基于Hadoop的海量电信数据云计算平台研究
2012-03-12黎宏剑黄广文
黎宏剑,刘 恒,黄广文,卜 立
(中国移动通信集团广东有限公司中山分公司 中山 528403)
1 引言
随着3G时代的来临,移动业务日益丰富,用户在使用移动业务过程中产生的各类数据以TB级速度增长。面对激烈的市场竞争,如何快捷、高效、安全地管理和分析海量的业务数据,深度挖掘业务特征,实行精确营销策略,成为电信运营商确保竞争优势的关键举措之一。
目前,面对海量的业务数据,电信运营商存在管理和分析难的问题。业务数据的管理要求高效存储、高效读取、高可用性及高扩展性架构,业务数据每天以TB级速度增长,基于传统关系型数据库的数据管理难以满足其要求,或需付出高昂的成本代价实现。对业务特征的挖掘分析,往往涉及网络域和业务支撑域的大数据以及这些大数据之间的关联。传统的关系型数据库对这些大数据的运算需要搭配高性能的机器,运算时间长,分析结果存在严重滞后性,直接导致错过了对相应行为采取有效措施的最佳时机。
Hadoop分布式技术的发展为解决上述问题提供了技术手段。Hadoop是一个在集群上运行大型数据库处理应用程序的开放式源代码框架,采用MapReduce编程模型对海量数据进行有效分割和合理分配,以实现高效并行处理,并行程序编写简单,节省时间。Hadoop分布式云计算平台对硬件配置要求不高,具有可伸缩性和高容错性,实施成本低。本文在研究云计算和Hadoop的基础上,设计并部分实现了基于Hadoop的海量电信数据云计算平台。
2 相关技术简介
2.1 云计算
云计算基于互联网相关服务的增加、使用和交付模式,是并行计算、分布式计算、网格计算综合发展的结果。它将计算任务分布在大量计算机构成的资源池上,使各种应用系统能够根据需要获取计算力、存储空间和信息服务,具有数据安全可靠、可共享、扩展性强、规模大、价格低廉等特点。按照提供服务的不同,云计算分为SaaS(software as a service,软件即服务)、PaaS(platform as a service,平 台 即 服务)和 IaaS(infrastructure as a service,基础设施即服务)3类。云计算以数据为中心,在并行数据处理、编程模式和虚拟化等方面具有独特的技术。
2.2 Hadoop
Hadoop是由Apache基金会组织开发的分布式计算开源框架,利用低廉设备搭建大计算池,以提高分析海量数据的速度和效率,是低成本的云计算解决方案。其模仿和实现了Google云计算的主要技术,包括HDFS(Hadoop distributed file system,Hadoop 分布式文件系统)、MapReduce、HBase、ZooKeeper等,分别对应于Google成熟商用云计算平台的GFS(Googlefilesystem,Google文件系统)、MapReduce、BigTable、Chubby,支持通过 Google的MapReduce编程范例创建并执行应用程序。
Hadoop是相关子项目的集合,核心是Hadoop Common、HDFS和MapReduce,其他子项目提供补充性服务。Hadoop技术栈如图1所示,具体介绍如下。

图1 Hadoop技术栈
Hadoop Common:支撑Hadoop的公共部分,是最底层的模块,为其他子项目提供各种工具。
HDFS:是一个主从 (master/slave)结构,由一个NameNode(名称节点)和若干个 DataNode(数据节点)构成,NameNode管理文件系统的元数据,DataNode存储实际数据。
MapReduce:处理海量数据的并行编程模型和计算框架,采用“分而治之”思想,包括分解任务的map函数和汇总结果的reduce函数,MapReduce任务由一个JobTracker和若干个TaskTracker控制完成,JobTracker负责调度和管理TaskTracker,TaskTracker负责执行任务。
Pig:SQL-like语言,是在MapReduce上构建的一种高级查询语言,以简化MapReduce任务的开发。
Hive:数据仓库工具,提供SQL查询功能。
Hbase:基于列存储模型的分布式数据库。
ZooKeeper:针对分布式系统的协调服务。
Chukwa:分布式数据收集和分析系统。
Avro:提供高效、跨语言RPC的数据序列系统,持久化数据存储。
Hadoop具有可扩展、高容错、经济、可靠、高效的优点,被广泛应用在云计算领域,在Yahoo、Facebook、支付宝、人人网等大型网站上都已经得到了应用,是目前应用最为广泛、成熟的开源云计算平台。
3 基于Hadoop的海量电信数据云计算平台设计
目前,电信运营商对海量电信数据的分析都是基于传统的关系型数据库,这种分析方法依赖于高性能机器,分析时间长、效率不高,直接影响了业务决策时机。
针对这些问题,结合海量电信数据的特点,本文提出利用Hadoop云计算技术对海量电信数据进行分析的方法,该方法通过构建基于Hadoop的海量电信数据云计算平台,采用MapReduce编程模型加强对数据的管理,提高数据分析的速度和效率,解决了电信运营商对海量电信数据管理和分析难的问题。
3.1 平台设计的目标与原则
海量电信数据云计算平台的设计目标是利用Hadoop基于低廉设备的海量数据处理优势,利用一批下线的低端PC服务器搭建Hadoop云计算平台,支撑海量电信数据的分析需求,提高数据分析的速度和效率,达到为业务决策提供即时、准确信息的目的,同时为公司节约投资成本。
平台的设计原则包括:经济原则,充分利用现有资源搭建平台基础设施,根据Hadoop对硬件要求不高的特点,采用一批下线低端PC服务器搭建Hadoop集群;高效原则,充分利用云计算平台的特性,提高海量电信数据的处理效率;安全原则,在平台设计过程中,必须充分考虑平台的自身安全和信息安全,采取必要措施,规避安全风险。
3.2 平台框架结构
结合海量电信数据自身的特点,海量电信数据云计算平台在设计上采用分布式、分层结构,可以划分为数据层、模型层、应用层3层结构,如图2所示。
(1)数据层
海量电信数据包括网络域数据和业务支撑域数据。其中,网络域数据包括Gb口数据、A口数据、WLAN数据等;业务支持域数据包括客户信息、客户业务订购数据、客户消费数据等客户基本数据。数据层通过Hadoop的HDFS存储这些数据,然后利用 Hbase、Hive、Pig、ZooKeeper等数据处理和管理工具,用类SQL语言定义统计指标,动态生成MapReduce任务进行计算和聚合,对海量电信数据进行高效处理,处理结果仍以文件格式存储在HDFS中,并可导出为所需格式。
客户会上,美丰加蓝同与会客户探讨了市场情况、生产技术、售后服务等方面内容。今年,美丰加蓝创新设置了“推广之星”“潜力之星”和“销量之星”等三个奖项,对在合作过程中表现突出的优秀客户进行表彰奖励。
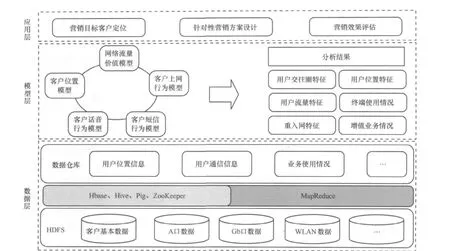
图2 海量电信数据云计算平台框架结构
(2)模型层
模型层利用数据层对海量电信数据进行基于Hadoop的ETL处理输出的汇总数据,建立分析模型,如客户位置模型、客户上网行为模型、客户短信行为模型、客户话音行为模型等基础模型,实现客户位置、客户离网预警、客户交往圈等分析应用。
(3)应用层
应用层是利用模型分析得出的结果,如生活轨迹特征、增值业务使用情况、用户的交往圈特征等,精确定位营销目标客户,设计针对性营销方案,并对营销效果进行评估分析。
3.3 平台功能模块
海量电信数据云计算平台的功能模块包括用户管理、数据管理、任务管理、集群管理4个模块,如图3所示。
·用户管理模块:包括账号开通、身份认证、权限管理、交互控制。
·数据管理模块:包括数据的上传和下载、删除。
·任务管理模块:包括任务申请、资源申请、结果反馈。
·集群管理模块:包括Hadoop集群状态和任务进度、节点管理。

图3 海量电信数据云计算平台的功能模块
3.4 网络拓扑结构
Hadoop集群局域网由 1台 NameNode服务器、1台Secondary NameNode服务器、1台JobTracker服务器和多台从服务器组成。
·NameNode服务器负责管理海量数据文件的分割、存储以及监控DataNode的运行情况。应用程序需要读取数据文件,首先访问NameNode服务器,获取数据文件在各DataNode上的分布,然后直接与DataNode通信。一旦发现某个DataNode宕机,NameNode将通知应用程序访问宕机节点各数据块的副本,并在其他DataNode上增加宕机节点各数据块的副本,以保证平台的可靠运行。

·Secondary NameNode服务器用来监控HDFS状态,与NameNode进行通信,以便定期保存HDFS元数据的快照,若NameNode发生问题,其作为备用NameNode使用。
·JobTracker服务器负责管理计算任务的分解和汇总,负责监控各TaskTracker节点的运行情况,一旦某个任务失败,JobTracker自动重新启动这个任务。
·从服务器承担了DataNode和TaskTracker两种角色,分别负责数据块的存储和数据计算的map、reduce任务的运行。
3.5 平台安全机制
由于Hadoop集群节点之间是互通的,对Hadoop集群节点操作的账号是统一的,同时电信数据属于敏感数据,Hadoop本身的机制难以对数据进行有效的安全控制,在一定程度上存在安全问题。为规避安全风险,防范安全事故的发生,必须采取相应的安全机制加强对平台和数据的安全管理。平台采取的安全机制包括平台自身安全管理、账号安全管理和数据安全管理。
(1)平台自身安全管理
将Hadoop集群网络划分为内部局域网,通过设置防火墙策略与其他网络进行隔离,NameNode作为唯一出口负责与外部进行通信,内部其他节点通过NameNode进行访问。同时,将NameNode加入堡垒机,将其操作的任何记录均保存在堡垒机服务器中。
(2)账号安全管理
严格控制平台管理员账号,定期更换口令;将操作Hadoop集群的账号和用于数据传输的账号分离,严格控制其访问权限;保存各账号的操作记录,定期审计。
(3)数据安全管理
电信数据属于敏感数据,必须加强敏感数据的保密工作,主要通过记录数据进出、分开存放、传输加密和记录人员对数据的操作、定期审计等措施,对数据进行安全管理。
4 平台的部分实现及其效果
由于时间和精力有限,本文仅对海量电信数据云计算平台的底层Hadoop集群部署进行实现,并通过实验论证本文提出的方法及设计平台的有效性、可行性。
4.1 底层Hadoop集群部署的实现
底层 Hadoop集群包括 1个 NameNode服务器、1个JobTracker服务器和4个DataNode服务器,设备配置信息见表 1。
底层Hadoop集群采用Hadoop-0.20.2版本,操作系统为Linux CentOS 5.6,Hadoop运行需要JDK环境,本文选择的是jdk1.6.0_31。

表1 集群设备配置信息
Hadoop的安装过程为:配置host文件、新建Hadoop目录和用户、安装JDK及配置环境变量、配置SSH免密码登录、安装Hadoop及配置。此外,为了增强平台的扩展性,分别安装了 Hive-0.8.1、Pig-0.9.2、Hbase-0.20.6、Zookeeper-3.3.3。其中,Hadoop、ZooKeeper和Hbase之间的启动和停止有顺序要求,介绍如下。
·启动过程:启动Hadoop→启动 ZooKeeper→启动Hbase。
·停止过程:停止Hbase→停止ZooKeeper→停止Hadoop。
4.2 实验结果
在部署好的平台中进行相关实验,验证本文提出的基于Hadoop的分布式云计算方法在海量电信数据分析方面是否存在优势。
在分布式和非分布式环境下,计算全网客户的位置信息,主要字段为:IMSI、CGI、时长、时间切片标识。实验数据为网分A口数据文件,包括话音数据call_20120316.txt(2.2 GB)、短信数据 SMS_20120316.txt(600 MB)和位置数据location_20120316.txt(3.3 GB)。实验的前提条件是假设各实验采用的机器设备在配置上都是相同的。
实验一:采用非分布式计算(Oracle数据库),在Oracle环境下的计算时长大约为4 h。
实验二:采用分布式计算,利用单数据节点进行MapReduce计算,Hadoop配置信息为 1个 NameNode、1个JobTracker和1个DataNode。运行日志如图5所示,运行时长大约为63 min。
实验三:采用分布式计算,利用两个数据节点进行MapReduce计算,Hadoop配置信息为 1个 NameNode、1个JobTracker和2个DataNode。运行日志如图6所示,运行时长大约为37 min。
通过对比实验一和实验二的运算结果得出,在大运算量上,利用Hadoop分布式计算可以大大提高计算速度和效率,本次实验缩短了3 h以上;通过对比实验二和实验三的运算结果得出,Hadoop的数据节点数影响到Hadoop的整体性能,本次实验采用2个数据节点比1个数据节点的运算时间快了近1倍。

图5 实验二的MapReduce计算过程

图6 实验三的MapReduce计算过程
可以看出,与传统的数据分析方法相比,本文提出的针对海量电信数据的分布式云计算方法,即基于Hadoop的海量电信数据云计算平台,有效地提高了海量数据分析的速度和效率。
5 结束语
本文针对传统数据分析方法面对海量电信数据存在分析效率不高的问题,提出了基于Hadoop的分布式云计算方法,设计了基于Hadoop的海量电信数据云计算平台,并对平台的部分功能进行了实现。实验表明,本文提出的方法是有效和可行的,为进一步研究Hadoop在海量电信数据分析方面的应用做出了指引,在下一步的研究中,重点讨论MapReduce编程模型改进和数据节点的扩展问题,以进一步提高海量数据的运算效率。
1 Wbite T.Hadoop:the Definitive Guide.O’Reillly Media,Inc.,2009
2 张建勋,古志民,郑超.云计算研究进展综述.计算机应用研究,2010,27(2):429~433
3 施岩.云计算研究及Hadoop应用程序的开发与测试.北京邮电大学硕士学位论文,2011
4 Hadoop官方网站.http://hadoop.apache.org,2012
5 刘鹏,黄宜华,陈卫卫.实战Hadoop——开启通向云计算的捷径.北京:电子工业出版社,2011
