市场冲击、劳动共享与制造业集聚——基于中国城市面板数据的研究
2011-12-21张文武
张文武,梁 琦
(1.南京大学,江苏 南京 210093;2.中山大学,广东 广州 510275)
市场冲击、劳动共享与制造业集聚
——基于中国城市面板数据的研究
张文武1,梁 琦2
(1.南京大学,江苏 南京 210093;2.中山大学,广东 广州 510275)
文章基于劳动共享模型,采用城市面板数据计算了中国的劳动共享效应,并解释制造业集聚的变化。结果表明:劳动共享是产业集聚形成的重要因素,劳动共享效应会提高地区的集聚水平;城市规模对制造业集聚有正的显著影响,本地市场效应在我国发挥着重要作用;我国制造业集聚与工资溢价负相关,反映了现阶段制造业集聚与低劳动成本的糅合。最后,文章提出了相关政策建议。
劳动共享;市场冲击;产业集聚
中国过去三十多年来制造业不断向沿海集聚,逐步拉大了内陆与沿海之间经济发展的差距。这种区域发展的不均衡现象与产业集聚过程密切相关:一方面,沿海地区制造业的空间集聚取得了巨大的生产优势,产业结构和资源配置不断优化,区域增长速度和竞争力与其他地区的差距逐步扩大[1-3];另一方面,产业转移往往伴随着劳动力的流动,大量的劳动力和厂商集中在东部沿海,所产生的劳动市场共享和知识溢出效应将进一步拉大各地区的差距,产生持久性的影响[4-5]。其中产业集聚地的劳动市场共享效应尤为值得关注,对研究中国普遍存在的劳动力跨地区流动和区域发展不均衡现象具有积极的意义。
本文首次尝试利用中国城市的数据进行劳动市场共享的计算,并实证与制造业集聚的关系。
1 实证模型的建立
市场冲击存在下,劳动共享有利于提高厂商的期望利润,,吸引厂商进入形成产业集聚;劳动共享愈明显,工人期望报酬越高,进一步吸引劳动者进入,形成持续的产业集聚。
本文将根据多区域多部门的劳动力市场共享模型,预测劳动力共享对产业集聚的影响。
结合中国的实际情况建立如下实证模型:

C为制造业空间集聚度,为了更好的表达厂商的空间分布,本文采用Ellison-Glaeser指数;lp为劳动市场共享,pop为城市人口量,w为城市工资溢价,city为城市虚拟变量,ε为误差项。另外,下标s表示城市,t代表年份。
2 数据、变量及样本描述性统计
2.1 数据来源及变量说明
本文数据主要来源于1998—2008年的《中国城市统计年鉴》,共取286个城市作为观察样本,包括268个地级市和15个副省级市和3个直辖市,其中地级市的范围是其下辖的区、县及县级市。鉴于数据处理的难度和研究的目的,本文采用近十年的数据作为实证依据。其他所需数据来源于同年份的《中国工业统计年鉴》和《中国区域统计年鉴》。
2.2 变量说明
(1)C代表制造业空间集聚度。本文选用Ellison-Glaeser指数作为模型的因变量。
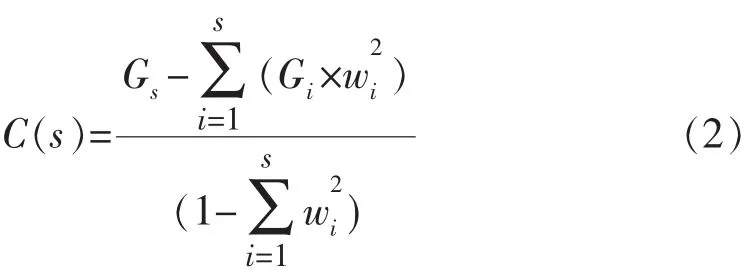

其中Sn为某产业第n个地区的产值占全国总产值的份额,N为地区总数,本文指286个城市。鉴于考察对象为制造业集聚度,计算Gs时,Sn取第n个地区的GDP总值占全部总产值的份额;计算Gi,Sn取第n个地区制造业产值占全部地区制造业总产值的份额。C(s)越大表示制造业空间集聚度越高,此计算方法尽可能的降低了地理单元大小的干扰,避免出现某些地区制造业产值很大,但集聚度并不是很高的情况。
(2)lp代表劳动市场共享,是本文重点关注的变量。根据现有文献的研究成果,该指标的计算大致有三种方法:净劳动生产率法;管理人员与生产工人比值法;工人中拥有博士、硕士和学士学位人员比例法。本文采用三种方法的综合替代,并考虑了劳动者就业环境(市场冲击)和厂商环境(市场冲击)。计算公式为:
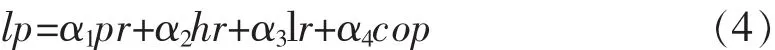
其中,pr为净劳动生产率,等于地区制造业产值占当地GDP比例除以制造业工人数占当地总人口比例;hr为人力资源密度,等于地区高等学校在读学生和在职教师总数除以制造业工人数。lr为城市劳动就业环境,采用的是城市非农业劳动人口数量除以制造业就业人口。最后一个指标cop,代表公司的生存环境,采用非公有企业的产值占制造业总产值的比例,值越大表示企业发展环境越好。由于首次采用加权的方法计算劳动市场共享,对加权系数的确定并没有现成的公式计算。本文采用了对比回归的方法确定各项指标加权系数值,得到α1= 19.8%,α2=26.4%,α3=30.1%,α4=23.7%。
(3)pop代表城市人口总量,取10万为单位。选取该指标作为自变量代表劳动市场的大小和生产市场的规模。
(4)w代表工资溢价。鉴于数据的处理难度,采用近似替代的方法计算工资溢价。本文采用该城市职工平均工资与全国职工平均工资的比值。高收入城市往往伴随着明显的工资溢价,为了更贴近产业发展的现实,我们利用city变量对一些特殊高收入的资源型城市进行了区分,资源型城市取0,非资源型城市取1。
(5)year为时间虚拟变量,用来控制时间固定效应的影响。
2.3 样本描述性统计
表1给出了样本的描述性统计,可以看出,中国制造业的Ellison-Glaeser指数11年来的均值有明显的上升趋势,同时劳动市场共享均值、城市人口总量也在逐年增加。
呈明显的正相关关系(见图1)。

图1 劳动市场共享与Ellison-Glaeser指数散点图
3 模型估计与结果分析
3.1 模型设定的技术性处理
本文采用面板数据的处理方法。面板数据的基本假设是参数齐性,违背假定的情况通常有参数非齐性偏差和选择性偏差。本文数据样本是包括286个城市11个年份的这样一个宽而窄的样本,因此,参数的非齐性是本文在建模时考虑的重点。除非两种检验均表明不能拒绝回归系数齐性的原假设,否则直接对方程进行OLS估计都是有偏的。我们通过F值检验和Husman检验确定模型的系数截距项与固定随机效应。另外,由于本文考察的是劳动市场共享和制造业集聚间的关系,还涉及到工资溢价,因果关系并不是固定的,也即是说有可能存在变量内生性的问题。为了解决内生性的问题,本文参照Redding and Venables(2004)等人的做法[6],引入各地区制造业企业总数(Cs)为工具变量。将这一工具变量和其他外生变量对lnlp进行回归,得到Cs的回归系数为0.9106,且在5%的统计水平上显著,整个回归的拟合优度为0.861,说明Cs满足作为一个良好工具变量的第一个必要条件,反映一个地级单位经济规模的变量,是外生的。基于以上分析,我们认为选取Gc作为市场潜能的工具变量是可行的。另外,通过对引入工具变量前后的回归对比,发现工具变量使R2自0.673上升到0.884,并且企业总数的系数为0.2316,在1%的统计水平上显著,选取企业总数作为工具变量是合适的。
3.2 结果分析

表2 模型估计结果

表1 样本的描述性统计
表2给出了固定效应和随机效应下分别以OLS方法和2SLS方法的估计结果。结果显示,无论是以何种方式进行回归,劳动市场共享的系数均显著为正。固定效应和随机效应的Husman卡方值为负,本文倾向于选择接受系数存在系统误差的假设,结合内生模型的回归,选择随机效应模型作为分析依据。第四列显示了使用工具变量的随机效应模型(IVRE)的分析结果,Husman的检验结果(P=0.002)拒绝了IVRE和RE的回归系数没有系统误差的假设,说明劳动市场共享具有内生性。根据表2列出的结果及相关检验,我们认为,工具变量随机效应模型所得到的实证结果是稳健的。
根据实证结果显示,劳动市场共享的系数显著为正。在控制其他变量的情况下,1%的劳动市场共享可以使Ellison-Glaeser指数提高约0.12%。实证结果与理论预测一致。本文的劳动市场共享是将劳动生产率、人力资源密度、劳动风险、风险冲击均考虑在内,符合当前国内的情况。中国制造业的集聚,往往是建立在迁移目的地良好的交通、人力资源、优惠政策等基础上的。我国东部沿海这些基础都具备,劳动力资源的优势尤为突出,大量劳动力尤其是高素质劳动力人群的聚集,提供了广阔的知识共享和风险分散的空间。
结果显示,城市人口总量对制造业集聚有显著正的效应。城市人口近似代表地区的劳动力规模和消费规模,根据新经济地理学的解释,较大规模的本地市场能够创造更多的产品需求和劳动力供应,并有利于降低中间产品交易的成本,因而产生后向关联吸引厂商聚集在该地区。正如我国东部沿海居住着超过40%的人口,具有较高的经济水平和较高的消费能力,吸引大量的制造业生产厂商聚集,该结果符合理论和实际情况。
本文还以替代指标考察了工资溢价对于集聚地影响。结果显示,工资溢价对制造业的集聚影响为负。这个结果与我们先前的理论预测不尽一致,开始我们以为是替代指标的设定错误,并尝试了利用其他学者已经研究的部分年度的工资溢价进行反复比较,最后得到的结果都显示为工资溢价对制造业集聚产生负的影响。该结果可能与我国现阶段所处的制造业阶段有关。近年来,劳动力优势一直是我国制造业和对外贸易快速发展的落脚点,劳动密集型企业也取得了成功。但是劳动力优势并不是建立在技术领先方面的,而是依赖较低的劳动成本,一旦劳动力使用成本上升,这种优势就会受到影响。2008年新劳动法的实施加之国际经济危机的影响,出现过加工贸易企业倒闭,农民务工流返乡的现象,这些都是低劳动成本依赖性的某种体现。
4 总结性评论
本文在劳动市场共享模型的基础上使用中国1997—2007年 286个城市面板数据对劳动市场共享、工资溢价等因素与制造业空间集聚的关系进行实证分析。结果表明:①在控制了其他变量的情况下,劳动市场共享对我国制造业集聚影响显著为正。提高劳动生产率、降低就业风险、改善企业的生存环境有利于制造业集聚的形成和加强。这支持了空间经济模型的理论预测,也为劳动市场共享研究提供了来自中国的证据;②城市人口规模对制造业集聚有正的显著影响,说明本地市场效应在我国发挥着重要作用,较高的消费能力和丰富的劳动力资源是促进制造业集聚的关键要素。③我国制造业集聚与工资溢价为负相关,即劳动力工资的上升不利于集聚的形成,该结果与理论预测相悖,但恰好反映了我国现阶段制造业集聚与低劳动成本的糅合。低劳动成本优势在我国制造业集聚过程中发挥了不容忽视的作用,也是近年来经济快速发展的重要支撑,但终究不是长久之计。随着经济的发展和全球化的推进,我国的劳动力成本优势正在逐步减小,制造业集聚格局如何优化发展将成为需要解决的重要问题。
[1]梁琦.知识溢出的空间局限性与集聚[J].科学学研究,2004,(01).
[2]李国平,范红忠.生产集中、人口分布与地区经济差异[J].经济研究,2003,(11).
[3]简泽.技术外部性、工业集聚与地区经济的非均衡增长[J].南方经济,2007,(06).
[4]Henry G.Overman,Diego Puga.Labor pooling as a source of agglomeration:An empirical investigation[R].CEPR discussion paper 2009,7174.
[5]范剑勇.产业集聚与地区间劳动生产率差异[J].经济研究,2006,(11).
[6]Redding S.,Venables.Economic geography and international inequality[J].Journal of International Economics,2004,(62).
Market Impact,Labor Pooling and Industry Agglomeration——based on Chinese Cities Panel Data
Zhang Wenwu1,Liang Qi2
(1.Nanjing University,Nanjing 210093,China;2.Sun Yat-sen University,Guangzhou 510275,China)
In this paper,we calculated the labor pooling of China using city census data based on the labor pooling model,and explained the industry agglomeration changes.This paper found that:(1)Labor market pooling has a positive significant effect on industry spatial concentration.Meanwhile,the increase in degree of labor pooling will raise the region’s income level.(2)The size of the urban population has a significant positive impact on industry clustering,the capacity of local consumption can promote Industry agglomeration;(3)The wage premium has a negative impact on industrial clustering,the income gap has become an obstacle to the manufacturing industry agglomeration.At last,we also pointed out some proposals.
labor pooling;market impact;industry agglomeration
国家社会科学基金重点项目(07AJY012),全国优秀博士学位论文作者专项基金(200703),南京大学研究生科研创新基金(2009CW02)。
2010-12-10
张文武(1983-),男,南京大学经济学院博士研究生;研究方向:产业经济、新经济地理。
F129.9
A
(责任编辑 迟凤玲)
