,错误认定率为7.5%。与/ai/相反,起点值的区分效果明显好于中点和终点。而中点的效果最差。
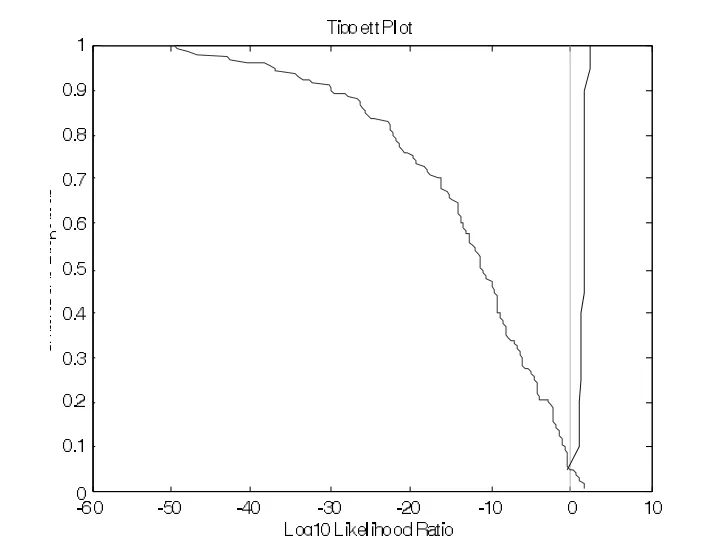
图8 /iao/的F1~F3终点频率值似然率计算的Tippett图
图9是/iao/的前三个共振峰频率的起点值、中点值和终点值合并似然率计算的Tippett图。结果表明:三点综合分析的等误率为0,错误排除和错误认定的概率均为0。同一话者对与不同话者对完全区分开来,没有一例错判,正识率为100%。
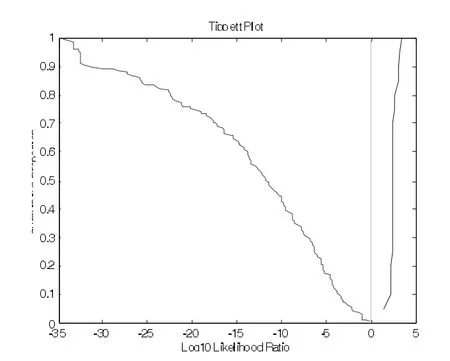
图9 /iao/的F1~F3三点频率值似然率计算的Tippett图
综合/iao/的前三个共振峰频率值的测试结果发现,与/ai/的测试结果相似,三点综合分析的效果明显优于任意一点单独分析的结果。不同的是,/iao/的共振峰由起点到中点轨迹的动态性明显高于中点到终点,所以其起点的区分效果好于中点和终点。这和/ai/的分析结论是一致的。
3.3 /ai/、/iao/比较
表中列出了利用/ai/和/iao/的前三个共振峰的三点频率值进行话者区分测试的比较结果。其中,ERR代表等误率,SS代表相同话者对错判的概率,DS代表不同话者对错判的概率。
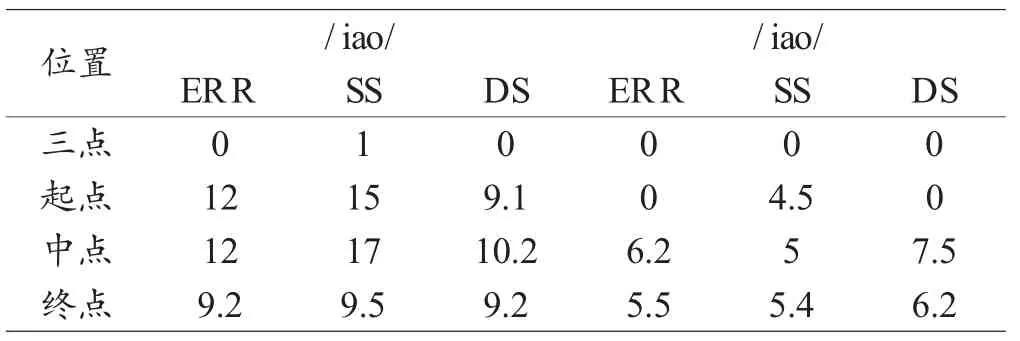
表 /ai/和/iao/的话者区分测试结果(%)
从两个元音进行话者区分测试的结果来看:对于/ai/来说,不论是三个点的综合分析还是各个点单独分析,同一话者对错判(即错误排除)的概率都高于不同话者对错判(即错误认定)的概率。而对于/iao/来说,除起点以外,不同话者对错判的概率略高一些。此外,从Tippett图的曲线分布来看,两个元音的同一话者比较的数据比较集中,而不同话者比较的数据则分散得多,这应该是来源于较大的话者之间差异所致。
从总的结果看,两个元音测试的等误率均为0,这说明两个元音的话者区分能力是很强的,话者区分的效果非常理想。当然,比较而言,/iao/的话者区分效果明显好于/ai/,这应该是由于/iao/比/ai/的共振峰轨迹变化幅度更大,动态性更强所致。无论是/ai/还是/iao/,当起点、中点、终点分别做话者区分能力测试时,其等误率和同源/非同源区分的错误率都较高;将所有点进行综合测试时,其各种错误率大大降低。即三个点综合分析的效果明显好于单个点的比较,这说明进行话者比较时应该选取尽量多的测量点或参数。特征点越多,话者的特异性越强,越容易区分。
4 结论
本文采用似然率的分析方法,对20名女性发音人的/ai/和/iao/两个元音进行了话者区分的测试分析。对前三个共振峰起点、中点和终点的频率值进行似然率分析的结果表明了两个元音的话者区分能力及效果。研究表明,共振峰的动态性对话者鉴别来说是极为重要的,动态性越强,话者区分的效果越好,因此三合元音和二合元音的话者区分效果好于单元音。此外,多点测量优于单点测量,特征参数越多,话者区分的效果越好。在连续语流中,单元音也会表现一定的动态性,因此仅仅测量共振峰的频率均值进行话者鉴别是不够的。利用共振峰轨迹追踪技术,应该会取得更好的区分效果。
目前的测试结果表明了两个元音具有很强的话者区分能力,其他元音的话者区分能力还有待进一步测试。本研究测试的是实验室条件下的朗读语料,而且音节前后环境基本相同。实际案件条件下的自然口语语料的区分效果应该会有所减弱,但是结果如何还有待测试。此外,本实验的测试对象均为女性发音人,一般而言,女性语音由于基频较高,声学显示较男性语音差,声学测量有一定难度。如果对男性语音进行测试,效果应该会更好。
本研究的意义在于量化分析共振峰的动态性及其在话者鉴别中的作用,而不是单纯比较两个元音的动态性。似然率分析方法为共振峰的动态性在话者鉴别中的应用价值提供了客观的量化评价结果,这有利于提高法庭话者鉴别方法的定量化和标准化,促进法庭话者鉴别客观化和科学化进程。
1.Aitken,C.G.G.,Taroni F.2004.Statistics and the Evaluation of Evidence forForensic Scientists. Chichester,U.K.:Wiley
2.Baldwin,D.J.2005.Weight of Evidence for ForensicDNAProfiles.Chichester,U.K.:Wiley
3.Daubert,U.S.SupremeCourt.1993.Daubert v.MerrellDowPharmaceuticals,Inc.113SCr2786
4.RodriguezJ.G.,RoseP,etal.2007.Emulating DNA:rigorous quantification of evidential weight in transparent and testable forensic speaker recognition.IEEE Transactions on Audio, Speech, and Language Processing, IEEE Signal Processing Society,15(7):2104-2115
5.Rose P.2003.The technical comparison of forensic voice samples, Expert Evidence,Issue 99:Thomson,Sydney,Australia
6.Kinoshita Y.2001.Testing realistic forensic speaker identification in Japanese: a likelihood ratio-based approach using formants.Ph.D.thesis,Australian National University
7.RoseP,OsanaiT,KinoshitaY.2003.Strength of forensic speaker identification evidence:multispeaker formant-and cepstrum-based segmental discrimination with a Bayesian likelihood ratio as threshold.Speech LanguageandtheLaw.10(2):179-202
8.Rose,P.2007.Forensicspeakerdiscrimination with Australian English vowel acoustics,Proceedings of the 16th International Congress of Phonetic Sciences. Universit?t de Saarlandes, Saarbrücken,Germany:1817-1820.
9.Morrison.G.S.2008.Forensicvoicecomparison using likelihood ratiosbased on polynomial curvesfitted to the formant trajectories of Australian English/aI/,InternationalJournalofSpeech,Language and the Law.15:247-264
10.Morrison,G.S.2009.Likelihood-ratiofor nsic voice comparison using parametric representations of the formant trajectories of diphthongs.Journal of the AcousticalSocietyofAmerica,125:2387-2397
11.Aitken,C.G.G,Lucy,D.2004.Evaluation ofTrace Evidence in the Form ofMultivariate Data. AppliedStatistics.Vol.54:109-22
12.Morrison,G.S.Matlab implementation of Aitken&Lucy’s(2004)forensiclikelihood-ratio software using multivariate-kernel-density estimation,software versionof17July2008,http://geoff-morrison.net/
13.Zhang C.,Morrison G.S.,Rose,P.2008.Forensic speaker recognition in Chinese:A multivariate likelihood ratio discrimination on /i/ and /y/,Proceedings of Interspeech 2008 Incorporating SST.International Speech Communication Association:1937-1940
14.MorrisonG.S.,ZhangC.,Rose,P.2011.An empiricalestimateoftheprecisionoflikelihoodratiosfroma forensic-voice-comparisonsystem.SubmittedforForensic ScienceInternational,Vol,2008:59-65
