英语口语测试系统的研究与实现
2012-01-11王娜
王 娜
(福建师范大学 福清分校数学与计算机科学系,福建 福清 350300)
在英语教学中,口语课常常不被重视.一个很重要的原因是学生认为只要常听示范朗读或者多做题目就可以在笔试中拿到高分.很多人特别是大学生在学习了几年英语之后,甚至是一些大学英语四六级的高分考生却不能用流利的英语表达自己的想法,学习外语关键在于练习.在传统的课堂教学中,教师无法实现让每个学生起立朗读课文,纠正他们的发音错误,因为这样会耗费大量的时间;课余时间也无法进行一对一的辅导.而复读机虽然可以让学生多次听、反复跟读,但是学生只能是从主观上把自己的读音与标准发音进行比较,无法得到客观的打分结果.
近年来,计算机技术蓬勃发展,人们开始思考如何让机器“听懂”人的语言,语音识别技术应运而生了.现在的计算机辅助教学中,“听”的比重远大于“说”,也就是发音练习、纠错反馈、实时评分的训练并不多见.英语口语测试系统为英语学习者提供这样的条件,让他们通过多次发音训练,纠正错误发音,从而改善当前口语教学的状况.
1 隐马尔可夫模型(HMM)
英语口语测试系统的核心功能是对用户的发音状况作出评价.但如何选取适当的评分规则给用户的发音一个公正客观的评价是关键所在.隐马尔可夫模型(HMM)采用概率统计的方法形成识别模型,识别速度较快,识别率较高,动态时间序列建模能力强,识别效果良好.因此笔者选取了隐马尔可夫模型(HMM)为基础来训练声学模型.
1.1 隐马尔可夫模型(HMM)的定义
隐马尔可夫模型(HMM)是用单一离散随机变量描述过程状态的时序概率模型,该变量的可能值就是世界的可能状态,但观察者不能直接感知状态的变迁[1].
隐马尔可夫模型定义为一个五元组:
HMM=(S,Y,π,A,B)
模型的世界状态集S={S1,S2,…,SN},N是状态的总个数;输出符号集Y={Y1,Y2,…,YM},M是每个状态中的观测值总数;π是初始的状态出现概率分布向量;A={aij}是状态转移矩阵,aij表示从状态Si转移到状态Sj的概率;B是观测值概率分布,B={bj(k)},bj(k)表示在状态Sj时输出符号Yk的概率[2].
1.2 隐马尔可夫模型中的三个基本问题
欲使所建立的隐马尔可夫模型能解决实际问题,以下三个问题必须加以解决:
(1)给定一个观察序列O=O1,O2,…,OT和一个HMM参数组λ=(π,A,B),如何有效地计算在给定模型λ条件下产生观察序列的概率P(O/λ).
(2)给定一个观察序列O=O1,O2,…,OT和一个HMM参数组λ=(π,A,B),如何选择最佳的状态序列,使它产生的观察序列O的概率最大.
一致性检验(Conformity Test)模型是判断目标光谱与参考光谱一致性的常用手段。本文在建立雷公藤一致性检验模型时,采用的建模方法是:将待测光谱按约定化学计量学模型方法进行处理后,通过将待测光谱与参考光谱库平均光谱相比较,计算其最大一致性指数(max.conformity index,最大CI值),与模型设定的一致性指数限度(conformity index limit,CI值限度)进行比较,从而快速简单地判断待测样本木质部光谱与雷公藤木质部光谱是否具有一致性。其中最大一致性指数CI值计算公式为:
(3)如何根据观察序列不断修正模型参数λ,才能使P(O/λ)最大.
问题(1)实际上是一个评估问题,前人已研究出“前向-后向”算法;问题(2)是解码问题,其关键在于选用怎样最佳意义上的状态序列Q使P(O/λ)最大,目前最好的解决方案是Viterbi算法;问题(3)是学习问题,Baum-Welch算法解决了HMM训练问题即HMM参数估计问题,但该算法并不是唯一和最完善的方法[3,4].
2 系统的设计
2.1 系统功能需求

图1 系统的功能需求
系统主要功能是英语口语的学习与测试.这就需要系统管理员设置好学习模式或测试模式.系统的功能需求如图1所示.如果是在学习模式下,用户首先从一个可视化窗口进入系统,选择相应的题库,打开示范语音,进行跟读和练习,此时,语音提示与纠错功能可用.如果是在测试模式下,用户进入系统后,由系统随机抽取题目以确保考试的公平性,此时,语音提示与纠错功能被禁止.用户通过麦克风录制自己的音频,形成WAV格式的文件保存起来.系统内部要进行语音识别、分割、对比、评分等一系列的活动直到成绩发布到动态网页上.
2.2 角色分配
经过认真分析和研究,得出了系统的角色分配模型,如图2所示.系统共分为三个角色,分别是系统管理员、学生和教师.系统管理员能够管理用户信息(这里的用户包括系统管理员、学生和教师),对这些信息进行增加、删除、编辑、查询的操作;能够设置系统的模式,是教学还是考试模式;管理题库,每过一段时间更新一次题库,删除其中比较旧的题目.学生能够进行口语学习或者参加考试,学生交卷后,系统将评定学生的成绩,学生能够通过自己的用户名和密码查询自己的考试成绩.教师能查询学生的成绩,系统能够以班为单位汇总、输出成绩提供给教师参考.

图2 系统的角色分配模型
2.3 语音评分的工作流程

图3 语音评分的工作流程
首先,被测试者通过文本的提示进行发音,系统从MIC中采集到被测语音信号,随机自动转入端点检测,从而分离出有效信号.系统将有效信号和标准语音抽取Mel频率倒谱系数(MFCC),用Viterbi算法切割音素,进行对比,从发音、语速、语调、重音和停顿几个方面进行加权平均,得到最后的相似度得分.语音评分的工作流程如图3所示.
2.4 语音评分算法的原型接口设计
为了提高效益、降低成本并考虑到系统的扩展性,本系统在Windows平台上通过编写C/C#代码实现,部分算法采用了MATLAB.以下是部分C程序.
BOOL WINAPI AudioMarkInit(BOOL bInit)
{
}
HANDLE WINAPI AudioMarkCreate(const void *lpInit,UINT nSize)
{
//2、创建语音评分的对象/环境
}
BOOL WINAPI AudioMarkDestroy(HANDLE h)
{
//3、释放创建的语音评分对象
}
BOOL WINAPI AudioMarkSetEndPoint(HANDLE h,const Endpoint *lpEndPoint,int nCount)
{
//4、设置语音范围
}
long WINAPI AudioMarkCheck(HANDLE H,const short *pnData,int nDta,int nSampleRate)
{
//5、根据创建的对象,进行评分
}
3 系统的实现
3.1 登录界面
本系统的角色涉及到考生、教师、系统管理员,他们拥有不同的权限.英语口语测试系统的登录界面如图4所示.用户登录校园网,通过输入正确的用户名和密码并选择相应的身份即可进入系统.如果用户名或密码不正确,登录失败,系统会弹出“用户名或密码错误,请重新输入!”的对话框,然后返回登录界面.由于考生用户比较多,系统设置了个人信息核对.

图4 英语口语测试系统的界面
3.2 朗读测试界面
英语口语测试系统的朗读测试界面如图5所示,页面上显示了朗读测试题的内容,考生的个人信息,播放控制,语音信号的波形等.其中,播放控制从左到右的三个键分别代表播放、录制、暂停.被按下的键表示当前的工作状态,如录制按钮显示为红色表示当前系统处于录制状态.

图5 英语口语测试系统的朗读测试界面
4 实验结果
实验的语音采集是由16名学生(其中男性8名,女性8名)手持麦克风在普通机房进行录音完成的.每人读50个单词,每个单词读4遍,共采集到3200个测试语音样本.标准语音来源于《大学英语》精读课本的标准朗读语音.采用普通声卡,Windows自带的录音软件,采样频率为44.1KHZ,PCM方式,量化精度为8bits.本系统使用13维的MFCC进行特征提取.教师人工打分参考值来源于四名英语专业教师的打分的平均值.利用本系统评分与人工打分的对比情况如表1所示.
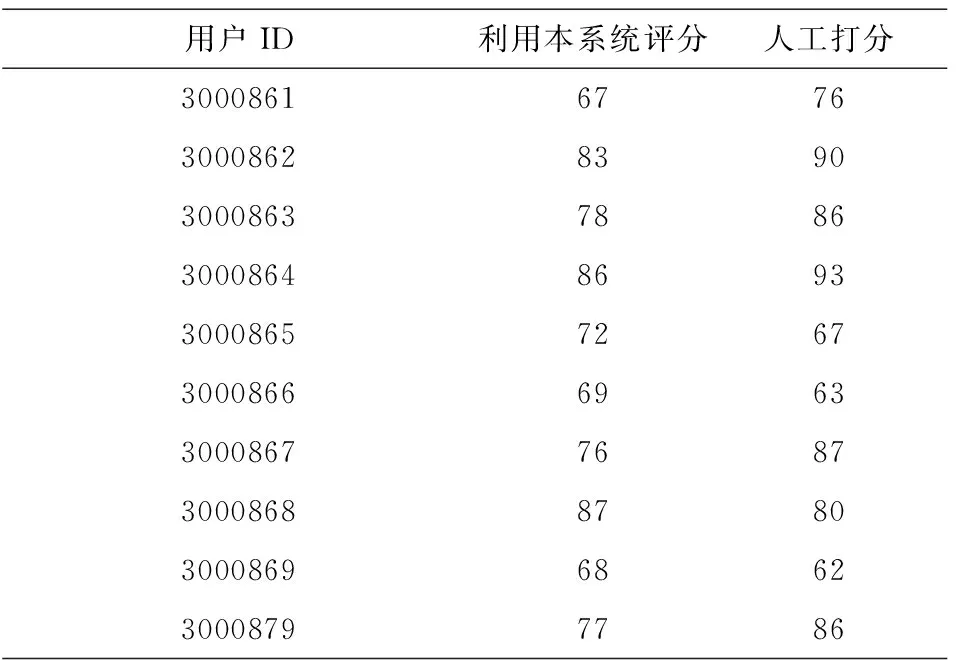
表1 利用本系统评分与人工打分的对比情况表(部分)
本文依照英语发音的特点,利用基于HMM模型的语音识别技术研发了一个英语口语测试系统.评测结果表明,本文的语音评价系统比较符合人的主观感觉,其评价结果能够反映出被测试者的发音水平.
参考文献:
[1]高济.人工智能高级技术导论[M].北京:高等教育出版社,2009:245~246.
[2]Mohamed Debyeche,Aderrahmane Amrouche,Jean Paul Haton.Distributed TDNN-Fuzzy Vector Quantization for HMM speech recognition[C]//International Conference on Multimedia Computing and Systems,2009:72~76.
[3]易克初,田斌,付强.语音信号处理[M].北京:国防工业出版社,2000:172~176.
[4]刘幺和,宋庭新.语音识别与控制应用技术[M].北京:科学出版社,2008:4~8.
