基于Handel-C的软硬件协同验证方法
2012-06-03刘舜奎蔡艺军
刘舜奎,蔡艺军
(厦门大学 电子工程系,福建 厦门361005)
在数字集成电路的设计中,需要通过仿真来检验设计是否可实现预期的功能。仿真需要为设计项目建立一个测试平台,为设计项目提供尽可能完备的测试激励和可供观测的输出响应,根据输出响应信息可判断设计项目是否可实现预期的功能。随着系统设计复杂性的不断增加,当设计集成度超过百万门后,设计正确性的验证就比设计本身还要困难,系统仿真的实时性很难满足要求。在对复杂电路进行软件仿真时,系统的仿真时间往往占据了设计的大部分,系统某些电路功能的仿真验证常常需要几个小时甚至几天。因此,如何提高仿真效率、减少仿真复杂度、缩短仿真时间,成为系统设计中的关键问题。
为了方便而快速地实现仿真验证,及时得到测试结果,本文提出运用硬件加速的思想,并以OpenGL-ES算法中的坐标变换算法为例,将其作为待验证的IP放在整个OpenGL-ES软件平台上进行测试。利用Handel-C语言对该IP进行FPGA实现,并采用Bus Master DMA的通信方式在软、硬件之间进行通信,实现软硬件协同加速仿真。选用以OpenGL-ES为例是因为该算法为开源的;采用C++实现,存在大量矩阵运算,将其用 FPGA实现,可充分利用硬件并行的特性。同时,也因为Handel-C与C语言的高度相似性,开发周期得到了明显的缩短。
1 OpenGL ES及相关算法分析
OpenGL ES 1.1的绘图主要分两个阶段:几何处理阶段和光栅化处理阶段[1-2],如图1所示。

图1 OpenGL ES 1.1绘图流水线
本文关注的是几何处理阶段中的坐标转换模块。通过线性代数的方法将物件的三维空间模型进行移动、缩放和变形等,借助由控制物体上每个点的坐标变动,可以实现对物体的移动、缩放和旋转。对应的三种顶点坐标变换算法为平移变换、缩放变换和旋转变换,均通过顶点坐标构成的矩阵相乘来实现,其中旋转变换算法的运算量最大。现以绕任意轴的旋转变换算法为例,简单介绍其实现步骤。
设旋转轴 AB由任意一点A(xa,ya,za)及其方向向量(a,b,c)定义,空间一点Q(xq,yq,zq)绕 AB 轴旋转 θ角到Q′(xq′,yq′,zq′),则可以通过下列步骤来实现Q点的旋转:
(1)将A点移到坐标原点。
(2)使AB分别绕X轴、Y轴旋转适当角度与Z轴重合。
(3)将 AB绕Z轴旋转 φ。
(4)作上述变换的逆变换,使AB回到原来位置。即:

其 中 ,RAB(θ)=T-1(xa,ya,za)Rx-1(α)Ry-1(β)Rz(θ)Rx(α)T(xa,ya,za),矩阵T为平移矩阵,R为绕某坐标轴的旋转矩阵,而α、β分别为AB在YOZ平面与XOY平面的投影与Z轴的夹角。
该系统采用的演示程序中,旋转轴为单位轴(nx,ny,nz),则旋转矩阵 RAB(θ)为如下形式:
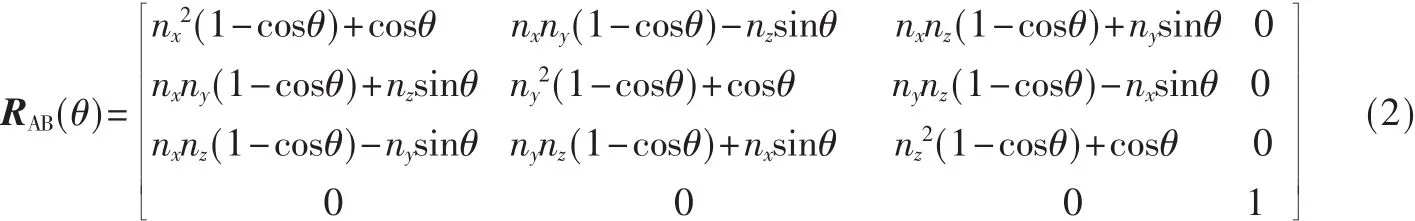
2 HANDEL-C及开发流程
本设计采用Handel-C、硬件描述语言和C++协同开发的方式,其一般开发流程如图2所示。

Handel-C的代码默认从顶部开始串行执行到底部,每一条语句占用一个时钟周期[3]。但Handel-C同样支持并行处理机制,这是通过使用关键字“par”来实现的。坐标变换算法中涉及到大量的矩阵乘法运算,而矩阵乘法运算中乘积矩阵的所有元素互相独立、互不相关,可以将其并行实现。因此该设计充分利用了Handel-C的并行机制,使矩阵乘法的效率大大提高。
Handel-C支持和C语言一样的数组形式。Handel-C中的数组可以让所有变量在一个时钟周期内被并行地访问,从而提高变量的存储和读取效率。例如用来求定点数平方根倒数的函数EGL_InvSqrt()中用到了查表法,表的大小只有8×16 bit,而该函数在旋转算法中被大量用到。因此为了提高效率,采用数组的形式定义该表。
但索引一个大数组将耗用大量的硬件资源,这时可以换成用RAM或ROM来实现。Handel-C提供了“ram”或“rom”关键字来解决该问题[4]。例如在旋转变换算法中,涉及到三角函数运算sine和cosine,同样采用查表法来实现,而表的大小为1 024×16 bit,这时必须用ROM来实现,使用“rom”关键字定义该表即可。
由以上特点可以看出,该设计采用Handel-C可以从开发流程的各个环节降低开发难度,从而缩短开发周期。
3 系统设计与实现
3.1 Bus Master DMA
为了满足整个系统的实时数据处理要求,该设计选用PCI Express接口在FPGA与PC之间实现数据传输。当采用8通道的PCI Express数据传输时,可实现4 GB/s的传输速率,满足该系统对数据处理的实时性要求。
本设计采用BMD(Bus Master DMA)的实现方式,BMD的DMA引擎被内嵌在PCI Express架构的endpoint端,负责在系统内存与endpoint之间移动数据。endpoint即为该系统的硬件部分,即内嵌了DMA引擎的坐标变换模块。
3.2 系统硬件设计
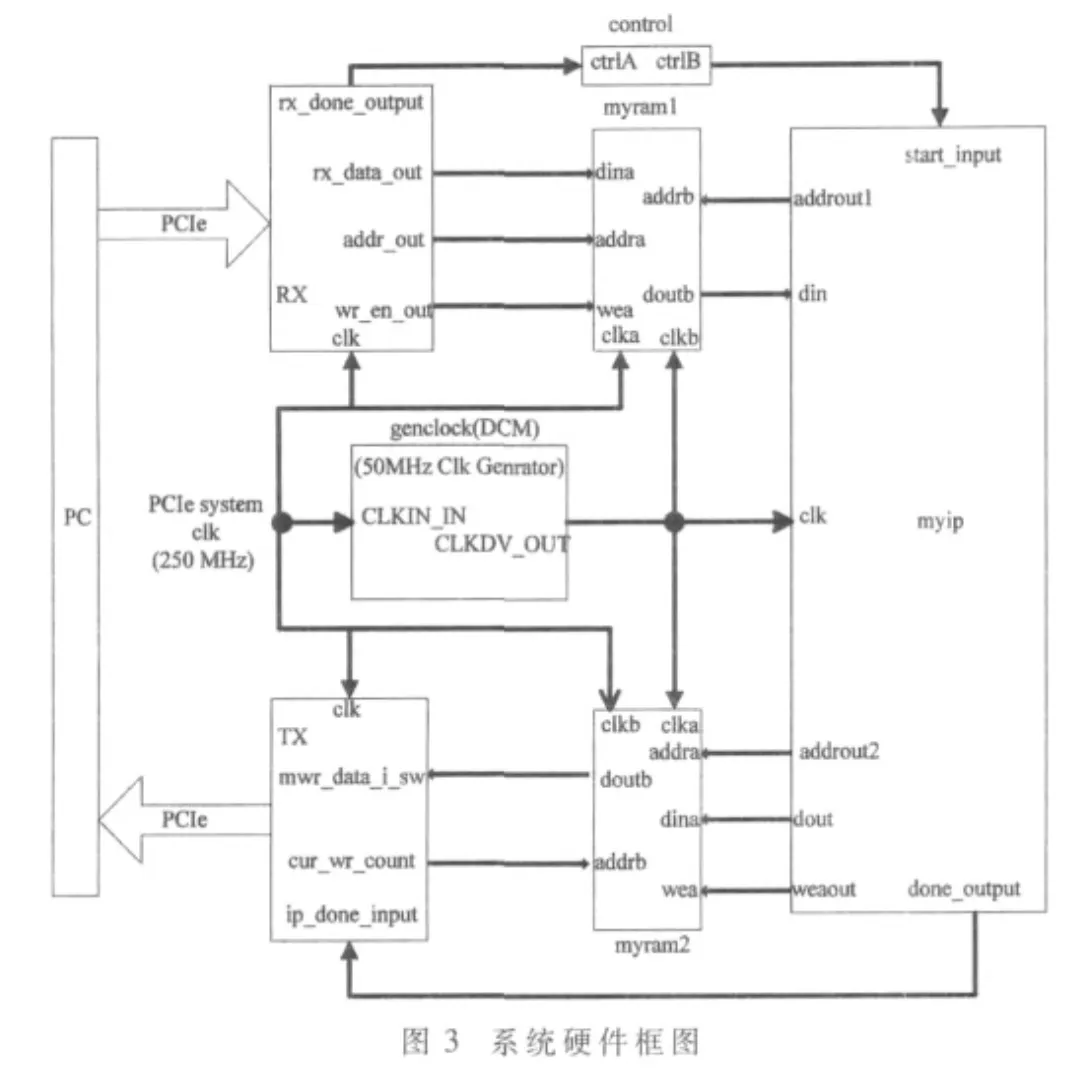
采用Handel-C与Verilog混合设计的方法对该系统的硬件平台进行设计,其中较多涉及到调度及状态转换的模块用Handel-C设计,涉及到较为严格的时序要求的模块用Verilog设计。该系统的硬件整体框图(省略BMD控制部分)如图3所示。
其中PC部分为系统软件部分,包括OpenGL-ES中除坐标变换算法以外的其他部分,以及DMA传输控制的软件部分;RX和TX模块分别为DMA的接收和发送引擎,即BMD架构中Initiator Logic模块里的 Rx和Tx。可见,DMA已经内嵌在系统硬件设计中;myram1和myram2为双口RAM,具有独立的数据读写和时钟端口,作为输入和输出缓存,同时隔离了用户IP和PCIe两部分的时钟,为实现双时钟工作提供了条件;genclock为DCM模块,对PCIe的输入时钟进行5分频,得到50 MHz的时钟供用户 ip使用,除了 myram1的 clkb、myram2的clka以及myip的clk为50 MHz外,其他时钟均为250 MHz;control模块为控制信号的跨时钟域转换模块,因为控制信号rx_done_output从频率高的时钟域输出到频率低的时钟域,必须对其进行转换,才能使其在频率低的时钟域内被有效识别。
myip部分内含myTransform IP核,这部分为用户自定义的IP,其内部结构如图4所示。

其中,myTransform模块为由Handel-C转换而来的坐标变换模块,它有 4个数据输入口(angle,x,y,z)和 10个数据输出口(my_m_elements_1~my_m_elements_a)。而myip为1个数据输入口和1个数据输出口,即串行输入和串行输出。为了将myTransform模块封装成myip的串行输入、输出形式,在输入、输出端分别有一个4 bit串/并转换模块4-bit Serial2Par和10 bit并/串转换模块10-bit Par2Serial;而Control_Logic为myip模块的逻辑控制模块,主要实现以下功能:
(1)对各模块的开始(start)与完成(done)信号进行处理,并根据这两个信号对各模块的工作进行调度。包括整个myip模块、myTransform模块、串/并模块和并/串模块。
(2)对外部两个双口ram的读写进行控制,包括地址和写使能信号的控制。
这里的用户IP即myTransform模块,根据用户IP的数据输入、输出形式,只要改变串/并转换的位数和并/串转换的位数,即可实现用户IP模块与myip模块的整合,而无需改变myip模块的接口以及控制信号,为该系统的通用性提供了保证。
3.3 系统软件设计
软件包括两部分:DMA通信部分和OpenGL-ES中除了坐标变换算法以外的其他部分。
DMA通信部分又分为驱动层和应用层接口。驱动层的设计涉及到Windows下PCIe驱动程序的编写,不是本文的讨论重点;应用层接口是在驱动层的基础上生成API,用以在应用程序中进行相关的 DMA操作(主要包括DMA器件的打开和关闭、读写DMA的设置、DMA启动以及DMA各寄存器的读写操作等)。
将原始的OpenGL-ES中坐标变换模块用DMA操作代替:首先打开 DMA器件、复位 DMA器件、设置DMA传输中各寄存器的值,再将输入参数放到相应内存(TLPReadBuffer)中,然后启动DMA操作,将该内存的值通过PCIe传到开发板上进行处理,处理完后的数据再通过DMA写操作写进PC相应的内存(TLPWriteBuffer)中。通过不断读取写操作完成寄存器的值,来判断写操作是否完成。如果写操作未完成,则继续读取该寄存器值来判断,若读取次数超出设定值,则重新启动DMA。当写操作完成时,从相应内存(TLPWriteBuffer)中读取处理完的数据,即为坐标变换模块的返回值。软件工作流程如图5所示。

图5 软件工作流程
启动DMA操作实际上包括启动DMA读和写的操作。DMA硬件会先启动读操作,将内存中的值读入开发板,然后经过用户IP进行处理完后,写回内存。因此只需要确定DMA写操作完成即可,此时整个DMA读写操作也一定完成。
4 性能分析与验证
经过软件仿真验证各模块功能完全正确之后,将该设计进行软、硬件联合验证。
本设计采用的硬件验证平台为Avnet公司的AES-XLX-V5SXT-PCIE50-G开发板,该开发板的FPGA芯片型号为Xilinx公司Virtex5系列的xc5vsx50t[5]。
针对一些运行时间较长的单元,在Handel-C中加入par并行处理进行优化,在ISE11.1中用XST进行综合。表1体现了加入par之前和之后所耗资源的对比。
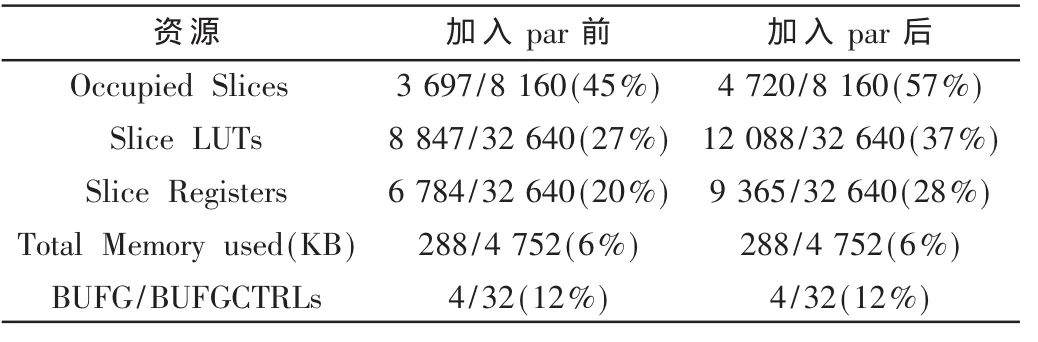
表1 资源使用情况
由表1可以看出,加入并行处理后资源消耗有所增加,但处于合理范围内。
用ISE11.1对综合后的网表进行实现,生成.bit文件并下载到开发板中,联合软件部分进行协同验证。为了将其与传统Modelsim仿真速度作对比,这里将模块处理复杂度扩大10 000倍,即可明显看出该验证方法的速度优势。表2给出了在PC主频2.66 GHz下,从Rst信号到Done信号之间仿真消耗的时间对比。由表中可看出,本文采用的验证方法在仿真速度上是传统ModelSim仿真的778倍,即使对经过Modelsim优化后的节点进行仿真,也快了202倍。

表2 仿真速度比较
本文用Handel-C设计和实现了OpenGL-ES的坐标变换算法,并将其与软件平台进行软、硬件协同验证。结果表明,Handel-C能够用来实现复杂的算法,并且比传统的HDL设计方法更为高效;通过该方法建立的软、硬件仿真平台对IP进行验证,具有更高的效率。
[1]孙家广.计算机图形学(第三版)[M].北京:清华大学出版社,1999.
[2]Munshi.OpenGL ES common/common-lite profile specification[S].2004.
[3]Celoxica.Handel-C language reference manual[Z].2005.
[4]Celoxica.Handel-C code optimization[Z].2003.
[5]Xilinx.Virtex-5 FPGA user guide[Z].2009.
