基于TMS320C6678的语种识别并行算法设计与实现*
2012-06-03吉立新刘伟伟李邵梅
吉立新,刘伟伟,李邵梅
(国家数字交换系统工程技术研究中心,河南 郑州450002)
语种识别是计算机通过分析处理一个语音片段,判别其所属语言种类的过程[1]。语种识别的任务在于快速准确地识别出语言的种类,自上世纪90年代以来,已经成为通信和信息领域一个新的学科增长点,在多语种信息服务、机器翻译及军事安全等领域都有着广泛的应用前景[2]。语种识别走向实用化,不仅要有令人满意的识别性能,其实时处理的效率也是必须要考虑的因素。因此,设计能够实现多路实时处理的语种识别系统是语种识别迈出实用化的关键一步。
本文针对语种识别系统算法的特点,设计了一种基于TI多核处理器TMS320C6678的语种识别并行实现方法,实现了任务级的并行流水处理和核间的高效通信。
1 平台介绍
TMS320C6678是基于TI公司最新DSP系列器件TMS320C66x、采用8个1.25 GHz DSP内核构建而成的业界首款10 GHz DSP,可在10 W功耗下实现160 GFLOP(Giga-Floating Point Operations per Second)浮点计算性能[3]。不仅能整合多个 DSP以缩小板级空间并降低成本,同时还能减少整体的功耗要求,充分满足现代数字信号处理日益增长的需求。
本文语种识别系统的开发在TI公司的最新DSP集成开发环境CCSv5(Code Composer Studio)中基于浮点运算设计完成。
2 基于TMS320C6678的语种识别算法优化
2.1 语种识别算法分解
本文的语种识别系统是基于区分性Model Pushing算法[4]进行构建的,并且对特征参数进行了fDWNAP[5-6]处理,因此系统的测试阶段由特征提取模块、fDWNAP模块及对数似然得分模块3个模块构成,如图1所示。
(1)特征提取模块

图1 语种识别测试过程系统构成图
特征提取模块的任务包括语音信号预处理、MFCC提取、RASTA滤波、SDC扩展、VAD检测、CMS处理、高斯化等过程,该模块结束即输出56维的特征参数,其需要存储的参数包括汉明窗和梅尔滤波器组总共不到2 KB。
(2)fDWNAP模块
该模块的工作是对所提取的56维特征参数进行处理,以去除与语种无关的各种干扰信息,达到净化语种特征参数的目的。如参考文献[6]介绍,该模块首先将特征参数映射至SVM的高维空间,然后利用训练得到的投影矩阵计算映射后的参数中所包含的干扰信息,再将干扰信息映射至特征空间,从而进行去除。该模块中事先训练得到的投影矩阵 P=I-wwT,wwT是对称矩阵,因此存储wwT需要7 MB的存储空间。另外,K-L变换矩阵D是对角矩阵,需要112 KB的存储空间。
(3)对数似然得分模块
[4]所述,本模块主要任务是利用训练得到的各语种GMM模型对语音特征参数计算对数似然得分进行输出的判决。
本模块需要存储训练阶段得到的各目标语种的GMM模型及非目标语种的GMM模型,即针对每个语种需要存储2个GMM模型。所有的GMM模型只是均值矢量不同,高斯混元权重及协方差矩阵都是共享UBM模型的。以L个语种为例,需要存储2L个均值矢量,即需要224L KB的存储空间,共享的高斯混元权重需要2 KB的存储空间,协方差矩阵由于是对角化的只需要112 KB的存储空间。
2.2 算法实时性分析
首先对各模块的运算实时性进行分析。以30 s的语音(8 000 Hz采样,帧长 25 ms,帧移 10 ms)为例,后端模型使用单个语种模型,利用CCSv5的环境进行软件仿真得到各模块处理所花的时钟周期数,然后按照TMS320-C6678芯片的单个内核的工作主频(1.25 GHz)计算得到处理时间,结果如表1所示。

表1 语种识别测试过程各模块未经算法优化的耗时
由表1可知,整个语种识别系统测试阶段,在算法代码未经任何优化的情况下,一段30 s的语音在单个TMS320C66x CPU内核上的处理时间约为22.3 s,结果非常不理想,并且特征提取模块和对数似然得分模块耗时较多。
为此,本文从两个方面对代码进行了优化:一是算法本身的约减,二是算法基于TMS320C6678平台的优化。
2.3 算法优化
(1)算法约减
计算过程的优化主要对语种识别系统中对数似然得分模块的算法做约减。对数似然得分过程就是利用已经训练好的各语种GMM模型对输入的语音特征进行似然得分的计算,语种数越多,则该模块的耗时越多。利用Top n的方法,对每个模型选取得分最高的10个高斯用来计算对数似然得分。由于区分性Model Pushing模型是由SVM训练得到的支持向量重构而来,而支持向量由GMM-UBM模型自适应得到,因此,区分性Model Pushing模型与GMM-UBM模型的各高斯分量之间有着很强的对应关系。
上述介绍说明,区分性Model Pushing模型与GMMUBM模型有着很强的对应关系,可近似认为对同一个特征向量它们得分最大的高斯混元一致[7]。针对拥有512个高斯混元的GMM,似然得分的计算结果必定仅仅集中于很少的几个高斯混元,大部分的高斯混元得分都会非常小以致可以忽略。因此,考虑将得分小的高斯混元结果忽略不计,只计算得分大的高斯混元。鉴于fDWNAP模块包含特征向量对GMM-UBM计算后验概率的部分,可利用该部分的结果选取Top 10的高斯混元用于后端对数似然得分的计算。
(2)基于TMS320C6678平台的算法优化
基于平台的优化主要是通过选择CCSv5提供的编译优化参数来实现。通过不断的参数选择、搭配,获得最理想的参数优化方式,提高代码中循环运算的性能,使用软件流水调度技术提高代码的并行执行效率。
除此之外,特征提取阶段的FFT和fDWNAP的矩阵运算等算法采用DSPlib中优化的库函数进行替代,利用优化的库函数可以极大地提升代码的运行速度。
(3)算法优化前后识别性能对比
首先检验Top 10算法对系统识别性能的影响。在测试集中模型使用Top 10的区分性Model Pushing,前端特征参数保持不变,在VC++2010的环境下测试系统性能。实验所用语料库为实验室采集的电话信道通话语音,含汉语普通话、日语和英语3个语种,测试集包含汉语1 000段、日语450段及英语 750段,共 2 200段30 s的语音和3 000段 10 s的语音(各语种1 000段)。系统性能用等错误率EER(Equal Error Rate)[2]衡量,实验结果如表2所示。
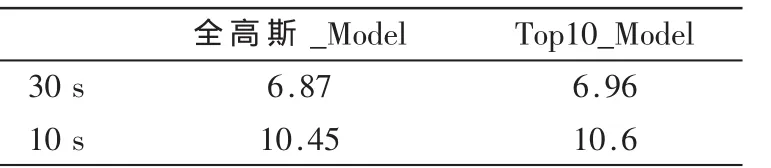
表2 Top 10得分模型与全高斯得分模型系统EER (%)
由表2可以看出,相对于全高斯得分模型,Top 10得分模型系统性能有所下降,主要因为舍弃了其他得分低的高斯成分,而其中必定包含部分语种区分信息,但舍弃掉的这一部分所含的语种信息有限,所以性能下降在可接受范围之内(相对下降小于5%)。该优化方法下模块的运算量下降是显而易见的,同样耗时也会大幅下降。
(4)算法优化前后系统实时性对比
对经算法优化的系统耗时做如下测试,同样以30 s的语音(8 000 Hz采样,帧长 25 ms,帧移 10 ms)为例,用CCSv5的环境进行软件仿真得到各模块处理所花的时钟周期数,然后按照TMS320C6678芯片的单个内核的工作主频(1.25 GHz)计算得到处理时间,结果如表3所示。
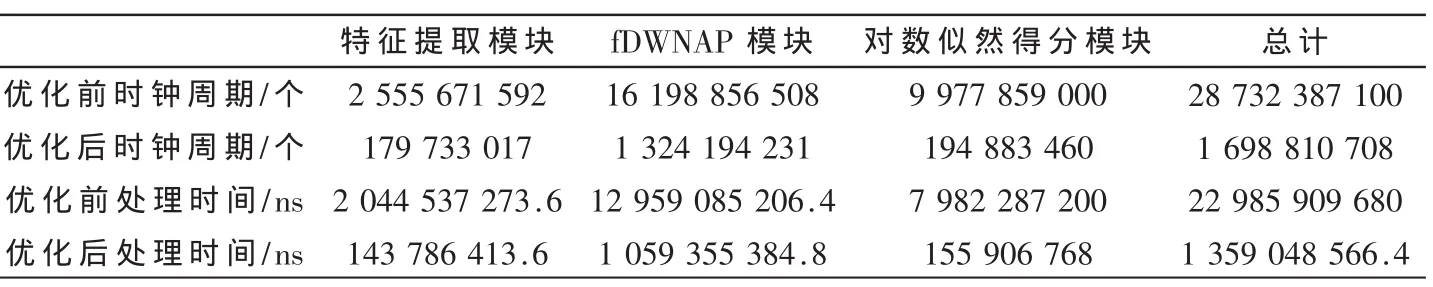
表3 语种识别测试过程算法优化前后各模块耗时对比
由以上分析可以看到,算法优化后的系统耗时由22.3 s减少至1.36 s,下降非常明显,其中下降最多的是fDWNAP模块和对数似然得分模块。在整个系统中,经过算法优化,fDWNAP模块耗时所占比例依旧最大,因此在多核任务并行设计时,需要将该模块的任务进行分解。
3 基于TMS320C6678的语种识别算法并行设计
3.1 模块间通信分析
根据语种识别的系统结构,测试过程分为3个模块,各模块的算法都已经进行了相应的优化。这些模块相互配合,通过控制信号完成数据流的交互。任务的控制流程主要是模块的执行次序,任务分配在不同核上的模块之间以传递消息的方式实现同步。模块间数据的传递会造成相应的时间延迟,因此,控制流程的设计准则为最大化系统的处理能力。模块间的数据流程主要是数据的传输方向,描述模块与外部数据间的相互关系。相反,最小化模块间的数据通信量则是数据流程的设计准则。
语种识别系统算法各模块间控制流程和数据流程的通信示意图如图2所示。该图由数据层和控制层两部分构成,控制信号的传输由虚线箭头表示,数据的传输由实线箭头表示。
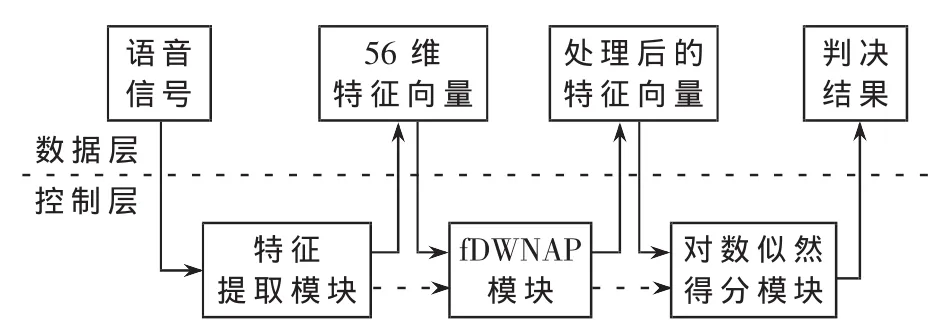
图2 语种识别系统算法各模块间通信示意图
3.2 模块任务的核映射
为了充分利用所有内核CPU的计算资源以最大限度地提高系统处理速度,根据算法优化前后的系统实时性测试结果及各模块运算量分析,将fDWNAP模块的矩阵乘法任务分配到多个核并行执行。
因本文的语种识别系统适合于数据流模式的任务并行方式,将整个系统的运算任务适当地分配给各个内核,实现任务级的并行流水。由于fDWNAP模块计算复杂度大,制约了整个系统任务级流水的处理速度。为了充分发挥TMS320C6678的性能优势,将该模块任务映射到多个核进行处理。该模块首先需要计算特征矢量对应的自适应GSV;然后通过投影矩阵计算SVM特征域的干扰空间,这一部分的大矩阵乘法占据了整个模块的绝大部分运算量;最后还需要将干扰空间返回映射到特征域,并在特征域去除干扰。整个模块80%以上的运算量都集中在大矩阵的乘法上,故采用将大矩阵拆为小矩阵分配到多个核上并行运算,将其他任务集中在一个核上进行处理。在该模块内还是一个任务级的流水处理方式,矩阵相乘部分是核级相同的并行流水处理方式。
4 基于TMS320C6678的语种识别算法实现
4.1 语种识别算法在TMS320C6678中的实现
根据设计思路,将本文提出的语种识别算法在CCSv5上进行软件仿真。其中,利用SYS/BIOS[8]提供核间任务调度,利用IPC[9]实现核间同步和通信。
启动系统,完成所有核的初始化后,首先调用IPC_start函数让各核进入同步等待状态,然后各核上的程序才能开始执行。从共享存储器划出MSM_IN和MSM_OUT 2块存储区,MSM_IN存储K-L变换矩阵和各语种GMM模型,MSM_OUT存储判决输出结果。投影矩阵数据存储在外接DDR3存储器中的位置信息事先存在Core1中。Core1将投影矩阵数据分成5份,通过Notify_sendEvent函数将5份数据的地址发送到Core2、Core3、Core4、Core5 和 Core6。Core2、Core3、Core4、Core5 和Core6上的子矩阵乘法任务一直处于悬挂状态,直到Core1发送过来数据地址,矩阵乘法任务才开始并行执行。各核分别根据数据地址从外接DDR3读取数据与Core1传递的数据计算干扰因子向量,计算完毕再利用MessageQ_put函数将干扰因子向量数据的Message写入到Core1建立的消息队列上。Core1利用MessageQ_get函数从消息队列读取Message,从Message中获取干扰因子向量数据;然后计算补偿后的特征向量;接着Core1利用MessageQ_put函数将补偿的特征向量数据的Message写入到Core7建立的消息队列上,Core7上的判决任务开始执行,最后将执行结果的数据写入MSM_OUT。
4.2 实验及结果分析
根据本文语种识别算法的TMS320C6678任务并行设计方案,本节将给出CCSv5平台下浮点算法的软件仿真结果,并进行分析验证。
按照3.2节的描述,将fDWNAP模块设计为并行处理,同样以30 s的语音为例,采用3个语种的模型测试整个系统在TMS320C6678上的实时性能。3个部分的运算处理时间结果如表4所示。

表4 各部分运算处理时间
由表4可以看出,三个模块中fDWNAP模块耗时(0.227 s)最多,因此估算该系统的实时倍率至少为132(30/0.227)。
为了验证基于TMS320C6678平台的语种识别系统性能,将采用Top 10优化后的算法与在VC++2010平台中的识别性能进行对比。实验语料保持不变,表5给出了基于两种不同平台的系统EER。
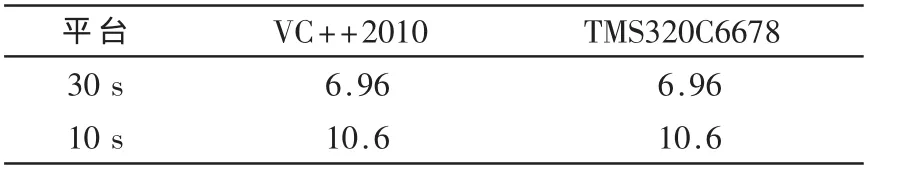
表5 基于VC++2010平台与TMS320C6678平台的语种识别系统EER(%)
实验结果表明,基于TMS320C6678平台的浮点软件仿真结果和VC++2010平台下的浮点计算结果完全一致,从而验证了TMS320C6678平台实现语种识别系统的正确性。
本文针对语种识别系统的实时性需求,在分析语种识别算法原理和多核DSP任务并行的基础上,分析了系统各模块的运算量,根据各模块的运算量对算法进行了优化。针对优化后算法的特点,设计了基于TMS320C6678平台的语种识别系统。最后从实时性和识别性能两个方面对系统性能进行了测试,结果验证了算法在TMS320C6678中实现的正确性及优化的有效性。
参考文献
[1]WONG K Y E.Automatic spoken language identification utilizing acoustic and phonetic speech information[D].Queensland:Queensland University of Technology,2004.
[2]徐婷婷.语种识别中的若干问题研究[D].北京:北京邮电大学,2011.
[3]Texas Instrument.TMS320C6678 multicore fixed and floatingpoint digital signal processor[R].SPRS691C,2012.
[4]刘伟伟,吉立新,李邵梅.基于区分性 Model Pushing的语种识别方法[J].电子技术应用,2012,38(4):113-116.
[5]刘伟伟,吉立新,李邵梅.基于区分加权干扰属性投影的语种识别方法[J].中文信息学报,[已录用未发表].
[6]Liu Weiwei,Ji Lixin,Li Shaomei.Robust cepstral feature compensation for language recognition[C].Guangzhou:Proc.of BEMI,2012:119-122.
[7]徐颖.语种识别声学建模方法研究[D].合肥:中国科学技术大学,2011.
[8]Texas Instrument.SYS/BIOS inter-processor communication(IPC)and I/O user’s guide[R].SPRUGO6C,2010.
[9]Texas Instrument.TI SYS/BIOS v6.33 real-time operating system user’s guide[R].SPRUEX3K,2011.
