一种改进的基于共现关系的短文本特征扩展算法研究
2012-02-09王细薇张凯
王细薇,张凯
(河南城建学院,河南平顶山467036)
随着信息技术的发展,网络新闻评论、微博、手机短信等字数在160个以内的短文本信息越来越多地影响着人们的生活,分类技术能够帮助人们快速的管理这些文本,但是,短文本特征词语由于长度短、所描述概念信号弱,单纯的基于词特征选择容易使文本表达主题分散,核心词易被赋予较低权重,而特征权重是分类的一个关键因素,直接影响了分类器的性能。
基于共现关系的特征扩展能较好地解决文本表达主题分散的问题。本文在以往研究的基础上[1-2],提出了一种改进的基于共现关系的短文本特征扩展算法。该算法考虑了多个共现词同时出现的情况,改进了特征词权重计算公式及特征扩展策略,并应用于中文短文本分类,改善了单一共现词描述能力不足的问题,提升了分类精度。
1 基于共现关系的短文本特征扩展算法原理
现行的特征集选择主要以选择词特征为主,但是由于词语本身存在着对短语和上下文依赖等现象,将意义可能密切相关的词孤立提取,则会忽略词语的语言学特征和相互关系,因此导致这种特征提取存在较大的局限性[1-6]。
关联规则是从海量数据中挖掘出描述数据项之间相互联系的有价值的知识[4]。本文将关联规则用于短文本特征扩展,并考虑共现关系对特征权重的影响。本文认为,强关联规则的前项一旦在文本中出现,后项必以一定概率出现,具体到短文本分类中,对于特征词先根据特征共现集进行共现词的扩展,由于该共现词本身就在训练文本中,因此只需根据共现关系调整该词的权重即可。
1.1 现有的短文本特征扩展算法的不足
Shen-Zheng Zuo等[3]通过从训练语料中抽取关键词语对中文短文本进行了研究,尽管其实验效果有所改善,但总体效果仍然不理想。王细薇等[2]在选取文本特征时,考虑了词语间的共现关系,建立了短文本分类模型,用关联规则挖掘算法创建了特征共现集用于短文本特征扩展,但还存在以下不足:其一是特征词权重只考虑了共现词唯一的情况,当不唯一时,权重赋予不理想;其二,由于没有考虑多个共现词的情况,导致特征扩展算法运行时会出现花费大量时间和空间计算不唯一的情况,其消耗是指数级增长的,直接导致分类效果不理想。基于上述情况,本文提出了改进的基于共现关系的短文本特征扩展算法。
1.2 基于共现关系的特征权重提升计算公式
本文用关联规则挖掘算法创建了特征共现集[2]Ik,以第k类为例(1≤k≤12)。
定义1共现词对:S、C大于设定的阈值的关联规则中的前后项构成共现词对。
对于某一共现词对ti→tj中后项特征权重提升计算公式为:

式中:Wti为特征ti的权重;Wtj为特征tj的权重;S为共现词对ti→tj的支持度;C为其置信度。
2 改进算法方案
特征共现集Ik中某一特征词的共现词可能唯一,也可能不唯一,大于置信度、支持度阈值的共现词对是允许存在的,这样可以丰富特征共现集,对短文本特征扩展有利。
2.1 改进的基于共现关系的特征权重提升计算公式
当特征词的共现词不唯一时,分别计算M=S×C×(共现词的词频),并对M进行排序后取前二,对于某一特征词ti,假设排在前二的共现词分别为tx、ty,那么ti的特征权重计算公式为:
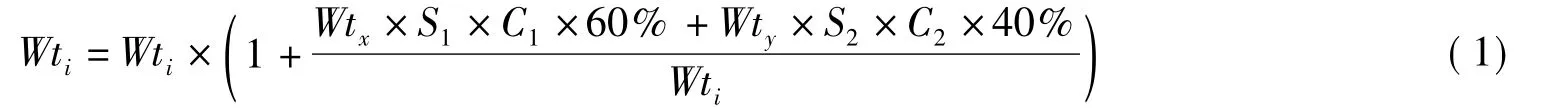
式中:Wti、Wtx、Wty分别为ti、tx、ty的权重;S1为共现词对tx→ti的支持度;C1为其置信度;S2为共现词对ty→ti的支持度;C2为其置信度。当共现词唯一时,ty不存在,Wty为0。经过大量的试验论证,发现共现词tx对特征词ti的影响要大些,取60%修正是比较合理的。
2.2 改进的特征扩展算法
以第k类为例(1≤k≤12)。
输入:特征共现集Ik,关联规则抽取阈值分别为最小置信度阈值C、最小支持度阈值S,训练文本词频统计文件star.txt;
输出:训练文本词频统计结果star_.txt。
步骤1对于star.txt文档中任一个特征词ti,查询特征共现集Ik,如果存在唯一一个共现词对,并且当C大于设定的阈值时,Wty=0,执行步骤2。如果共现词对不唯一,则计算M=S×C×(共现词的词频),并按照M排序后取前二共现词对ti进行概念扩展,执行步骤2。如果不存在共现词对则执行步骤3。
步骤2根据特征权重提升计算式(1)修改ti的权值。
步骤3对特征词ti不进行概念扩展。
3 实验结果及分析
3.1 实验数据
本文使用的数据集是12个不同领域的共470 252篇网友评论。将每类文本集随机地平均分为四份,一份为测试集,另外三份为训练集。实验系统是在WindowsXP系统下,使用Borland C++Builder 6.0作为开发工具。
分类性能用两种评估指标:宏平均F1值(Macro-F1)和微平均F1值(Micro-F1)。
3.2 实验方法设置
(1)常规方法:选用了清华大学开发的CsegTag3.0对中文进行分词,并去除停用词,然后用词频(Term Frequency)进行特征抽取,采用CHI选择特征方法,以朴素贝叶斯(Naïve)为分类器,未经过特征扩展,分别选取特征数为1 000、2 000、3 000、…、10 000,进行10轮12类短文本分类实验。
(2)基于共现关系的短文本特征扩展算法:在方法(1)的基础上训练集特征经过概念扩展(特征共现集[2]),分别选取特征数为1 000、2 000、3 000、…、10 000,进行10轮12类短文本分类实验。其中,FP-Growth的支持度和置信度阈值分别设为0.3%、2%。
(3)改进的基于共现关系的短文本特征扩展算法方法:在方法(2)的基础上分别选取特征数为1 000、2 000、3 000、…、10 000,进行10轮12类短文本分类实验。
3.3 实验结果及分析
特征数目不同时三种方法的分类性能比较。结果如图1、图2所示。图1、图2的实验结果表明:总体上,方法(2)比常规方法分类性能有所提高,前者比后者宏平均F1值提高1~2个百分点,微平均F1值提高1~3个百分点,方法(2)提高了特征词对应的共现词的权重并形成概念特征词,有效地选择出了高性能的特征,提高了分类器性能,在一定程度上解决了短文本有效特征不足所造成的分类器分类性能下降的问题,但是效果不够理想。方法(3)又在方法(2)的基础上进一步改进了特征扩展算法,分类性能明显优于前两种方法,提高了分类精度。
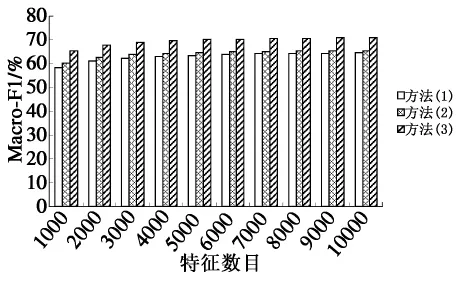
图1 特征数目不同时三种方法的宏平均Macro-F1比较

图2 特征数目不同时三种方法的微平均Micro-F1比较
4 小结
本文提出了一种改进的基于共现关系的短文本特征扩展算法。该算法考虑了多个共现词同时出现的情况,改进了特征词权重计算公式及特征扩展策略,应用于中文短文本分类时,使短文本的信息量得到补充,同时也使短文本分类效果得到提升。
[1]王细薇,沈云琴.中文短文本分类方法研究[J].现代计算机,2010(7):28-31.
[2]王细薇,樊兴华,赵军.一种基于特征扩展的中文短文本分类方法[J].计算机应用,2009,29(3):843-845.
[3]Zuo Shen-zheng,Wu Chun-hua,Zhou Yan-quan,He Hua-can.Chinese Short-Text Categorization Based on the Key Classification Dictionary Words[J].The Journal of China Universities of Posts and Telecommunicationa,2006(13):47-49.
[4]张会容.关联规则挖掘的研究与及其应用[D].广州:华南理工大学,2004.
[5]王丹,樊兴华.面向短文本的命名实体识别[J].计算机应用,2009,29(1):143-145.
[6]蔡月红,朱倩,孙萍,等.基于属性选择的半监督短文本分类算法[J].计算机应用,2010,30(4):1015-1018.
