以分布式计算实现电信数据分析业务加速的研究
2012-06-11闻剑峰石屹嵘
闻剑峰,石屹嵘
(中国电信股份有限公司上海研究院 上海200122)
1 引言
为了提高电信行业的工作效率和服务质量,建立灵活的营销机制,推动新业务的开展和适应激烈的市场竞争,商业智能(business intelligence,BI)开始进入电信行业。BI应用在电信行业又称作电信数据分析系统。随着电信全业务运营时代的到来,电信传统的数据分析系统正面临着海量数据处理的压力,亟需根据自身的管理需求和市场竞争需要,构建适合于自身管理特点的电信数据分析系统。本文研究的目的是如何利用分布式计算技术实现电信数据分析系统的业务处理加速,进而提高系统性能,加强决策水平。
2 电信数据分析系统的现状
随着电信业务的快速发展以及市场竞争的挑战,数据分析平台作为各级领导制定策略的重要参考以及市场部门进行推广计划的重要依据,数据分析相关业务的重要性和应用价值不断提升。
随着数据分析业务数据量的快速增加,分析维度的扩展,某些业务已经出现明显的性能瓶颈,妨碍数据业务分析在电信业务发展和市场竞争中发挥更大的作用。数据分析业务的性能瓶颈主要表现在以下3个方面。
·海量数据挑战:数据分析业务从话音的CDR(call detail record,呼叫详细记录)发展为数据业务的DPI(deep packet inspection,深度报文检测)的 UDR(user data record,用户数据记录);记录规模从千万条增长100倍发展到数十亿条;存储规模正由GB级别向TB级别发展。
·传统方案失效:面对海量数据,传统的小型机+磁阵方案无法胜任;Oracle可处理数千万条,无法处理数十亿条记录;传统SQL查询响应慢,某些业务运行时间超过数小时。
·并行分析瓶颈:分析维度需要同时支持多种业务的并行分析;业务平台还需要同时支撑多部门、多地域的并发查询;业务请求集中在月初,由于时间冲突,导致效率下降。
3 基于分布式计算框架的数据分析方案研究
3.1 分布式计算概述
分布式计算是近年提出的一种新的计算方式,它研究如何把一个需要巨大计算能力才能解决的问题分成许多小的部分,然后分配给许多计算机进行处理,最后把计算结果综合起来得到最终结果。分布式计算是云计算领域的重要研究方向,共享稀有资源和平衡负载是其核心思想之一。分布式计算能更好地使用计算资源,更智能地进行大规模数据处理。基于高效的虚拟计算资源,应用程序能以一种灵活且安全的方式实现快速扩展和缩减,从而交付高品质服务。分布式计算使得IT管理更加轻松,保证快捷响应业务需求。业务或客户服务以极为简化的方式交付,这将大大推进创新和高效决策。业界一致认为,分布式计算平台是提高海量数据分析性能的最佳解决方案。
电信企业信息化建设不断发展,需要处理分析的数据量不断快速增长,利用分布式计算架构实现业务加速是一个可行的技术方案,并且,该方案可以广泛地应用在联机分析和数据挖掘等需要进行大规模数据处理的领域。其中,Hadoop是采用开源模式的分布式计算技术框架,以HDFS(Hadoop distributed file system)文件分散存储和MapReduce并行计算为基础的分布式计算平台,底层采用Linux操作系统,利用低成本的PC设备组成大型集群,构建下一代具备高性能的海量数据分布式计算服务平台。
3.2 基于Hadoop框架的分布式计算技术实现方案
Hadoop分布式计算已经集成了数十个高性能的应用组件,可以满足各种数据分析处理的需求。基于Hadoop框架的分布式计算平台逻辑架构如图1所示。Hadoop分布式计算平台主要包括以下应用组件。
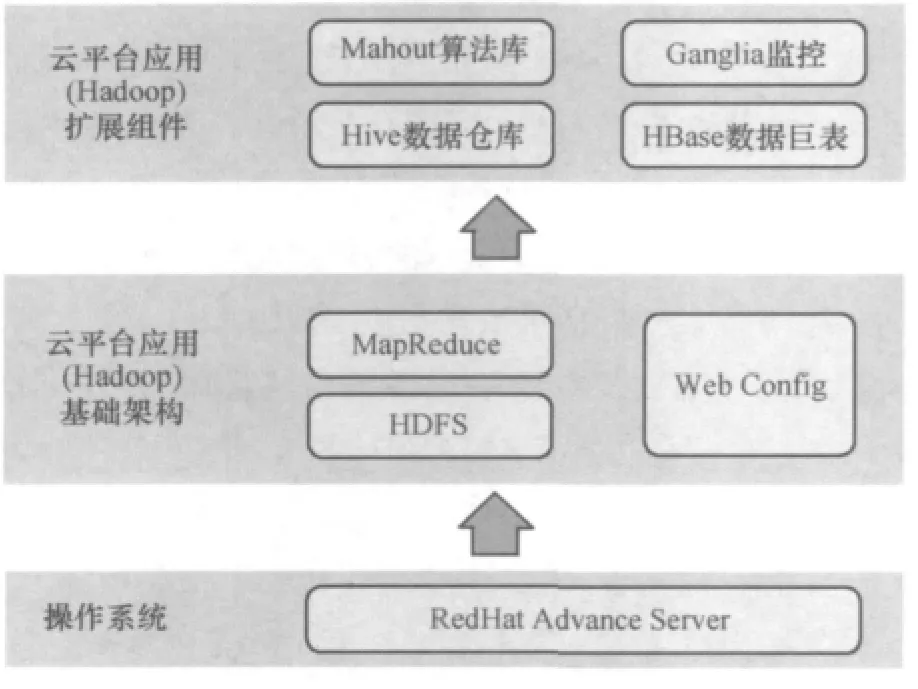
图1 基于Hadoop框架的分布式计算平台逻辑架构
·Hive分布式数据仓库:建立在Hadoop上的数据仓库框架,提供方便的数据集成、特殊查询以及建立在Hadoop文件上的大规模数据分析;支持MapReduce并行SQL查询的分布式关系型数据仓库,可以用于存储海量结构化数据,并支持数据分区以及建立索引等数据库功能,对外提供JDBC/ODBC接口,可以快速替代传统的Oracle数据库。
·HBase列存储数据库:基于列存储的分布式数据库,采用国际最流行的NoSQL数据库架构,支持列的动态增加和删除,最大可以支持到数万列,特别适合于用户行为分析的应用。
·Mahout智能算法库:提供各种k均值、神经网络等智能算法,满足数据挖掘的各种算法需求,采用MapReduce并行计算,运行效率极高,完全可以替代各种商业BI工具,从而节省大量成本。
·Ganglia实时监控:可以实时监控Hadoop平台各个节点的资源分配、作业运行、任务调度等,直接展示云平台运行情况。
3.3 分布式计算框架实现业务加速的应用分析
基于分布式计算架构的电信数据分析系统可以很好地实现业务加速能力,该平台具有以下技术优势。
·并行导入 ETL(extract transform and load,提取转换加载)加速:基于Hadoop的分布式计算采用HDFS分散存储机制,可以多个节点同时导入多个数据文件,实现数据文件的并行导入功能,避免了磁盘I/O瓶颈,可以有效缩短导入时间加速ETL过程。
·MR并发查询加速:数据表Table在Hive中以多个数据块存储,采用MapReduce并行机制,将查询作业映射为多个子任务,子任务处理少量数据块,然后输出统一结果,发挥了多核协同的性能优势。
·横纵分散取数加速:Hadoop支持数据分区模式的横向分散和按照列存储的纵向分散,满足不同的业务需求,其中分区横向模式符合电信管理模式,可以用于业务宽表的取数加速。
4 应用分布式计算实现海量取数加速案例研究
为了提高现有平台的业务处理能力,一种方案是系统扩容,目前电信使用的数据分析系统大多采用商业版本的软件平台,例如Teradata平台的系统扩容价格非常昂贵,而且需要绑定硬件的存储容量。另一种方案就是采用外部加速方式,即通过Hadoop云平台可以有效提高业务处理速度。本章将着重介绍采用外部加速实现海量取数加速的应用案例,案例对象是中国电信股份有限公司某省公司的大批量智能取数平台(intelligent data acquire platform,IDAP),研究目的是通过基于Hadoop框架改造实现业务加速。
4.1 传统大批量智能取数平台面临的挑战及应对
传统大批量智能取数平台的数据集市(采用Oracle数据库)中存储的数据量日渐庞大,由于数据量大并且并发业务多,当多用户在线操作或者取数量多时会存在着明显的业务瓶颈。该平台目前常用的功能包括资产取数、订单类取数、收入类取数以及业务量取数,日常操作中,在取1~3个月数据时有性能瓶颈,具体表现在以下几个方面。
·如果数据量太大或数据库对应并发量大,可能会导致取数失败。
·大数据量的提取,就意味着需要大的存储空间来存储数据。因此,存储空间随着业务的发展而需要扩充,且存储空间的增长不会影响性能。
·外部系统大数据量提取,数据库处理性能低下。
目前的业务瓶颈主要是系统的性能不能满足业务日益发展的需要,面对大数据量数据分析业务,通过传统的系统扩容来解决问题的方式已经行不通了。而基于对分布式计算的研究与理论论证,笔者认为可以在较低的硬件成本投入下产生较好的业务加速。针对现有系统的性能瓶颈,笔者着手对其进行基于Hadoop框架的分布式改造工作,图2方框内为改造后的技术架构,即将海量数据存储于Hadoop平台的HDFS分散存储模型上,然后通过UDF方式将此数据导入数据仓库Hive中。

图2 基于分布式计算的IDAP应用改造方案
具体来说,就是在多台PC服务器上部署Hadoop框架,包括了HDFS以及Hive分布式数据仓库,然后通过接口将数据集市中的数据导入Hadoop集群。应用Hadoop分布式计算框架提供的分布式文件系统以及Hive分布式数据仓库服务,替代原有的基于传统关系型数据库的IDAP数据集市,原有系统业务逻辑基本不变,仍然采用JDBC接口方式提交SQL业务查询请求。在进行数据表查询时,将一个SQL的查询操作通过UDF自定义的方式调用Hadoop的MapReduce并行架构,从而将SQL查询转换为成百上千个子查询任务,因此可以有效地提高查询速度,完成业务加速的目标。
4.2 测试数据分析
本次分布式集群硬件采用6台DELL R710服务器,具体配置为 2 个 Intel E5620 CPU、8×4 GB 内存、8×146 GB SAS硬盘以及4个吉比特网卡。笔者对基于分布式计算框架的IDAP大批量智能取数进行了专门的测试验证。测试的基准完全基于现有系统的数据集市的真实数据,即总容量2.7 TB总计84亿条记录数。选取传统平台上17个SQL取数语句作为测试用例,测试数据如表1所示。
在实际测试验证过程中,笔者分别记录传统和分布式IDAP上收入类取数、订单类取数、资产类取数、业务量取数等各主题的取数时间,然后进行比较。通过对所有测试用例取数时间的分析,最后得出以下主要结论。
·传统取数时间在3min以内的测试用例,分布式改造之后,有的测试用例取数时间比传统取数时间长,有的测试用例取数时间比传统取数时间短,提升效率不明显。
·传统取数时间在3~60min的测试用例,分布式改造之后,所有的测试用例取数时间都比传统取数时间缩短了,并且提升效率在5倍以上。
·传统取数时间在60min以上的测试用例,分布式改造之后,所有的测试用例取数时间都比传统取数时间缩短了,提升效率在10倍以上。
4.3 基于分布式架构IDAP方案与传统IDAP方案对比
通过基于分布式计算框架对传统IDAP进行业务加速改造,可以达到以下3个效果。
·改造成本低:Hadoop分布式计算平台采用开源免费的模式,硬件采用低成本PC设备,只需支付平台的软件服务费即可,节省了大量系统升级成本。

表1 取数时间对比

表2 基于分布式架构的IDAP方案与传统方案对比
·系统改造少:传统IDAP属于生产系统,其云加速平台采用标准的数据访问接口,对传统IDAP改造工作量少,基本无需改动,实现了业务无缝升级加速。
·提速效果明显:经过实际业务数据的测试,采用Hadoop分布式平台可以实现10倍以上的平均加速效果,完全满足了业务加速的需求。
传统的IDAP方案中大批量智能取数平台部署在一台P570上,后台通过光纤连接SAN存储,大约占用两个机柜,能耗超过10 000 W。表2为传统IDAP方案与基于分布式计算框架的IDAP方案的详细数据对比。
通过表2数据对比,可以得出以下结论。
·传统方案基于关系型Oracle数据库,无论从支持的节点数还是数据库容量都是有限的,而分布式方案可以支持PB级别海量数据,节点规模最大可以达到数千个。
·传统方案通过小型机+存储阵列方式构建平台,初始投入的费用相当可观,并且日后的维保开支也会很大,而分布式方案通过PC服务器或者工控机就可以组成高性能计算集群,费用可以节省70%以上。
·传统方案的扩展成本除了实施成本之外,还需要额外的数据库软件许可费用,而分布式方案只需要支付实施成本就可以了,显然分布式方案在成本方面更节省。
·在硬件成本一致的前提下,采用工控机的分布式方案要比采用PC服务器的分布式方案性价比更高,即能够实现更好的加速效果。
·分布式方案在空间利用率以及能耗方面都要优于传统方案,也就是说分布式方案为机房的绿色节能提供了可能性。
5 结束语
随着电信业务的不断发展,海量数据存储与分析的需求不断涌现,利用Hadoop分布式计算框架可以实现海量数据的超值存储和分析统计,提高数据分析的效率,让企业更加能适应快速变化的市场,为快速推出新的产品提供数据依据。
1 闻剑峰,石屹嵘.基于云计算的全球眼业务平台研究.电信科学,2010,26(6)
2 龚德志,闻剑峰.虚拟化技术在电信服务器资源整合中的应用研究.电信科学,2009,25(9):21~23
3 石屹嵘,段勇.云计算在电信IT领域的应用探讨.电信科学,2009,25(9):24~28
