用MapReduce框架构建虚拟天文台数据节点*
2012-01-25韩冀中崔辰州
宋 烜,周 薇,韩冀中,崔辰州
(1.北京天文馆,北京 100044;2.中国科学院计算技术研究所,北京 100190;3.中国科学院国家天文台,北京 100012)
1 背景
1.1 虚拟天文台
天文学正进入一个多波段数字巡天的时代,从射电波段到微波、红外、可见光、紫外、X射线,整个波段都会被覆盖。这些巡天项目产生的数据量通常可以达到TB甚至PB,这些数据也成为天文数据的主要来源[1-2]。一方面,天文数据量非常庞大,简单估算可知,以0.5″的分辨率,巡天由2×1012像素构成,仅单一波段的巡天就产生4 TB数据。另一方面,天文数据增长迅速,以斯隆数字巡天SDSS为例,它用了10年时间覆盖8000平方度的天空,得到了大约108个星或者星系的近40 TB的数据。而未来2个巡天计划PanSTARRS和LSST,只需3晚上就可覆盖半个天空,每晚产生的包含5.7×108个源的数据都会超过40 TB[3]。因为天文学家需要从巡天数据中寻找变化,巡天需要不停地进行,会产生数十到百亿个目标的星表,从而形成巨大的数据量。一些大的巡天计划和他们的数据量列表见表1。
为了天文学家和公众可以使用、查询世界上所有望远镜的数据,虚拟天文台的建设提上了日程[4]。虚拟天文台的建设目标就是给全世界天文学家、教师、天文爱好者以及公众提供一个平台,使他们在世界上任何时间任何地点可以协同使用全世界天文数据与计算资源。已经有19个国家和地区开发了符合国际标准[5]的可以相互协作的虚拟天文台系统。
虚拟天文台一经诞生就面临着庞大天文数据存储与计算问题。随着数据量的增长,本地星表交叉认证、聚类等多种数据敏感型的需求在增加。现有的虚拟天文台数据节点使用传统的数据库系统(DBMS)或者并行数据库系统(PDBMS)。并行数据库系统的研究始于20世纪80年代,大多数现有的PDBMS设计都类似于Gamma[6]和Grace PDBMS。在过去的几十年,各研究机构实现了许多提升性能的技术,包括索引、压缩、物理化视图、结果高速缓存和I/O共享。但是因为并行数据库设计之初即做出假设:大规模集群中的节点极少失效,即使规模大至几十个(而不是成百上千)[7]。基于此做出的工程实现,使得并行数据库在容错能力和异构环境的操作能力有限。现有数据库并行效率低,其局限在于:

表1 一些大巡天计划的数据量Table 1 Data sizes of some surveys
(1)容错。并行数据库在几十个节点时性能良好,当节点数上升至100个以上时,就会出现性能瓶颈[7],因为节点数增加后,节点失效就会更加频繁地发生,因此,不能像并行数据库当初的设计原则那样,认为节点失效是小概率事件。
(2)可扩展性。并行数据库要求节点都是同构的,当节点规模变大时,很难保证纯同构情况,且这种模式扩展性也不好。
(3)半结构化数据处理能力。天文研究需要的数据主要包括星表、星图、光谱。除了星表是完全结构化的二维表以外,其他数据都是非结构化或者半结构化的数据,传统数据库系统在这个领域性能较低。
(4)成本因素。并行数据库系统一般要求使用高端服务器和商用软件。在需要大规模部署的时候,成本也是不得不考虑的因素。
综合以上可以看出,使用数据库系统,面对海量数据,虚拟天文台数据节点面临很大的压力。
1.2 MapReduce
MapReduce[8]是一个非常适合分布式计算的编程模型和计算平台。在MapReduce模型下,程序由用户自定义map和reduce两部分组成。MapReduce通过3个基本操作,在shared-nothing结构的集群上,处理大规模分布式数据集。但是MapReduce的非结构化数据存储也使得数据没有适当的预处理和加工,因而数据库系统中许多提升性能的工具无法发挥作用,如索引。即便如此,已经有非常多的应用在MapReduce模型下进行处理,这其中包括日志分析、机器学习以及其他许多应用。
Hadoop[9]是一个基于谷歌(Google)技术的开源版本。它包括一个分布式文件系统HDFS和MapReduce计算模型。基于MapReduce框架,程序员不需要太多的并行处理或者分布式计算的经验,就可以轻松地操纵大规模的集群系统,无需考虑硬件细节,从而大大提高工作效率。分布式文件系统HDFS是一个高容错的系统,它可以提供高吞吐量的数据访问,非常适合在海量天文数据集上使用。另外由于Hadoop在设计之初就充分考虑使用大规模廉价集群,硬件故障被视为正常状态,所以Hadoop可以用低成本建立容错能力和可扩展能力非常高的集群。
1.3 星表交叉认证
交叉认证工作在天文学研究中起着关键作用。首先,联合了多个波段的数据可以获取天体或相关天文现象更全面的信息,加深对认证源的物理性质、演化规律的理解;其次,融合数据促进了新天体、现象、规律的发现[10]。所以,星表交叉认证是虚拟天文台在面对海量数据时不可避免要面对的一个问题。
交叉认证问题可以简单阐述为寻找球面上距离相近的点的问题。这个问题看似简单,但是由于数据量极为庞大,并且通常需要在2个甚至更多的星表之间进行匹配,导致问题变得复杂。
一般交叉认证算法包括3种:空间索引、像素编号算法(Pixel-code Algorithm)、平面扫描算法。
在目前MapReduce框架的实现中,其输入集合都是以原始的数据格式存放,因此采用平面扫描算法可以更好地适应此结构,即无需建立索引,而直接采用排序实现。利用支持MapReduce框架的开源系统Hadoop,可以达到非常好的排序性能[11]。
在数据库系统中,索引的建立会耗费较长的时间,有时会远大于数据库操作的执行时间。但是,因为索引可以一次建立多次利用,当数据被重复使用时,索引的建立是值得的。不过,大规模天文星表之间交叉认证的工作一般只需要匹配一次就可以作为结果使用,所以分布式并行数据库集群在索引上的优势在这项任务中没有起到太大作用。
本文针对传统并行数据库处理大规模数据的一些缺陷,提出了使用MapReduce框架构建虚拟天文台数据节点。既发挥中国虚拟天文台原有架构在功能方面的优势,又使其对海量天文数据处理的能力得到极大加强。最后,本文将MapReduce框架应用于本地海量星表交叉认证这一具体天文应用上,实验结果表明,此方案是非常有效的。
2 用MapReduce构建虚拟天文台数据节点
2.1 系统结构
由于使用标准SQL接口,本文构建的虚拟天文台数据节点符合中国虚拟天文台的各项标准,从而可以提供标准接口,供更上层的虚拟天文台服务器调度、查询。
系统具体结构如图1。天文数据节点有5个模块,分别由SKYNODE模块、ADQL模块、HIVE模块、HADOOP模块和VOTABLE模块组成。其中SKYNODE模块是天文数据节点的核心,负责与其他模块之间的交互以及SkyNodeInterface接口的发布;ADQL模块负责将ADQL标准的输入转换成标准SQL输入;HIVE模块负责将SQL输入翻译成MapReduce任务;HADOOP模块负责处理HIVE模块翻译出的MapReduce任务,得到用户需要的结果;VOTABLE模块则是将系统输出转化成标准的VOData格式。
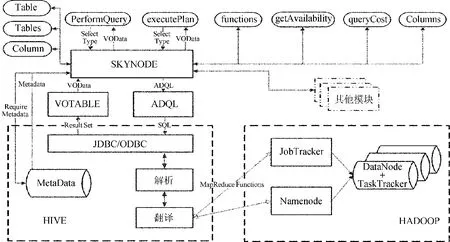
图1 天文数据节点系统结构图Fig.1 Architecture of data nodes of the Virtual Observatory
SKYNODE模块[12]:发布数据访问接口,一共实现了9种方法。它使用2种方法performQuery()和executePlan()实现查询,其中performaQuery()用来实现简单查询,而executePlan()用于处理复杂查询。其余的方法都是用来支持查询的辅助方法,比如元数据列、元数据表、节点状态等等。
ADQL模块[12]:它内部实现了ADQL的解析,并将解析后的对象通过翻译转换查询SQL语句送至HIVE模块。
HIVE模块:Hive是Hadoop项目下的一个子项目,它提供了JDBC/ODBC接口,使用者可以通过SQL执行MapReduce。有了Hive,Hadoop看上去就是一个数据库。HIVE模块的主要功能是将SQL输入翻译成MapReduce任务。其中包括子模块JDBC/ODBC驱动、解析器和翻译器。
HADOOP模块:处理MapReduce任务,由两部分组成:计算和存储。计算部分是由Hadoop模块的MapReduce框架完成的,MapReduce的JobTracker负责切割任务,然后将切割好的任务分发给TaskTracker执行。存储部分是由Hadoop的HDFS进行,其中NameNode切割数据,然后将其分发给多个Hadoop DataNode。
VOTABLE模块[12]:根据天文数据的统一数据标准,把来自不同数据集的数据以标准VOTable格式输出。它接收Results Set,将结果转换为VOTabl格式,以VOData对象输出。
基于MapReduce框架的虚拟天文台数据节点符合统一的数据访问接口,可以跟其他天文数据节点一起,给用户提供一个完整统一的、可以使用所有天文数据节点的平台。
2.2 运行流程
天文数据访问门户或客户端程序可以调用performQuery方法(简单查询)或者executePlan方法(复杂查询),将ADQL查询语句通过ADQL模块直接转换为SQL,然后通过HIVE处理,转化为MapReduce任务。HADOOP模块接受MapReduce任务,生成处理结果。具体处理步骤如下:
(1)HDFS的NameNode将输入文件(星表数据)按固定大小(16 M到128 M不等,用户可以自定义)分块,然后将分块后的数据分布在不同的Hadoop DataNode上;
(2)对于HIVE模块输出的MapReduce任务,MapReduce框架中的JobTracker将任务按Mapper数目分割;
(3)MapReduce框架遵循计算向数据迁移的原则,将Mapper优先安排在有数据的节点上,这样的处理过程可以尽量减少数据在节点之间传输;
(4)每个Mapper将计算出的中间结果保存在本地,等待Reducer来取中间数据,以便进一步处理;
(5)Reducer根据JobTracker的指示,去Mapper取中间结果,然后进行结果的归并,生成最终结果,保存在HDFS上;
(6)HDFS上的结果以结果集的方式输出到HIVE模块,然后输出到VOTABLE模块,保存为VOData对象,由executePlan接口输出。
在数据存储方面,由于HDFS有冗余备份机制,当其中一个节点失效后,可以在其他节点中找到数据备份,所以数据不会丢失。在计算方面,如果某一个mapper或者reducer失效,JobTracker会将失效mapper(reducer)上的任务分给其他mapper(reducer),因此它很好地解决了1.1节中的问题1。
MapReduce框架中,由于节点之间是可以互相通信的,不需要通过NameNode统一通信,所以,NameNode不会成为MapReduce的瓶颈,它具有良好的可扩展性,可以解决1.1节的问题2。
在天文领域,以半结构化或者无结构化数据居多,而MapReduce并行扫描的特点正好适合处理这种类型的数据,这就解决了1.1节中问题3提到的传统数据库对半结构化数据和无结构化数据的支持问题。
最初谷歌提出MapReduce框架的初衷就是利用大量的廉价机器搭建分布式系统,所以,它把机器的失效当成正常事件,不需要高价的服务器搭建系统。
至此已经很好地解决了1.1节中所描述的问题。下面以一个在虚拟天文台中非常重要的任务星表交叉认证测试新数据节点。
3 应用
星表交叉认证对虚拟天文台来说是最关键的任务之一,以批量星表交叉认证进行性能测试。本节介绍在新的天文数据节点下,如何进行节点内批量天文星表交叉认证。
在处理天文星表交叉认证问题时,要面对的不仅是一个点与点距离的问题。由于存在测量误差,每一个星周围都存在一个误差范围。这使得要处理的是搜索空间重叠的问题,如果有重叠发生,就再使用星等接近等其他规则进行处理,视为两颗星匹配。
交叉认证工作主要分为两个步骤:过滤和优选。过滤是筛选出落在最大误差矩形内的目标最小边界矩形(Minimum Bounding Rectanghes,MBR),这个矩形即为最小边界矩形。优选则是在最小边界矩形中通过其他规则逐个筛选符合要求的目标。一般找到最小边界矩形后的目标较少,所以问题集中在寻找最小边界矩形中备选目标的工作。
如图2,图中星星周围的圆型代表误差范围。MapReduce各个阶段的解释如下:
(1)输入:星表数据,包括赤经、赤纬、星名、误差等属性。两种颜色的星星可以表示两个星表中的目标。
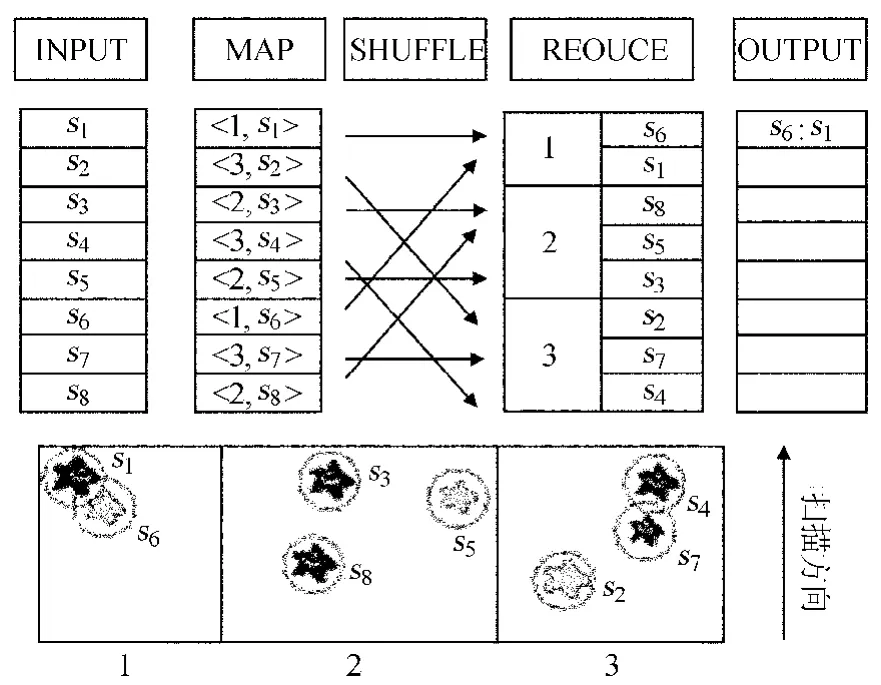
图2 MapReduce处理过程Fig.2 Data flow of astronomical cross-identification
(2)Map:按照数据流,在Map阶段之前的最开始阶段,两个要互相匹配的星表处于两个不同的文件中。根据输入的星的纵坐标,计算出每颗星所属的分区(图2中的1、2、3),把分区号作为中间key,星数据作为中间value,输出给Reduce。借助于MapReduce框架的功能,相同分区号的目标被分配到相同的Reduce中处理,然后在每一个Reduce中使用星的坐标位置进行平面扫描算法下的匹配查询。除了Reduce阶段的分布并行扫描,在为每颗星寻找它所属分条的Map阶段,可以并行同时给每颗星寻找分条,这正是Map阶段处理的特长,Map阶段要求计算的独立性,各个目标的计算互不影响。另外,还需注意对边界进行特殊处理。在实现过程中,让边界误差范围内的点同时被划分到2个分条内,可以很好地解决这一问题。
至此,每颗星都找到了所属的分条。处于相同分条的目标都在同一个Reduce中处理。目标是测试点还是目标点可以通过value中设置一个属性区分。每个Reduce会把Map送来的数据先进行排序。
(3)Reduce:Reduce阶段分为混合(shuffle)和Reduce两部分。混合是指把从不同Map送来的key/value进行排序,并把相同key的值聚合然后交给Reduce处理。Reduce即平面扫描过程。
传统的单机扫描算法需要把每个目标点与整个活动区域进行比较,活动区域的长度越长,同等宽度的面积就越大,包括的测试点就越多,所以活动区域的长度决定了传统平面扫描算法的效率。优化这种算法可以通过分条扫描,减少活动区域的边长,这样就降低了活动区域的面积,直接减少了需要匹配的测试点的数量,降低了运算量。除此之外,分条以后的各分条扫描可以通过Hadoop框架分布到集群中的机器并行扫描运算,可以明显地提高效率。
除了依靠Hadoop框架实现的混合排序工作,Reduce基本上和典型的平面扫描过程没有区别。主要分成两个阶段,过滤和优选。
过滤:在Reduce阶段中进行的过滤工作需要每一个目标的赤经、赤纬坐标,所以赤经、赤纬、星名和误差等作为中间key/value中的value。在过滤阶段的开始,按赤纬排序的数据顺序读入从Map送过来的中间值,每个Reduce只处理属于自己分条范围内的目标。这个阶段的主要任务是找到在所有测试点的最小边界矩形范围内的所有目标点,即如图3中心测试点和正方形覆盖的所有目标点的一对多关系。在每一个分条内,通过全部在内存中实现的平面扫描算法可以非常高效地找出最小边界矩形。如图3,t1是目标点,要寻找t1为圆心、d为直径的圆形范围内所有测试点。
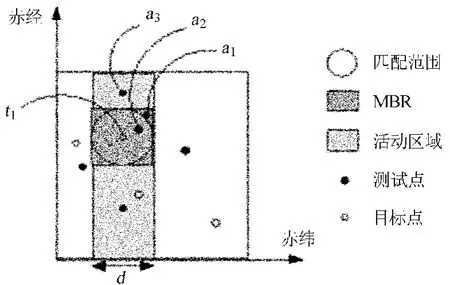
图3 过滤和优选Fig.3 Illustration of filtering and refinement for object cross-identification
优选:过滤以后的结果已经可以认为是匹配的了,只是条件还不够充分。这个结果的形式可以表示为<目标点,[测试点]>。可以在优选阶段对过滤阶段后结果再进行逐个精确筛选,看是否符合需求。
(4)输出:平面扫描后,可以获得和目标点匹配的测试点的列表。可以看到,本例的结果是s1/s6匹配。然后把结果转化为VOTalbe形式供虚拟天文台上层服务器调度处理。
4 性能评估
这一节比较了基于MapReduce框架下天文数据节点和基于传统数据库PostgreSQL之间的性能差异。MapReduce集群可以非常方便地部署到成千上万台廉价节点,而传统数据库集群只能达到几十台的规模[7]。本测试使用少量廉价MapReduce集群与单台数据库进行性能比较,目的在于测试增加少量MapReduce节点时的性能提升情况。
4.1 测试环境
测试数据来自2MASS[13](2μm巡天)和GLIMPSE[14](红外银道面特殊巡天)中的星表数据的一部分。数据规模:2MASS:15 433 500行,GLIMPSE:1 344 450行。测试集群配置为Dell PowerEdge,2.8 G,平均1.5 G内存。PostgreSQL测试机配置为:P4/3.2 G(HT)/1 G内存。
4.2 测试结果
首先测试了不同节点数目效率对比。如图4,随着节点数目的增多,效率也随之提高。但加速比也随着节点增多而减小,这主要是因为测试中所选数据集规模较小造成的。
在天文星表交叉认证工作中经常使用一种DBMS:PostgreSQL[15],使用它和MapReduce进行性能对比。
使用DMBS进行交叉匹配需要使用空间索引,而建立索引需要很长时间。在相同数据量的情况下,PostgreSQL建立空间索引需要30 min,匹配过程需要15 min(900 s)。性能对比如图5。
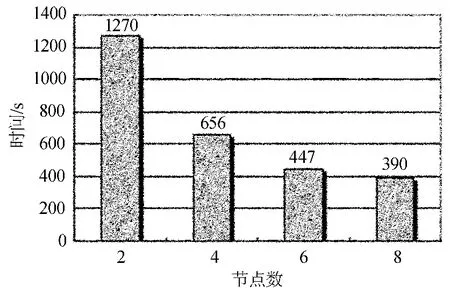
图4 节点数效率对比Fig.4 Comparison of efficiencies(measured in matching time)of different numbers of nodes
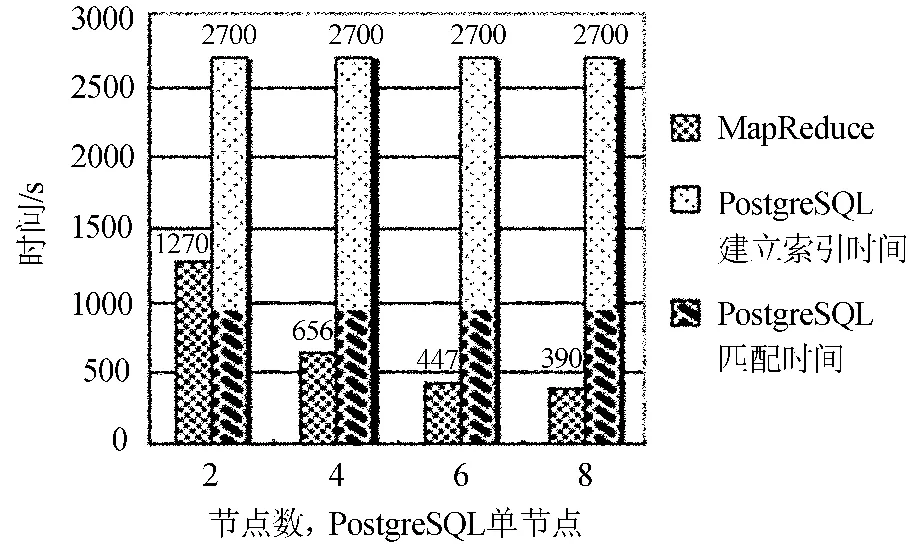
图5 MapReduce与PostgreSQL性能对比Fig.5 Performance comparison between the MapReduce and PostgreSQL
从上面结果可以看出在节点少于4个的时候,MapReduce需要的时间大于PostgreSQL匹配时间。这说明MapReduce在增加少量节点的情况下就可以获得比较大的性能提升。而节点数大于6个以后所获得的性能提升没有第4~5个节点显著。但仍可以设想如果在更大数据量情况下,越多节点应该会获得更好的效率。
天文星表数据一般只需要匹配一次就可以作为结果一直使用,所以可以认为数据库建立索引时间与星表匹配计算时间和需要与MapReduce进行比较,可以看到MapReduce有非常大的优势。但是在非大规模两个星表匹配查询中,如单个点的匹配查询,建立了索引的DBMS性能较好。
5 结论
本文首次提出将MapReduce框架应用于中国虚拟天文台数据节点,并在新框架下实现了本地星表交叉认证并测试了性能。借助于HDFS分布式存储,使用非结构化的键值对保存、处理数据,以及框架本身良好的设计,很好地解决了不仅是性能,而且扩展性、成本等多方面的问题,超越了原有设计。
[1]Djorgovski S G,Brunner R J.Astronomical Archives of the Future:a Virtual Observatory [J].Future Generation Computer Systems,1999,16(1):63-72.
[2]Cui Chenzhou,Zhao Yongheng.Worldwide R&D of Virtual Observatory [J].Proceedings of the International Astronomical Union,2007(3):563-564.
[3]Viewing the Heavens through the Cloud [EB/OL].[2010-10-22].http://ssg.astro.washington.edu/research.shtml?research/CluE1.
[4]赵永恒,崔辰州.中国虚拟天文台——任务、特点、方案 [EB/OL].[2010-10-22].http://www.china-vo.org/docs/cvo_draft.pdf.
[5]IOVA [EB/OL].http://www.ivoa.net/.
[6]D J DeWitt,R H Gerber,G Graefe,et al.Gamma—A High Performance Dataflow Database Machine [C]//Proceedings of the 12th International Conference on Very Large Data Bases.Very Large Data Bases'86.San Francisco:Morgan Kaufmann Publishers Incorpation,1986:228-237.
[7]Abouzeid A,Bbajda-Pawlikowski K,Aabadi D J,et al.Hadoopdb:an Architectural Hybrid of Mapreduce and dbMs Technologies for Analytical Workloads[C]//Proceedings of the2009 VLDB Endowment,2009,2(1):922-933.
[8]J Dean,S Ghemawat.MapReduce:Simplified Data Processing on Large Clusters [J].Communications of the ACM,2008,51(1):107-113.
[9]Hadoop [EB/OL].http://hadoop.apache.org/core/.
[10]高丹,张彦霞,赵永恒.中国虚拟天文台交叉证认工具的开发和应用 [J].天文学报,2008,49(3):348-358.Gao Dan,Zhang Yanxia,Zhao Yongheng.The Development and Application of the Cross-match Tool of China-VO [J].Acta Astronomica Sinica,2008,49(3):348-358.
[11]Owen O'malley.TeraByte Sort on Apache Hadoop [EB/OL].(2008-05) [2009-12-14].http://sortbenchmark.org/YahooHadoop.pdf.
[12]刘波,崔辰州,赵永恒.构建中国虚拟天文台的天文数据结点 [J].天文研究与技术——国家天文台台刊,2006,3(4):355-364.Liu Bo,Cui Chenzhou,Zhao Yongheng.Construction of the SkyNode System for Chinese Virtual Observatory [J].Astronomical Research & Technology——Publications of National Astronomical Observatories of China,2006,3(4):355-364.
[13]Cutri R M,Skrutskie M F,Van Dyk S,et al.2MASS All Sky Catalog of Point Sources.The IRSA2MASS All-Sky Point Source Catalog,NASA/IPAC Infrared Science Archive [EB/OL].(2003) [2009-12-14].http://irsa.ipac.caltech.edu/applications/Gator/.
[14]Churchwell E,Babler B L,Meade M R,et al.The Spitzer/Glimpse Surveys:A New View of the Milky Way [J].Publications of the Astronomical Society of the Pacific,2009,121:213-230.
[15]CGP.Report on Cross Matching Catalogues[EB/OL].(2009-09-29) [2009-12-14].http://wiki.astrogrid.org/pub/Astrogrid/DataFederationandDataMining/cross.htm.
