基于字符类别的识别反馈混排字符切分方法
2011-12-27安艳辉陈韶霞刘宗敏
安艳辉,陈韶霞,刘宗敏
(1.河北省工业和信息化厅,河北石家庄 050051;2.河北省农业区划委员会办公室,河北石家庄 050051)
基于字符类别的识别反馈混排字符切分方法
安艳辉1,陈韶霞1,刘宗敏2
(1.河北省工业和信息化厅,河北石家庄 050051;2.河北省农业区划委员会办公室,河北石家庄 050051)
字符切分是影响OCR系统识别的关键因素之一。对于中英文混排文档,提出了基于字符类别的识别反馈混排字符切分方法,利用字符特征分类判别出文档中的汉字类、英文、数字和标点符号类、部件类,对汉字类和部件类借助识别技术分别进行处理。该方法结构简单,容易实现,实验结果表明该方法切分效果好,字符类别判断准确。
字符切分;分类器设计;字符类别判断;字符识别
字符识别技术经过几十年的发展,取得了长足的进步,目前,大多数字符识别是基于对单个字符的逐个识别,字符识别率的高低与字符切分的正确与否密切相关,尤其是在中英文混排的情况下,显得更为重要,它直接影响到识别的正确率。脱机印刷体字符识别系统虽然已形成商业产品,随着中英文混排文档图像的日益增多,实用性不是很理想。
当前字符切分技术主要有以下几种方法[1]:
1)基于图像分析的分割;
通过图像分析寻找字符之间较为合理的分割点,主要采用静态的投影分析方法。
2)基于识别的分割;
在实际的分割前借助于识别能力对各种存在的分割进行选择合理的分割。
3)综合了前面两种技术的分割;
通过图像分析产生较少的垂直分割的假设,并通过识别对假设进行筛选。
4)整体识别;
以整个词为结识客体,根据词的整体特征来识别,从而避免分割对字符的损伤,这种方法在一般识别有限的关键性词汇时使用。
总结了近几年[2,3]的字符切分技术后认为,字符切分主要综合考虑两种信息:基于局部的特征,字符形状和结构等特征信息;基于整体的特征,切分出字符内容的信息。由于对字符形状与结构,字符内容信息等描述较复杂,工作量较大,不易扩展。由实验可知,单独描述字符信息或使用某种切分方法,对于实际的中英文混排文档的切分效果很不理想,因此采用基于字符类别的识别反馈混排字符切分方法。该方法结构简单,容易实现,实验结果表明该方法切分效果好,字符类别判断准确。
1 基于字符类别的识别反馈混排字符切分过程与原理
1.1 问题提出与定义规则
在自动录入书籍及其它一些文献时,会经常遇到中文 、英文 、数字和标点符号混排的文档,中文和英文在字符的形状和结构上都存在着很大的差异,这些字符有各自比较明显的特征,它们在印刷排版中也体现了不同的特性,针对实际的混排字符情况,应分别采用不同的字符切分方法。因此,首先应判断待切分字符的类型,字符类型包括汉字、英文 、数字和标点。文献[4]提出了一种印刷体字符类型判断方法,本文定义字符分类规则如下:
规则1 沿字符区域块从左向右逐列进行纵向扫描,记录每一列经过的白黑象素交换次数。如果白黑象素交换次数不低于4的列数与字符区域块的宽度比高于阈值a1,同时规则排版中字符宽度和字符中心距均在一定范围内且趋于一致,则认为该字符区域块内字符为汉字。这里,阈值a1来自实验值。
规则2 根据向上凹曲线的定义,求出区域块的向上凹曲线的个数,若个数不低于阈值b1,同时通过比较字符的高度、宽度、字符间距、字符中心距、字符所在位置和扫描线经过英文数字的笔画数,若字符的高度均小于平均高则认为该字符区域块内为英文和数字。这里,阈值b1来自实验值。
规则3 若区域块的方向比(宽度:长度)低于字符最小方向比阈值c1,若区域块内的字符宽度 、高度与平均字符高度与宽度的差值的绝对值小于一定阈值d1时,且该字符与后一字符间距比较大时,则认为该区域块内的字符为小标点;若区域块内的字符宽度 、高度与平均字符高度与宽度的差值的绝对值小于一定阈值d2时,且该字符与后一字符间距比较大时,则认为该区域块内的字符为大标点;这里c1、d1、d2来自实验值 。
规则4 若区域块的方向比位于单字区域块最小方向比阈值e1和最大方向比阈值e2之间,并且区域内有效字符的方向比位于单字字符最小方向比阈值f1和最大方向比阈值f2之间,则认为该区域块内的字符为汉字 。这里,阈值e1,e2,f1,f2来自实验值。
规则5 对于左右结构之分的汉字被切分成左右部件的情况,依据字符的基本信息(字符高度、字符宽度、字符间距、字符中心距、字符所在位置、平均行高、字符高宽比等),判断该区域块内的字符是否为汉字部件;其合并过程借助于识别模块来处理。
规则6 不满足上述任何规则的区域块,则认为是英文字符。
1.2 字符类别判断与字符切分流程图
字符类别判断与字符切分流程如图1所示。

图1 字符类别判断与字符切分流程
字符切分过程主要分为以下三步:
第一步:倾斜矫正及行列切分,倾斜矫正的目的是为后面分类器设计进行正确的字符特征提取;
第二步:根据行列切分的结果,依据分类器进行字符类别判断,分类判断出汉字类 、英文 、数字 、标点符号类 、部件类;
第三步:根据分类结果进行识别,若是正确的汉字类则作为切分结果保存记录;若为英文 、数字 、标点符号类直接保存记录切分结果;若为部件类根据左右关系及合并算法进行合并,然后识别,若结果正确,则作为切分结果保存记录,若不正确重新合并识别[5,6],直至为正确结果。
判断文字类别及部件合并、识别过程如图2所示。

图2 判断字符类别及合并识别过程
1.3 分类器设计
分类器设计原则:假定特征向量各分量间相对于决策变量是相对独立的,对于特征向量X=[x1, x2,…xd]T的训练样本,它属于Ci类的条件概率为:

对于汉字 、英文 、数字和标点字符类别都计算条件概率,最终的识别结果作为条件概率最大的那一字符类别,判别出相应的字符类别,依据字符类别进行单独处理,保存切分结果。
1.4 分器设计的特征提取
在进行分类器设计时,用到两种类型特征,一种是字符形状和结构方面的特征,包括六种字符外形特征(字符高度、宽度、字间距离、覆盖率、高宽比、纵向起始位置);另一种是字符内容特征,包括16维方面线素特征(提取出水平、垂直、45°、135°四个方向的方向像素特征),第一种特征里,除了覆盖率和高宽比外,其他的四种特征需要特征归一化[7]。因此,切分过程的第一步是倾斜矫正和估计汉字平均高和宽,依据这些特征和定义的6种规则,分类器完成字符类别判断,然后调用识别过程[8]进行识别,若识别正确,最终保存切分结果。
笔者采用超星数字图书馆和国家图书馆扫描的书籍作为训练和测试对象,从训练图像中挑选出三类字符(汉字类,英文 、数字 、标点符号类,部件类)作为训练样本,用训练样本的特征分布估计部件条件概率,完成分类器设计。
部件条件概率公式:
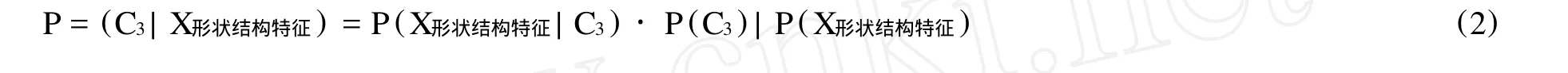
2 实验结果及分析
实验结果表明该种切分方法能正确判断出字符类别和对字符正确切分。实验结果如图3所示。

图3 总体实验结果
判断为汉字类及部件类合并后再识别为正确结果的情况如图4所示。

图4 汉字类实验结果
判断为英文数字标点类的情况如图5所示。

图5 英文、数字、标点类实验结果
我们从《求是》等杂志,《人民日报》《光明日报》等报纸及小说类的书籍作为样张,各扫描100页,统计结果如表1。

表1 字符分类前的切分统计结果
识别反馈后字符正确切分后的统计结果如表2。

表2 识别反馈后字符切分统计结果
3 总结
对于中英文混排字符图像,本文提出了一种基于字符类别的识别反馈混排字符切分方法。在该方法中,最佳阈值的选取需要大量的实践来获得,因此其可靠性以及鲁棒性仍需在更多的具体实践中得到验证和提高。结合识别后处理过程、自然语言理解和利用字符的上下文关系[9],进行描述与分析,也是进一步的研究工作。
[1] Richard G.Case,Eric Lecolinet.A Survey of Methods and Strategies in Character Segmentation[C].IEEE Transactionson Pattern Analysis and Machine Intelligence,1996,18(7):690-706.
[2] YILU.Machine Printed Characters Segmentation-An Overview[C].IEEE Transactions Pattern Recognition,1995,28(1):67 -80.
[3] YILU,M.Shridhar.Characters Segmentation in Handw ritten Words-An Overview[C].IEEE Transaction Pattern Recognition, 1996,29(1):77-96.
[4] 黄冬萍.OCR预处理技术—从版面分析到字符切分[D].东北大学硕士学位论文,1998.
[5] 马少平,夏莹,朱小燕,等.汉字系统的误识模型[J].清华大学学报,1999(38):108-111.
[6] 安艳辉,董五洲.粘连搭接字符切分方法研究[J].河北师范大学学报,2005,29(2):137-141.
[7] 徐蔚然,于武贵,郭军.基于统计方法的混排文字切分与分类[C].绍兴,第七届全国汉字识别会议论文集,2002:123-128.
[8] 苗秀芬.汉子字体识别研究[D].河北大学硕士学位论文,2003.6.
[9] 沈清,汤霖.模式识别导论[M].国防科技大学出版社,1991.
The segmen tation of the m ixed arranging character based on the sort and recogn ition of characters
AN Yan-hui1,CHEN Shao-xia1,LIU Zong-min2
(1.Industry and Information Technology Department of Hebei Province,Shijiazhuang,Hebei050051,China;2.Hebei Scheme of A gricultural Pursuits Bureau,Shijiazhuang,Hebei050051,China)
The characters′segmentation is one of the key facto rs w hich affect character recognition in OCR system.Aimed at the document image w ith both Chinese characters and English characters.this paper p resent themethod w hich is the segmentation of themixed arranging character based on the sort and recognition of characters.Classifying by the characters characteristic,it is distinguished into Chinese character class,English and number and punctuation mark class,and component class.Then Chinese character class and component class is p rocessed respectively w ith recognition technique.The structure of thismethod is simple and easy to realize.The result of the experiment indicates that this method has good effect on segmentation and has high accurate rate in character classification discrimination.
Character segmentation;Classification design;Character classification discrimination;Character recognition
TP319
:A
1001-9383(2011)01-0015-06
2011-01-12
河北省自然科学基金资助项目(602127)
安艳辉(1972-),男,河北省乐亭县人,高级工程师,硕士,主要从事计算机图像处理和数据库方面的研究.
