KAD网络负载均衡技术研究*
2012-02-19史建焘张宏莉
史建焘,张宏莉
(哈尔滨工业大学计算机网络与信息安全技术研究中心 哈尔滨150001)
1 引言
分布式散列表(distributed Hash tables,DHT)技术的出现扩展了对等网络用户的规模,彻底释放了用户的共享下载需求。相比之前的P2P网络,DHT网络具有可扩展性好、可靠性高等优点,但是网络节点的异构性也给这一技术的发展提出了许多挑战。作为为数不多的在实际环境下实现的DHT系统,利用Kademlia协议[1]的eMule软件的KAD网络已经拥有了数以百万的用户群,在Internet上产生了一定的影响。KAD协议是基于二进制异或运算(XOR)度量距离的DHT协议,每个KAD节点拥有一个128位的唯一标识,所有节点构成一个二叉树结构。通过若干操作实现对数据项映射
负载均衡作为DHT系统重要的性能评价指标已经成为了当前研究的热点,大多数研究工作都是以ID空间作为研究对象的[2]。认为理想状态下,DHT系统的负载均衡是指每个节点负责管理的ID空间应该根据其软硬件承载能力按比例分配。解决这类负载均衡问题的办法多是采用虚拟服务器的方式,该方法最初由参考文献[3]提出,考虑了节点软硬件能力的差异以及网络结构的异构性,将一个物理节点虚拟为在ID空间内独立的几个逻辑节点,并使系统中负责某一ID空间存储任务的节点数大致相当。但该方法增加了网络的波动性,导致网络维护代价增大。参考文献[4]对虚拟服务器方法进行了改进,大幅度提高了该方法的性能。参考文献[5]研究了具有超级节点的层次化DHT系统下的负载均衡问题。以上研究都是以负载在整个ID空间上的均匀分布作为假设的,而本文的研究以参考文献[6]的研究为基础,认为实际KAD系统中文件索引信息在ID空间上的分布是不均匀的,参考文献[6]提出的解决方法是通过存储和搜索过程中过滤无用关键词来防止某一ID子空间负载过重。但是,实际应用中很难提供完备的无用关键词集合,单独依靠这种方法很难完全解决文件索引的负载均衡问题。本文从KAD协议本身出发,在文件索引发布和搜索阶段对节点区域的负载进行控制,引入多重目标ID的方法分散热点关键词的负载,使系统在全局范围内达到负载均衡,从而保证KAD系统的健壮性和可用性。
2 负载分布测量
2.1 KAD资源发布机制
KAD的资源发布过程分为文件索引信息发布和源节点发布两部分。本文的研究内容仅涉及第一个发布过程:文件索引信息的发布,本节仅对这一过程做简单介绍。文件索引信息的发布涉及3个基本操作。
(1)候选节点收集(lookup)
对于给定的目标键值 (目标ID),lookup操作通过邻居节点之间的并发迭代查找,提供ID空间中可能负责目标ID的一些候选节点。其中初始节点并发查找分支数为α,后继节点并发查找分支数为β。除了初始节点采用α=3路并发查找外,后继节点会根据不同的操作目的选择并发迭代分支数。如果后续操作是发布(publish)操作,采用β=4路并发查找;后续操作是搜索(search)操作,则采用β=2路并发查找。当查找收敛到发现不了新节点时,Lookup操作停止,去掉和目标ID的公共前缀小于8的节点后,返回一个候选节点列表(candidate list)。
(2)发布
在最新的eMule实现中,选择距离目标ID最近的10个节点,通过Kademlia2_publish_key_req消息将
(3)搜索
选择距离目标ID最近的候选节点,通过Kademlia2_search_key_req消息,请求候选节点提供有关目标关键词的文件索引。候选节点收到该消息后,随机返回最多300个符合条件的索引项,并通过Kademlia2_publish_res消息返回。初始节点在收集满300个结果或者搜索超时后,立即停止搜索操作。
2.2 测量系统的设计
为了获取文件索引负载的分布情况,需要对KAD网络进行测量分析。出于不同的目的,本文的测量系统采用主动测量和被动测量两种方法。图1是整个测量系统的示意。

(1)主动测量
主动测量方法包括KAD爬虫和基于主动测量的虚拟客户端。其中KAD爬虫负责搜索网络中一定ID空间范围内的活动节点,是通过构造针对一系列特殊目标ID的lookup操作,获取目标节点部分或全部路由表的方法实现的,具体实现过程类似参考文献[7]。虚拟客户端负责并发Kademlia2_publish_key_req请求,收集活动节点Kademlia2_publish_res消息中的load负载标识以及测量lookup操作得到的候选节点与目标ID的距离分布。
(2)被动测量
被动测量通过设计虚拟客户段,将其节点ID设置为与目标ID非常接近的值,然后插入KAD网络,接收来自其他节点的索引发布和关键词搜索请求,统计和分析流量的分布情况和自身负载变化规律。
2.3 测量结果
(1)负载分布
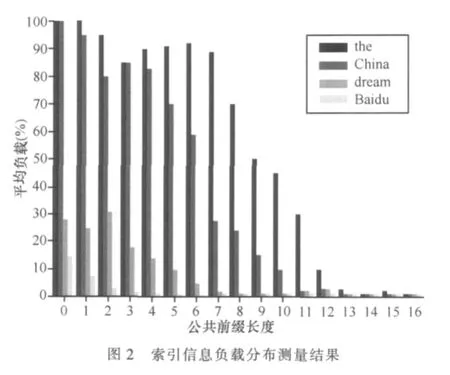
KAD系统中负责某一关键词的节点在ID空间上是相邻的,本文以ID值的8位公共前缀来标记对应的ID子区间。通过测量实验统计了负责关键词the(0xe3)、China(0xe6)、dream(0xca)、Baidu(0xe4)的4个ID子区间内的节点负载状况。具体过程是通过爬虫获得ID子空间内的所有节点,由索引发布模块向所有节点发送Kademlia2_publish_key_req消息,收集节点回馈消息中携带的load负载标识。实验发现最近节点一般与关键词ID有23~24个相同公共前缀,从最近节点开始,以公共前缀数排序统计了节点的平均负载情况。结果如图2所示,关键词the和China所在子区间节点负载最重,距离较远的节点也有较大负载,这是因为这两个关键词属于高频关键词。关键词Baidu所在区间的节点负载较轻,只有距离关键词ID最近的一些节点有一些负载,较远节点几乎没有负载。由此可见,以关键词为键值的文件索引信息在KAD网络的不同子区间的分布是不均匀的,存在一些超负荷区域。
(2)流量统计
为了发现负载强度对网络中节点性能的影响,通过被动测量实验统计了不同子区间内,节点在单位时间接收到的消息数。测量节点ID分别被设置为与关键词the、dream和盗梦空间的ID,即成为网络中距离目标关键词最近的节点。表1的结果是当节点路由表达到稳定状态后的1 h内收到的消息数。可见,负责关键词the的节点接收到的消息数最多,其中发布消息将近是查询消息的10倍,而其他两个关键词发布消息仅是查询消息的3~4倍。可以发现,大量的发布消息会集中在负责常用词的ID空间,位于这一区域的节点常常付出更多的通信开销。

表1 不同ID空间流量统计结果
(3)候选节点正确性
候选节点收集过程对KAD网络的索引发布和搜索非常重要,正确的候选节点可以提高搜索命中率。理论上如果节点在ID空间上的分布是均匀的,一个具有大约400万(≈222)个节点的网络,相邻节点的距离约为2128-22,也就是说相邻节点ID公共前缀的长度约为22位。笔者通过爬虫获得了网络中距离某一关键词ID最近的10个节点,与真正客户端候选节点收集过程得到的结果进行了对比。结果见表2,主动测量实验的结果与理论分析值很接近;而实际客户端由于搜索并发数的限制,除了前几个节点,并没有得到所有最近的10个节点,也就是说实际客户端得到的后几个候选节点动态性较大。对于高频关键词,由于索引信息量很大,大量距离较远的节点也会分配到一些索引信息,这就大大降低了其他节点的搜索命中率。为了改进KAD网络这种索引信息分配不均衡问题,提高搜索过程中索引信息的命中率,本文对索引信息的发布和搜索过程做了一定的改进。

表2 候选节点正确性测量结果
3 改进的索引信息发布策略
3.1 发布过程
改进的资源发布过程如算法1所示。先通过lookup过程选择离关键词ID最近的10个节点加入候选队列。与传统的发布过程不同,改进算法从队列的第10个节点开始前向分3轮选择发布节点。统计前两轮节点返回的负载值,如果大于系统预设的该节点最大负载阈值,则在轮次内累加负载值。如果该累加值超过最大误差值D=5%,则表明负责该关键词的节点区间负载过重。改进算法在下一轮将通过lookup过程选择新的节点区间发布该关键词信息,ID偏移量L=2120,即散列值的8位二进制公共前缀加1。最多会有以hash、hash+L、hash+2L为中心的3个ID空间负责负载量较大的关键词,通过更多的节点分担了负载。在最大负载MaxLoad的参数选择上,对于负责原散列hash的第10到第7个节点,MaxLoad=45%;第6到第4个节点,MaxLoad=65%;负责散列hash+L的第6到第4个节点,MaxLoad=35%。
算法1:m-Publish(hash)
{C0,C1,…,C9}←Lookup(hash);
ContactSet←{C9,C8,C7,C6};
for round←0 to 2 do
SumLoad=0;
for p∈ContactSet do
p.load←publish(p);
if round<2 then
SumLoad+=Max(p.load-p.MaxLoad,0);
if SumLoad>D then
{C0,C1,…,C9}←Lookup(hash+L));
if round=0 then
ContactSet←{C3,C4,C5};
if round=1 then
ContactSet←{C0,C1,C2};
3.2 搜索过程
改进的索引搜索过程如算法2所示。同样通过lookup过程选择10个节点加入候选队列,第一轮先从后4个节点中随机选择一个节点发出搜索请求,如果该节点返回的索引信息超过预设的阈值rMax,则再通过lookup过程选择hash+L空间内的节点加入候选队列,并且将rMax值增加150;否则,继续向前选择节点。第二轮选择新队列的后3个节点随机发送请求,过程与第一轮类似。这样最多会把hash、hash+L、hash+2L的3个ID空间内的一定节点加入候选队列。从第3轮开始同传统算法相同,选择最近的候选节点进行搜索,这样保证了算法的搜索效率。对负载较大的关键词,会更多地从较远节点获得索引信息,从而保证了更多的返回值。在MaxRefer参数选择上,对负责原散列hash的第10到第7个节点,MaxRefer=150;第6到第4个节点,MaxRefer=200;负责散列hash+L的第6到 第4个节点,MaxRefer=100,第3到第1个节点,MaxRefer=150。
算法2:m-Search(hash)
{C0,C1,…,C9}←Lookup(hash);
Candidates←{C0,C1,…,C9};
ContactSet←{C9,C8,C7,C6};
round←0;rMax←300;
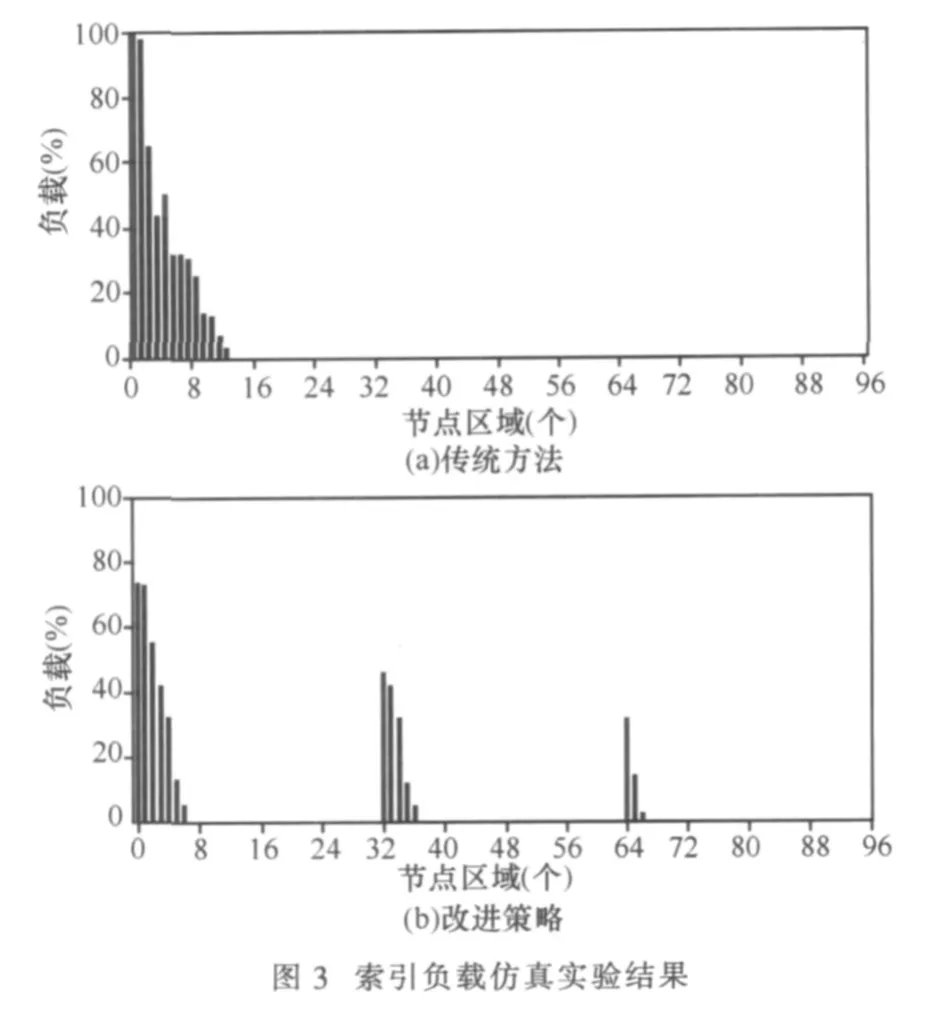
while references.size() if round<2 then p←ContactSet.getRandom(); R←search(p);references.add(R); if R.size()>p.MaxRefer then {C0,C1,…,C9}←Lookup(hash+L); rMax+=150; if round=0 then Candidates.add({C0,C1,…,C5}); ContactSet←{C0,C1,…,C5}; if round=1 then Candidates.add{C0,C1,C2}; ContactSet←{C0,C1,C2}; else p←Candidates.getFirst(); .add(search(p)); Candidates.remove(p); retrun references; 本节通过仿真实验验证前面所提出的方法,仿真程序以一个离散事件模拟引擎为基础,实现了基本的eMule的KAD协议。为提高仿真效率,节点空间的规模为3个连续的具有8位公共ID前缀的子空间。节点数目按照真实环境的比例分配,假设网络已经达到稳定状态,每个子空间保证有15 000个在线节点,节点上下线频率以采集到的真实环境下的数据为基础。仿真实验以一个给定的关键词生成文件索引。和真实协议一样,发布成功后每个索引在存储节点上保留24 h的模拟时钟时间。通过一个模拟客户端以每秒20个索引的频率在KAD网络发布文件索引。索引量基本饱和后,通过搜索过程提取当前系统中的文件索引,客户端分别采用传统算法和改进算法进行发布和搜索操作。 笔者根据节点ID值对每个子空间内的节点进行了分组,组间ID距离相等,每组大概有8个真实节点,由于大量文件索引发布在距目标ID较近的节点中,每个子空间只抽取了最近的32个分组并记录下节点的平均负载。实验结果如图3所示,当客户端采用传统方法时,大量节点出现了过饱和现象,其中距离目标ID最近的2个分组中,所有节点的负载率达到了100%,大量文件索引发布在距目标ID较远的节点上。而采用了改进的索引发布算法后,目标子空间的文件负载大大降低,基本达到了算法所控制的阈值,并且相邻子空间的部分节点也分担了大量的负载。模拟实验还记录了当索引发布达到饱和后,单位时间内能搜索到的最新文件的数量。由于大量候选节点达到了饱和状态,很多文件索引在传统协议下无法被成功发布和提取,实验获得的最新文件的提取率仅为18.7%;而采用改进方法后,文件的提取率可以达到89.3%。由此可见,改进的索引发布和搜索算法,能够大幅提高KAD网络的健壮性和文件发布效率。 基于DHT结构的P2P网络的发展给当今的互联网注入了活力,为用户提供了更多的便利和实惠。但是,由于应用环境的特殊性和网络节点的异构性,大多数DHT网络都存在着各种负载不均衡问题,需要进一步的优化和改进。本文通过测量实验发现了拥有大量用户群的eMule的KAD网络下,索引资源在ID空间上的分布是不均匀的,网络中存在的一些负载过重节点会威胁到用户对系统的正常使用。为了解决这一问题,本文提出了一种基于多重目标ID的索引发布和搜索机制,仿真实验表明该方法能够有效地提高索引负载分配的均衡性。 1 Maymounkov P,Mazieres D.Kademlia:a peer-to-peer information system based on the XOR metric.Proceedings of the International Workshop on Peer-to-Peer Systems,Cambrige,USA,2002:53~65 2 Godfrey P B,Stoica I.Heterogeneity and load balance in distributed Hash tables.Proceedings of IEEE INFOCOM,Miami,FL,USA,2005 3 Rao A,Lakshminaraynan K,Surana S,et al.Load balancing in structured P2P systems.Proceedings of the 2nd International Workshop Peer-to-Peer Systems,Berkeley,USA,2003:68~79 4 Hung-Chang Hsiao,Che-Wei Chang.A symmetric load balancing algorithm with performance guarantees for distributed hash tables.IEEE Transactions on Computers,2012(1) 5 张宇翔,张宏科.一种层次结构化P2P网络中的负载均衡方法.计算机学报,2010,33(9) 6 Steiner M,Effelsberg W,En-Najjary T,et al.Load reduction in the KAD peer-to-peer system.Proceedings of the Fifth International Workshop on Databases,Information Systems and Peer-to-Peer Computing,Austria,2007 7 Steiner M,En-Najjary T,Biersack E W.Long term study of peer behavior in the KAD DHT.IEEE/ACM Transactions on Networking,2009,17(5):1 371~1 3844 仿真实验
5 结束语
