浅谈存储过程在科研管理系统中的应用
2012-04-29李琼汉
摘要:该文阐述了存储过程在科研管理系统中的应用,简单介绍了科研管理系统的功能模块、存储过程的优点、存储过程的创建。
关键词:数据库;存储过程;科研管理系统
中图分类号:TP311文献标识码:A文章编号:1009-3044(2012)02-0464-03
Discussion on the Stored Procedure in the Application of Scientific Research Management System
LI Qiong-han
(Hainan College of Software Technology ,Qionghai 571400, China)
Abstract: This paper expounds the stored procedure in the scientific research management system application, introduces the scientific re? search management system function module, storage process advantages and create procedure.
Key words: database; storage process; scientific research management system
1概述
在各种系统开发中,使用存储过程是一个良好的习惯,不仅可以带来临时表、函数、游标等特性,而且调试、升级、维护都变得方便。在存储过程中能够把数据经过处理再返回,这样能够对数据提供更多的分析和控制。。存储过程是数据库中的一个重要对象,任何一个设计良好的数据库应用程序都应该用到存储过程。
2存储过程的优点
2.1开发效率高
端代码量很少,基本上是将客户端的数据,原原本本传入到存储过程。所有的计算都在存储过程里完成,开发调试方便。存储过程只在创造时进行编译,以后每次执行存储过程都不需再重新编译,而一般SQL语句每执行一次就编译一次,所以使用存储过程可提高数据库执行速度。
2.2维护方便
一般后台有什么错误,都在存储过程里,修改完了不需要重启服务,基本不会干扰客户运营.当对数据库进行复杂操作时(如对多个表进行Update,Insert,Query,Delete时),可将此复杂操作用存储过程封装起来与数据库提供的事务处理结合一起使用。
2.3安全性高
一个用户可能没有执行存储过程中语句的权限,但是可以被赋予执行存储过程的权限,这就增强了数据库的安全性。另外,可以通过存储过程来隐藏用户可用的数据和数据操作中涉及的商业规则,提高了数据安全级别。相对于直接使用SQL语句,在应用程序中直接调用存储过程有以下好处:
2.3.1减少网络通信量
调用一个行数不多的存储过程与直接调用SQL语句的网络通信量可能不会有很大的差别,可是如果存储过程包含上百行SQL语句,那么其性能绝对比一条一条的调用SQL语句要高得多。
2.3.2执行速度更快
有两个原因:首先,在存储过程创建的时候,数据库已经对其进行了一次解析和优化。其次,存储过程一旦执行,在内存中就会保留一份这个存储过程,这样下次再执行同样的存储过程时,可以从内存中直接调用。
2.3.3更强的适应性
由于存储过程对数据库的访问是通过存储过程来进行的,因此数据库开发人员可以在不改动存储过程接口的情况下对数据库进行任何改动,而这些改动不会对应用程序造成影响。
2.3.4分布式工作
应用程序和数据库的编码工作可以分别独立进行,而不会相互压制。
科研项目申报模块:教师个人登录后,可上传项目申报书,查看项目审批状态,修改个人登录密码,申报者可以查看是否通过。
科研数据录入模块:教师个人科研信息的录入,其中科研信息主要包括论文.项目,获奖、教材专著和课题等。
科研数据管理模块:教师个人科研信息的修改、删除。
科研项目审核模块::管理员对教师申报的科研项目进行审核、审批。
查询、统计和报表打印模块:对各种科研信息进行统计和报表的打印,包括对教师个人发表的科研论文、著作、获奖、本年度批准的科研项目情况统计和打印。
角色管理:主要实现系统的安全管理。包括添加用户,用户管理等.以实现对用户和用户角色的管理。角色管理是专为具有系统管理员权限的用户设计的。系统在数据库中首先设置一个或多个具有管理员权限的用户,通过用户登录来判断用户的权限,若为管理员则可进入该模块,实现对整个科研数据库的维护与管理(包括增加、修改、删除等多项操作)。
基本设置模块:主要包括年度、科研类别、研究类别、获奖类别、部门等一些基本信息的添加。
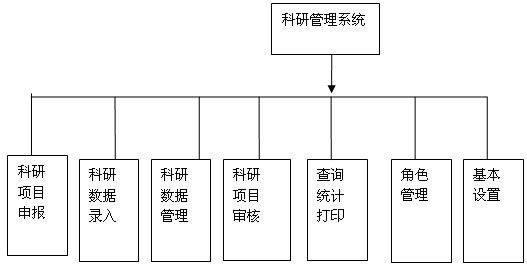
图1
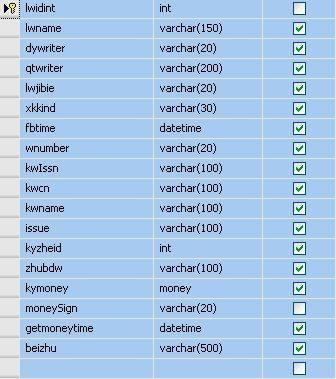
图2
4创建存储过程
下面以论文表为例,介绍存储过程在科研管理系统中的应用。
图2所示是论文表的字段构成。
--论文存储过程(包含插入论文与修改论文)
createproc [dbo].[proc_lunwen]
@lwidint integer=null, --论文id
@lwname varchar(150),--论文名称
@dywriter varchar(20),--第一作者
@qtwriter varchar(200),--其他作者
@lwjibie varchar(20),--级别
@xkkind varchar(30),--学科分类
@fbtime datetime ,--发表时间
@wnumber varchar(20),--字数
@kwIssn varchar(100),--刊物编号
@kwcn varchar(100),--国内编号
@kwname varchar(100),--刊物名称
@issue varchar(100),--期号(发表时间期数)
@kyzheid int,
@zhubdw varchar(100),--主办单位
@beizhu varchar(500)--备注
as
if isnull(@lwidint,0)=0 --插入记录
begin
insert lunwen(lwname,dywriter,qtwriter,lwjibie,xkkind,fbtime,wnumber,kwIssn,kwcn,kwname,issue,kyzheid,zhubdw,beizhu) values(@lw? name,@dywriter,@qtwriter,@lwjibie,@xkkind,@fbtime,@wnumber,@kwIssn,@kwcn,@kwname,@issue,@kyzheid,@zhubdw,@beizhu)
end
else--修改记录
begin
update lunwen
set lwname=@lwname,
dywriter=@dywriter,
qtwriter=@qtwriter,
lwjibie=@lwjibie,
xkkind=@xkkind,
fbtime=@fbtime,
wnumber=@wnumber,
kwIssn=@kwIssn,
kwcn=@kwcn,
kwname=@kwname,
issue=@issue,
zhubdw=@zhubdw,
beizhu=@beizhu
where lwidint=@lwidint
end
--统计论文存储过程
create proc [dbo].[tjlw] @dt1 varchar(20) ,@dt2 varchar(20)
as
create table #lw(
lwid int identity(1,1),
dywriter varchar(20) null,
qtwriter varchar(200) null,
fbtime datetime null,
lwname varchar(150) null,
kwname varchar(150) null,
kwissn varchar(100) null,
kwcn varchar(100) null,
issue varchar(100) null,
kyzheid int null,
beizhu varchar(500) null
)
create table #kyzhe(
kyid int identity(1,1),
kyzheid int null,
bmname varchar(20) null
)
create table #lwtj_temp(
lw_tid int identity(1,1),
dywriter varchar(20) null,
qtwriter varchar(200) null,
fbtime datetime null,
lwname varchar(150) null,
kwname varchar(150) null,
kwissn varchar(100) null,
kwcn varchar(100) null,
issue varchar(100) null,
kyzheid int null,
bmname varchar(20) null,
beizhu varchar(500) null
)
create table #lwtj(
id int identity(1,1),
writer varchar(200) null,--dywriter、qtwriter姓名
lwname varchar(150) null,--成果名称
fbtime datetime null,
chenggly varchar(200) null, --kwname、kwissn、kwcn成果来源
issue varchar(100) null,--发表时间
kyzheid int null,
bmname varchar(20) null,--系部
beizhu varchar(500) null
)
insert into #lw select dywriter ,qtwriter,fbtime,lwname,kwname,kwissn ,kwcn ,issue ,kyzheid ,beizhu from lunwen
insert into #kyzhe select kyzheid,bmname from kyzhe
declare @row int,
@i int,
@dywriter varchar(20),@qtwriter varchar(200),@fbtime datetime,@lwname varchar(150),@kwname varchar(100),@kwissn varchar(100),@kwcn varchar(100),@writer varchar(200),@chenggly varchar(200),
@issue varchar(100),@kyzheid int,@bmname varchar(20),@beizhu varchar(500)(下转第468页)
(上接第466页)
set @i=1
insert into #lwtj_temp select dywriter,qtwriter,fbtime,lwname,kwname,kwissn,kwcn,issue,#lw.kyzheid,bmname,beizhu from #lw join #ky? zhe on #lw.kyzheid=#kyzhe.kyzheid
set @row=@@rowcount
while @i<=@row
begin
--print i=+convert(varchar,@i)
select@dywriter=dywriter,@qtwriter=qtwriter,@fbtime=fbtime,@lwname=lwname,@kwname=kwname,@kwissn=kwissn,@kwcn=kwcn,@issue=issue,@kyzheid=kyzheid,@bmname=bmname,@beizhu=beizhu from #lwtj_temp where lw_tid=@i
set @writer=@dywriter+、+@qtwriter
set @chenggly=@kwname+、+@kwissn+、+@kwcn
insert into #lwtj select @writer,@lwname,@fbtime,@chenggly,@issue,@kyzheid,@bmname,@beizhu
set @i=@i+1
end
select * from #lwtj where fbtime>=@dt1 and fbtime<=@dt2
创建以上存储过程后,保存之。保存完毕,与该存储过程相对应的节点就会出现在服务器资源管理器中。同时请注意代码编辑窗口中的CREATE关键字变为ALTER关键字了,该关键字是用于更改任何现有的存储过程的。要运行上述存储过程,只要点击其节点并在右键弹出菜单中选择“运行存储过程”。
5结束语
设计具有高可靠性、高响应速度的软件系统是一件很难的事情。从数据库设计、系统的架构设计到存储过程设计和代码的编写,每个环节都息息相关。在设计过程中充分地考虑存储过程的应用,会给软件设计带来极大的便利,从而大大提高设计效率。
参考文献:
[1]李琼汉,周恩.基于ASP.NET AJAX的高校科研管理系统的设计与实现[J].电脑知识与技术,2011,7(2).
[2]【美】Sanjeev Rohilla. ADO.NET专业项目实例开发[M].陈君,王宝良,译.北京:中国水利水电出版社2003.
