基于大数据集的协同过滤算法的并行化研究
2012-05-04李章凤
李 改,潘 嵘,李章凤,李 磊
(1.顺德职业技术学院 电子与信息工程系,广东 顺德528300;2.中山大学 信息科学与技术学院,广东 广州510006;3.中山大学 软件研究所,广东 广州510275)
0 引 言
协同过滤算法是推荐系统中运用最广泛的的推荐算法[1-3]。协同过滤算法的核心是分析用户兴趣,在用户群中找到与指定用户相似(兴趣)的用户,综合这些相似用户对某一信息的评价,形成系统对该指定用户对此信息的喜好程度预测[4-5]。最近几年提出了各种高效的CF算法,其中包括潘嵘等提出了基于ALS的协同过滤推荐算法[6-8],N.Srebro等提出了 MMMF[9-10],R.Salakhutdinov等提出了PMF和 RBM[11-12],Daniel D.Lee等提出了 NNMF[13],以及聚类模型等等。
当前对这些协同过滤算法的研究都侧重于单节点的算法设计与实现。但随着互联网的迅猛发展,推荐系统中用户及推荐对象的数量在呈几何倍数增长,使得实现在单节点机器上的这些算法要算出结果需要耗费大量时间,无法满足大数据集的运算需要。因此如果我们能对这些算法实现分布式计算,将会大大缩短计算所需时间,同时必将对大规模协同过滤算法的应用研究有较大的推动作用。
本文的主要贡献是:研究基于矩阵分解的Alternating-Least-Squares(ALS)协同过滤算法的并行化问题,并详细介绍如何在开源的云计算平台Hadoop[14]上实现该算法的并行化。同时对ALS算法在多个节点下的并行化算法与其在单节点上的串行算法运行的时间进行对比,进而对实验进行评估。实验证明了ALS算法的可并行性,并行后ALS算法的运算性能获得了极大提高。
1 基于ALS协同过滤算法介绍
本节我们将首先简单介绍基于ALS的二维协同过滤推荐算法。
给定一个矩阵(R=(Rij)m×n)∈ {0,1}m×n,该矩阵表示具有m个用户、n个对象的评分矩阵。我们希望找到一个低秩矩阵X,来逼近矩阵R。同时最小化下面的Frobenius损失函数
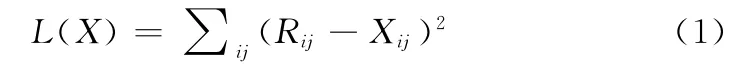
在上面的目标函数L(X)中,(Rij-Xij)2是低秩逼近中常见平方误差项。下面我们来考虑如何有效并且快速的求解最优化问题argminXL(X)。
考虑矩阵分解X=UVT,U∈Cm×d,d表示特征个数,一般d<<r,r表示矩阵R的秩,r≈min(m,n)。这时式(1)可以改写为
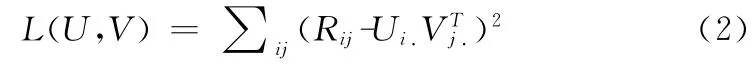
为了防止过拟合,我们给式(2)加上正则化项,则式(2)可改写为
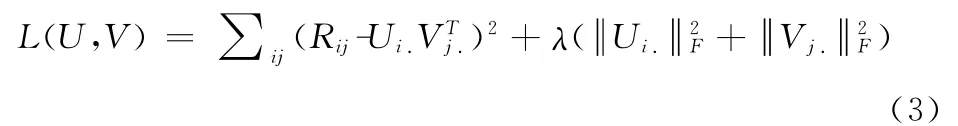
固定V,对Ui求导我们得到下面求解 Ui.的公式

式(4)中的Ri.表示用户i评过的电影的评分组成的向量,Vui表示用户i评过的电影的特征向量组成的特征矩阵。nui表示用户i评过的电影的数量。
同理,固定U,可以得到下面求解Vj.的公式
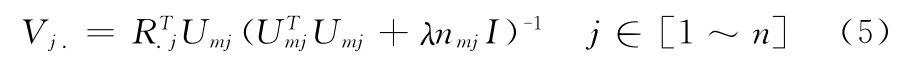
式(5)中的R.j表示评过电影j的用户的评分组成的向量,Umj表示评过电影j的用户的特征向量组成的特征矩阵。nmj表示评过电影j的用户的数量。
在式(4)、(5)中I表示一个d×d的单位矩阵。
基于式(4)、(5),我们提出下面的基于代正则化的交叉最小二乘法(ALS)的二维协同过滤推荐算法。①我们用0均值,偏差为0.01的高斯随机数初始化矩阵V,②我们用式(4)更新矩阵U,接着我们用式(5)更新矩阵V,直到本算法计算出的RMSE值收敛或迭代次数足够多而结束迭代为止。具体算法描述如下:
算法1 基于ALS的二维协同过滤推荐算法
输入:用户的评分矩阵R,特征个数d。
输出:矩阵R的逼近矩阵X。
(1)初始化V。
(2)反复迭代运用式(4)、(5)更新U、V,直到本算法计算出的RMSE值收敛或迭代次数足够多而结束迭代。
(3)X=UVT,返回矩阵X。
2 ALS算法在Hadoop上并行实现
本节主要介绍ALS算法在Hadoop上的并行实现。包括算法设计和算法的实现细节部分。
2.1 Hadoop平台简介
云计算的核心计算模式是Map/Reduce,该技术是云计算的运算基础。它的存储基础是 Hadoop Distributed File System(HDFS)项目,是云平台的大规模数据存储技术。下面我们就这两个技术分别加以介绍[14-15]。
Hadoop的计算核心是Map/Reduce模式[16]。区别于网格计算,Map/Reduce计算模式要求并行处理的数据块之间是相互独立的。Map/Reduce计算模式的数据输入是Key/Value对。Map过程由Key/Value进行数据的处理和整合,输出到Reduce过程,最终的输出依然是Key/Value数据对,Map和Reduce操作由程序员自己编写提交给系统处理。由Hadoop的作业调度机制将数据和Map和Reduce操作分发给不同的虚拟机进行处理,并把计算结果输出到分布式文件存储平台上。计算集群中的各个数据处理模块相互独立。Map过程处理完成之后,系统要对结果进行排序,排序后的结果又由Hadoop的作业调度机制分发给不同Reduce操作处理,最终将结果输出。MapReduce的处理流程图可参考文献 [14-15]。
HDFS是一个高度容错的文件系统,非常适合部署到廉价的机器群上。HDFS的设计侧重于数据的吞度量上,而不是处理速度。尤其是与Hadoop的计算模式相结合,使计算程序与数据存储尽可能的在同一个虚拟机上,保证数据的极大吞吐量。HDFS采用master/slave架构。HDFS集群由一个Namenode和若干个Datanode组成。Namenode设置于中心服务器,负责管理整个HDFS的名字空间和用户对HDFS的访问;Datanode是分布在不同虚拟机上的数据节点,负责用户对数据的读写等操作。HDFS同时提出了数据均衡的方案,系统会自动的将数据从一个容量不足数据节点上转移到其他空闲节点,保证整个文件系统的数据均衡。HDFS的结构示意图可参考文献 [15]。
2.2 并行算法设计
在算法1中,我们知道,ALS算法一次迭代需要分别计算U和V,而求U或求V这个过程是比较耗时的,而这个过程正是算法并行之所在。根据式(4)和(5),我们知道,在计算每一个用户的特征向量Ui时,与它相关的量只有电影特征矩阵V和该用户i评过分的电影的集合即Ri,Ri是一个向量;同理在计算每一部电影的特征向量Vj时,与它相关的量只有用户特征矩阵U和评价过电影j的用户的集合,即Rj,Rj是一个向量。用户与用户之间,电影与电影之间是没有联系的,所以我们在计算用户或电影的特征向量时,是可以通过并行方式来处理的。
基于MapReduce的ALS算法,一次迭代需要启动两次MapReduce过程,每次求U或V都需启动一次MapReduce过程。每次MapReduce过程,执行算法1中的步骤(2)或(3)。Hadoop的MapReduce编程模型有两个阶段Map(映射)和Reduce(规约),由于用户ID和电影ID的唯一性,基于MapReduce的ALS算法并不需要Reduce过程。
基于MapReduce的ALS算法求解U步骤如下:①输入用户评过分的电影的集合R[n](n为用户数量)及电影特征矩阵V。②启动MapReduce过程,将电影特征矩阵V分发到各个节点。输入为存在DFS上的用户评过分的电影的集合R [n]。③Map过程:输入为R [1…n],对于R[i],利用式(4),计算用户i的特征向量 Ui。输出为i,Ui。其中i为key,Ui为value。
同理,基于MapReduce的ALS算法求解V步骤如下:①输入评价过电影的用户的集合R[m](m为电影数量)及用户特征矩阵U。②启动MapReduce过程,将用户特征矩阵U分发到各个节点。输入为存在DFS上的评价过电影的用户的集合R [m]。③Map过程:输入为R [1…m],对于R [j],利用式(5),计算电影j的特征向量Vj。输出为j,Vj。其中j为key,Vj为value。
2.3 并行化算法实现细节
2.3.1 数据预处理
在实验中使用的原始数据集是由一条一条用户的评分记录组成的。每一条评分记录都以一个三元组表示:(UserID,ItemID,Rate)。其表示的含义是某一个用户对某一个对象进行打分(这里的评分我们统一用1到5分,1分表示非常不喜欢,5分代表非常喜欢)。我们需要将其进行处理得到:用户i评过分的电影的集合Ri和评价过电影j的用户的集合Rj,如果有n个用户,m部电影,则一共有n个Ri,m个Rj。
对于式(4),Ri.集合中的元素不仅仅只是评分,还需要保存用户评价过哪些电影。因为分数是1到5分,所以Ri.集合中的元素是ItemID*10+Rate。这样电影与评分一一对应,而不丢失信息。
如:ID为1的用户评过电影1,3,5,评分记录为:

则 Ri.表示为:
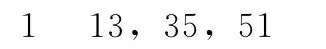
同理对于式(5),合中的元素不仅仅只是评分,还需要保存电影被哪些用户评价过。所以R.j集合中的元素是UserID*10+Rate。这样用户与评分一一对应,而不丢失信息。
如:ID为1的电影被用户1,2,3评过分,评分记录为:

则 R.j表示为:
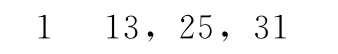
这个数据预处理过程也可以利用Hadoop的 MapReduce实现。这个预处理需要启动两次MapReduce,一次求用户评过分的电影的n个集合Ri.,一次求评价过电影的用户的m个集合R.j。MapReduce编程模型默认的输入格式是文本输入,每一行数据都是一条记录。Map函数接受一组数据并将其转换为一个key/value对列表,输入域中的每个元素对应一个key/value对。Reduce函数接受 Map函数生成的列表,然后根据它们的键(为每个键生成一个键/值对)缩小key/value对列表。
如以下是4条评分记录:

在求用户评过分的电影的集合时,运行Map函数将得出以下的key/value对列表:
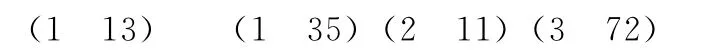
如果对这个key/value对列表应用Reduce函数,将得到以下一组key/value对:

同理在求评价过电影的用户的集合,运行Map函数将得出以下以下的key/value对列表:
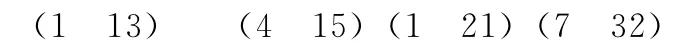
如果对这个key/value对列表应用Reduce函数,将得到以下一组key/value对:

数据预处理中MapReduce的逻辑数据流如图1所示。

图1 MapReduce的逻辑数据流
2.3.2 Hadoop参数传递
在ALS算法中,求用户特征矩阵U时需要事先知道电影特征矩阵V,求电影特征矩阵V时需要事先知道用户特征矩阵U,所以求U时,需要将V作为参数传递到算U的函数中;求V时,需要将U作为参数传递给算V的函数中。将ALS算法实现在单节点时,只需要将U和V设置成全局变量,就可以解决参数传递问题。
然而在基于MapReduce的ALS算法中,我们知道在将MapReduce作业提交给Hadoop集群时,相关的输入数据将按照Block的大小首先被划分为多个片,分发到各个节点进行计算,各个节点在计算时只执行MapReduce任务,所以MapReduce编程模型并不支持全局变量。然而在求用户特征矩阵U时,每个节点计算过程都需要知道V,这时,我们就需要将V作为参数传递到各个节点。选择合适的方式来传递参数既能提高工作效率,也可以避免bug的产生。
在基于MapReduce的ALS算法中,求用户特征矩阵U时,电影特征矩阵V是存在DFS中。我们知道在MapReduce过程中,会将输入数据按照Block的大小分块,假设分成批p块,则有p个Map任务,每个Map任务求解K个用户特征向量。如果在求每个用户的特征向量Ui时,都从DFS中读取电影特征矩阵V,那样效率会非常低,因为如果有n个用户,则需从DFS中读取n次。并且V矩阵一般比较大,其大小是m×d(m是电影数量,d为特征数),所以这种参数传递方式效率非常低,并不可取。
同理求电影特征矩阵V时,这种参数传递方式也不可取。每个Map任务在开始前都会进行初始化操作,如果在初始化时,读取文件放到变量中,将这个变量做为整个Map任务的共享变量,则读取文件次数将减少,有多少个Map任务,只需要读多少次文件,效率将大大提高。
Hadoop的分布式缓存机制使得一个job的所有map或reduce可以访问同一份文件。在任务提交后,hadoop将由-files和-archive选项指定的文件复制到 HDFS上(Job-Tracker的文件系统)。在任务运行前,TaskTracker从Job-Tracker文件系统复制文件到本地磁盘作为缓存,这样任务就可以访问这些文件。对于job来说,它并不关心文件是从哪儿来的。在使用hadoop的缓存文件DistributedCache时,对于本地化文件的访问,通常使用Symbolic Link来访问,这样更方便。通过 URI hdfs://namenode/test/input/file1#myfile指定的文件在当前工作目录中被符号链接为myfile。这样job里面可直接通过myfile来访问文件,而不用关心该文件在本地的具体路径。
2.3.3 Map函数实现
由于用户ID和电影ID的唯一性,基于MapReduce的ALS算法并不需要Reduce过程。Map函数主要对输入的每一条数据进行处理,其默认的输入格式是文本输入,每一行数据都是一条记录。在数据预处理时,我们已经知道,每一行的数据格式是:
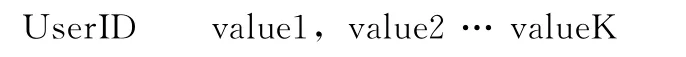
或者:
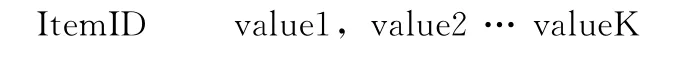
Map的任务就是求每一个用户或每一个对象的特征向量。
3 实验评估
本章主要对ALS算法在Hadoop平台实现的性能进行评估,并阐述实验环境和实验结果。
3.1 Hadoop集群配置
我们的Hadoop集群配置如下:在实验中分别使用了一台Master、2台Slave和一台Master、5台Slave组成的Hadoop集群。所有的机器都是HP计算机,每台计算机配置为4颗Intel(R)Core(TM)i7处理器,8GB内存。这些机器都处于同一个局域网内。
3.2 实验数据集
在这个实验中,我们使用的数据集是Netflix对外发布的一个电影评分数据集[2,5]。这个数据集包括了480 189个用户在对17 770部电影的103,297,638个评分。所有的评分值都是1到5中的整数值,其中分数越高表示客户对相应电影的评价越高(越喜欢)。这个数据集非常稀疏,有将近99%的评分值未知。从这个数据集中随机抽取140万条评分记录作为测试集TestSet,其余作为训练集TrainSet。
3.3 实验结果
本论文进行了3个实验,分别是ALS算法在单节点的实现,在一台Master、2台Slave的Hadoop集群中的实现和在一台Master、5台Slave的Hadoop集群中的实现。
ALS算法中有两个参数,分别是特征个数和迭代次数。
在第一轮实验中,设定迭代次数为1,特征个数分别为10,20,30,40,50。最终实验结果如图2所示。

图2 ALS迭代次数为1的实验结果
横坐标为特征个数,纵坐标为时间,单位为秒(S)。
由图2可以看出,随着特征数的增多,ALS算法在单节点运行的时间与在Hadoop集群上运行的时间之间的比例是越来越大,当特征数为50时,其比例达到了5。由式(4)和式(5)可知,特征数的增多,意味着运算复杂度增加。当特征数为10时,ALS算法在单节点运行的时间比在Hadoop集群运行的要快,这是因为Hadoop集群进行并行化时,master需要进行调度,特征数为10时,运算复杂度并不高,所以用Hadoop集群进行并行计算,并不能体现出并行计算的威力。
Hadoop集群中节点的增多,意味着其运算能力的增加,从图2可以看出,5个nodes的Hadoop集群运算效率要比2个nodes的Hadoop集群高。当然,并不是越多机器越好,假设每个节点处理一个Map任务,当节点数多于Map任务时,节点的增多并不能提高运算效率,此时多于的机器会被闲置。所以理想情况下,Map任务数最好是Hadoop集群节点数的倍数,这样才能有效充分利用Hadoop集群的运算能力。
在第二轮实验中,设定迭代次数为10,特征个数分别为10,20,30,40,50。最终实验结果如图3所示。

图3 ALS迭代次数为10的实验结果
横坐标为特征个数,纵坐标为时间,单位为:分钟。
在这两个实验中,可以看出特征数越多,迭代次数越多,ALS算法在Hadoop集群上的运算效率会提高的越多。
4 结束语
本文对推荐系统的协同过滤算法进行介绍,并针对其中基于矩阵分解的ALS算法进行了详细介绍;同时还对Hadoop平台产生的背景,应用背景,平台架构和核心部分做了比较详细的介绍;然后在上述基础上实现ALS算法在Hadoop平台的并行化,以提高算法性能。
通过实验,我们可以清楚看到基于Hadoop平台实现的算法在运算效率上提高的非常明显。当然,在实验中,我们的实验数据集还不够大,还不能完全体现出Hadoop的优势来,据我们所知Yahoo为了满足广告系统和web搜索的研究,在4000个服务器集群上部署Hadoop;Facebook使用了1000个节点的集群部署HDFS,以支持其大量的日志数据的存储;淘宝网则使用hadoop集群网络处理大量的电子商务相关的数据;百度公司利用hadoop并行计算系统,进行大规模网页的分析与搜索,其处理数据达每周200TB。因此协同过滤推荐算法的并行化至关重要,其应用前景非常广泛。
在本实验中我们实现了基于矩阵分解的ALS协同过滤算法在Hadoop平台的并行化,在时间效率上有提高,但Hadoop集群除了受集群机器数影响,还有受一些参数配置的影响,如:文件Block的大小,文件的复制数等,这些参数配置对Hadoop集群的影响将是下一步工作。本文所提出的并行化ALS的算法思想还可以运用于并行化其他的协调过滤算法,如RBM、NNMF等。
[1]LUO Xin,OU YANG Yuanxin,XIONG Zhang,et al.The effect of similarity support in K-nearest-neighborhood based collaborati ve filtering [J].Chinese Journal of Computers,2010,33(8):1437-1445(in Chinese).[罗辛,欧阳元新,熊璋,等.通过相似度支持度优化基于K近邻的协同过滤算法 [J].计算机学报,2010,33(8):1437-1445.]
[2]Ricci F,Rokach L,Shapira B,et al.Recommender system handbook [M].New York:Springer,2011:1-29.
[3]Das A,Datar M,Garg A,et al.Google news personalization:Scalable online collaborative filtering [C].Canada:Proceedings of the 16th International Conference on World Wide Web,2007:271-280.
[4]Adomavicius G,Tuzhilin A.Toward the next generation of recommender systems:A survey of the state-of-the-art and possible extenstions [J].TKDE,2005,17(6):734-749.
[5] WU J L.Collaborative filtering on the netflix prize dataset[EB/OL].[2010-08-01].http://dsec.pku.edu.cn/~jinlong/
[6]PAN R,ZHOU Y,CAO B,et al.One-class collaborative filtering[C].Pisa,Italy:Proceedings of the Eighth IEEE International Conference on Data Mining,2008:502-511.
[7]PAN R,Martin S.Mind the gaps:Weighting the unknown in large-scale one-class collaborative filtering [C].Paris,France:Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,2009:667-676.
[8]ZHOU Y H,Wilkinson D,Schreiber R,et al.Large-scale parallel collaborative filtering for the Netflix prize [C].Berlin:Proceedings of the 4th International Conference on Algorithmic Aspects in Information and Management,2008:337-348.
[9]Srebro N,Rennie J D M,Jaakkola T.Maximum-margin matrix factorization [C].Vancouver:MIT Press(NIPS),2004:1329-1336.
[10]Rennie J D M,Srebro N.Fast maximum margin matrix factorization for collaborative prediction [C].Bonn,Germany:Proceedings of the 22nd International Conference on Machine Learning,2005:713-719.
[11]Salakhutdinov R,Mnih A.Probabilistic matrix factorization [C].Vancouver,British Columbia,Canada:Proceedings of the 25th International Conference on Machine Learning,2007:1257-1264.
[12]Salakhutdinov R,Mnih A,Hinton G.Restricted boltzmann machines for collaborative filtering [C].NY,USA:Proceedings of the 24th International Conference on Machine Learning,2007:791-798.
[13]LEE D D,Seung H S.Learning the parts of objects by non-negative matrix factorization [J].Nature,1999,401(11):788-791.
[14]Tom Wbite.Hadoop:The definitive guide [M].2nd ed.USA:O'Reilly Media,Inc,2010:1-60.
[15]Apach HDFS Architecture [EB/OL].http://hadoop.apache.org/hdfs/docs/current/cn/hdfs_design.html.
[16]Jeffrey Dean,Sanjay Ghemawat.Map reduce:Simplified data processing on large clusters [C].San Francisco,CA:Proceedings of the 6th Conference on Symposium on Opearting Systems Design &Implementation,2004:137-150.
