基于ARM Cortex-M3核的SoC架构设计及性能分析
2012-03-15陶友龙赵安璞陈海波
陶友龙,赵安璞,陈海波
(东南大学 国家ASIC系统工程技术研究中心(无锡),江苏 无锡214135)
ARM Cortex系列是ARM公司推出的基于ARMv7架构、使用高性能的Thumb-2指令集的32位嵌入式微处理器核。主要有三种款式,分别是Cortex-A、Cortex-R和Cortex-M。其中Cortex-M系列主要用于低功耗、低成本的嵌入式应用。本文用于 SoC(System on Chip)设计的Cortex-M3核便属于该系列。该处理器核凭借其高性能、低功耗、低成本和开发方便等特点,受到了各厂商的青睐。STMicroelectronics、NXP Semiconductors、ATMEL 等都竞相推出各自基于Cortex-M3核的SoC。由于Cortex-M3核的结构与传统ARM核有很大区别,因此基于Cortex-M3的SoC架构设计也有与以往不同的特点。不同的架构对芯片整体性能影响很大。本文使用CoreMark对实际芯片作了性能测试,其结果证明了SoC架构对芯片性能的影响。
1 Cortex-M3核SoC架构设计
1.1 总线接口
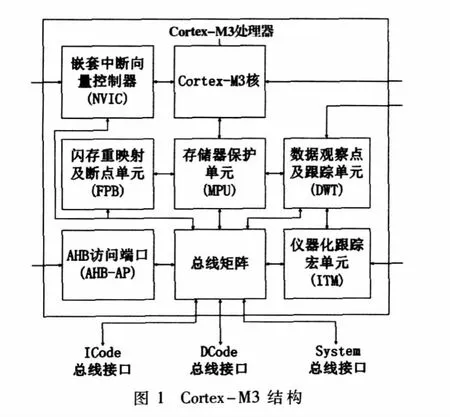
处理器核对SoC架构最大的影响是其总线接口。传统的ARM处理器使用单一总线接口。如ARM7处理器采用冯诺依曼结构,指令和数据共用一条总线,从而核外部为单总线接口[1];ARM9虽然使用了哈佛结构,核内部指令总线和数据总线分开,但这两条总线共用同一存储空间,且在核外共用同一总线接口[2]。使用单一总线接口的弊端是取指和取数据无法并行执行,效率相对较低。
Cortex-M3的结构如图1所示。Cortex-M3采用了多总线结构,在核外有 ICode、DCode、System三个总线接口[3]。其中,ICode和DCode总线接口使得在地址空间Code区中的取指和取数据分开并行执行,而System总线使得在地址空间SRAM区中的取指和取数据使用同一总线接口,无法并行执行。
1.2 SoC架构设计
由Cortex-M3的结构特点可以看出,Cortex-M3不适合像传统ARM处理器那样将代码由Flash搬移到RAM来提高效率,那样反而可能会降低效率(由于SRAM区中的取指和取数据使用同一总线接口)。而Cortex-M3是将代码和只读数据放在Flash中,程序执行时将可读写数据放在RAM中,从而获得最高效率。
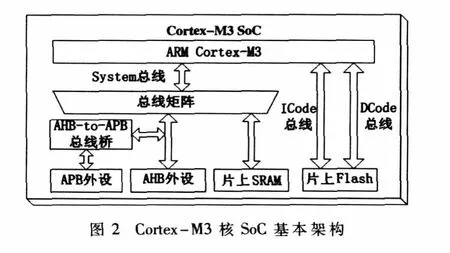
基于以上考虑,设计Cortex-M3核的SoC时,最好将片上Flash挂接在ICode和DCode总线上,即0x00000000~0x20000000地址空间,如图2所示,将片上 SRAM挂接在 System总线上,即0x20000000~0x40000000地址空间。这样从Flash中取指和取只读数据可以分别通过ICode和DCode总线并行执行,提高了Flash的读取效率。而对SRAM中的数据读写通过System总线进行。三条总线各自分工,使得SoC性能大大提高。
1.3 自主设计的Cortex-M3核SoC
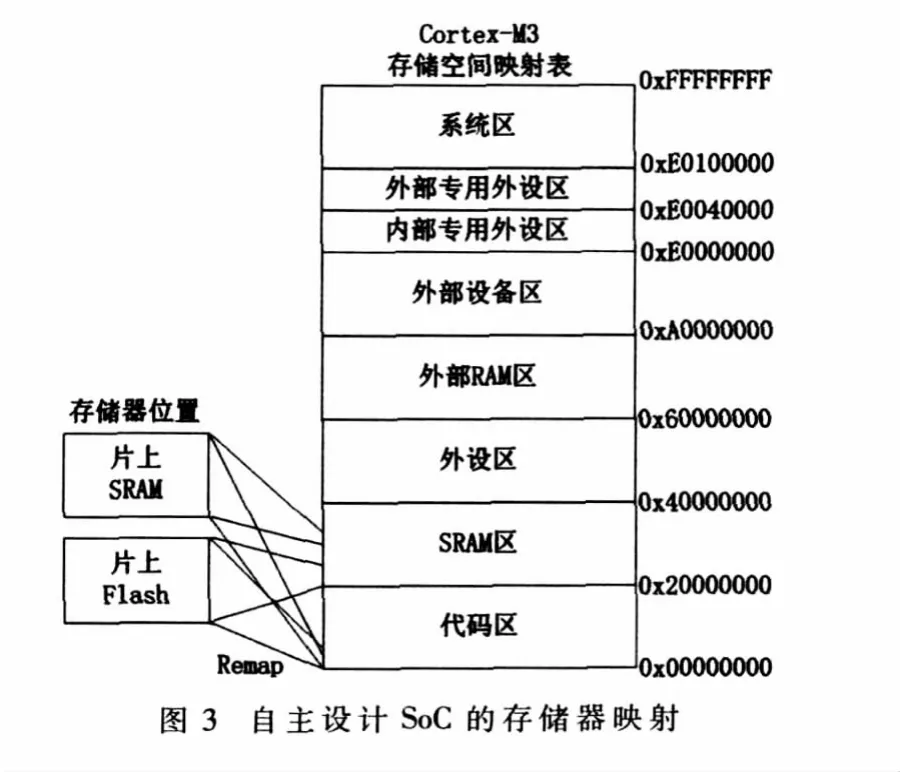
实验室自主设计了一款基于Cortex-M3核的SoC,并采用 0.18 μm CMOS工艺流片成功。如图 3所示,芯片的片上Flash从0x20000000开始,共256 KB;片上SRAM从0x30000000开始,共96 KB。其架构特点是片上Flash和片上 SRAM均处于0x20000000~0x40000000地址空间,即挂接在System总线上,但两者均可再映射Remap到0地址,即可挂接到ICode和DCode总线上。
默认情况下片上SRAM可Remap到0地址,这意味着SRAM默认拥有0x00000000和0x30000000两个起始地址。因此,将代码放在SRAM中时,若从0x00000000地址开始执行,则处理器通过ICode和DCode总线来访问SRAM;若从0x30000000地址开始执行,则处理器通过System总线来访问SRAM。下面将利用这特一点来进行性能分析。
2 性能测试及分析
2.1 CoreMark简介
传统的嵌入式微处理器性能测试普遍采用Dhrystone程序,WEICKER R P通过统计程序中常用的操作及其所占比例,构建了一个测试基准,并经过多次完善,才得到了 Dhrystone程序[4]。但Dhrystone程序本身过于简单,并不能准确反映处理器运行实际应用程序时的性能。
EEMBC组织自成立之初就打算制定一种能够代替Dhrystone并能更好地测量嵌入式微处理器性能的标准。但由于EEMBC的程序和认证一般都是收费的,所以其发布的测试程序一直没能得到很好的普及。直到其发布了完全公开和免费的CoreMark程序,才逐渐改变这一局面,并有取代Dhrystone的趋势。CoreMark是一个虽代码量小但很复杂的测试程序,通过执行应用程序中常用的数据结构和算法来测试处理器性能,其内容包括链表操作、矩阵运算和CRC校验等,可以更好地反映处理器运行实际应用程序时的性能。本文采用CoreMark来测试SoC的性能。
2.2 自主设计SoC的性能测试
使用Keil开发环境:将CoreMark程序放在芯片的片上SRAM中,分别设置从片上SRAM的两个起始地址执行,其在72 MHz主频时的测试结果如表1所示。
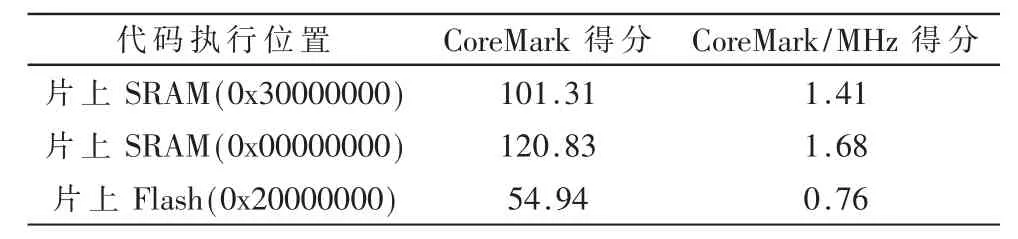
表1 自主设计的SoC测试结果
可见,对于同一片上SRAM存储器,从0x00000000地址访问执行比从0x30000000地址访问执行时的处理器性能要高出约20%。因此,使用ICode和DCode总线取指和取只读数据比使用System总线性能要高。在今后的设计中将取消Remap,直接将片上Flash放在从0x00000000开始的空间,将片上SRAM放在从0x30000000开始的空间,实现取指、取只读数据、取可读写数据并行执行,从而达到最佳性能。
2.3 STM32F103性能测试
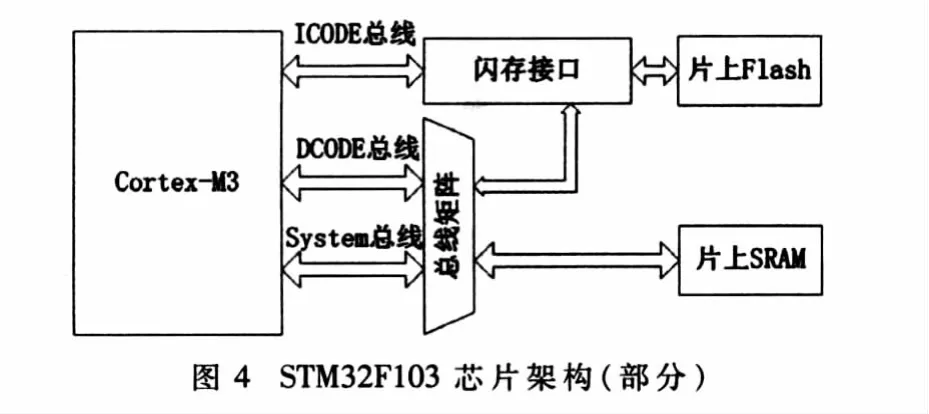
意法半导体的STM32系列MCU是目前市场上最常见的Cortex-M3核SoC之一,该系列中的STM32F103架构如图4所示[5]。该芯片的片上 Flash挂接在 ICode和DCode总线上,片上SRAM挂接在System总线上。其中ICode总线直通 Flash,而 DCode总线和 System总线通过一个总线矩阵分别连接到片上Flash和片上SRAM及其余外设。此外,STM32采用了一个64 bit的Flash,并使用了一个2×64 bit的缓冲器,一次可缓存 128 bit数据,从而大大降低了Flash的访问频率,弥补了Flash速度较慢的缺陷,使得取指和取只读数据的速度大大提高。该架构与前述分析基本一致,故可以保证最佳性能。
使用CoreMark对STM32F103进行性能测试。将代码分别放在片上SRAM和片上Flash中执行,其在72 MHz主频时的测试结果如表2所示。

表2 STM32F103测试结果
可见,STM32F103在片上Flash中执行代码的性能超过了在片上SRAM中的性能。主要原因是在片上Flash中执行时,三条总线合作分工,加之Flash本身位宽较大(64 bit),且外部有 2×64 bit缓冲器,因此效率很高,代码在片上Flash中执行的性能可以与在片上SRAM中执行时相当。
与实验室自主设计的SoC相比,两芯片在片上SRAM中执行代码的性能几乎相同。这是因为两者均只使用System总线对SRAM进行访问,且两芯片的SRAM存取速度均跟得上Cortex-M3核对其访问的速度。但如表1所示,自主设计的SoC在片上Flash中执行代码的性能还不到STM32F103的一半,原因是所使用的Flash本身速度较低、位宽较低(2×16 bit),且没有采用外部高位宽缓冲器等手段减少访存频率,再加上测试时Flash挂接在System总线上,因此Flash的性能成为了所设计SoC的性能瓶颈。
3 影响SoC性能因素
(1)芯片架构:由以上分析可见,芯片架构对SoC性能有很大的影响。要想获得最佳性能,关键是要深入了解所用处理器核的结构特点,再据其采用合适的芯片架构。
(2)存储器速度:存储器速度尤其是Flash速度也是限制SoC性能的一个关键因素。存储器速度越慢,CPU需要插入的等待周期就越多,效率就越低。这一点在上述自主设计的SoC中就不够好,需要在Flash部分作大的改进。而STM32在这方面做得很好,通过加大存储器位宽和增加缓冲器使Flash不会成为芯片性能的瓶颈。
(3)工艺:工艺对存储器速度及芯片整体性能的影响是显而易见的,更先进的工艺意味着更高的性能。但提升工艺同时意味着增加流片成本,故需根据实际情况考虑。
(4)主频:主频越高,意味着同一段时间内可以执行更多的指令,即测试结果CoreMark总分提升,但CoreMark/MHz没变。此外,若 Flash速度跟不上,则会将最高性能限制住,提升主频不但不会提高整体性能,反而还会降低效率,即测试结果CoreMark总分不变,Core-Mark/MHz反而降低。
本文主要研究了基于ARM Cortex-M3核的SoC架构设计,重点分析了处理器核的总线接口对芯片架构设计的影响。采用CoreMark程序,对实验室自主设计的一款Cortex-M3核SoC以及意法半导体的STM32F103 MCU进行了性能测试及分析,说明了芯片架构对性能的影响。最后,对影响SoC性能的因素作了总结。对高性能的Cortex-M3核SoC设计有着指导作用,对一般的SoC设计也有借鉴意义。
[1]ARM Ltd..ARM7TDMI Technical Reference Manual Revision:r4p1,2004.
[2]ARM Ltd..ARM920T Technical Reference Manual Rev 1,2001.
[3]ARM Ltd..Cortex-M3 Technical Reference Manual Revision:r2p1,2010.
[4]WEICKER R P.Dhrystone:A synthetic systems programming benchmark[J].Communications of the ACM,1984,27(10):1013-1030.
[5]ST Microelectronics Ltd..STM32F101xx,STM32F102xx,STM32F103xx,STM32F105xx and STM32F107xx advanced ARM-based 32-bit MCUs Reference manual Rev 11,2010.
