基于聚类和最大似然法的汶川灾区泥石流滑坡易发性评价
2012-01-02胡凯衡崔鹏韩用顺游勇
胡凯衡,崔鹏,韩用顺,游勇
(中国科学院山地灾害与地表过程重点实验室;中国科学院水利部成都山地灾害与环境研究所:610041,成都)
2008 年5 月12 日,四川省龙门山地区发生了Ms8.0 的强烈地震,震中位于汶川县映秀镇,距成都约80 km(图1)。地震引发了大量的滑坡、崩塌、滚石、堰塞湖[1-2],这些同震的地质灾害为震后泥石流提供了丰富的松散物源。居民点和基础设施,如公路、桥梁和水电站都受到了严重威胁。震后的地质灾害造成了更多的人员伤亡和财产损失,如2008 年9 月24 日,北川县一场24 h 降雨量为272.4 mm 的暴雨激发了大面积的泥石流,仅北川老县城附近就有42 人死亡,几十间安置房被摧毁。Cui 等[1]认为,震后地质灾害的活跃期最长可以持续20 年左右。为了指导震后灾害评估、搬迁安置和灾害防治,有必要对震区开展灾害易发性评价工作。
灾害的易发性可以看成某一地学单元发生灾害的空间可能性,通常被描述为一些影响因子的函数,如地层、断裂、坡度、土地利用等[3-6]。目前,已经发展了许多的易发性评估方法[3-14],He 等[14]把这些方法大致划分为定性/半定量方法和定量方法。定量方法包括统计和机制性方法。后验统计方法,如判别分析和逻辑回归方法,可以从灾害分布数据建立易发性和影响因子之间的统计关系;但如果没有足够的灾害分布数据,就无法应用这些方法,而地震发生后短时间内无法了解灾害的分布情况,因此,急需研究在缺少或者只知道部分灾害分布的情况下对地质灾害的易发性进行快速评估的方法。
为此,笔者拟采用聚类分析和最大似然法对强震后泥石流滑坡的易发性进行快速评估。聚类分析法是多元统计分析中的一种常用非监督分类法,在数据挖掘、模式识别、图像分析和机器学习等研究中得到了广泛应用。与后验方法相比,非监督分类方法有2 个优点:可以不用任何训练数据将一个多元数据集分成几个子类;可以避免在赋予影响因子的权重或分类阈值时的主观不确定性。将这一方法应用于汶川地震极重灾区泥石流滑坡的易发性评价中具有其他方法不可比拟的快速评价的优势。
1 研究区概况
研究区位于青藏高原东缘到四川盆地的过渡带龙门山地区,是受此次地震影响最大的区域。龙门山位于四川盆地西北缘,长约500 km,宽约30 ~50 km,呈北东—南西方向延伸,西北与青藏高原相邻,东南与四川盆地相接。地势陡峻,一般高度在3 km以上,最高处超过4 km,而其东南的四川盆地平均高度约500 m。龙门山高高地突起在四川盆地西缘,构成了中国西部与东南部的主要地形分界线。这一区域主要有3 条大的断层,分别是龙门山后山断裂、中央断裂和前山断裂。后山和中央断裂之间主要由志留系—泥盆系浅变质岩和前寒武系杂岩构成,中央和前山断裂之间则主要由上古生界—三叠系沉积岩构成,包括古生代灰岩和含煤岩系[15]。在地貌上,这一区域也可划分为3 个单元:中央断裂以西海拔高于2 000 m 的高山区;中央和前山断裂之间海拔在1 000 ~2 000 m 之间的丘陵区;山前断裂带以东南的平原地貌区(海拔400 ~700 m)。这一区域的气候在夏季主要为太平洋高压带来的亚热带暖湿季风控制,来自东南的暖湿气流受龙门山脉的阻挡,使当地成为川西地区的暴雨中心区,山脉东侧的年平均降水1 100 ~1 500 mm。据l954—1987 年绵竹汉旺气象站资料,年均降水量1 503 mm,最大年降水量2 082 mm(1961 年),多年平均最大1 d 降雨量149 mm,并多次出现大暴雨或特大暴雨,而北川县城观测到的最大年降水量为2 340 mm。山脉西侧主要由暖温带半干旱的大陆季风控制,年均降水量在500 mm 左右。这些自然条件使得这一区域成为中国最容易发生地质灾害的区域之一。研究区域为汶川地震极重灾区四川省,总面积2 万5 800 km2,包括汶川县、北川县、绵竹市、什邡市、青川县、茂县、安县、都江堰市、平武县、彭州市10 个县市(图1),为国家灾后恢复重建的重点规划区域。
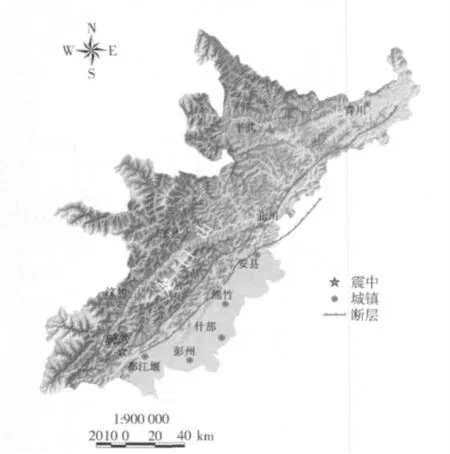
图1 研究区和龙门山断裂Fig.1 Location of study area and Longmenshan faults
2 研究方法
2.1 聚类分析和最大似然法
灾害易发性的聚类分析方法是基于这样的假设:易发性相同的空间单元其影响因子的值也应该比较接近,假设影响灾害易发性的因子有n 个,每个因子在空间上的分布值离散后就是一个栅格,n 个因子的值就组成一个栅格列(图2),在同一个空间单元上就有n 个值,构成一个向量(X1,X2,…,Xn),而一个向量可以看成n 维属性空间的一个属性点,这样,n 个栅格就对应属性空间的一个点集。按照这个假设,易发性比较接近的点应该集中在某个范围内,或者说一个子集里。聚类分析的目的就是将属性空间的一个点集划分为不同的子类或子集,并计算每个子类的统计特征值,如均值和方差。在实际操作时,不是所有的空间单元都参与到子类划分中,只需要选择研究区域一个样板区来进行聚类分析,获取不同子类的特征值。进行聚类分析前只需要给出子类的个数。
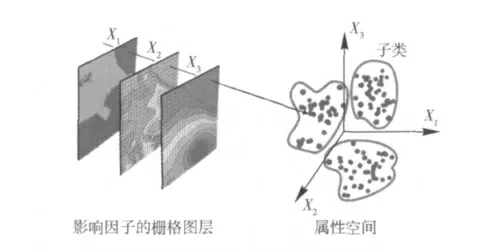
图2 易发性聚类分析示意图(假设影响因子有3 个)Fig.2 Schematics of basic idea of susceptibility mapping with cluster analysis(supposed that there are three effective factors X1,X2,X3,n=3)
聚类分析的算法采用的是k-平均聚类法。计算步骤如下:1)假设k 个子类的初始质心(即均值)均匀或者随机分布在属性空间(图3(a));2)计算点集的每一个点与k 个子类质心的距离,将每一个点归到与其距离最小的那个子类(图3(b));3)计算第2 步得到的新子类的质心(图3(c));4)重复第1步直到每个子类的点数变动少于2%。
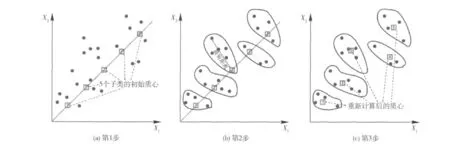
图3 k-平均聚类算法示意图Fig.3 Schematics of k-mean clustering algorithm
聚类分析完成后,可以采用最大似然法MLC(maximum likelihood classification)判断研究区域的任意一个空间单元(网格)属于哪一个子类。根据每个子类的均值和协方差矩阵,基于Bayesian 判别准则和多元属性空间高斯分布的假设,MLC 方法能计算每一个单元属于不同子类的概率。MLC 方法中假设每个子类的先验概率都是相同的,当然,也可以赋给每个子类不同的先验概率(图4)。对某一空间单元来说,它所属的子类就是概率最大的那个子类,落入同一个子类的那些空间单元可以认为易发性相等。
2.2 影响因子
地质灾害发生的3 个充分条件是势能、水源和物源。根据这3 个条件,震后易发性评价的影响因子选择了坡度、相对高差、地表径流深和地震烈度。坡度反映了松散物质起动的动力条件,坡度越陡,物质就越容易起动,但仅用坡度一个因子不能完全反映势能的影响,如泥石流沟口的堆积扇区域比较平坦,坡度比较小,而泥石流堆积扇却是最容易遭受泥石流危害的地方;因此,相对高差也是比较重要的。将相对高差定义为
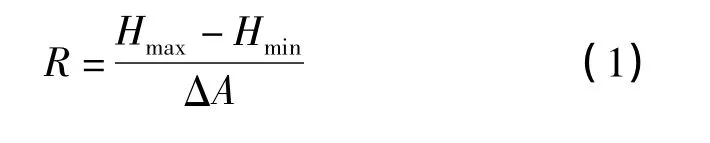

图4 易发性评价流程图Fig.4 Flow diagram of susceptibility mapping by the cluster method
式中:R 为相对高差,m;Hmax、Hmin分别为面积等于ΔA 的一个空间邻域内单元高程的最大值和最小值,m。地表径流深可以反映降水和土壤类型等,是一个综合因子。地震影响着震后的地质灾害的坡体破坏程度或物质来源。如果纯粹考虑因地震而产生的地质灾害,可以认为坡体破坏程度和松散物质量与地震能量,即地震烈度大致呈正比关系;所以,用地震烈度来表示物质这一因素。
2.3 数据和分类
坡度和相对高差栅格数据来自SRTM(Shuttle Radar Topography Mission)提供的DEM 数据,空间分辨率为74 m×74 m(图5(a)和(b))。坡度用ArcGIS 中的表面分析工具计算,相对高差用ArcGIS的邻域统计函数计算。邻域的搜索半径设为10 个网格单元,即ΔA≈0.74×0.74π≈1.72 km2。地震烈度栅格图层来自于美国地调局网站上公布的MMI(Modified Mercalli Intensity)矢量数据(图5(c))。地表径流深栅格数据来自四川省水文局制作的四川省1956—2000 年平均年径流深等值线图(图5(d))。
因为聚类分析中采用的距离是欧几里得距离,所以,聚类的结果对栅格图层的取值范围比较敏感。为了消除这一影响,每个栅格图层都用它的最大值归一化,使其值在0 到1.0 之间,如地震烈度的最大值为9.9,烈度栅格层除以9.9 后,取值在0.545 到1.0 之间。归一化后,采用k-平均聚类方法将栅格集分为极低、低、中等、高、极高5 个子类,并输出每个子类的统计特征值(表1)。聚类分析的样本集为10×10 的子块中取一个单元,迭代到100 次之后5个子类的均值和方差都没有变化为止。最大似然估计用这些子类的最终统计特征值来判断每个单元属于哪一个子类。所有的这些操作,包括数据转换、栅格计算和聚类计算都在ArcGIS 中实现。

表1 k-平均聚类法得到的5 个子类的归一化均值Tab.1 Means of five clusters obtained by k-mean clustering
3 结果与分析
采用聚类和MLC 方法最终得到5 种级别的泥石流滑坡易发性评价结果,但是,为了知道哪个子类对应哪种易发性,还需要进一步做出判断。基于一些常识或专家的经验,很容易判断出第1 个子类为极高易发性区,第2 个子类为高易发区,第5 子类为极低易发区;但是,不太容易判断第3 和第4 个子类哪个是中等易发区,哪个是低易发区。为此,用地质灾害的点密度(个/km2)来判别这2 个子类。一般来说,灾害的点密度值越大,易发性也就越高,灾害点密度的数值来自从遥感图像和应急调查中获取的有限地质灾害分布数据。这个分布数据只有3 967 个灾害点,是地震发生后短时间内获得的。计算结果(表2)表明,第3 个子类的点密度为0.123,而第4 个子类的点密度为0.082。由此可以判断出第3 个子类为中等易发区,第4 个子类为低易发区。另外,第1、2 和5 子类的点密度分别为0.391、0.198和0.071,说明对这3 个子类的易发性分析是正确的。最终的易发性分区图见图6。
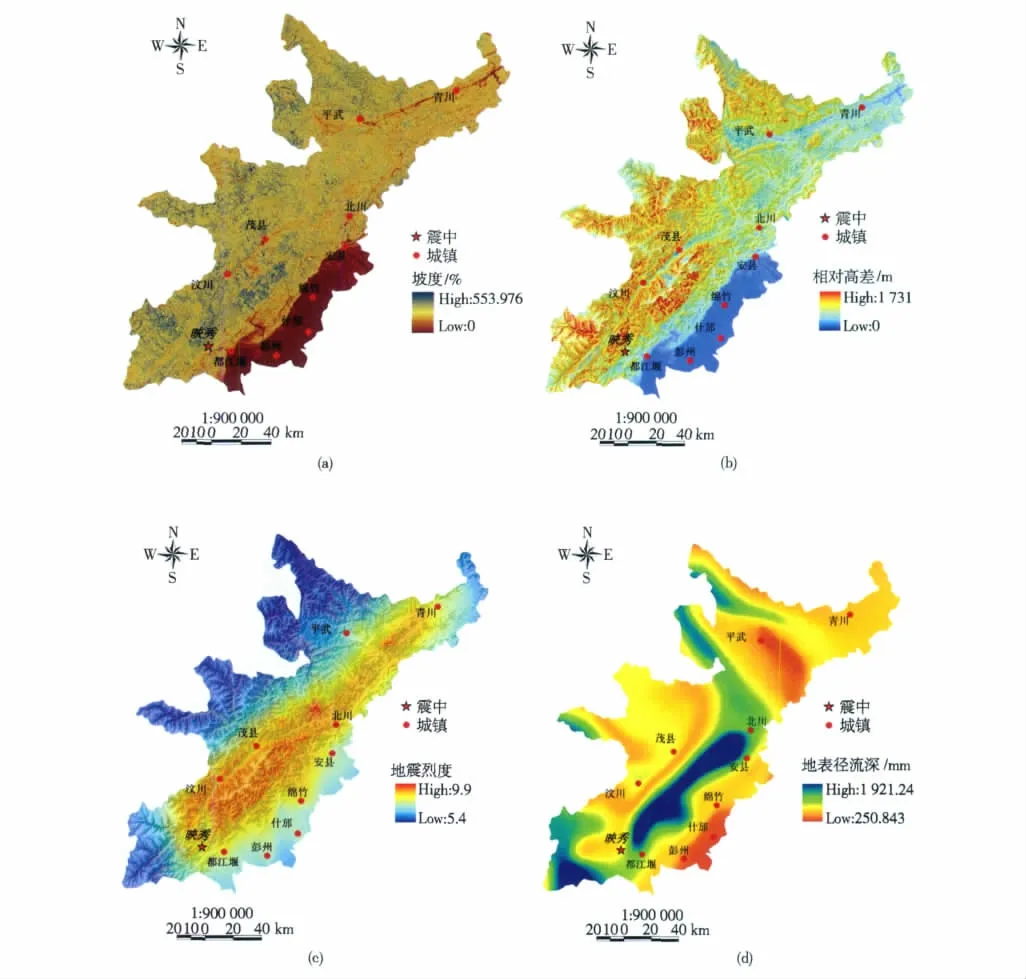
图5 影响因子的栅格图Fig.5 Grid maps of four effective factors

表2 各子类的面积和灾害的点密度Tab.2 Area and geo-hazard density of five clusters
从表1 可以观察到,极高子类的地震烈度、地表径流深度值都是最大,而它的坡度和相对高差并不是最大。与此相反,极低子类具有最小的坡度和最小的相对高差值。从图6 可以发现,即使在高易发区域(图6 中的粉红色区域),放大之后可以看到有极低易发区域(绿色区域)存在,如茂县、青川和平武县县城附近,这几个县城没有直接受到震后地质灾害的威胁,泥石流滑坡的危害也不明显;因此,这一分区图可以用来寻找危险区中的安全岛(即小块的低易发区)。从分区图中还可以发现一点,在极高易发区和高易发区以及高易发区与极低易发区分界线附近,地质灾害点分布比较密集,如北川老县城就位于极高易发区和高易发区交界处,就在地震后不到1 年的时间里,滑坡和泥石流就毁坏了大部分的县城(图7)。
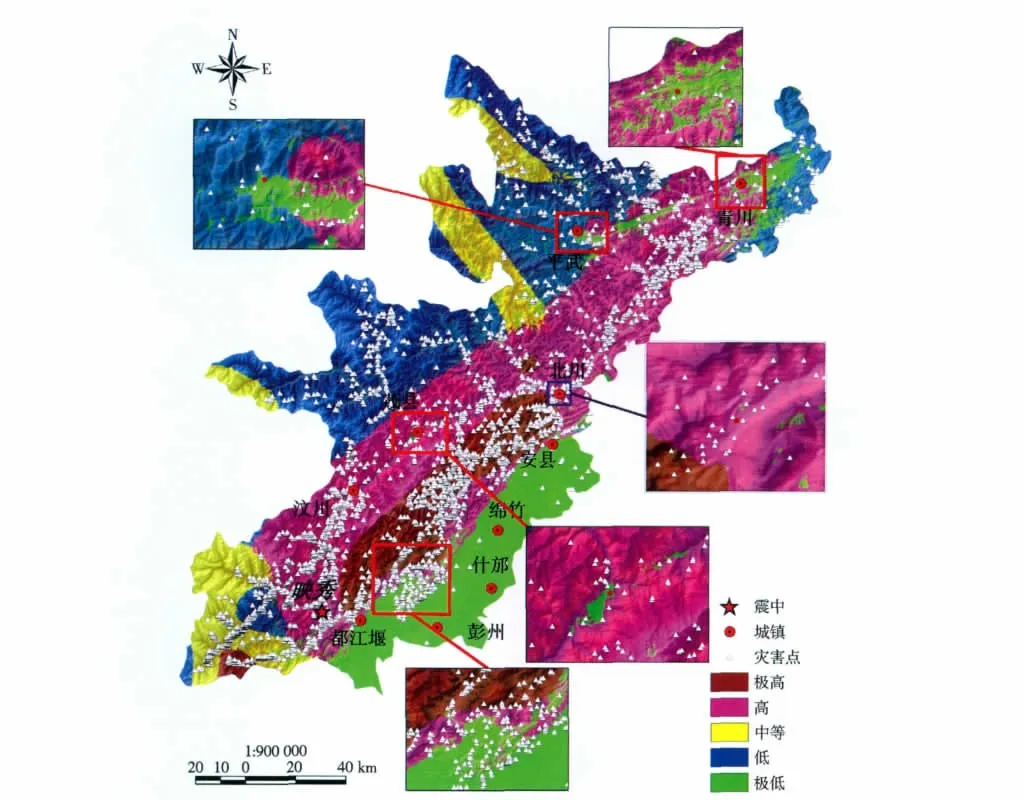
图6 地质灾害分布和易发性评价图Fig.6 Maps of geo-hazards and susceptibility

图7 2009 年4 月16 日的北川县城遗址Fig.7 City of Beichuan on 16 April,2009 inundated by post-quake rainstorm-triggered debris flows
4 结论与讨论
在没有足够训练数据的情况下,采用聚类分析和最大似然方法可以快速对一个大区域的地质灾害易发性进行评估,且不需要给定各个影响因子的权重。
研究选取了坡度、相对高差、地震烈度和地表径流深4 个影响因子,虽然没有考虑更多的因子,如断裂距离、岩性等,但最终得到的地质灾害易发性评价图比较合理,与地质灾害的点密度值吻合。从易发性评价图可以发现,在大块的高易发区内存在一些小的极低易发区,这些极低易发区可以作为安全的居民点。另外,在极高易发区和高易发区以及高易发区和极低易发区分界线附近,地质灾害点分布比较密集。
[1] Cui P,Chen X Q,Zhu Y Y,et al.The Wenchuan Earthquake(May 12,2008),Sichuan Province,China,and resulting geohazards[J].Nat Hazards,2011,56(1):19-36
[2] 黄润秋,李为乐.“5·12”汶川大地震触发地质灾害的发育分布规律研究[J].岩石力学与工程学报,2008,27(12):2585-2592
[3] Dai Fuchu,Lee C F.Landslide characteristics and slope instability modeling using GIS,Lantau Island,Hong Kong[J].Geomorphology,2002,42:213-228
[4] Lin M L,Tung C C.A GIS-based potential analysis of the landslides induced by the Chi-Chi earthquake[J].Eng Geol,2004,71:63-77
[5] Kamp U,Growley B J,Khattak G A,et al.GIS-based landslide susceptibility mapping for the 2005 Kashmir earthquake region[J].Geomorphology,2008,101: 631-642
[6] Carrara A,Crosta G,Frattini P.Comparing models of debris-flow susceptibility in the alpine environment[J].Geomorphology,2008,94:353-378
[7] Carrara A,Cardinali M,Detti R,et al.Gis techniques and statistical-models in evaluating landslide hazard[J].Earth Surf Proc Land,1991,16:427-445
[8] Jade S,Sarkar S.Statistical-models for slope instability classification[J].Eng Geol,1993,36:91-98
[9] Jiang H,Eastman J R.Application of fuzzy measures in multi-criteria evaluation in GIS[J].Int J Geogr Inf Sci,2000,14:173-184
[10]Van Westen C J,Rengers N,Soeters R.Use of geomorphological information in indirect landslide susceptibility assessment[J].Nat Hazards,2003,30:399-419
[11]Lee S,Ryu J H,Min K D,et al.Landslide susceptibility analysis using GIS and artificial neural network[J].Earth Surf Proc Land,2003,28:1361-1376
[12]Lan H X,Zhou C H,Wang L J,et al.Landslide hazard spatial analysis and prediction using GIS in the Xiaojiang watershed,Yunnan,China[J].Eng Geol,2004,76:109-128
[13]Ercanoglu M.Landslide susceptibility assessment of SE Bartin(West Black Sea region,Turkey)by artificial neural networks[J].Nat Hazard Earth Sys,2005,5: 979-992
[14]He Y P,Beighley R E.GIS-based regional landslide susceptibility mapping: a case study in southern California[J].Earth Surf Proc Land,2008,33:380-393
[15]李勇,黄润秋,周荣军,等.龙门山地震带的地质背景与汶川地震的地表破裂[J].工程地质学报,2009,17(1):3-18
