ID3决策树算法分析与高等学校综合教学评价
2012-05-26胡萍
胡 萍
近年来,随着高校数据收集量的不断增加以及教育决策对量化分析结果的愈加依赖,数据挖掘技术在我国高校管理中的应用呈显著上升趋势。教学评价在高等学校教学管理中起着非常重要的作用,是指依据一定的教学目标与教学规范标准,通过对学校教与学等教育情况的系统检测与考核,评定其教学效果与教学目标的实现程度。由于教学评价具有复杂性、多因素性和模糊性等特点,如何客观、科学、全面地对教学质量进行评价,以提高教学评价研究的科学性、客观性和准确性,是现代教学评价研究中的一个非常重要的课题。本文应用数据挖掘技术,通过信息熵构造决策树的ID3算法来对课堂教学评价数据库中的数据进行数据挖掘,设法从中找出隐藏在数据中的规律性知识,为学校决策部门提供科学的依据和参考。
1.基于ID3算法的决策树基本理论
1.1 基本原理
近年来,数据挖掘引起了信息产业界的极大关注,其主要原因是存在大量数据,可以广泛使用,并且迫切需要将这些数据转换成有用的信息和知识。数据挖掘的任务是从数据集中发现模式,在实际应用中,往往根据模式的实际作用细分为以下几种:分类、聚类、回归、序列、时间序列等[1][2]。其中分类是重要的数据分析方法,应用非常广泛。解决分类问题的方法很多,决策树是对分类问题进行深入分析的一种方法,作为一种分类问题的解决方法正在被广泛地研究。
1.2 ID3算法
早期著名的决策树算法是1986年由Quinlan提出的ID3算法[3]。其基本思想是采用信息论中的互信息(或称信息增益)作为决策属性分类判别能的量,进行决策节点属性的选择。在ID3算法中,决策节点属性选择应用了信息论中熵(Entropy)的概念来完成,通过信息增最大(或最大熵压缩)的属性建立决策树,这样选择的节点属保证了决策树具有最小的分枝数量和最小的冗余度。
设S是n个数据样本的集合,将样本集划分为c个不同的类Ci(i=1,2,…,c},每个类Ci含有的样本数目为 ni,
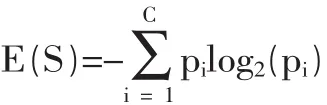
其中,pi为S中的样本属于i类Ci的概率,即pi=ni/n
假设属性A的所有不同值的集合为Values(A),Sv是S 中属性 A 的值为 v 的样本子集,即 Sv={s∈S襔A(s)=v},在选择属性A后的每一个分支点上,对该节点的样本集Sv分类的熵为E(Sv)。选择A导致的期望熵定义为每个子集Sv的熵的加权和,权值为属于Sv的样本占原始样本S的比例Sv/S ,即期望熵为:则S划分为c个类的信息熵或期望信息为:
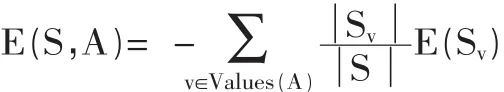
其中,E(Sv)是将Sv中的样本划分到c个类的信息熵。属性A相对样本集合S的信息增益Gain(S,A)定义为:
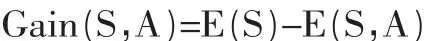
信息增益率为 Ratio(A)=Gain(A)/E(A)。
Gain(S,A)是指因知道属性A的值后导致的熵的期望信息压缩。Gain(S,A)越大,说明选择测试属性A对分类提供的信息越多[4]。Quinlan的ID3算法就是在每个节点选择信息增益Gain(S,A)最大属性作为测试属性。该算法需要计算每个决策属性的信息增益率,具有最大信息增益率的属性被作为给定数据集S的决策属性节点,并通过属性的每一个取值建立由节点引出的分枝。
1.3 决策树的规则提取
对于生成好的决策树,可以直接从中获取规则[5]。其规则的提取方法为:1)从根结点到叶结点的每一路径都可以是一条规则;2)以每一路径中各测试属性的合取作为规则的前提,而以其叶结点作为规则的结论;3)对提取的每一条规则,用IF-THEN形式表示成知识。
2.应用实例分析
通过调查分析,目前很多高校将教师个人评价结果直接反馈给教师或进行简单的排名,并没有对大量的评价数据进行深入的分析。这些评价数据背后隐藏着什么样的规律?能否利用这些评价数据为教师和管理人员提供决策支持?能否利用这些数据对教师进行发展性评价?下面围绕这些问题,利用ID3算法建树对合肥学院教学评价数据进行了深入的分析,得出了一些可供参考的结果;在此基础上构建了一个教学评价分析模型,以期为完善现有评价系统的功能提供参考。
2.1 数据准备
这里,以笔者所在的合肥学院的日常教学管理为例。学校为了提高教学水平和教学质量,每学期都要对全校开设的课程进行学生网上评教。除此之外还要通过系(部)级教学考评组和校(系)级督导组随堂听课等方式综合评价课堂的教学情况。全校各门课程按多项指标进行评价的结果汇总到学校的教学管理数据库后,为了防止教学评估的片面性,可对学生、系(部)和校(系)督导三者的评价数据按一定的权重进行综合处理,去除部分不完备和统计无效的元组,然后再应用粗糙集理论对其指标属性按等价关系进行维数约简或直接由专家组讨论确定,以此形成的数据集即为经数据准备后产生的待挖掘数据集。
对于待挖掘的数据集,假设教学评价指标体系经研究后,归纳为:教学态度(A2)、教学内容(A3)、教学方法(A4)、教学效果(A5)和综合评价等级(A6)共五项。但为了克服ID3算法存在不能够处理连续属性和计算信息增益时偏向于选择取值较多的属性等不足,这里对A2、A3、A4、A5给出的四个连续属性按如下区段进行划分,C1:90-100,C2:80-89,C3:70-79,C4:60-69,C5:小于 60,以此找出决策属性与综合评价等级A6之间的知识。假如我们任意选取15门课程,其各指标属性的值经离散化后形成的格式如表1所示。
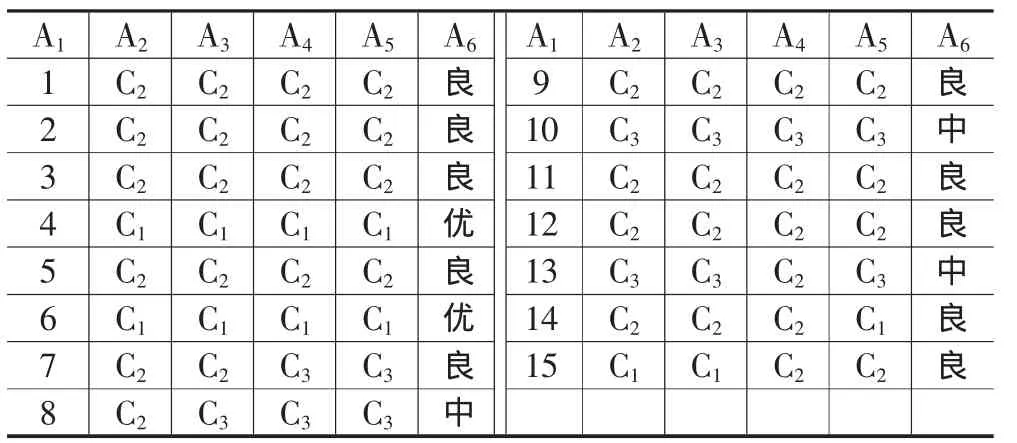
表1 教学评价经离散化后的数据集
2.2 数据挖掘
由ID3算法,先去掉属性A1。因为A1,对于综合评价属性而言,无互信息,即无信息增益,即gain(A1)=0。计算测试属性集的全部信息熵:
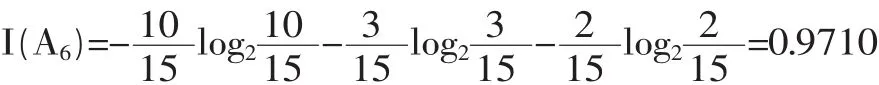
然后计算各结点的信息量I(Ei),如以A2为例:
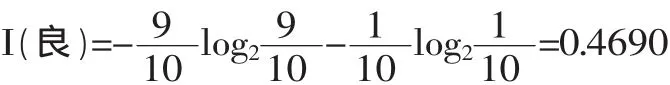
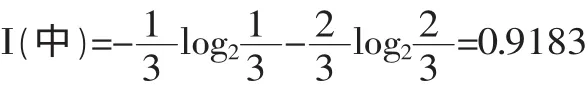
I(优)=0

同理,可计算出A3,A4,A5的信息熵增益分别为:
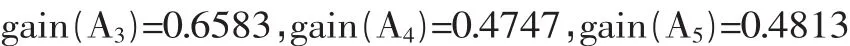
2.3 知识规则描述
故取A3为根属性,再用ID3方法对C1这一分枝继续进行划分。于是,可建立如图1所示的ID3决策树。从中可以看出,教学内容A3是一重要指标。表1中隐藏的知识有如下几种情况:
规则1:IF(A3=C2)THEN(良)
规则 2:IF(A3=C3)THEN(中)
规则 3:IF(A3=C1∧A5=C1)THEN(优)
规则4:IF(A3=C1∧A5=C2)THEN(良)
即如果教学内容为良,则课堂教学质量评价等级一定为良;如果教学内容为中,则课堂教学质量评价等级一定为中;如果教学内容和教学效果均为优,则课堂教学质量评价等级一定为优;如果教学内容为优而教学效果为良,则课堂教学质量评价等级为良。因此,从这些规则中,可以归纳出一条重要的知识,就是:教学内容组织好的老师,其课堂教学质量的综合评价成绩较好。
3.结束语
数据挖掘是一种新的数据分析技术,将决策树运用于教学评价之中,可以提高教学评价技术水平,提高教学评价的科学性、客观性和公证性,使之更好地为教学服务。
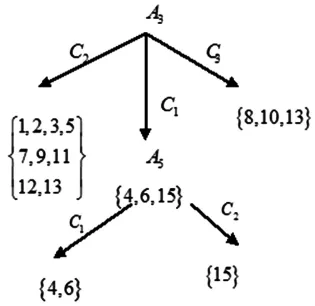
图1 课堂教学的ID3决策数
[1]陈 伟.改进的ID3算法构造决策树[J].淮南师范学院学报,2010,(3).
[2]罗运摸,崔小兵,谢志敏.等数据仓库应用与开发[Ml北京:人民邮电出版社,2001.
[3]武献宇,王建芬,谢金龙.决策树ID3算法研究及其优化[J].微型机与应用,2010,(21).
[4]邹筱梅,姜山,唐贤瑛.基于决策树的股市数据挖掘与仿真[J].计算机仿真,2004,21(3):52-55.
[5]李楠,杨彬彬.决策树ID3分类算法在文本分类中的应用研究[J].大连大学学报,2009,(6).
